背景:
- 人工智能发展:随着人工智能技术的快速发展,特别是深度学习(Deep Learning)的进步,如神经网络、自然语言处理(NLP)和生成式对抗网络(GANs)等技术的突破,使得构建聊天机器人成为可能。
- 用户需求:随着互联网的普及和移动设备的广泛使用,人们对于便捷、个性化和24/7的交互方式的需求增加,聊天机器人作为虚拟助手,可以提供即时解答和咨询服务。
- 商业应用:企业看到了聊天机器人的商业价值,它们可以用于客户服务、在线销售、知识管理等多个领域,提高效率,降低人力成本
目的:
- 人机交互:深度学习聊天机器人旨在模仿人类对话,理解用户的自然语言输入,然后生成有意义和相关的回复,提供流畅的交互体验。
- 信息处理:通过处理和理解大量的文本数据,机器人可以学习到丰富的知识,从而能够回答各种领域的问题。
- 个性化服务:通过深度学习,机器人可以根据用户的历史对话和行为,提供个性化的推荐和服务。
- 自动化任务:在客户服务中,机器人可以自动处理常见问题,减轻人工客服的压力。
- 知识库更新:聊天机器人可以不断学习和更新,随着新知识的输入,其回答能力会逐渐增强。
那么让我们了解一下该机器人是怎么来解决问题的
一.代码解读(创建聊天机器人)
1.首先导入必要的库跟加载模型
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QVBoxLayout, QHBoxLayout, QWidget, QLineEdit, QTextEdit, QPushButton
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np # 确保导入 numpy
import pickle
2.加载预训练的聊天机器人模型
model = tf.keras.models.load_model('chatbot_model.h5')3.加载用于文本序列化的Tokenizer
with open('tokenizer.pkl', 'rb') as handle:
tokenizer = pickle.load(handle)接下来是聊天机器人的核心部分,它负责处理用户的输入,生成并返回机器人的回复
def predict_response(input_text):
# 将输入文本转换为整数序列
input_seq = tokenizer.texts_to_sequences([input_text])
# 填充序列以匹配模型所需的固定长度
input_seq = pad_sequences(input_seq, maxlen=20)
# 使用模型对填充后的序列进行预测
prediction = model.predict(input_seq)
# 获取预测序列中概率最高的索引
predicted_seq = np.argmax(prediction, axis=-1)
# 将预测的整数序列转换回文本
predicted_text = tokenizer.sequences_to_texts(predicted_seq)
# 返回预测的文本
return predicted_text[0]
4.然后就可以实现了一个简单的聊天机器人应用界面。
-
首先,定义了一个
ChatBotApp类,继承自QMainWindow。在构造函数中,设置了窗口标题、大小和中心部件,并在中心部件中添加了一个竖直布局。 -
在中心部件中,添加了一个用于显示聊天内容的
QTextEditwidget,并设置为只读,以及一个用于输入用户问题的QLineEditwidget 和一个用于发送问题的QPushButtonwidget。 -
在
handle_send方法中,获取用户输入的文本,如果用户输入不为空,则将用户输入显示在聊天窗口中,并调用predict_response函数获取机器人的回答,将回答也显示在聊天窗口中,最后清空用户输入框。 -
最后,创建了一个
QApplication实例,显示并运行ChatBotApp实例class ChatBotApp(QMainWindow): # 初始化函数,设置窗口的基本属性 def __init__(self): super().__init__() self.setWindowTitle("ChatBot聊天机器人") # 设置窗口标题 self.setGeometry(300, 300, 700, 600) # 设置窗口的大小为300x300,左上角坐标为(300, 300) self.central_widget = QWidget() # 创建一个中央部件 self.setCentralWidget(self.central_widget) # 将中央部件设置为窗口的主体 self.layout = QVBoxLayout() # 创建一个垂直布局,用于放置聊天内容和输入框 self.chat_display = QTextEdit() # 创建一个文本编辑器,用于显示聊天记录 self.chat_display.setReadOnly(True) # 设置文本编辑器只读,不能编辑 self.layout.addWidget(self.chat_display) # 将文本编辑器添加到垂直布局中 self.input_layout = QHBoxLayout() # 创建一个水平布局,用于放置输入框和发送按钮 self.user_input = QLineEdit() # 创建一个单行输入框,提示用户输入问题 