描述ASN.1编码规则的标准
ITU-T Rec. X.690 | ISO/IEC 8825-1 (BER, CER and DER)
ITU-T Rec. X.691 | ISO/IEC 8825-2 (PER)
ITU-T Rec. X.692 | ISO/IEC 8825-3 (ECN)
ITU-T Rec. X.693 | ISO/IEC 8825-4 (XER)
一.BER编码规则
描述了如何将ASN.1 类型的值编码成字节串的方法。BER的语法传输格式一直是TLV三元组<Type, Length,Value>
- tag(标志域): 指明数据类型,占用一个字节常见的类型有
#define BER_TYPE_BOOLEAN 0x01
#define BER_TYPE_INTEGER 0x02
#define BER_TYPE_BIT_STRING 0x03
#define BER_TYPE_OCTET_STRING 0x04
#define BER_TYPE_NULL 0x05
#define BER_TYPE_OID 0x06
#define BER_TYPE_SEQUENCE 0x30
#define BER_TYPE_COUNTER 0x41
#define BER_TYPE_GAUGE 0x42
#define BER_TYPE_TIME_TICKS 0x43
#define BER_TYPE_NO_SUCH_OBJECT 0x80
#define BER_TYPE_NO_SUCH_INSTANCE 0x81
#define BER_TYPE_END_OF_MIB_VIEW 0x82
#define BER_TYPE_SNMP_GET 0xA0
#define BER_TYPE_SNMP_GETNEXT 0xA1
#define BER_TYPE_SNMP_RESPONSE 0xA2
#define BER_TYPE_SNMP_SET 0xA3
#define BER_TYPE_SNMP_GETBULK 0xA5
#define BER_TYPE_SNMP_INFORM 0xA6
#define BER_TYPE_SNMP_TRAP 0xA7
#define BER_TYPE_SNMP_REPORT 0xA8
- 长度域(length):指明值域的长度,长度不等,一般为一到三个字节。其格式可分为短格式(后面的值域长度<=127),长格式.
(1)定长方式

length=30 表示为1E(16进制),30长度域为 0001 1110 没有超过127;
- 长格式 :表示方法为1(bit)K(7bit)K个八位长度(K Byte)

length = 169 转换为 81 A9(169长度超过127,长度域为1000 0001 1010 1001;169是后8位的值,前8位的第一个1表示这是一个长格式的表示方法,前8位的后7位表示后面有多少个字节表示针对的长度000 0001后面有一个字节表示真正的长度 1010 1001是表示长度为169)
length=1500=>82 05 DC(1000 0010 0000 0101 1101 1100,先看第一个字节,表示长格式,后面有2 个字节表示长度,这两个字节是0000 0101 1101 1100 表示1500)
(2).不定长方式
Length所在八位组固定编码为0x80,但在Value编码结束后以两个0x00结尾。这种方式使得可以在编码没有完全结束的情况下,可以先发送部分消息给对方。
Length所在八位组固定编码为0x80,但在Value编码结束后以两个0x00结尾。这种方式使得可以在编码没有完全结束的情况下,可以先发送部分消息给对方。

-
值域(value)
-
整型Integer的编码 integer::=0x02 length{byte} (表示重复),最高位代表符号位,去掉多余的0。对于正数,如果最高比特位为0则直接编码;如果为1,则在最高比特位之前增加一个全0的八位组。
-
最高位为0:
0BBBBBBB -
最高位为1:
00000000|1BBBBBBB
-
- 例: 对于负数,先取绝对值进行编码,再取反,最后加1
1500=>02 02 05 DC
40000=>02 03 00 9C 40
-129=>129=>0000 0000 1000 0001->1111 1111 0111 1110 ->(加1)->FF 7F 最终为02 02 FF 7F
-
布尔值的编码由1个字节组成。FALSE为00; TRUE为FF。
- TRUE的编码: 01 01 FF
- FALSE 的编码: 01 01 00
-
字符串类型的编码 string::=0x04 length{byte}* 例如:04 06 70 75 62 6c 69 63表示字符串public
-
位串(BITSTRING)类型 :编码规则:位串的第一位放到第一个负载字节的第8位;位串的第二位放到第一个负载字节的第7位; 依此类推.填充满第一个负载字节,就继续填充第二个负载字节.如果最后一个负载字节未被填充满,空的位用0来填充, 0的个数存放到头部用来表示填充数据的那个字节里.
例如:
ASN定义如下:
A ::= BIT STRING {a(0),b(1),c(2),d(3),e(4),f(5),g(5),h(6),i(7),j(8),k(9),l(10)} (SIZE(16))
位串赋值为a,e,f,g,i,l
位串{1,0,0,0,1,1,1,0,1,0,0,1}
开始填充负载字节.第一个字节填充后为10001110= 0x8E; 第二个字节填充后为10010000 = 0x90, 低位4个0为填充的空位.则,负载为2个字节加上表示填充0个数的一个字节0x04总共3个字节.则完整的编码为:0x03 03 04 8E 90.
