前言:
yolo系列的论文阅读
论文阅读 || 深度学习之目标检测 重磅出击YOLOv3
论文阅读 || 深度学习之目标检测yolov2
论文阅读 || 深度学习之目标检测yolov1
该篇讲解的工程连接是:
tensorflow的yolov3:https://github.com/YunYang1994/tensorflow-yolov3
自己对该工程的解析博客:
YOLOv3 || 1. 使用自己的数据集训练yolov3
YOLOv3 || 2. dataset.py解析
YOLOv3 || 3. dataset.py的多进程改造
YOLOv3 || 4. yolov3.py 网络结构的搭建和loss的定义
YOLOv3 || 5. train.py
YOLOv3 || 6. anchorboxes的获取 kmeans.py
YOLOv3 || 7. yolov3的pb文件的测试
1 代码讲解
1.1 概述
该脚本主要定义了一个数据读取的类,结构如下:
class Dataset(object): """implement Dataset here""" def __init__(self, dataset_type): ... def __iter__(self): return self def __next__(self): ... def __len__(self): return self.num_batchs其中,核心部分为
def __next__(self):,是整个数据处理过程
- 创建存放 输入图片和label 的数组
- 读取训练集或验证集的数据信息(输入图片路径、bboxes)
- 数据增强:随机翻转、随机裁剪、随机平移、
- 将图片缩放和填充到target_shape(相同规则处理bboxes)
- 结合anchorbox等信息,将bboxes的信息,转化为神经网络训练的label
需要注意的是,读取文本得到的bboxes的格式为【左上角-右下角】信息,代码中会将bboxes信息转化为【center_x, center_y, height, width 】。
其中主要内容为
def __next__(self),具体定义为def __next__(self): with tf.device('/cpu:0'): self.train_input_size = random.choice(self.train_input_sizes) self.train_output_sizes = self.train_input_size // self.strides # 创建存放【输入图片】的数组 batch_image = np.zeros((self.batch_size, self.train_input_size, self.train_input_size, 3)) # 创建存放【label】的数组 batch_label_sbbox = np.zeros((self.batch_size, self.train_output_sizes[0], self.train_output_sizes[0], self.anchor_per_scale, 5 + self.num_classes)) batch_label_mbbox = np.zeros((self.batch_size, self.train_output_sizes[1], self.train_output_sizes[1], self.anchor_per_scale, 5 + self.num_classes)) batch_label_lbbox = np.zeros((self.batch_size, self.train_output_sizes[2], self.train_output_sizes[2], self.anchor_per_scale, 5 + self.num_classes)) # 创建存放 在3个尺度下,负责预测的bboxes batch_sbboxes = np.zeros((self.batch_size, self.max_bbox_per_scale, 4)) batch_mbboxes = np.zeros((self.batch_size, self.max_bbox_per_scale, 4)) batch_lbboxes = np.zeros((self.batch_size, self.max_bbox_per_scale, 4)) num = 0 # 批内的计数器 if self.batch_count < self.num_batchs: # 当【已读取的批数】小于【一轮总批数】 while num < self.batch_size: # 当【批内读取个数】小于【batch】 index = self.batch_count * self.batch_size + num # 【index】为一轮内已经读取的数据个数 if index >= self.num_samples: index -= self.num_samples # 如果【index】大于【数据总量】,将index置0 # 读取训练集或验证集的数据信息(输入图片路径、bboxes) annotation = self.annotations[index] # 数据增强:随机翻转、随机裁剪、随机平移、将图片缩放和填充到target_shape(相同规则处理bboxes) image, bboxes = self.parse_annotation(annotation) # 结合anchorbox等信息,将bboxes的信息,转化为神经网络训练的label label_sbbox, label_mbbox, label_lbbox, sbboxes, mbboxes, lbboxes = self.preprocess_true_boxes(bboxes) batch_image[num, :, :, :] = image batch_label_sbbox[num, :, :, :, :] = label_sbbox batch_label_mbbox[num, :, :, :, :] = label_mbbox batch_label_lbbox[num, :, :, :, :] = label_lbbox batch_sbboxes[num, :, :] = sbboxes batch_mbboxes[num, :, :] = mbboxes batch_lbboxes[num, :, :] = lbboxes num += 1 self.batch_count += 1 return batch_image, batch_label_sbbox, batch_label_mbbox, batch_label_lbbox, \ batch_sbboxes, batch_mbboxes, batch_lbboxes else: self.batch_count = 0 np.random.shuffle(self.annotations) raise StopIteration
1.2 读取数据集信息
def load_annotations()
- 标签的格式为:
voc_train.txt:
image_path x_min, y_min, x_max, y_max, class_id x_min, y_min ,…, class_id
例:
xxx/xxx.jpg 18.19,6.32,424.13,421.83,20 323.86,2.65,640.0,421.94,20
xxx/xxx.jpg 48,240,195,371,11 8,12,352,498,14
def load_annotations()读取该文件,以获取【[图片的路径】和【对应的bboxes】def load_annotations(self, dataset_type): with open(self.annot_path, 'r') as f: txt = f.readlines() annotations = [line.strip() for line in txt if len(line.strip().split()[1:]) != 0] np.random.shuffle(annotations) return annotations
1.3 数据增强
该工程使用的数据增强有3中方式:随机翻转、随机裁剪、随机平移
1.3.1 图片效果展示
原图:
随机翻转
随机裁剪(观察前后两张图,能看到图片被裁减了)
随机平移
1.3.2 具体实现代码
- 随机翻转
def random_horizontal_flip(self, image, bboxes): if random.random() < 0.5: _, w, _ = image.shape image = image[:, ::-1, :] bboxes[:, [0,2]] = w - bboxes[:, [2,0]] return image, bboxes
- 随机裁剪
def random_crop(self, image, bboxes): if random.random() < 0.5: h, w, _ = image.shape # print(image.shape) # 求图片中所有框的最小凸集的左上角和右下角 max_bbox = np.concatenate([np.min(bboxes[:, 0:2], axis=0), np.max(bboxes[:, 2:4], axis=0)], axis=-1) # 获取【最小凸集的左上角】与【图片的左上角】的距离 # 【最小凸集的右下角】与【图片的右下角】的距离 max_l_trans = max_bbox[0] max_u_trans = max_bbox[1] max_r_trans = w - max_bbox[2] max_d_trans = h - max_bbox[3] # 随机获取裁剪边框的边界值 crop_xmin = max(0, int(max_bbox[0] - random.uniform(0, max_l_trans))) crop_ymin = max(0, int(max_bbox[1] - random.uniform(0, max_u_trans))) crop_xmax = max(w, int(max_bbox[2] + random.uniform(0, max_r_trans))) crop_ymax = max(h, int(max_bbox[3] + random.uniform(0, max_d_trans))) # 对图像进行裁剪 image = image[crop_ymin : crop_ymax, crop_xmin : crop_xmax] bboxes[:, [0, 2]] = bboxes[:, [0, 2]] - crop_xmin bboxes[:, [1, 3]] = bboxes[:, [1, 3]] - crop_ymin return image, bboxes
- 随机平移
