温馨提示
关于本文:
本文你可以学习到完整的不使用webui借助lora和dreambooth微调Stable Diffusion的全过程。
手把手教你微调Stable Diffusion生成优弧,但是半失败版😂
关于训练:
单卡32GV100进行的微调,因为一些训练策略显存只需要16G就够了。
训练用时一个半小时多一点点。根据自己显卡量力而行。


搞环境
先搞个虚拟环境:
conda create -n youhu
conda activate youhu scipy
进入虚拟环境了。开搞。

因为我们是使用DreamBooth对Stable Diffusion进行微调,所以先把Diffusion Model的库搞下来。
git clone https://github.com/huggingface/diffusers.git
下载成功之后你现在会看到多出来一个diffuser文件。

然后进入到这个文件夹了里。开始安排环境
pip install -e .

进入examples/dreambooth目录,继续安排环境的依赖包:
pip install -r requirements_sdxl.txt
pip install bitsandbytes xformers
配置一下accelerate的环境
accelerate config default

数据集
接下来就是准备几个你小子的图。放到examples/dreambooth目录下。


准备脚本
打开vim写个脚本,代码下拉可以直接复制。
这个脚本是使用你刚才的图片通过Dreambooth微调Stable Diffusion模型。

export MODEL_NAME="./stable-diffusion-xl-base-1.0"
export INSTANCE_DIR="yh"
export OUTPUT_DIR="lora-trained-xl"
# export VAE_PATH="madebyollin/sdxl-vae-fp16-fix"
python train_dreambooth_lora_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--instance_prompt="upper_body, 1 boy, glasses, youhu, nixiaozi" \
--resolution=1024 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--learning_rate=1e-5 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500 \
--validation_prompt="youhu, nixiaozi" \
--validation_epochs=25 \
--seed="0" \
--enable_xformers_memory_efficient_attention \
--gradient_checkpointing \
--use_8bit_adam \
# --mixed_precision="fp16" \
# --pretrained_vae_model_name_or_path=$VAE_PATH \
这里解释一下。这个脚本的主要目的是配置和运行一个Stable Diffusion模型的训练过程,包括模型的参数设置、数据路径、学习率、批处理大小等。你可以根据自己的需求修改这些参数,然后运行脚本来训练模型。
-
export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0":设置了一个名为MODEL_NAME的环境变量,该变量指定了预训练模型的名称或路径。 -
export INSTANCE_DIR="yh":设置了一个名为INSTANCE_DIR的环境变量,该变量指定了实例数据的目录或路径。 -
export OUTPUT_DIR="lora-trained-xl":设置了一个名为OUTPUT_DIR的环境变量,该变量指定了模型训练结果的输出目录或路径。 -
python train_dreambooth_lora_sdxl.py命令,它实际执行了模型训练的操作。以下是命令中的参数和选项的解释:-
--pretrained_model_name_or_path=$MODEL_NAME:指定了预训练模型的名称或路径,使用了之前设置的MODEL_NAME环境变量。 -
--instance_data_dir=$INSTANCE_DIR:指定了实例数据的目录或路径,使用了之前设置的INSTANCE_DIR环境变量。 -
--output_dir=$OUTPUT_DIR:指定了模型训练结果的输出目录或路径,使用了之前设置的OUTPUT_DIR环境变量。 -
--instance_prompt="a photo of youhu":设置了实例提示,描述了输入数据的内容。 -
--resolution=1024:指定了训练过程中使用的分辨率。 -
--train_batch_size=1:指定了训练时的批量大小。 -
--gradient_accumulation_steps=4:指定了梯度累积的步数。 -
--learning_rate=1e-5:指定了学习率的初始值。 -
--lr_scheduler="constant":选择了学习率调度器的类型,这里是常数学习率。 -
--lr_warmup_steps=0:指定了学习率预热的步数。 -
--max_train_steps=500:指定了最大训练步数。 -
--validation_prompt="youhu, ni xiao zi":设置了验证提示,描述了用于验证的输入数据的内容。 -
--seed="0":设置了随机种子,以确保训练的可重复性。 -
--enable_xformers_memory_efficient_attention:启用了XFormers模块的内存效率注意力机制。 -
--gradient_checkpointing:启用了梯度检查点,以减少内存使用。 -
--use_8bit_adam:使用了8位Adam优化器,这可以提高训练速度。 -
最后两行的注释部分是选项的注释, Stable Diffusion原装VAE存在数值不稳定的问题,因此hugging face官方一般都推荐换一个VAE模型。但是推荐的那个VAE模型实际使用起来有冲突,会一直报错。所以这里还是使用原装VAE吧。
-
缓存模型
接下来还不能直接运行。因为墙的原因,你的服务器没办法直接从抱抱脸上直接下载模型。所以我的建议是,有两个办法:
在examples/dreambooth目录下建一个文件夹stable-diffusion-xl-base-1.0
从这个链接下载模型放到目录中:stabilityai/stable-diffusion-xl-base-1.0 at main (huggingface.co)