-
空类型的编码 null::=0x05 0x00
-
对象标识ObjectID(oid)编码 SNMP服务器维护的所有管理信息库(MIB)对象采用ObjectID表示,其编码规则如下:objectID::=0x06 length {subidentifier}*
(1) subidentifier::= {leadingbyte}* lastbyte
(2) leadingbyte::=1 7bitvalue
(3) lastbyte::=0 7bitvalue
(4) 首两个ID被合并为一个字节X*40+Y
虽然规则很多,但由于大多数子对象标识在0~127,只需按规则(1)、(4)即可;当子对象标识大于127,则按规则(2)、(3)、将其分解为多个字节,最后一个字节的高位为0,其余字节的高位为1
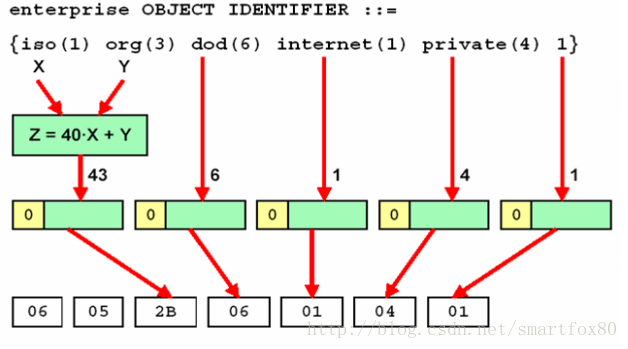
如:1.3.6.1.810.1,根据规则(5),首两个子对象标识1.3被合并为2B(1 *40 +3=40+3=43); 子对象标识810超过127,根据规则(2)、(3)将其拆分为两个字节86 2A (810=11 0010 1010==>1000 0110 0010 1010);
整个MIB被编码为:0x06 0x06 0x2b 0x06 0x01 0x86 0x2a 0x01。
如:1.2.840.113549 最终编码如下:06 06 2a 86 48 86 f7 0d
-
首两个ID被合并为一个字节X*40+Y
-
每个字首先被分割为最少数量的没有头零数字的7位数字.这些数字以big-endian格式进行组织,并且一个接一个地组合成字节.
举例: 30331 = 1* 128^2 + 108 * 128 + 123 分割成7位数字(0x80)后为{1,108,123}
- 除了编码的最后一个字节外,其他所有字节的最高位(位8)都为1.
设置最高位后变成{129,236,123}.如果该字只有一个7位数字,那么最高为0
MD5 OID的编码:
1. 将1.2.840.113549.2.5转换成字数组 {42, 840, 113549, 2, 5}.
2. 然后将每个字分割为带有最高位的7位数字,{{0x2A},{0x86,0x48},{0x86,0xF7,0x0D},{0x02},{0x05}}
3. 最后完整的编码为 0x06 08 2A 86 48 86 F7 0D 02 05.
- sequence组合类型的编码 sequence::=0x30 length{asndata}*
如:30 05 02 01 10 05 00表示一个sequence结构,内含两个成员,其中一个为整型16,另一个为空类型(NULL)。
例:考虑如下序列
User ::== SEQUENCE{
ID INTEGER,
Active BOOLEAN
}
当取值为{32,TRUE}时,编码为 0x30 06 02 01 20 01 01 FF 在ASN.1文档里,使用空格来表示编码的属性.
0x30 06
02 01 20
01 01 FF
二.CER与DER
CER与DER(Canonical and Distinguished Encoding Rules)
1 更多限制规则的需求
在X.400 和X.500中应用接力传递消息,会使用到X.509数字签名(Digital Signature),其过程如下图所示:
Figure 3-25 接力传递消息
发送方发送v的编码结果c1(v),同时发送其数字签名σ(c1(v));中继收到消息后,解码得到v,保留签名,发送时重新编码发送结果为c2(v);接收方收到结果后,解码得到v,同时对c2(v)计算数字签名σ(c2(v)),通过比较σ(c1(v))与σ(c2(v))是否相同来确定消息内容是否被修改。
在上面的过程中,如果直接使用BER编码规则,比如存在BOOLEAN类型的值“TRUE”,则因为两次编码过程c1和c2可能对TRUE的编码结果不同,从而导致数字签名比较不通过。
通常,我们称不给因具体实现和编码过程动态因素留出自由发挥余地的编码规则为规范编码规则(Canonical)。从BER中派生出两种规范编码规则,分别为CER(Canonical Encoding Rules)和DER(Distinguished Encoding Rules)。这两种规则是BER规范的特例,因此BER解码器能解码这两种规则的传输语法,反之则不然。
这两套编码规则为抽象值和他们的编码提供了一一对应的关系。应用这个属性,接收应用层可以不用了解具体结构和类型,就能比较接收的八位组流。
这两套规则的主要区别在于:CER针对不定长格式,而DER针对定长格式。因此CER常应用在需要传输大量数据的应用的。
Table 3-1 CER、DER对BER的限制
| CER | DER |
| 长度域Length L | |
| primitive类型采用定长形式(有长、短两种情况); constructed类型采用不定长形式。 | 不管是primitive还是constructed类型,L都是定长形式的。 |
| BOOLEAN | |
| 值“TRUE”的编码为:11111111。 | |
| REAL | |