def random_translate(self, image, bboxes): if random.random() < 0.5: h, w, _ = image.shape # 求图片中所有框的最小凸集的左上角和右下角 max_bbox = np.concatenate([np.min(bboxes[:, 0:2], axis=0), np.max(bboxes[:, 2:4], axis=0)], axis=-1) # 获取【最小凸集的左上角】与【图片的左上角】的距离 # 【最小凸集的右下角】与【图片的右下角】的距离 max_l_trans = max_bbox[0] max_u_trans = max_bbox[1] max_r_trans = w - max_bbox[2] max_d_trans = h - max_bbox[3] # 对图像进行仿射变换,这里只用到了平移,未添加旋转。这里的(tx,ty)的取值需要注意 # 当(tx,ty) = (-(max_l_trans - 1),-(max_u_trans - 1)),目标的最小凸集的左上角与变换后的图片的左上角重合 # 当(tx,ty) = ((max_r_trans - 1), (max_d_trans - 1)),目标的最小凸集的右下角与变换后的图片的右下角重合 tx = random.uniform(-(max_l_trans - 1), (max_r_trans - 1)) ty = random.uniform(-(max_u_trans - 1), (max_d_trans - 1)) M = np.array([[1, 0, tx], [0, 1, ty]]) image = cv2.warpAffine(image, M, (w, h)) bboxes[:, [0, 2]] = bboxes[:, [0, 2]] + tx bboxes[:, [1, 3]] = bboxes[:, [1, 3]] + ty return image, bboxes
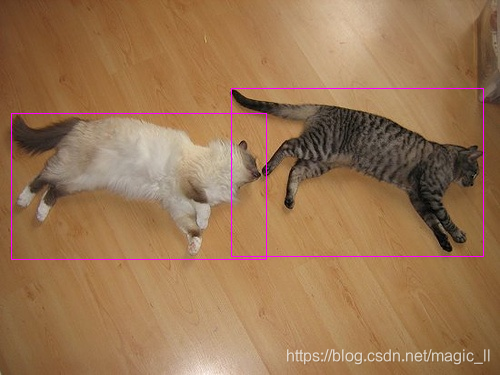



1.4 缩放和填充图片到target_shape
已知神经网络设定的输入数据的大小为target_shape。
def parse_annotation():将图片缩放并填充到target_size,并以相同缩放或填充规则处理bboxes,此时bboxes为【左上角-右下角】的形式。
具体缩放填充的方式为:
- 缩放:计算图片的长边与target_shape的比值,然后用该比值对原图进行缩放(这样会保持原图的长宽原有比例)
- 填充:然后将图片的短边填充到target_shape
def image_preporcess(image, target_size, gt_boxes=None): image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB).astype(np.float32) ih, iw = target_size h, w, _ = image.shape scale = min(iw/w, ih/h) # 获取长边与target_shape的比值 nw, nh = int(scale * w), int(scale * h) # 获取缩放后的图片的shape image_resized = cv2.resize(image, (nw, nh)) # 缩放图片 image_paded = np.full(shape=[ih, iw, 3], fill_value=128.0) # 创建个target_shape大小的图片,并用128填充 dw, dh = (iw - nw) // 2, (ih-nh) // 2 image_paded[dh:nh+dh, dw:nw+dw, :] = image_resized # 将缩放后的图片放在image_paded的中间位置 image_paded = image_paded / 255. # 将图片除以255,进行归一化 if gt_boxes is None: return image_paded else: # 将缩放和填充的操作,应用到bboxes上 gt_boxes[:, [0, 2]] = gt_boxes[:, [0, 2]] * scale + dw gt_boxes[:, [1, 3]] = gt_boxes[:, [1, 3]] * scale + dh return image_paded, gt_boxes
1.5 制作神经网络所需的label
def preprocess_true_boxes()该函数返回神经网络的标签,一个尺度下的输出标签的shape为 (batch_size, output_size, output_size, 3, 5+num_class)。其中,3:表示一个grid cell 使用3个anchorbox;5+num_class:4维的位置信息,1维的置信度,num_class是类别的onehot形式。
- yolov3有3个尺度的输出模块,分别对输入大小进行了8、16、32倍的降采样。每个尺度下有3个anchorbox进行预测。
- 分别在3个输出尺度下,计算【输出尺度下的anchor_boxes数值】和【缩小的真实框】的iou。
- 当iou>0.3时,将【真实box-输入尺度上的数值,置信度,分类的onehot】保存在对用anchorbox负责维度项,否则对应label位置数值为0。
当所有的iou都小于0.3时,选择最大iou的【真实box-输入尺度上的数值,置信度,分类的onehot】保存到相应位置。