其他解决方法:
-
给你服务器上搞个梯子,开全局
开始训练
bash train.sh

然后就等着他进度条就行了:

到这样就是训练完了:

开始生成
还是在examples/dreambooth目录下,搞一个python文件,我这里叫generate.py
直接复制下边的代码即可。
from diffusers import DiffusionPipeline
import torch
lora_model_id = './lora-trained-xl/pytorch_lora_weights.safetensors'
base_model_id = "./stable-diffusion-xl-base-1.0"
pipe = DiffusionPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
pipe.load_lora_weights(lora_model_id)
prompt = ["youhu, ni xiao zi","youhu","ni xiao zi","ni xiao zi, youhu","a photo of youhu", "a photo of ni xiao zi"]
for p in prompt:
image = pipe(p, num_inference_steps=50).images[0]
image.save(f"{p}.png")
-
from diffusers import DiffusionPipeline:从diffusers模块导入DiffusionPipeline类。这个类提供了一个管道,用于执行扩散过程,这是生成图片的关键步骤。 -
import torch:导入PyTorch库,这是一个用于深度学习的开源库。 -
lora_model_id = './lora-trained-xl/pytorch_lora_weights.safetensors':定义一个变量来存储预训练模型的权重文件路径。 -
base_model_id = "./stable-diffusion-xl-base-1.0":定义一个变量来存储基础模型的路径。 -
pipe = DiffusionPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16):使用基础模型的路径加载预训练的扩散管道,并设置数据类型为float16。 -
pipe = pipe.to("cuda"):将管道移动到GPU设备上进行计算。 -
pipe.load_lora_weights(lora_model_id):加载预训练模型的权重到管道中。 -
prompt = ["youhu, ni xiao zi","youhu","ni xiao zi","ni xiao zi, youhu","a photo of youhu", "a photo of ni xiao zi"]:定义一个列表,包含了多个生成图片的提示。 -
for p in prompt::对提示列表进行遍历,每次循环处理一个提示。image = pipe(p, num_inference_steps=50).images[0]:通过管道生成一张图片。这里的字符串p是生成图片的提示,而num_inference_steps=25表示推理步骤的数量。image.save(f"优弧{i}.png"):将生成的图片保存为优弧{i}.png文件,其中i是当前循环的索引号。
然后就是生成过程:

结果图

发个勉强能看的。😂

失败原因分析:
-
训练集不足,且图片差异较大,分辨率过低(这个是主要原因)。
-
以及训练过程和验证过程prompt差异较大
-
没换VAE(因为
madebyollin/sdxl-vae-fp16-fix)实在是用不了。 -
这个模型本身效果就一般。
以上种种原因导致最后效果不尽人意😂。
毕竟别人用五张高清柯基,训练出了比较好的柯基图。
训练集:

结果:

写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

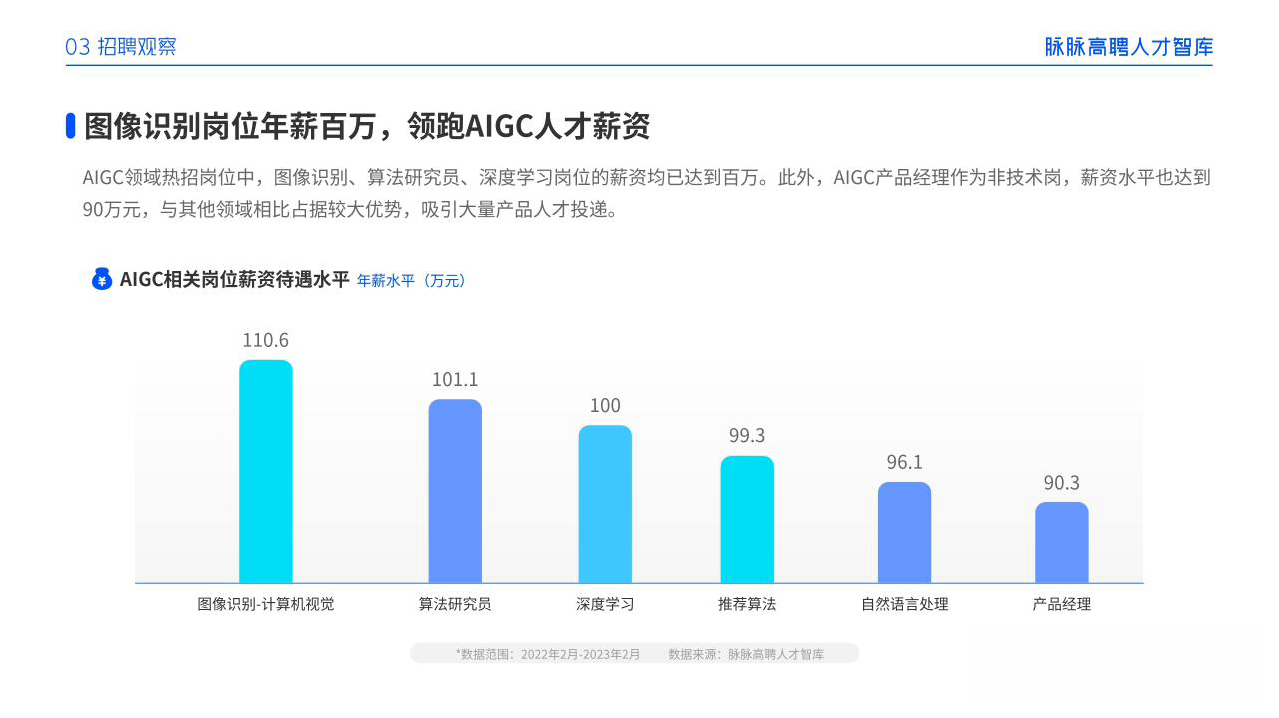
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
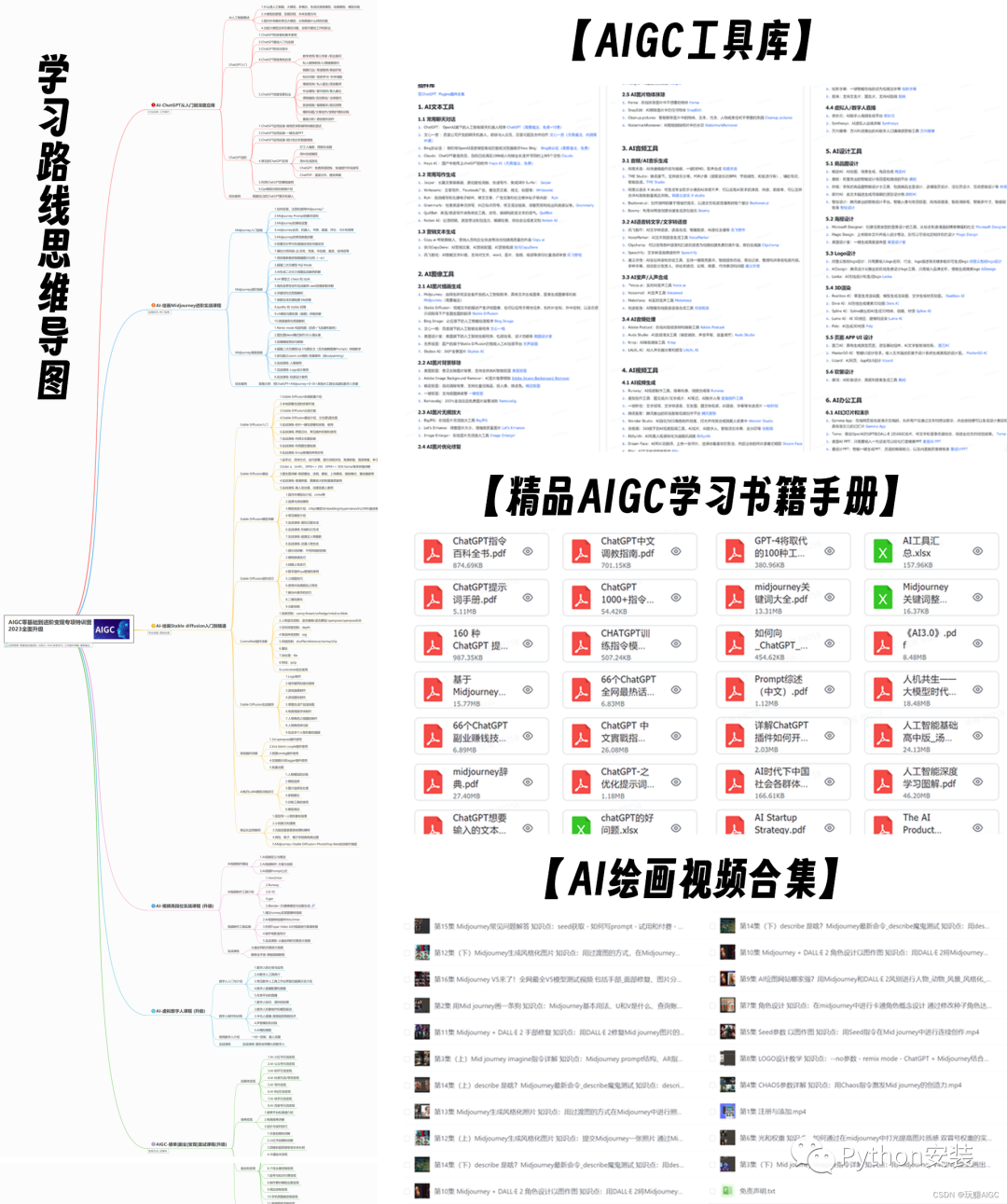