| if the base component equals 10, a real value is encoded as a character string of NR3 format without spaces [ISO6093]; it has no “+" sign if the number is positive; the dot is the decimal separator; the mantissa must not begin nor end with zeros; it is followed by a dot and the E character; the exponent must not use the “+" sign nor begin with a 0 but for the null exponent denoted “+0" | |
|
| [X.509] forbids base-10-real values in the Directory applications |
| if base = 2, a real value is binary-encoded with mantissa M and exponent E so that the mantissa equals 0 or is an odd number; the mantissa and the exponent are encoded on the minimum number of octets; the scale factor F equals 0 | |
| BIT STRING | |
| 最后一个八位组中未使用的比特为0; 如果包含一个命名列表,最后的0比特不编码;如果该类型有SIZE约束,则按照需要补充并且编码最后的0比特;如果取值为空,则长度为1,值为全0的八位组。 | |
| BIT STRING或者OCTET STRING或者CHARACTER STRING | |
| 如果小于1000个八位组,则采用primitive形式; 否则采用constructed形式;除最后一个外,其余子部分,每个为1000个八位组。 | 一律采用primitive形式。 |
| GeneralString | |
| escape sequences must only be used when the requested character set differs from the usual C0, C1 and G sets (see also the defect report http://www.furniss.co.uk/maint/asn/dr8825 1 005.htm) | |
| GeneralizedTime或者UTCTime | |
| 秒不是必须的;秒片段中0有意义;如果没有秒片段,就没有小数点; 必须同步为Universal Time(即以z开头); GeneralizedTime类型,小数点必须使用。 | |
| SEQUENCE或者SET | |
| 各个成员等于其未编码的值。 | |
| SET | |
| 成员按照其Tag升序编码;如果模块声明包含AUTOMATIC TAGS,则按照描述的顺序编码; | |
| 当成员是一个无Tag的CHOICE,它要用其选项中最小Tag来参加排序(静态顺序) | 当成员是一个无Tag的CHOICE,它要用被选择项的Tag来参加培训(动态顺序) |
| 为了避免这种排序步骤,推荐用SEQUENCE替代SET。 | |
| SET OF | |
| 按照编码的升序排列:这些编码作为OCTET STRING进行比较,比较需要的话,后面补充空八位组; 为了避免这种动态的排序,推荐用SEQUENCE OF替代SET OF。 | |
| EXTERNAL、EMBEDDED PDV或者CHARACTER STRING | |
| 只有当抽象语法包含子类型约束避免传递表示上、下文标识的情况下,才能接力传递,如: EMBEDDED PDV (WITH COMPONENTS {..., identification (WITH COMPONENTS { ..., presentation-context-id ABSENT, context-negotiation ABSENT })}) 和字符抽象语法相关联的字符传输语法注册在{iso standard 10646 level-1(1)}都是规范的;此外,符合注册为level-2(2)或者level-3(3)抽象语法的值也能接力传递。 | |
2 CER
CER比DER出现晚,它的Object Identifier为:{joint-iso-itu-t asn(1) ber-derived(2) canonical-encoding(0)},Object Description为:”Canonical encoding of a single ASN.1 type”。
CER十分适合使用潜在重要编码的应用中,如ODA(Office Document Architecture)。对编码器,如果编码数据比可用内存空间大,就有必要使用不定长方式,在完成全部编码前开始发送。因为很少有编译器能产生这种形式的编码,所以CER在实际应用中比较少,这也是为什么DER作为缺省规范规则的原因。
3 DER
DER的Object Identifier为:{joint-iso-itu-t asn(1) ber-derived(2) distinguished-encoding(1)},Object Description为:”Distinguished encoding of a single ASN.1 type”。
DER适合安全数据传输,特别是数字签名方面。在电子商务方面有独特的优势。适合传输平均大小的数据。因为采用定长编码,所以要求编码器有足够的内存空间。
三.PER
