热乎的京东算法岗面经
如果onehot等操作之后维度过高你会怎么做;
- 根据类别特征的意义进行合并(分桶)
- 将类别按频次排序,频次特别低的一部分合并
- 特征哈希
- PCA降维
- 按照该特征对应目标值进行合并
- 使用每个分类对应目标变量均值+偏差,或出现频数代替
- 考虑平均数编码(高基数类别特征)
- Embedding
将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码。
有些基于树的算法在处理变量时,并不是基于向量空间度量,数值只是个类别符号,即没有偏序关系,所以不用进行独热编码。 Tree
Model不太需要one-hot编码: 对于决策树来说,one-hot的本质是增加树的深度。
gbdt的算法流程,和随机森林的区别
gbdt各基学习器之间是如何产生联系的;
场景题:ctr预估场景做特征工程等;
- 基础属性特征,比如用户的年龄、性别、职业、地域等基础信息;物品的各级类目等基础属性
- 统计类特征,用户过去不同时间窗口内对物品发生行为的统计,如点击/查看/下载/购买等;同样地,物品在不同时间窗口内的以上行为的统计
- 上下文特征,如用户当前所处地理位置,当前时刻,当天是否为休息日,发薪日后几天等强时效性特征
- 高阶交叉特征,两个独立特征交叉在一起的时候,往往会产生奇妙的化学反应,比如“用户所在地域”这个特征为美国,“时间”这个是特征为圣诞前夕,这两个特征组合起来,对“圣诞树”购买的几率就会大幅上升
- 其他高级特征,如文本特征、图像特征等,用户的评论、签名,物品本身携带的文字内容信息,都携带了用户/物品的特性,通过BoW,Ngram,LDA软聚类,word2vec,fasttext等方式挖掘文本特征;另外,如果用户/物品带有图片,可以通过cnn将图片解析成向量,捕捉到图片特征
通过Hash函数的方法,虽然Hash函数的方法,在数据量比较大的时候会有一些冲突,但是这对最后的影响结果不是很大。
user feat + photo feat + combine feat
user 类特征
# user id
# user gender
# user follow
# user like
# user negative
# user click
# user count feature
# user lda
# user lda
# user loc
# user device
# user ad download: 对cvr比较有用
# user ad like
# user installed apps & games label
# user view & like photo label
photo 特征
# photo id
# photo region from ip
# Photo Author
# photo width
# ad category : 有一点用
# photo advertiser info
# ExtractPhotoTitle
# ExtractPhotoCaptionSegment
combine 特征
# UserLevel + Photofeature
# UserLevel + PhotoAuthorfeature
# UserLevel + PhotoRegion
# UserLda + PhotoId
# user region & photo region
# User attribute photo id
# User device photo id
# user like & authorid
# user click & authorid
dense feat + sparse feat :
sparse feat 进一步做 embedding
dense feat 一般是由其他 api 直接提供的 embedding
黑白样本失衡该如何处理,如果smote采样的话如何生成样本;
SMOTE 上采样:通过找到少数类别样本的 k 近邻样本,通过 x n e w = x + r a n d ( 0 , 1 ) ∗ ∣ x − x n ∣ x_{new}=x+rand(0,1)∗∣x−x_n∣ xnew=x+rand(0,1)∗∣x−xn∣来生成新样本。
sigmoid和relu对比;
神经网络过拟合如何处理;
dropout前向和反向的处理;
手写代码:二叉树镜像。
京东算法上海现场面经(9.18-9.19)
word2vec怎么做的,原理。
机器学习,lr为什么不用mse,svm为什么用hinge不用logloss,问svm为什么要用核函数。
有没有用过机器学习的降维方法
京东提前批算法工程师一面面经
ResNet,BN,以及梯度消失的缓解方法等。
再之后问了NMS和IOU的计算
def py_cpu_nms(dets, thresh):
x1 = dets[:,0]
y1 = dets[:,1]
x2 = dets[:,2]
y2 = dets[:,3]
areas = (y2-y1+1) * (x2-x1+1)
scores = dets[:,4]
keep = []
index = scores.argsort()[::-1]
while index.size >0:
i = index[0] # every time the first is the biggst, and add it directly
keep.append(i)
x11 = np.maximum(x1[i], x1[index[1:]]) # calculate the points of overlap
y11 = np.maximum(y1[i], y1[index[1:]])
x22 = np.minimum(x2[i], x2[index[1:]])
y22 = np.minimum(y2[i], y2[index[1:]])
w = np.maximum(0, x22-x11+1) # the weights of overlap
h = np.maximum(0, y22-y11+1) # the height of overlap
overlaps = w*h
ious = overlaps / (areas[i]+areas[index[1:]] - overlaps)
idx = np.where(ious<=thresh)[0]
index = index[idx+1] # because index start from 1
return keep
京东算法提前批面经,许愿一个京东offer!
