在机器学习的世界里,K-Nearest Neighbors(KNN)算法是一种简单而强大的分类方法。它基于一个直观的想法:相似的数据点往往属于同一类别。本文将通过 Python 的 scikit-learn 库实现 KNN 分类,以经典的鸢尾花数据集为例,展示从数据加载到模型评估的完整流程。
1. KNN 算法简介
KNN 是一种监督学习算法,主要用于分类和回归任务。它的工作原理非常简单:对于一个新的数据点,算法会查找训练数据中与其最近的 K 个点(即“邻居”),然后根据这些邻居的类别进行投票,最终决定新数据点的类别。KNN 的关键在于选择合适的 K 值以及定义“最近”的距离度量方式。
2. 鸢尾花数据集
鸢尾花数据集是机器学习领域中最经典的数据集之一,由英国统计学家和生物学家 Ronald Fisher 在 1936 年首次发表。该数据集包含 150 个样本,每个样本有 4 个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度),分别对应鸢尾花的三种类别:Setosa、Versicolor 和 Virginica。
3. 实现 KNN 分类
接下来,我们将通过 Python 的 scikit-learn 库实现 KNN 分类。以下是完整的代码实现:
# 导入必要的库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, accuracy_score
# 1. 加载数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据
print("数据集特征:", iris.feature_names)
print("数据集标签:", iris.target_names)
# 2. 划分训练集和测试集(训练集70%,测试集30%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 3. 特征标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 4. 创建KNN模型并训练
k = 3 # 设置K的值
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
# 5. 进行预测
y_pred = knn.predict(X_test)
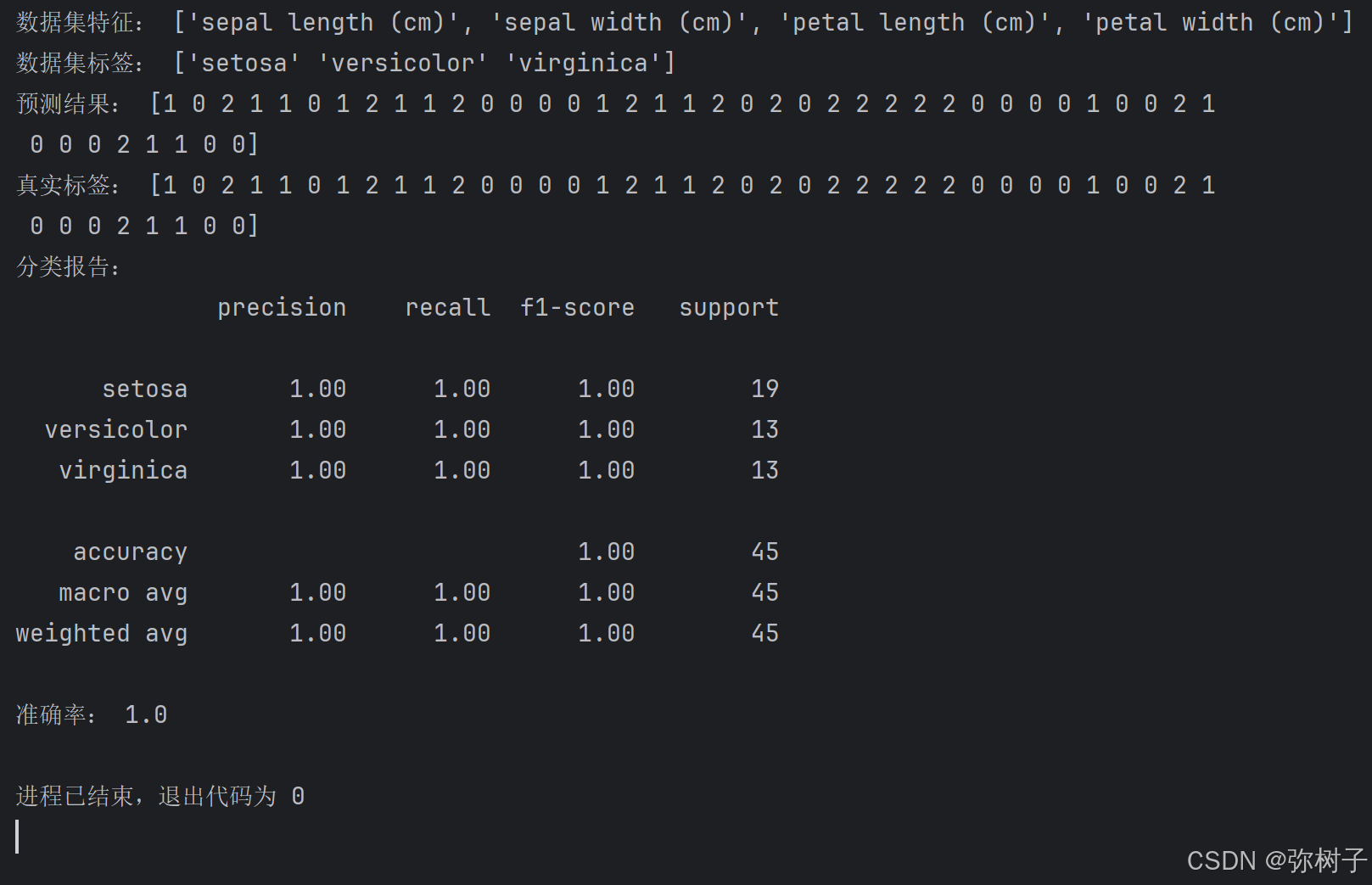
print("预测结果:", y_pred)
print("真实标签:", y_test)
# 6. 评估模型性能
print("分类报告:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
print("准确率:", accuracy_score(y_test, y_pred))代码解析
-
加载数据集
使用scikit-learn提供的load_iris()函数加载鸢尾花数据集。数据集包含 4 个特征和 3 个类别。 -
划分训练集和测试集
使用train_test_split函数将数据集划分为训练集(70%)和测试集(30%)。这样可以评估模型在未见过的数据上的性能。 -
特征标准化
KNN 算法对特征的尺度非常敏感,因此我们使用StandardScaler对特征进行标准化处理,使每个特征的均值为 0,标准差为 1。 -
创建 KNN 模型并训练
使用KNeighborsClassifier创建 KNN 模型,并通过fit方法训练模型。这里我们选择 K=3。 -
进行预测
使用训练好的模型对测试集进行预测,并打印预测结果和真实标签。 -
评估模型性能
使用classification_report和accuracy_score评估模型的性能。分类报告提供了每个类别的精确率、召回率和 F1 分数,而准确率则表示模型在测试集上的整体性能。
4. 结果分析
运行上述代码后,你会看到以下输出:
5. 总结
通过本文,我们展示了如何使用 Python 和 scikit-learn 实现 KNN 分类。从数据加载、预处理、模型训练到性能评估,整个过程清晰明了。KNN 算法虽然简单,但在许多实际问题中都能取得不错的效果。当然,KNN 的性能也依赖于 K 值的选择和数据的特征分布。在实际应用中,你可以尝试不同的 K 值,或者使用交叉验证来优化模型。
希望本文能帮助你更好地理解和应用 KNN 算法。