BER编码因其在大小上的开销过大而受人诟病,和真实编码数据相比,平均需要增加50%的额外数据。正式这个原因推动了PER(Packed Encoding Rules)的诞生。相同协议,PER编码与BER相比在大小上至少有40%到60%的改进。因而在VoIP、视频电话、多媒体以及3G等需要高速数据传输的领域有广泛应用。
1 基本规则
PER编码规则的黄金定律为:“obtain the most compact encoding using encoding rules as simple as possible”。
与BER中递归使用三元组TLV<Tag, Length, Value>不同,PER的格式为:’[P][L][V]’ <optional Preamble, optional Length, optional Value>,这里PLV中每个域都不再是八位组串而是比特串。
因为Length可以省略(甚至Value也可以省略),那么就不能从编码中得知边界,所以解码器必须知道抽象描述才能正确解码。PER编码中没有Tag域,因此PER不再缺省支持扩展,必须明确在描述中添加扩展符。
只有当长度没有被SIZE固定或者数据长度很重要的情况下,才对Length进行编码;对SEQUENCE或者SET类型的值编码时,汇总前面增加个bitmap来标识可选成员是否出现;同样,在编码CHOICE的被选择成员前,会增加一个序号指示其位置。
和BER相比,PER使得编解码器处理时间相对要少(但达不到两倍的处理速度),传输速度更快。
2 四种变形
PER编码规则可以分为基本的(Basic)和规范的(Canonical)两类,每一类又可以分为对齐(Aligned)和不对齐(Unaligned)两种。规范形式的优势在CER和DER中已经讨论过了,主要用在中继接力系统和安全系统等使用数字签名的场合。在基本形式中,一个抽象值可能有多个PER编码。但是,在有限测试后,我们知道基本形式编码器要比规范形式编码器速度更快。
对齐方式下,为了保持八位组对齐,可以增加值为0的比特。不对齐方式则编码更为紧凑,但是在编解码时需要花费更多的处理时间。不对齐方式下,不会检查八位组的对齐情况,只在整个数据编码结束后,才进行补位。
注意对齐和不对齐两种方式不能互通,即只能用同种的解码器解码同种编码器编码后的码流。在四种变形中,基本不对齐方式编码是最紧凑的。按照紧凑性降低的顺序,后续依次为:规范不对齐方式,基本对齐方式和规范对齐方式。
在表示层传输上下文协商中,我们需要用Object Identifier指明具体采用的是哪种变形。具体值,请参考第二章中Object Identifier注册树。
3 PER可见子类型约束
为了最大限度的压缩编码,PER需要依赖ASN.1描述中的子类型约束。约束增加的越具体,PER越能得到更优化的编码。而且PER会使用到的约束都是经常使用的约束,这样也使得PER编译器容易实现。此外,这些约束都是编译器在编译过程中“静态”使用的,不会增加实际编解码过程处理时间。
我们称这类约束为PER可见约束(PER-Visible Constraints),它们只包含下表所列:
Table 3-3 PER可见约束
| 类型 | PER可见约束 |
| BOOLEAN | 无 |
| NULL | 无 |
| INTEGER | 单值约束、值域约束、类型包含约束、约束组合、约束扩展 |
| ENUMERATED | 无 |
| REAL | 无 |
| BIT STRING、OCTET STRING | SIZE约束、约束组合、约束扩展 |
| OBJECT IDENTIFIER | 无 |
| NumericString、PrintableString、VisibleString、ISO646String、 IA5String、UniversalString、 BMPString | FROM约束、SIZE约束、类型包含约束、约束组合、SIZE约束中的扩展 |
| not-known-multiplier character string types | 无 |
| GeneralizedTime、UTCTime、ObjectDescriptor | 无 |
| open types | 无 |
| SEQUENCE、SET | 无 |
| SEQUENCE OF、SET OF | SIZE、约束组合、约束扩展 |
| CHOICE | 无 |
| EXTERNAL | 无 |
| EMBEDDED PDV、CHARACTER STRING | WITH COMPONENTS |
open types指引用到一个类型域、一个可变类型的值域、或者一个可变类型值集合域。即引用到信息对象类中的类型。
不在上表中的,都不是PER可见约束, PER编译器也就不做相应优化。
4 数的编码
我们考察一个非负数的四种形式的编码,因为自然数常出现在长度域L、bitmap的大小、CHOICE中的序号以及INTEGER类型边界中。
对于INTEGER类型,PER可见约束之一是值域约束。对于有值域约束(bmin..bmax)的值n,如果下边界bmin足够大,PER编码n- bmin的代价就更小。如下:
Figure 3-26 有约束自然数的基本编码规则
I. 有约束数编码
有约束指值域的上、下边界都有限。如果d=1,即只有一个值,则收、发双方都知道,那么就没有编码的必要。
在对齐方式下:∞
l 当2≤d≤255,n- bmin的编码占用log2d个比特。这些比特添加在待发送比特域之后,不进行八位组对齐,不编码L;
l 当d=256,n- bmin的编码占用一个八位组,不编码L;
l 当257≤d≤65,536,n- bmin的编码占用两个八位组,不编码L;
l 当65,537≤d,n- bmin的编码占用log256d个八位组,并且在前面增加L的编码。
