大模型中的MoE是什么?
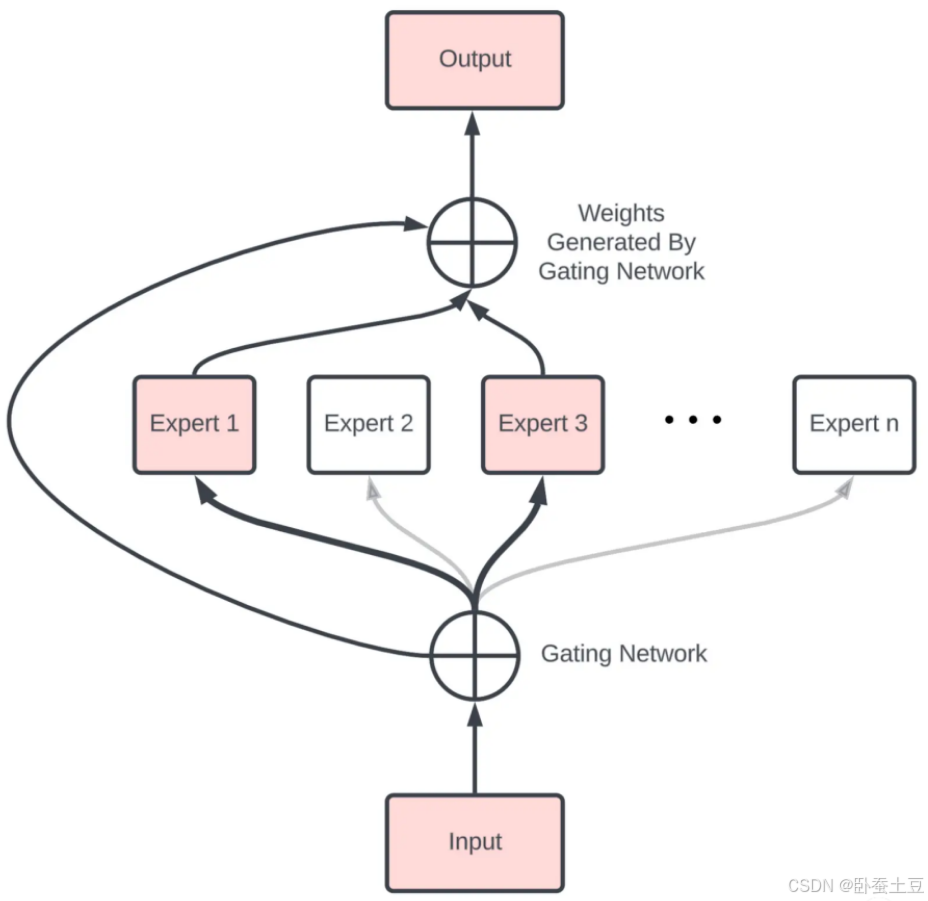
MoE(Mixture of Experts)是一种用于提高深度学习模型性能和效率的架构。其核心思想是通过引入多个专家(Experts)模型,每个输入数据只选择和激活其中的一部分专家模型来进行处理,从而减少计算量,提高训练和推理速度。
MoE的底层原理
MoE架构由两个主要部分组成:
- 专家(Experts):一组独立的模型或神经网络,可以是同构或异构的。
- 门控网络(Gating Network):一个选择机制,用来决定哪些专家应该处理输入数据。门控网络根据输入数据生成一组权重,这些权重用于加权组合各个专家的输出。
基本流程如下:
- 输入数据通过门控网络,门控网络输出每个专家的权重。
- 输入数据分别通过所有专家模型,每个专家生成一个输出。
- 专家的输出根据门控网络的权重进行加权求和,得到最终的输出。
公式表示如下:
y = ∑ i = 1 N g i ( x ) ⋅ f i ( x ) y = \sum_{i=1}^{N} g_i(x) \cdot f_i(x) y=i=1∑Ngi(x)⋅fi(x)
其中:
- y y y 是最终输出
- N N N 是专家数量
- g i ( x ) g_i(x) gi(x) 是第 i i i 个专家的权重,由门控网络生成
- f i ( x ) f_i(x) fi(x) 是第 i i i 个专家的输出
MoE的实现方法
MoE有多种实现方法,主要可以分为以下几种:
- Soft Gating MoE
- Hard Gating MoE
- Sparse MoE
- Hierarchical MoE
1. Soft Gating MoE
在Soft Gating MoE中,所有专家的输出都会被加权并合并。门控网络的输出是一个概率分布,对所有专家的输出进行加权平均。
代码示例:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SoftGatingMoE(nn.Module):
def __init__(self, input_dim, num_experts, expert_dim):
super(SoftGatingMoE, self).__init__()
self.num_experts = num_experts
self.experts = nn.ModuleList([nn.Linear(input_dim, expert_dim) for _ in range(num_experts)])
self.gating_network = nn.Linear(input_dim, num_experts)
def forward(self, x):
gate_outputs = F.softmax(self.gating_network(x), dim=1)
expert_outputs = torch.stack([expert(x) for expert in self.experts], dim=1)
output = torch.sum(gate_outputs.unsqueeze(2) * expert_outputs, dim=1)
return output
# 示例
input_data = torch.randn(10, 20) # 假设输入维度为20
model = SoftGatingMoE(input_dim=20, num_experts=5, expert_dim=30)
output = model(input_data)
2. Hard Gating MoE
在Hard Gating MoE中,每个输入数据只选择一个专家来处理。门控网络的输出是一个one-hot编码,表示被选择的专家。
代码示例:
class HardGatingMoE(nn.Module):
def __init__(self, input_dim, num_experts, expert_dim):
super(HardGatingMoE, self).__init__()
self.num_experts = num_experts
self.experts = nn.ModuleList([nn.Linear(input_dim, expert_dim) for _ in range(num_experts)])
self.gating_network = nn.Linear(input_dim, num_experts)
def forward(self, x):
gate_outputs = F.gumbel_softmax(self.gating_network(x), hard=True, dim=1)
expert_outputs = torch.stack([expert(x) for expert in self.experts], dim=1)
output = torch.sum(gate_outputs.unsqueeze(2) * expert_outputs, dim=1)
return output
# 示例
input_data = torch.randn(10, 20)
model = HardGatingMoE(input_dim=20, num_experts=5, expert_dim=30)
output = model(input_data)
3. Sparse MoE
Sparse MoE通过选择少量的专家来处理输入数据,通常使用Top-k选择机制来选择权重最大的k个专家,从而实现稀疏化。
代码示例:
class SparseMoE(nn.Module):
def __init__(self, input_dim, num_experts, expert_dim, k=2):
super(SparseMoE, self).__init__()
self.num_experts = num_experts
self.k = k
