参考博客:决策树实战篇之为自己配个隐形眼镜 (po主Jack-Cui,《——大部分内容转载自
参考书籍:《机器学习实战》——第三章3.4
《——决策树基础知识见前两篇 ,
摘要:本篇用一个预测隐形眼镜类型的例子讲述如何建树、可视化,并介绍了用sklearn构建决策树的代码
目录
1 数据处理
隐形眼镜数据集是非常著名的数据集,它包含很多患者眼部状态的观察条件以及医生推荐的隐形眼镜类型。隐形眼镜类型包括硬材质(hard)、软材质(soft)以及不适合佩戴隐形眼镜(no lenses)。给出一个数据集,使用决策树预测患者的隐形眼镜类型(共三类:hard/soft/no lenses)
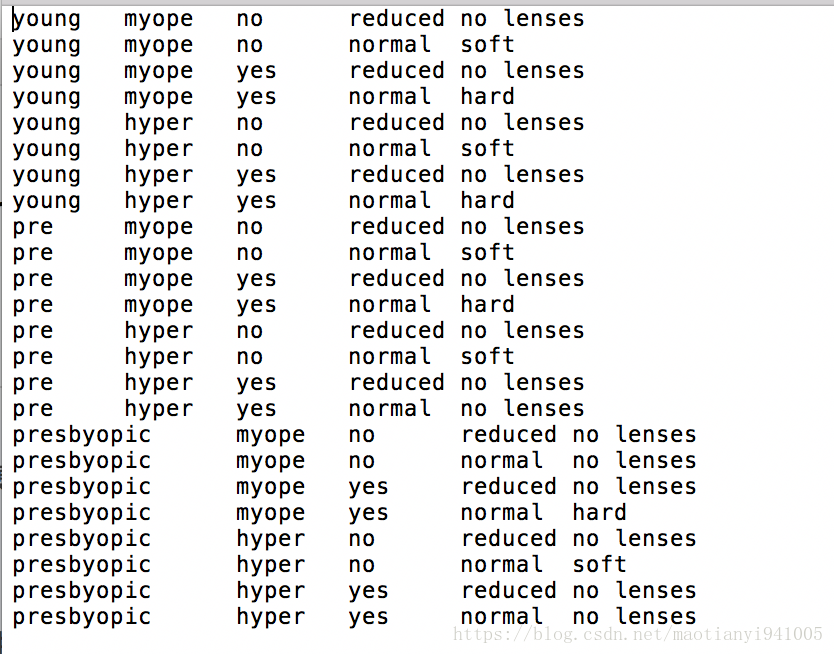
lenses.txt数据如下图,共24组数据,5列属性,第5列为隐形眼镜类型,即我们需要预测的分类。
数据labels为[age、prescript、astigmatic、tearRate、class]
即[年龄、症状,是否散光,眼泪数量,最终的分类标签]
'''创建数据集'''
def createDataSet():
fr = open('lenses.txt')
dataSet = [rl.strip().split('\t') for rl in fr.readlines()]
print dataSet
labels = ['age','prescript','astigmatic','tearRate'] #特征属性
return dataSet, labels #返回数据集和特征属性2 完整代码
#!/usr/bin/env python
#_*_coding:utf-8_*_
import numpy as np
import json
import operator
from math import log
'''创建数据集'''
def createDataSet():
fr = open('lenses.txt')
dataSet = [rl.strip().split('\t') for rl in fr.readlines()]
labels = ['age','prescript','astigmatic','tearRate'] #特征属性
return dataSet, labels #返回数据集和特征属性
'''经验熵'''
def calShannonEnt(dataset):
m = len(dataset)
lableCount = {}
'''计数'''
for data in dataset:
currentLabel = data[-1]
if currentLabel not in lableCount.keys():
lableCount[currentLabel] = 0
lableCount[currentLabel] += 1
'''遍历字典求和'''
entropy = 0
for label in lableCount:
p &#