在不对齐方式下:
n- bmin的编码占用log2d个比特,不编码L。
II. 半约束数编码
半约束指值域没有上边界(上边界为+∞)。
n- bmin的编码占用log256d个八位组,并且在前面增加L的编码。
III. 无约束数编码
无约束指值域没有下边界(即使存在上边界)。
按照BER中整数的编码方式编码,并且在前面增加L的编码。
IV. 常见小自然数编码
这种情况经常出现在对表征SEQUENCE、SET类型可选成员的Bitmap长度进行编码时;或者CHOICE类型序号编码时。这种长度相当小,但是却没有一种限定。
l 当0≤n≤63时,n以6个比特编码,并且在前面增加一个0比特(八位组不对齐):
l 当64≤n时,n以半约束数方式编码,下边界为0,并且在前面增加一个1比特:
5 长度域编码
与BER中长度域表征编码的八位组数不同,在PER的长度域出现下,如果编码为比特串则表征比特位数;如果编码为八位组串(OCTET STRING和open类型)则表征八位组个数;如果编码为known-multiplier character string则表征字符数;如果是SEQUENCE OF或者SET OF则表征成员个数。
每当ASN.1描述中 对类型通过(SIZE(lmin..lmax))做大小限定时(lmax可以是+∞),长度l的值要按照3.3.4 中的规则编码。作为特例,当lmin =lmax≤65,535时,长度不需要发送,因为解码器知道该长度。
对齐方式下:
l 当l是一个bitmap的长度,l-1作为常见小自然数编码;
l 当lmax≤65,535,l作为有约束的数编码(约束为(lmin..lmax));
l 当65,535≤lmax,或者lmax是无穷大:
- 当l≤127,l以一个八位组编码(八位组对齐),最高比特位为0;
-当128≤l≤16,383,l以两个八位组编码(八位组对齐),最高两个比特位为10;
-当16,384≤l,整个编码以f*16K为单位分割(f取值为1,2,3或者4)。除最后的片段外,其余每段,长度都以一个八位组编码,最高两个比特位为11。如果编码恰好时16K的整倍数,则在最后补充一个全空的八位组;否则最后一个片段按照前两条进行编码。例如占147,457个单元的编码可以为:
不对齐方式下:
l 当l是一个bitmap的长度,l-1作为常见小自然数编码;
l 当lmax≤65,535,l-lmin以占用log2(lmin-lmax+1)个比特编码;
l 当65,534≤lmax-lmin,或者上边界为无穷大:
-当l≤127,l以八比特编码,最高比特位为0;
-当128≤l≤16,383,l以十六比特编码,最高两个比特位为10;
-当16,384≤l,编码方式域对齐类似,但是不是八位组对齐的。
当类型有可扩展的SIZE约束,并且待发送值不在该约束扩展的根部分,则长度l作为半约束数编码(即lmin=0, lmax =+∞)。
6 各类型编码
I. BOOLEAN
以一个比特编码,1为TRUE,0为FLASE。
直接编码,不编码长度,也不做八位组对齐。
II. NULL
不编码。
如果NULL是作为CHOICE的一个选项或者SEQUENCE、SET可选成员值出现,则已经有bitmap能表征。
III. INTEGER
假设INTEGER类型拥有有效的值域范围(bmin..bmax),当描述中INTEGER类型有至少一个可扩展的PER可见约束(PER-Visible Constraint),在编码时会在前面增加一个前导(Preamble)比特(不考虑八位组是否对齐)。当INTEGER类型的值在扩展的根部分,该比特为0;否则该比特为1。
在编码n- bmin过程中,如果需要编码L(前面讨论过),则增加长度域L的编码。长度L的约束为(1..lmax),其中lmax =log2bmax。
如果待发送值n属于约束的扩展部分,则长度按照无约束自然数方式编码,如值:
v INTEGER (3..6, ..., 8..10) ::= 8
的对齐方式编码为:
IV. ENUMERATED
如果该ENUMERATED类型不是可扩展的,则先按照数值大小做升序排列,然后以0为起点,步长为1给每个成员编上序号。对该类型的值编码时,只将序号以值域约束(0..Indexmax)编码。如:
v ENUMERATED {orange(56), green(-2), red(2476)} ::= orange
的PER编码为“01”(因为此时为Indexmax 2,需要两个比特)。
如果该ENUMERATED类型是可扩展的,那么要在编码前增加一个前导(Preamble)比特。当值在扩展的根部分时,该比特为0;否则该比特为1。同时对扩展部分的成员重新进行编号,起点仍为0,步长为1。编码时对值在根部分的情况,就和该类型是不可扩展时一样;值在扩展部分的情况,对序号按照自然数方式编码。如:
v1 ENUMERATED {orange(56), green(-2), red(2476), …, yellow}
::= orange
的PER编码仍然为“01”;而
v2 ENUMERATED {orange(56), green(-2), red(2476), …, yellow, purple}
::= yellow
的PER编码则为“10000000”。
V. REAL
对值的编码规则和CER或者DER相同(而且是八位组对齐的),并且在前面增加长度域L的编码。这里L表征的是八位组数。
VI. BITSTRING
如果该BITSTRING类型有可扩展的PER可见大小约束(PER-Visible Size Constraint),那么要在编码前增加一个前导(Preamble)比特。当值在扩展的根部分时,该比特为0;否则该比特为1。