SVM是什么,核函数有哪些,KKT条件是什么
GBDT与ARF的不同点是什么
K-means聚类算法中K值如何选择?
-
数据的先验知识,或者数据进行简单分析能得到
-
基于变化的算法:即定义一个函数,随着K的改变,认为在正确的K时会产生极值。如Gap
Statistic Jump Statistic 。可以这么理解,给定一个合理的类簇指标,比如平均半径或直径,只要我们假设的类簇的数目等于或者高于真实的类簇的数目时,该指标上升会很缓慢,而一旦试图得到少于真实数目的类簇时,该指标会急剧上升 -
基于结构的算法:即比较类内距离、类间距离以确定K。这个也是最常用的办法,如使用平均轮廓系数,越趋近1聚类效果越好;如计算类内距离/类间距离,值越小越好;等。其中轮廓系数(silhouette coefficient)。结合了凝聚度和分离度。计算公式如下
其中 [公式] 向量到所有它属于的簇中其它点的距离的平均, [公式] 向量到所有非本身所在簇中其它点的距离的平均距离
-
基于一致性矩阵的算法:即认为在正确的K时,不同次聚类的结果会更加相似,以此确定K
-
基于层次聚类:即基于合并或分裂的思想,在一定情况下停止从而获得K
-
基于采样的算法:即对样本采样,分别做聚类;根据这些结果的相似性确定K。如,将样本分为训练与测试样本;对训练样本训练分类器,用于预测测试样本类别,并与聚类的类别比较
-
使用Canopy Method算法进行初始划分
L1和L2正则化的区别是什么
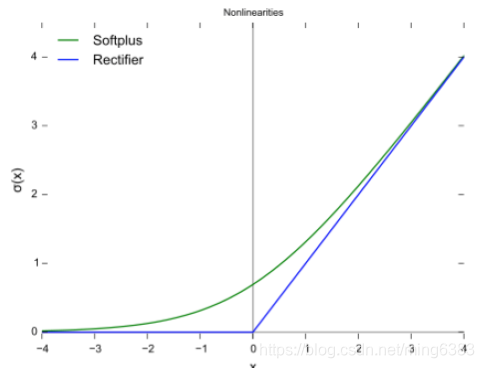
softmax是什么,用过softplus吗
softplus:
f ( x ) = l o g ( 1 + e x ) f(x) = log(1+e^x) f(x)=log(1+ex)
softplus可以看作是ReLu的平滑
京东搜索部门算法日常实习面经
算法题:两数之和
梯度爆炸梯度消失(要求举具体的例子做为说明)
fasttext原理(上一面不会的这一面还是不会😓)
有机会可以看一下,fastText是一个快速文本分类算法,涉及到Hierarchical Softmax和N-gram
fastText原理和文本分类实战,看这一篇就够了
正则化方法(l1,l2的区别)
GCN和CNN的区别(项目中有相关内容)
算法题: 旋转数组中查找某给定数(二分查找)
京东nlp算法一面面经
tensorflew与pytorch区别
python垃圾回收
垃圾回收
python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略,
- 1、通过 “标记-清除” 解决容器对象可能产生的循环引用问题:第一阶段是标记阶段,GC会把所有的『活动对象』打上标记,第二阶段是把那些没有标记的对象『非活动对象』进行回收。
- 2、通过 “分代回收” 以空间换时间的方法提高垃圾回收效率:新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。
它的缺点是需要额外的空间维护引用计数,这个问题是其次的,不过最主要的问题是它不能解决对象的“循环引用”,因此,也有很多语言比如Java并没有采用该算法做来垃圾的收集机制。
多线程多进程问题,cpu,磁盘io哪种多线程带来效果好
京东_东哥面经+Smart
python的sleep的同步和异步
当前线程调用 sleep() 函数进入阻塞状态后,在其睡眠时间段内,该线程不会获得执行的机会,即使系统中没有其他可执行的线程,处于 sleep() 中的线程也不会执行,因此 sleep() 函数常用来暂停程序的运行。
sleep()与wait()方法都不占用cpu时间及利用率。
京东算法实习二面面经
交叉熵,求导
cross_entropy = sum(-y*np.log(y_hat) - (1-y)* np.log(1-y_hat)) / n
dtheta = (1.0/n) * ((y-y_hat)*X)
