1.说明
各位小伙伴大家好,已经快2年没有更新博客了,这期间有很多朋友关于ai大模型在垂直行业应用等问题留言发表了自己的问题和想法,也有很多朋友对大模型在垂直领域该如何跟自己应用进行集成存在很多疑问。这里我拿一个多模态机器人的架构设计案例从0到1绍一下,ai或者大模型等在通用领域或者垂直领域是如何进行顶层的架构设计的,本文不会涉及太多具体技术设计内容,意指是介绍ai在行业应用上的整体的集成架构思维。
小爱架构图



便于大家理解多模态智能小机器人,上面是我放置小爱 和小度的智能助手图片,这只是多模态机器人的其中一种形式,即智能助手的形式,该形式一般是一个交互式的语音音响。另外一种是基于行动式的,即操作式或者行动式,本文主要是以智能助手形式来作为软件架构思想讲解,因为操作式和行动式涉及到动力学,姿态控制和其他相关学科知识,不在本文讨论范围内。之所以拿多模态智能助手来进行案例讨论,主要是因为这已经是大家身边耳熟能详的ai落地案例,而且其中结合了具体的行业智能家居集成应用,便于进行整个链路场景的分析
2:多模态小机器人的架构设计
这里咱们只说软件部分的设计,硬件的模块部分不做详细讨论,以下是我对多模态机器人的顶层架构设计图,大家重点是看一下架构思路,便于在各自领域行业进行多模态设计。
2.1:顶层架构图

2.2:语言模块
语言模块主要是nlp 处理单元,作用是对自然语言的分词,理解和反馈,说白了就是可以和人一样交互对话,目前主流的模型架构是Transformer架构,Transformer架构主要架构如下图,了解即可,目前nlp 模块基本都是基于开源LLM直接微调,
目前主流的nlp开源LLM主要有chatgpt 系列,llama系列, qwen系列,grok系列等,有兴趣的可以自己部署体验一下。

transformer架构图
2.3:视觉模块,常用微调方案
视觉模块主要是很对图像和视频的处理单元,图片处理的作用主要是几种,一种是基本分类,就是将输入的图片给定一个结果,比如输入猫的图片,返回是猫或者具体猫的品种,数据基本的分类,第二种是领域判定,比如输入了x光的图像或者输入了
多个图像,然后综合判定是否生病以及判定依据,第三种是图片理解,比如输入了一个景区照片,让推理模型给出自己的理解,这个大部分没有标准答案,实际应用中一般是前两种,也就是用来给出某些确定的结果,目前主流的nlp开源LLM
2.4:如何设计自己的语言模块和视觉模块并进行微调
语言模块一般无需自己从0到1训练,目前基本的都是直接拿nlp大模型直接进行微调,视觉模块主要是看自己需求,
如果是针对自己特定需求的图像识别,那可以针对性的从0到1训练也可以基于大模型微调,如果自己独立训练目前主流的是基于yolo系列进行,
但是我建议还是直接拿大模型进行微调比较好,主流的微调工具有llama-factory,peft,unsloth,swift等。
另外如果跨领域比较多,可以训练为多个推理模型,添加模型选择模块,在推理时动态选择对应的模型,这样既解耦了模型训练时的模型大小,也加快了模型推理的速度。
3:针对通用领域和垂直领域的应用集成架构设计
这部分是小伙伴们最关心的,就是如何将推理与自己的应用结合,架构思路是应用端预留接口,推理客户端或者推理平台可以进行调用,一般私有客户端都是可以进行配置的,例如ip,wifi,端口等。
3.1:顶层架构图
拿小爱举例,当你让他说一下今天最新时事新闻时大致的流程如下图
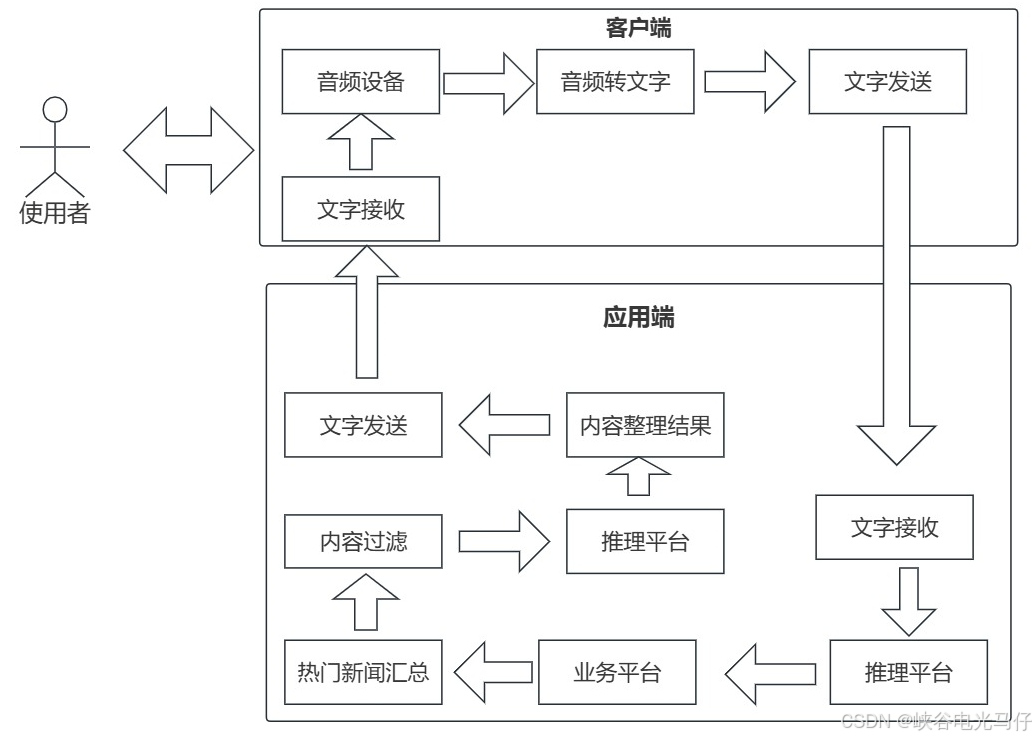
总体思路,就是如果需要集成自己应用的话,推理需要分为两步,第一步是让推理模型给你一个他理解的结果,这个模型只需给出简单的判断,判定结果是具体需要调用的业务,比如结果是几个数字代码,如1001,1002,1003,代码代表的是与我们具体应用关联的业务,比如1001代表调用用户当前的账户余额查询,1002代表他的信用积分查询,1003代表信用卡办卡进度等,然后可以通过这个模型给出的判定代码结果进行业务关联操作,这一步可以是实时的,也可以是准实时的,第例如银行需要跑风控大脑的这种长时操作可以直接异步mq处理,最后经过内容整合的模型直接可以给这个用户发短信反馈结果,实时的可以直接文字转语音反馈,第二部推理就是内容整合,比如查到了一堆结数据,需要用自然语言进行语音播报,那么需要结合二次推理将数据变为一段自然语言内容,也有的架构把两次推理在内部可以整合为一次推理的上下游模型两个部分,可以查看下面流程图