对于有大小约束(SIZE(lmin..lmax))的BIT STRING类型:
l 当lmin=lmax≤16比特,不发送长度,直接编码(不是八位组对齐的);
l 当17≤lmin=lmax≤65,536比特,不发送长度,直接编码(在八位组对齐方式下是八位组对齐的);
l 当65,537≤lmin=lmax,长度按照3.3.5 中约定编码;而值按照需要进行分段;
l 当lmin≠lmax(或者没有有效的大小约束),长度按照3.3.5 中约定编码;而值按照需要进行分段。
如果BITSTRING类型包含一个命名位置列表,所有结尾的0比特都被去掉;此外,为了满足大小约束,可以增加或者删除结尾0比特来达到最小的长度。
VII. OCTET STRING
与BIT STRING规则相同,不过长度域L表征的是八位组的个数而不是比特数。
VIII. OBJECT IDENTIFIER
值的编码规则与BER相同,前面需要增加长度域L的编码。
IX. RELATIVE-OID
值的编码规则与BER相同,前面需要增加长度域L的编码。
X. 字符串与日期
首先描述known-multiplier字符串类型,如果这种类型是受约束的,带了一个形如(SIZE(lmin , lmax))的有效的size约束和一个形如(FROM("c1"|"c2"|...|"cn"))的有效的字符约束。如果FROM约束是可扩展的,则有效的字符约束就包括了父类型包含的所有的字符。
如果SIZE约束是可扩展的,则在bit-field上加一个比特。如果串长属于扩展根的范围内,则该比特等于0,否则该比特等于1。记住,如果FROM约束中包含了可扩展的符号,则该约束对于PER不可见,即不会改变扩展比特的取值。
PER压缩known-multiplier字符串类是基于有效的字符约束的。假设n是有效字符约束中字符的个数,b = [log2 n], c = [log2 b],则每个字符在aligned变体中被编码成B = 2 c个比特(大于b的最小的2的次方),而在unaligned变体中被编码成B = b 个比特。设vmin和vmax分别是("c1"|"c2"|...|"cn")对应的最小和最大的字符值。
如果vmax≤ 2B -1, 即所有的系列里的("c1"|"c2"|...|"cn")都可以用B个比特来编码,串中的每个字符都可以作为在区间(vmin .. vmax)之间的一个整数来编码。这就避免了给字符重新排序赋值。否则,字符序列("c1"|"c2"|...|"cn")按照标准[ISO646] 或 [ISO10646-1]中定义的顺序加索引,索引从0开始,每次加1。这个新的索引号以B个比特来编码和发送。
如果字符串的长度是固定的(lmin = lmax)并且小于64K,则长度字段L就不需要了,在aligned变体情况下,只有当 B ×lmax≥ 17 时才需要octet - aligned。.
如果字符串的长度不固定或者长度虽然固定但大于64K,则长度字段按照章节3.2 编码,然后附着到码流中(在在aligned变体情况下,只有当 B ×lmax≥ 17 时才需octet - aligned)。
例如,字符串
v IA5String (FROM ("ACGT")^SIZE(3)) ::= "TAG"
被编码成 11 00 10 。而字符串
v IA5String ::= "TAG"
在unaligned变体情况下被编成(注:IA5String的vmin和vmax分别为0和127):
在aligned变体情况下被编成(下面的方框表示从整数个字节开始)
日期类型 GerneralizedTime和UTCTime 的编码方式在basic PER情况下与BER相同,在canonical PER情况下与DER相同。
对于不属于known-multiplier的字符串类型,所有的约束对PER都是不可见的。它们的编码方式在basic PER情况下与BER相同,在canonical PER情况下与DER相同。长度字段L作为一个无约束整数加在前面。
对于known-multiplier字符串类型在定义中最小和最大的字符值请参考下表:
Table 3-4 known-multiplier字符串的最小最大字符值
| 类型 | vmin | vmax |
| NumericString | 32 | 57 |
| PrintableString | 32 | 122 |
| VisibleString | 32 | 126 |
| IA5String | 0 | 127 |
| BMPString | 0 | 216 -1 |
| UniversalString | 0 | 232 -1 |
XI. Open类型
一个open类型的值实际上是一个任意类型的值,这个类型对于发送方和接收方而言都是已知的。因此这个值就被编成它的有效类型而没有类型的指示。通常情况下,这个值的类型已经在前面发送过了,解码器会存储类型到关联表中,而后在收到open类型能够的值后根据关联表就可以查询到对应的类型进行解码。
相应的值编码后,不是整数个字节的情况补充值为'0'的比特位以便使该码流为整数个字节(假设为n)。并在头部加上长度字段L表示字节数n,L作为无约束整数进行编码。
XII. SEQUENCE
首先,如果有COMPONENTS OF语句,则由相应的类型进行替换。
如果SEQUENCE类型是可扩展的,则在编码的头部加上一个比特的bit-field,如果SEQUENCE的取值中有属于扩展附加部分的成员,则该比特等于1,否则等于0。