self.user_input.setPlaceholderText("请输入你的问题") # 设置输入框的提示文本 self.input_layout.addWidget(self.user_input) # 将输入框添加到水平布局中 self.send_button = QPushButton("提问") # 创建一个按钮,用于发送用户输入的问题 self.send_button.clicked.connect(self.handle_send) # 当按钮被点击时,调用handle_send方法 self.input_layout.addWidget(self.send_button) # 将按钮添加到水平布局中 self.layout.addLayout(self.input_layout) # 将水平布局添加到垂直布局中 self.central_widget.setLayout(self.layout) # 将垂直布局设置为中央部件的布局 # 当用户点击发送按钮时,处理发送操作 def handle_send(self): user_text = self.user_input.text() # 获取用户输入的文本 if user_text.strip(): # 如果用户输入不为空 self.chat_display.append(f"User: {user_text}") # 在聊天记录中添加用户的消息 response = predict_response(user_text) # 调用predict_response函数获取机器人回复 self.chat_display.append(f"Bot: {response}") # 在聊天记录中添加机器人回复 self.user_input.clear() # 清空输入框,准备接收新的用户输入 # 创建应用程序实例,显示窗口并启动事件循环 app = QApplication(sys.argv) chat_app = ChatBotApp() chat_app.show() sys.exit(app.exec_())二.灵活运用机器人
你是否也想得到以下这种回答呢:
用户:明天会下雨吗?
机器人:根据天气预报,明天可能会有降雨,请记得带伞。
用户:编程中遇到了问题怎么办?
机器人:在编程过程中遇到问题很正常,可以查阅文档、搜索资料或向社区寻求帮助。
用户:我感到很沮丧,怎么调整心情?
机器人:沮丧时可以尝试做一些喜欢的事情,如听音乐、运动或与家人交流。
用户:你有什么特长?
机器人:我擅长回答各种问题,帮助您解决疑惑或提供信息。
用户:你喜欢什么颜色?
机器人:作为机器人,我没有感觉,所以对颜色没有偏好。
用户:如何提高写作能力?
机器人:提高写作能力需要多读书、多写作,并接受他人的反馈意见。
用户:你会唱歌吗?
机器人:抱歉,我无法唱歌,但我可以为您提供歌词或音乐推荐。
用户:怎样保持健康?
机器人:保持健康需要均衡饮食、适量运动和良好的作息习惯。等等
数据准备:在训练聊天机器人模型时,需要准备大量的对话数据。这可能需要使用网络爬虫或其他工具来收集对话数据,并将其格式化为模型可以使用的格式。
那么你需要这样做:
三.创建预设字典
1.创建一个包含预设回复的文本文件,例如 data.txt,并将每个回复写在一个新行中:
明天会下雨吗?|根据天气预报,明天可能会有降雨,请记得带伞。
编程中遇到了问题怎么办?|在编程过程中遇到问题很正常,可以查阅文档、搜索资料或向社区寻求帮助。
# ... (其他预设回复)2.在你的程序中,读取这个文本文件并将预设回复存储在一个字典中
def load_preset_responses(file_path):
preset_responses = {}
with open(file_path, 'r') as file:
for line in file:
key, value = line.strip().split('|')
preset_responses[key] = value
return preset_responses
preset_responses = load_preset_responses('preset_responses.txt')
3.在 predict_response 函数中,检查用户输入与预设回复:
def predict_response(input_text):
# ... (其他代码不变)
# 检查预设回复
if input_text in preset_responses:
predicted_text = preset_responses[input_text]
else:
# ... (模型预测部分)
return predicted_text
这样,就可以在不修改代码的情况下更新预设回复,只需要修改 data.txt 文件。
四.训练模型
1.导入必要的库
import pandas as pd
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
import matplotlib.pyplot as plt
import pickle2.接下来对数据集进行预处理,以便用于训练一个文本生成模型
# 读取对话数据
data = pd.read_csv('data.txt', sep='\t', header=None, names=['dialogue'])
texts = data['dialogue'].tolist()
# 将对话数据拆分为用户输入和机器人回复
input_texts = []