softmax
算法题:找前k个最大的数,优化。
京东算法工程师暑期实习面经
描述下前向传播、后向传播;
什么是梯度下降,有哪些优化算法,区别是什么,它们(SGD,BGD,mini-BGD)的区别;
常见的激活函数有哪些;
sigmoid的特点;
为什么要用非线性激活函数,relu右侧导数是1,为什么能作为激活函数;
激活函数为什么要零均值输出;

梯度消失和梯度爆炸的原因,怎么解决;
什么是过拟合和欠拟合,怎么解决;
Dropout什么原理;
L1和L2正则化介绍下;
验证集是做什么的,测试集效果怎么评估;
介绍下AUC和F1-score;
- F1 score
F 1 = 2 × p e r c i s i o n × r e c a l l / p e r c i s i o n + r e c a l l F1 = 2\times percision \times recall /percision + recall F1=2×percision×recall/percision+recall
分类和回归都用什么损失函数,分类为什么不用平方损失;
迁移学习怎么做,原理;
特征迁移学习是为了寻找源领域和目标领域特征空间中 共同的特征表示,缩小两个领域之间的差异,用于提高目标领域的分类性能。特征迁移学习得到的特征起到了不同领域知识的迁移作用,使用源领域的特征有利于目标领域分类。在眼底图像分类中,特征迁移学习是使用自然图像训练得到的参数初始化网络,通过CNN提取医学图像上的特征作为目标图像的特征,再使用分类器对提取到的特征进行训练。
怎么用的动态学习率,人工干预还是自动的;
怎么理解AUC;
项目用的什么平台,keras、tensorflow、pytorch都是哪家公司的,为什么喜欢用pytorch;
了解哪些模型,讲下它们的原理(VGG,Inception V1-V4,Resnet);
了解检索或者推荐算法,是否对推荐或搜索感兴趣;
京东算法 二面面经
各种排序算法说下,写个插入排序。
冒泡排序
选择排序
插入排序
快速排序
归并排序
基数排序
说下神经网络正向和反向过程,最后面试官画了个图,让我求导。
用pytorch写下逻辑回归训练过程
PyTorch基础入门四:PyTorch搭建逻辑回归模型进行分类
口述逻辑回归
求第k大数
如果数据量很大,内存不够怎么办
快排
栈实现队列
dnn和cnn区别
cnn为什么参数共享
推导梯度下降公式
sgd和batch梯度下降区别
一个batch指的什么
京东算法实习面经,求hr面
对xgboost的了解,xgboost和lightgbm的区别
xgboost 是GBDT 的工程化实现,此外,显式地将树模型的复杂度作为正则项加在优化目标公式;推导里用到了二阶导数信息,而普通的GBDT只用到一阶;使用column(feature) sampling来防止过拟合;节点分裂算法能自动利用特征的稀疏性(自动缺失值处理)。
口述逻辑回归,写下其损失函数
口述l1和l2正则化
FM模型与LR区别
FM为每个特征学习一个隐向量,进行二阶特征交叉。
word2vec和bert区别
deepfm模型、deepwalk优缺点
口述了解的激活函数,为什么要激活函数
ctr中会遇到什么问题,怎么解决
对稠密特征怎么做处理
1、把原始的稠密特征直接和全连接层进行连接不和通过词嵌入转化的类别稠密特征进行交叉
2、把原始稠密特征离散化,转换为离散特征,然后和原始类别特征都进行词嵌入,之后再进行特征交叉。
3、对每个原始稠密特征x维护一个词嵌入向量e,然后把原始稠密特征和权重向量相乘得到最终的特征向量,相当于一个稠密特征映射成一个特征向量,之后和类别映射的词嵌入矩阵进行拼接。
4、鲜为人知的Key-Value Memory方法(详细推导见链接)。
京东实习算法二面面经
coding: 连续子序列和>=s的最短子序列长度
坐标旋转
京东算法工程师补招面经
F1值的计算公式说一下?