如果SEQUENCE的定义中在扩展根部(extension root)有"n"个成员被置为OPTIONAL或DEFAULT,则在编码头部再添加"n"个比特的bit-field,该bit-field从第一个bit开始,依次指示被标记为OPTIONAL或DEFAULT的成员是否出现。如果为1,则该成员出现,否则没有出现。如果“n”小于64K,则这个 bit-field 应该直接添到码流中。如果"n"大于等于64K, 按照前面提到的处理方法把“n”个bit的bit-field分段并添加到域序列中,前面的长度字段L就作为一个有约束的整数编码,而约束的上限和下限都等于n。
以上为导言(preamble)部分,导言之后是各成员类型的编码,依次出现。
在canonical PER中,对于标记有DEFAULT的成员,如果要编码的值就是缺省值,那么这个成员的编码省略;在basic PER中,如果序列中标记为DEFAULT的成员是一个简单类型,当它的值为缺省值时,它的编码应省略。而对于结构化的成员(SEQUENCE, SET, SEQUENCE OF, SET OF, CHOICE) ,即使它的取值是缺省值时,是否被编码是由发送方来决定的。
如果类型是可扩展的但取值中没有出现扩展附加部分,则该SEQUENCE的值的编码已经结束。
如果类型是可扩展的并且取值中有p个扩展附加部分(双重方括号内的所有成员只当作一个附加扩展部分),则添加一个p个比特的bit-map,对应的比特取值为1则表示该扩展附加部分出现,否则就没有出现。为长度"p"的bit-map增加一个长度指示,编码方式为一个通常的小的非负整数的编码。
以后,依次出现的是各扩展附加部分的编码值。
扩展附加部分的编码方式如下:
l 如果该扩展附加部分是单个的成员,则作为open类型来编码,即包括长度字段和整数个字节的值字段。
l 如果该扩展附加部分是由双重方括号内的所有成员组成的,则该扩展附加部分的值作为open类型来编码。与上面不同的是:双重方括号内的所有成员的值被当成一个SEQUENCE类型的取值来编码,编码方式参见本节上段。
注意在SEQUENCE类型的值没有包括长度字段,因为根据扩展根部的可选成员对应的bit-map和扩展附加部分对应的bit-map使解码器推断出成员是否存在。
XIII. SET
SET类型的扩展根部(extension root)的成员是按照canonical order来排序的,具体法则如下:
1) 首先按标签类型排序,按照UNIVERSAL,APPLICATION,context-specific,PRIVATE四种类型依次排序,UNIVERSAL标签类型的元素在最前,PRIVATE标签类型的元素在最后;
2) 在标签类型内部,按照标签值的大小排序,小的在前,大的在后。
在排序过程中如果发现某个成员是没有标签的CHOICE类型,则该CHOICE类型的标签值就会等于其所有选项中标签的最小值。在CHOICE类型嵌套的情况下亦是如此。
如果SET类型是可扩展的且SET类型的值中有扩展附加部分,则扩展附加部分的排序按照其协议定义时的顺序,不做改动(因为在新增扩展附加部分时对应的标签必须符合canonical order)。
经过上述的排序后,SET类型的编码就按照SEQUENCE类型的编码。
XIV. SEQUENCE OF
显式PER限制仅仅对SEQUENCE OF类型的成员个数有效。
假设成员数目的上限为"ub",下限为"lb"。如果没有上限或者上限值ub大于等于64K,就认为ub不确定;如果没有下限,"lb"置为0。假设实际的SEQUENCE OF的成员数量为“n”,编码按如下规则进行:
1) 如果有size约束且该约束可扩展,则在码流上添加一个1比特的bit-field(不需要octet-aligned)。 如果元素的个数属于约束的根部则这个比特等于0,反之该比特等于1。在前一种情况下,调用节3.2为生成的编码增加一个半约束数的长度指示,长度值等于n。
2) 如果成员值的数目固定且小于64K,则没有长度指示,SEQUENCE OF的各成员的值的编码依次填充到生成的编码中去。
3) 其它情况,增加长度指示成员值的数目。如果"ub"存在,则长度指示作为约束数编码,否则作为半约束数类型的整数编码。
需要注意的是在给每个成员编码时,在aligned变体情况下需要octet-aligned。
XV. SET OF
在basic variant情况下,把每个SET类型的元素按顺序编码即可,而不需要调换顺序。而在canonical variant情况下需要先把各SET中的元素按canonical order进行排序再编码,并在必要的时候需要做一些调整,如加上一些'0' bit以形成整数个字节,或加上值为0的字节以使短部分和长的部分长度一致。
XVI. CHOICE
先给CHOICE的各个选项标上索引(index),过程如下:
1) 对于CHOICE类型的根部(root)的选项,先按照canonical order对各选项进行排序,然后给排序后的选项标上索引,第一个选择项索引为0,第二个为1,直至根部的最后一个。 如果嵌套了没有标签的CHOICE类型,则该类型的标签是其择项中的最小的那个标签。
2) 如果CHOICE类型是可扩展的,并且有扩展附加选项,则给扩展附加选项也分别标上索引,第一个扩展附加选项的索引为0,第二个为1,直至扩展部分的最后一个。(标索引之前不需要对这些选项进行排序,是因为在新增扩展附加选项时对应的标签必须符合canonical order)。
在索引标完后,就可以对CHOICE类型的值进行编码,过程如下:
1) 如果仅有一个选择项,如果选择了该选择项的话,不要对索引进行编码。