二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!
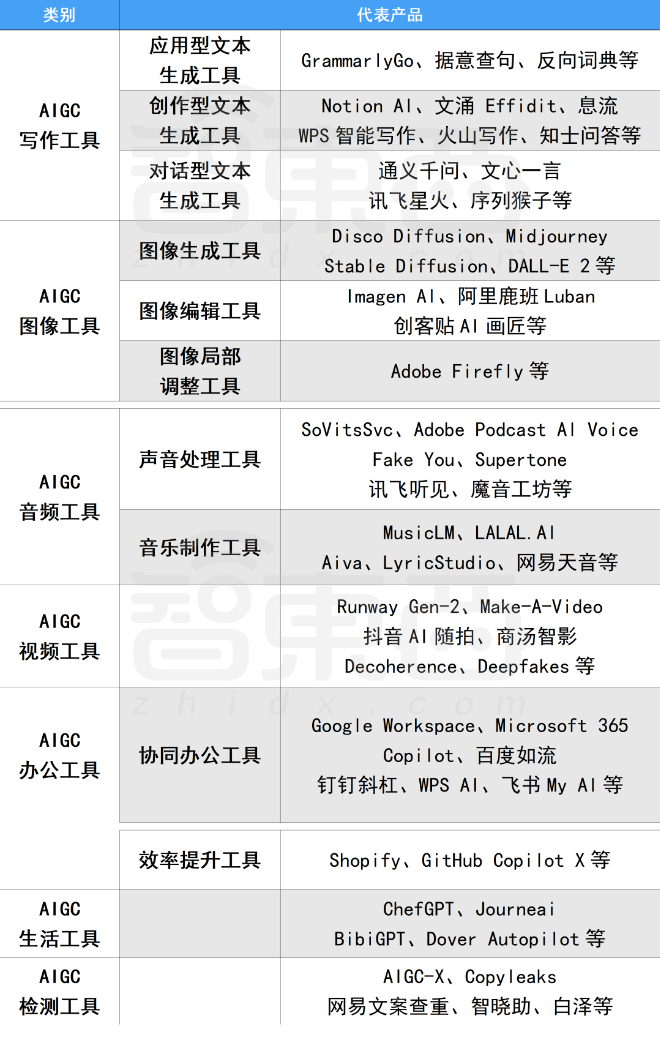
三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。