self.experts = nn.ModuleList([nn.Linear(input_dim, expert_dim) for _ in range(num_experts)])
self.gating_network = nn.Linear(input_dim, num_experts)
def forward(self, x):
gate_outputs = self.gating_network(x)
topk_values, topk_indices = torch.topk(gate_outputs, self.k, dim=1)
gate_outputs = F.softmax(topk_values, dim=1)
expert_outputs = torch.stack([self.experts[i](x) for i in topk_indices.T], dim=1)
output = torch.sum(gate_outputs.unsqueeze(2) * expert_outputs, dim=1)
return output
# 示例
input_data = torch.randn(10, 20)
model = SparseMoE(input_dim=20, num_experts=5, expert_dim=30, k=2)
output = model(input_data)
4. Hierarchical MoE
Hierarchical MoE采用层次化的结构,首先选择一个子集的专家,然后在子集中进一步选择。
代码示例:
class HierarchicalMoE(nn.Module):
def __init__(self, input_dim, num_experts, expert_dim, num_clusters):
super(HierarchicalMoE, self).__init__()
self.num_clusters = num_clusters
self.cluster_gating = nn.Linear(input_dim, num_clusters)
self.experts_per_cluster = num_experts // num_clusters
self.expert_gatings = nn.ModuleList([nn.Linear(input_dim, self.experts_per_cluster) for _ in range(num_clusters)])
self.experts = nn.ModuleList([nn.Linear(input_dim, expert_dim) for _ in range(num_experts)])
def forward(self, x):
cluster_gate_outputs = F.softmax(self.cluster_gating(x), dim=1)
cluster_outputs = []
for i in range(self.num_clusters):
expert_gate_outputs = F.softmax(self.expert_gatings[i](x), dim=1)
expert_outputs = torch.stack([self.experts[i * self.experts_per_cluster + j](x) for j in range(self.experts_per_cluster)], dim=1)
cluster_output = torch.sum(expert_gate_outputs.unsqueeze(2) * expert_outputs, dim=1)
cluster_outputs.append(cluster_output)
cluster_outputs = torch.stack(cluster_outputs, dim=1)
output = torch.sum(cluster_gate_outputs.unsqueeze(2) * cluster_outputs, dim=1)
return output
# 示例
input_data = torch.randn(10, 20)
model = HierarchicalMoE(input_dim=20, num_experts=8, expert_dim=30, num_clusters=2)
output = model(input_data)
MoE的具体应用场景
MoE模型在实际应用中具有广泛的潜力,特别是在需要处理大规模数据、提高模型效率和性能的场景。以下是一些具体的应用场景:
1. 自然语言处理(NLP)
在NLP领域,MoE模型可以用于提高各种任务的性能,例如机器翻译、文本生成、情感分析等。通过选择适当的专家来处理不同类型的文本数据,MoE模型可以显著提高处理速度和准确性。
示例:
在机器翻译任务中,不同的语言对可能需要不同的专家模型来处理。MoE模型可以根据输入语言的特征选择适当的专家,从而提高翻译质量。
class TranslationMoE(nn.Module):
def __init__(self, input_dim, num_experts, expert_dim):
super(TranslationMoE, self).__init__()
self.num_experts = num_experts
self.experts = nn.ModuleList([nn.Transformer(input_dim, expert_dim) for _ in range(num_experts)])
self.gating_network = nn.Linear(input_dim, num_experts)
def forward(self, src, tgt):
gate_outputs = F.softmax(self.gating_network(src), dim=1)