2) 如果CHOICE类型是可扩展的,则在码流上加一个比特的bit-field(不需要octet-aligned)。如果该值属于扩展附加选项,则 该比特等于1,否则等于0。
3) 如果没有扩展标记,或者有扩展标记但选项在CHOICE类型的根部,则选项的索引值就作为一个INTEGER来编码(约束为0..n,假设n为根部的最大索引值),然后是选项的值的编码。
4) 如果有扩展标记且选项是CHOICE类型的扩展附加选项,则该索引被当作一个通常的小的非负整数进行编码,其"lb"置为0。把选项的值当作open类型进行编码。
XVII. Tagged Type
因为PER不是隐式支持Tag的,所以一个有Tag类型的值按照该类型的编码规则进行编码。在ASN.1模块内,特定Tag上的限制要遵守;建议在模块头的声明中增加AUTOMATIC TAGS,这不会影响已有的限制。
XVIII. EXTERNAL
略。
XIX. INSTANCE OF
一个INSTANCE OF类型的值按照其等效SEQUENCE类型值进行编码。
XX. EMBEDDED PDV或者CHARACTER STRING
如果EMBEDDED PDV或者CHARACTER STRING类型有WITH COMPONENTS约束,该约束限制可选项syntaxes是两个预定义object identifier的序列(即对收、发双方抽象语法、传输语法都明确);或者限制成员identification选项为fixed,则PER编码中嵌入数据作为OCTET STRING类型编码。
如果成员identification没有按照前面两种方式之一约束,则这两种类型的值需要按照等效的SEQUENCE类型值进行编码。
XXI. Value Set
编码一个有值域Value Set约束类型的值时,值域被当作有该值域约束的类型看待。如值域:
Set1 INTEGER(1..20) ::= {1 | 5 | 7}
被等同作:
Set1 ::= INTEGER(1..20)(1|5|7)
XXII. Information Objects 与 Information Object Sets
信息对象和信息对象集合不编码。传输其中信息的方式,是在类型或者值中引用信息对象或者信息对象集合。编码时,按照所在值的编码规则进行编码。
7 一个完整例子
还是以BER中的例子,来看其对应的PER编码。
ASN.1描述:
MyHTTP DEFINITIONS AUTOMATIC TAGS ::=
BEGIN
GetRequest ::= SEQUENCE
{
header-only BOOLEAN,
lock BOOLEAN,
accept-types AcceptTypes,
url Url,
...
}
AcceptTypes ::= SET
{
standards BIT STRING {html(0), plain-text(1), gif(2),
jpeg(3)} (SIZE (4)) OPTIONAL,
others SEQUENCE OF VisibleString (SIZE (4))
OPTIONAL
}
Url ::= VisibleString (FROM ("a".."z"|"A".."Z"|"0".."9"|"./-_~%#"))
v GetRequest ::=
{
header-only TRUE,
lock FALSE,
accept-types { standards {html,plain-text} },
url "www.asn1.com"
}
END相应对齐方式的PER编码结果为:
不对齐方式的PER编码结果为:
四. 其它编码规则
1 LWER
Light Weight Encoding Rules (LWER),1985年有德国发起,1988年由法国继续推进。其目的是为了在BER基础上构造处更为轻量级编码规则,随着PER的出现和成熟,于1997年放弃。
2 BACnet
BACnet (Building Automation and Control Network)是由美国加热、冷冻、空调工程师协会(ASHRAE-American Society of Heating, Refrigerating and Air-conditioning Engineers)设计。用于在Internet上传输从分布在各地,监控集中加热、通风、空调或者烟雾报警器的控制设备来的数据。
现在BACnet编码规则,结合ECN(X.692, Encoding Control Rule),使得可以使用一个通用的工具来生成编解码规程。
BACnet编解码规则具体细节,可以访问网站:
http://www.bacnet.org
或者:
ftp://ftp.bacnet.org/Encoding.doc
3 OER
应用很少,略。
具体信息可以访问:http://www.viggen.com/ntcip/documents/oer.rtf
4 SER
SER(Signaling specific Encoding Rules)是由法电研发部(France Telecom R&D)和诺基亚(Nokia)联合开发的。其主要目的是想通过合适的编译器,为原本不是用ASN.1描述的协议,通过重新描述能自动生成编解码器。这类协议主要是在ASN.1出现之前就有的,如七号信令的协议,GSM接入协议等。
据悉,国内电信设备商H,基于同样目的也设计了类似编码规则。但和上述的工作原理有差异。
因专利保护关系,这些规则的详细内容不得而知。
5 XER
此外,自1999年后,ASN.1中引入了XML。相应的有了XER(XML Encoding Rules)。