target_texts = []
for i in range(0, len(texts), 2):
input_texts.append(texts[i].split(':')[1]) # 提取用户输入
target_texts.append(texts[i+1].split(':')[1]) # 提取机器人回复
# 初始化 Tokenizer
tokenizer = Tokenizer(num_words=10000)
tokenizer.fit_on_texts(input_texts + target_texts)
# 保存 Tokenizer
with open('tokenizer.pkl', 'wb') as handle:
pickle.dump(tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)
# 文本转换为序列
input_sequences = tokenizer.texts_to_sequences(input_texts)
target_sequences = tokenizer.texts_to_sequences(target_texts)
# 序列填充
padded_input_sequences = pad_sequences(input_sequences, maxlen=20)
padded_target_sequences = pad_sequences(target_sequences, maxlen=20)3.展示如何从零开始构建一个简单的聊天机器人模型,包括数据预处理、模型构建、训练、评估和预测。
择合适的模型架构和超参数设置对训练出高质量的聊天机器人模型至关重要。如果模型架构设计得不当,或者超参数设置不合适,那么训练出的模型可能会表现得不够好,无法生成合理有意义的回复。
# 构建模型
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, Dense, Embedding
def build_model(vocab_size, embedding_dim, rnn_units, batch_size):
input = Input(shape=(None,))
x = Embedding(vocab_size, embedding_dim)(input)
x = LSTM(rnn_units, return_sequences=True)(x)
output = Dense(vocab_size, activation='softmax')(x)
model = Model(inputs=input, outputs=output)
return model
vocab_size = 10000
embedding_dim = 256
rnn_units = 1024
batch_size = 10
model = build_model(vocab_size, embedding_dim, rnn_units, batch_size)
model.summary()
# 准备标签数据,使用序列移位方法来生成输入和目标
target_sequences_shifted = np.zeros_like(padded_target_sequences)
target_sequences_shifted[:, :-1] = padded_target_sequences[:, 1:]
target_sequences_shifted[:, -1] = padded_target_sequences[:, -1]
# 编译并训练模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
history = model.fit(padded_input_sequences, target_sequences_shifted, epochs=450)
# 绘制训练过程中损失的变化
plt.plot(history.history['loss'])
plt.title('Model Loss Progression')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train'], loc='upper left')
plt.show()
# 保存模型
model.save('chatbot_model.h5')
# 模型评估
loss = model.evaluate(padded_input_sequences, target_sequences_shifted)
print(f'Model Loss: {loss}')
# 测试生成响应
def predict_response(input_text):
input_seq = tokenizer.texts_to_sequences([input_text])
input_seq = pad_sequences(input_seq, maxlen=20)
prediction = model.predict(input_seq)
predicted_seq = np.argmax(prediction, axis=-1)
predicted_text = tokenizer.sequences_to_texts(predicted_seq)
return predicted_text4.进行一下项目测试
# 示例测试
test_text = "你对环保议题有什么看法?"