用过Hadoop、Spark吗?
口述一道SQL题,差集
在哈啰出行的项目详细盘问(非常详细)
用到了哪些特征,大概多少维?为什么要用这些特征?
lightgbm讲一下,具体是怎么做的?
lightgbm和xgboost的区别讲一下
lightgbm的直方图加速讲一下?具体是怎么来做的?
lightgbm的叶子节点是怎么分裂的?说一下
GBDT和随机森林的区别来说一下?
GBDT和随机森林的树的深度哪一个比较深?为什么?
LR(逻辑回归)是怎么优化的?
讲一下极大似然估计
极大似然估计,通俗理解来说,就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值!
换句话说,极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。
极大似然估计和最大后验估计的区别是什么?
最大后验概率估计就是最大化在给定数据样本的情况下模型参数的后验概率, 依然是根据已知样本,来通过调整模型参数使得模型能够产生该数据样本的概率最大,只不过对于模型参数有了一个先验假设,即模型参数可能满足某种分布,不再一味地依赖数据样例.
出了一道贝叶斯公式的概率题,比较简单
CNN和传统的全连接神经网络有什么区别?
你常用的深度学习框架都有哪些?
除了CNN,其他的NLP相关和推荐系统相关的模型有了解吗?
参数优化方法说一下(梯度下降的三种方式的优缺点)
深度学习里面的优化方法momentum和Adam来分别讲一下原理和公式
样本分布不平衡时,模型效果为什么不好?说明理由
样本不平衡会使得我们的分类模型存在很严重的偏向性,但是从一些常用的指标上又无法看出来。
快排
卷积核大小为什么是奇数
- 奇数卷积核更容易做padding。我们假设卷积核大小为k*k,为了让卷积后的图像大小与原图一样大,根据公式可得到padding=(k-1)/2,看到这里,细心地小伙伴应该已经看到点端倪了,没错,这里的k只有在取奇数的时候,padding才能是整数,否则padding不好进行图片填充;
- 奇数卷积核有中心像素点。这又是什么意思呢?在CNN中,一般会以卷积核的某个基准点进行窗口滑动,通常这个基准点是卷积核的中心点,所以如果k’是偶数,就找不到中心点了。
最大似然估计解释下
LR和SVM
Kmeans聚类
本人18家算法面经,吐血整理
快手(offer):
一面:
1、kmeans,K值选择,初始点
2、tensorflow原理,keras和他的区别
3、xgboost、正则化、怎么优化,boost算法
4、dropout原理,欠拟合,过拟合
5、分析代码复杂度
6、类别不平衡
7、怎么预处理
8、两个栈实现队列
9、你的职业规划
10、SQL
二面
实现sqrt
最小二乘法原理
怎么打标签
集齐12星座平均需要多少人
12/12+12/11+12/10+…+12/1 ≈ 37.24
sql
作业帮(一面凉):
1、首先自我介绍,没有多余的话,直接做题,一道hard,一道mid(白板定义树,从建树到先、中、后序遍历,后序遍历不允许用网上最容易查到的那种方式),我作为小菜瓜,当然不会,凉凉。
百度(提前批一面挂,正式批三面都面完):
1、说说你的项目,具体一点,数据是什么,为什么这么做,好处是什么,精度?
2、说下boosting算法,你了解的。
3、说一下LR和SVM的区别,要详细,LR和数据分布有没有关系?
4、聚类算法熟悉吗?
5、一个句子的逆序输出,I am a boy? boy a am I?,要bugfree,各种边界问题,特殊情况
6、现在有一亿个样本,你如何找到单词最相似的?
7、假设现在有一万个数据,每个数据被取到的概率是不同的,1/2,1/3,1/100,现在如果是你,你会怎么取这一批数据?,数据有好有坏
8、十进制转2进制的最优化算法?