def preprocess_true_boxes(self, bboxes): # label:保存着神经网络的标签 label = [np.zeros((self.train_output_sizes[i], self.train_output_sizes[i], self.anchor_per_scale, 5 + self.num_classes)) for i in range(3)] # bboxes_xywh: 对于每个输出尺度,如果有进行预测真实框,就将所有的bbox_xywh信息放入bboxes_xywh bboxes_xywh = [np.zeros((self.max_bbox_per_scale, 4)) for _ in range(3)] bbox_count = np.zeros((3,)) for bbox in bboxes: # 框的【左上角右下角】坐标信息 bbox_coor = bbox[:4] # 框的分类信息 bbox_class_ind = bbox[4] # 框的标签向量中的分类信息的onehot形式 onehot = np.zeros(self.num_classes, dtype=np.float) onehot[bbox_class_ind] = 1.0 # 对onehot进行smooth平滑,减小过拟合,增加泛化性 uniform_distribution = np.full(self.num_classes, 1.0 / self.num_classes) deta = 0.01 smooth_onehot = onehot * (1 - deta) + deta * uniform_distribution # 将真实框bboxes,从【左上角右下角】的形式 转换为(x,y,w,h)形式 bbox_xywh = np.concatenate([(bbox_coor[2:] + bbox_coor[:2]) * 0.5, bbox_coor[2:] - bbox_coor[:2]], axis=-1) # 将target_size下的物体box,缩小到3个输出尺度下的box值 bbox_xywh_scaled = 1.0 * bbox_xywh[np.newaxis, :] / self.strides[:, np.newaxis] iou = [] exist_positive = False # 在3个输出尺度下迭代处理 # 这里要加强理解numpy的广播操作 for i in range(3): anchors_xywh = np.zeros((self.anchor_per_scale, 4)) anchors_xywh[:, 0:2] = np.floor(bbox_xywh_scaled[i, 0:2]).astype(np.int32) + 0.5 anchors_xywh[:, 2:4] = self.anchors[i] iou_scale = self.bbox_iou(bbox_xywh_scaled[i][np.newaxis, :], anchors_xywh) iou.append(iou_scale) iou_mask = iou_scale > 0.3 if np.any(iou_mask): xind, yind = np.floor(bbox_xywh_scaled[i, 0:2]).astype(np.int32) # 这里的iou_mask 的使用,当iou>0.3的时候进行赋值 label[i][yind, xind, iou_mask, :] = 0 label[i][yind, xind, iou_mask, 0:4] = bbox_xywh label[i][yind, xind, iou_mask, 4:5] = 1.0 label[i][yind, xind, iou_mask, 5:] = smooth_onehot bbox_ind = int(bbox_count[i] % self.max_bbox_per_scale) bboxes_xywh[i][bbox_ind, :4] = bbox_xywh bbox_count[i] += 1 exist_positive = True # 如果所有的真实框与anchorbox的iou<0.3,选择最大的iou的真实框进行保存 if not exist_positive: best_anchor_ind = np.argmax(np.array(iou).reshape(-1), axis=-1) best_detect = int(best_anchor_ind / self.anchor_per_scale) best_anchor = int(best_anchor_ind % self.anchor_per_scale) xind, yind = np.floor(bbox_xywh_scaled[best_detect, 0:2]).astype(np.int32) label[best_detect][yind, xind, best_anchor, :] = 0 label[best_detect][yind, xind, best_anchor, 0:4] = bbox_xywh label[best_detect][yind, xind, best_anchor, 4:5] = 1.0 label[best_detect][yind, xind, best_anchor, 5:] = smooth_onehot bbox_ind = int(bbox_count[best_detect] % self.max_bbox_per_scale) bboxes_xywh[best_detect][bbox_ind, :4] = bbox_xywh bbox_count[best_detect] += 1 label_sbbox, label_mbbox, label_lbbox = label sbboxes, mbboxes, lbboxes = bboxes_xywh return label_sbbox, label_mbbox, label_lbbox, sbboxes, mbboxes, lbboxes