expert_outputs = torch.stack([expert(src, tgt) for expert in self.experts], dim=1)
output = torch.sum(gate_outputs.unsqueeze(2) * expert_outputs, dim=1)
return output
# 示例
src = torch.randn(10, 20, 512) # 假设输入维度为512
tgt = torch.randn(10, 20, 512)
model = TranslationMoE(input_dim=512, num_experts=5, expert_dim=512)
output = model(src, tgt)
2. 图像处理
在图像处理任务中,MoE模型可以用于图像分类、目标检测、图像生成等任务。通过选择适合处理特定图像特征的专家模型,MoE可以提高图像处理的效率和精度。
示例:
在图像分类任务中,不同类型的图像(例如自然场景、手写数字、人脸等)可能需要不同的专家模型来处理。MoE模型可以根据输入图像的特征选择适当的专家,从而提高分类准确率。
class ImageClassificationMoE(nn.Module):
def __init__(self, input_dim, num_experts, expert_dim, num_classes):
super(ImageClassificationMoE, self).__init__()
self.num_experts = num_experts
self.experts = nn.ModuleList([nn.Conv2d(input_dim, expert_dim, kernel_size=3, padding=1) for _ in range(num_experts)])
self.gating_network = nn.Linear(input_dim, num_experts)
self.fc = nn.Linear(expert_dim, num_classes)
def forward(self, x):
gate_outputs = F.softmax(self.gating_network(x.view(x.size(0), -1)), dim=1)
expert_outputs = torch.stack([F.relu(expert(x)) for expert in self.experts], dim=1)
output = torch.sum(gate_outputs.unsqueeze(2).unsqueeze(3) * expert_outputs, dim=1)
output = F.adaptive_avg_pool2d(output, (1, 1)).view(output.size(0), -1)
output = self.fc(output)
return output
# 示例
input_data = torch.randn(10, 3, 32, 32) # 假设输入维度为3x32x32
model = ImageClassificationMoE(input_dim=3, num_experts=5, expert_dim=64, num_classes=10)
output = model(input_data)
3. 推荐系统
在推荐系统中,MoE模型可以用于个性化推荐。不同用户群体可能对不同类型的内容感兴趣,通过MoE模型可以选择适合特定用户群体的专家模型,从而提高推荐效果。
示例:
在视频推荐系统中,不同的用户可能喜欢不同类型的视频(例如电影、体育、音乐等)。MoE模型可以根据用户的历史行为选择适当的专家,从而推荐最适合的视频内容。
class RecommendationMoE(nn.Module):
def __init__(self, input_dim, num_experts, expert_dim, num_items):
super(RecommendationMoE, self).__init__()
self.num_experts = num_experts
self.experts = nn.ModuleList([nn.Linear(input_dim, expert_dim) for _ in range(num_experts)])
self.gating_network = nn.Linear(input_dim, num_experts)
self.fc = nn.Linear(expert_dim, num_items)
def forward(self, user_features):
gate_outputs = F.softmax(self.gating_network(user_features), dim=1)
expert_outputs = torch.stack([F.relu(expert(user_features)) for expert in self.experts], dim=1)
output = torch.sum(gate_outputs.unsqueeze(2) * expert_outputs, dim=1)
output = self.fc(output)
return output
# 示例
user_features = torch.randn(10, 50) # 假设用户特征维度为50
model = RecommendationMoE(input_dim=50, num_experts=5, expert_dim=128, num_items=1000)
output = model(user_features)
总结
MoE通过将任务分配给多个专家模型并引入门控机制,有效地减少了计算复杂度,提高了模型的效率和性能。不同类型的MoE模型可以根据具体的应用场景进行选择和调整。通过合理设计和使用MoE,能够显著提升深度学习模型的训练和推理效率。