response = predict_response(test_text)
print(f'Input: {test_text}')
print(f'Response: {response}')接下来试一下机器人是如何使用的,运行结果如下:
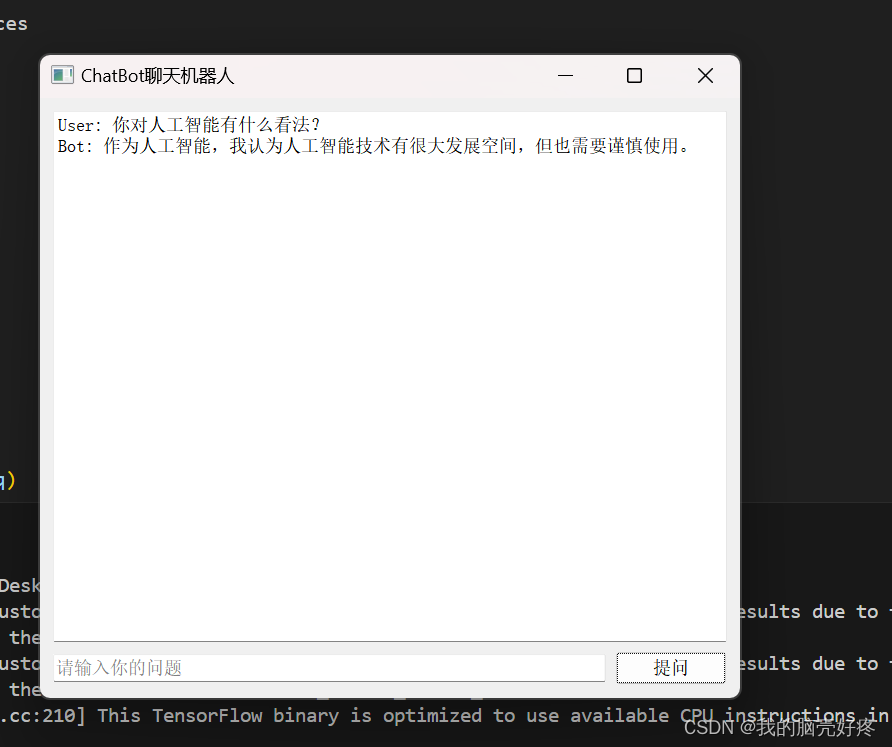
五.超参数调节过程
- 选择初始值:根据经验和领域知识设置初始的超参数值。
- 网格搜索或随机搜索:在给定的超参数范围内,通过网格搜索或随机搜索尝试不同的组合。
- 交叉验证:使用交叉验证来评估每个超参数组合的性能,确保模型在未见过的数据上表现良好。
- 监控性能:在训练过程中,记录模型的损失和指标,如准确率、BLEU分数等。
- 早停:如果在验证集上的性能不再提升,或者开始下降,可能需要提前停止训练,以防止过拟合。
- 调整:根据性能反馈调整超参数,重复上述步骤,直到找到最佳组合。
这个过程可能需要多次迭代,特别是对于复杂的模型和大型数据集。在实际应用中,可以使用自动化工具如Hyperopt、Keras Tuner或Ray Tune等来简化超参数调整过程
六.总结
这篇文章介绍了一种基于循环神经网络(RNN)的聊天机器人模型的构建、训练和评估过程。文章首先导入了必要的库,并定义了一个模型构建函数,该函数接受词汇表大小、嵌入维度、RNN单元数和批量大小作为参数。然后,文章使用这个函数构建了一个模型,并打印了模型的摘要。
接下来,文章展示了如何准备标签数据,通过将目标序列向左移位一个位置来创建新的目标序列。然后,文章编译了模型,并使用训练数据对模型进行了450个周期的训练。在训练过程中,文章还绘制了损失曲线,以便观察模型训练的进展。
训练完成后,文章将模型保存到'HDF5'格式的文件中,并使用评估方法评估了模型在训练数据上的性能。最后,文章定义了一个预测响应函数,该函数接受输入文本,将其转换为序列,并使用模型预测响应,最后将预测的序列转换回文本。
总而言之,这篇文章提供了一种构建、训练和评估基于RNN的聊天机器人模型的方法,并展示了如何使用这个模型生成响应。
本文链接:写文章-CSDN创作中心