9、python中 +和join的区别。
10、推荐算法了解吗?你怎么给用户做推荐。
这里特别提醒一句,百度的面试非常重视基础,不要整花里胡哨的,基础啊兄弟们。我二面的时候,机器学习那一套,从预处理到Model,每个细节都讲了,那75min,把我掏干了。
追一科技(一面挂,聊得很开心):
1、Adaboost详细,adaboost的权值和RF比较
2、比赛的介绍
3、boosting算法
4、one-hot编码,以及logn的编码
5、前序,two sum 有序数组
6、卷积神经网络,好处是什么
7、为什么用小卷积核
8、介绍下项目论文
9、分类评价指标,ROC
10、线性回归为什么用均方差
浦发(现场面(offer)):
1、先做题,三四道题目,很简单,全A。然后面试15分钟,我最后还交了体检报告与背调。
小红书(三面挂):
一面:做题,leetcode124题,磕磕绊绊做了出来。然后聊项目,问boosting算法细节,非常细
二面:聊项目,LR公式,设计一个实际模型,我忘记是什么模型了。。。。。。不难
三面:两个open case,①photoshop里面抠图是什么原理?怎么实现的 ②设计一个知乎推荐系统
事实证明,我三面答的不好,凉凉。三面挂的人很少很少。
360(二面挂):
一面:
1、是个妹子面的,问项目,做题目比较简单,二分查找之类的
2、项目+简历,问了很多机器学习基础,LR、SVM、boosting一套细节。
3、调参细节
二面:
很玄学,二面聊得很开心,全基础问题,我也全部答了出来,面经找不到了,但是真的很简单,然后告诉我挂了。
同程艺龙(奇怪的公司,HR加我微信,说这两天给我发offer,现在一个多月了,似乎还必须要去实习,体验不好)
一面:
1、GCN公式推导来一遍,每个参数
2、GBDT和XGboost区别(具体点),为什么GBDT用负梯度当做残差,xgboost你讲讲,要详细,公式
3、xgboost为什么用二阶导
4、牛顿法公式推一遍、要公式
5、假设信息增益函数entropy(x,y),实现特征重要性的计算featureImportce(feature,label)(写代码)
6、用过哪些模型,说说,图自编码器、cnn等你了解深度学习模型
7、CTR怎么做的?MLR懂吗?分词是啥?
8、能不能来实习?不能来实习的话就…(我说,我懂你的意思)
二面:
1、了解FM、FFM吗
2、需要用归一化的模型有哪些
3、RF和GBDT区别、详细一点
4、CTR讲一下,大规模稀疏的特征怎么处理
5、怎么判断过拟合,有哪些方法,dropout和RF,dropout是随机的吗
6、模型的权重和特征的权重怎么处理
7、L1和L2正则,全部内容
8、对统计这一块了解吗?p值是什么
9、聚类算法,聚类怎么确定K值
10、AUC值在广告预测中的指标、NLP了解吗?
11、FM算法、FFM算法讲一讲
华为(打电话叫我转岗,我就投了AI&Cloud的开发,事实证明这个举动真的很蠢)
一面:
1、项目+做题,好像是排列组合的题目。
二面:
面试体验一般。上来问我会不会C,要求必须用C写代码。我说我不会用C,用java行不行,我写出来了。他说java不大行啊,我就不管了,这是我第一次遇见必须用指定语言做题目的。然后问我opencase,海量数据问题,我没答好。我承认我太菜了,我以为堆是数组,结果堆是树。我还和他battle一会,哈哈哈,sorry,的确是我的问题。然后挂掉
电信云(这个就面试体验超级无敌差!!!)
一面:
不问项目不问基础不问技术,叫我写pandas,我说我不记得函数名了,一般随用随查。面试官就很不开心了,然后问我python的边边角角,我又不记得,我只能一路说我不会。一共面了十分钟,甚至我以为我面了一家外包公司,八字不合,拜拜您嘞。
网易互娱(一二三面)
一面:项目+机器学习基础
二面:聊人生聊理想
三面:聊人生聊理想
凉
招行信用卡(二面凉):
一面:项目、深度学习和机器学习区别、过拟合、正则化那些,boosting调参
二面:人工智能趋势、tensorflow用的多吗、接收加班吗、这里我嘴贱,我明明不懂deepFM,我还说了,他让我做个比较推荐算法那些,我不懂。友情提示:不懂得别瞎说
陌陌(这是我体验的比较好的一家,两个面试官超级有水平,点赞+1):
一面:项目非常非常细,细到怀疑人生。正则化、过拟合、boosting、LR公式推导,梯度下降等等
二面:面试官直接说我们这个项目没什么实际意义,哈哈哈,我被怼了还很开心,因为他说的对。然后他还指导我怎么去水论文,我非常感动,真的很nice。
中兴:
聊人生聊理想,然后把我挂了。估计今年中兴都挑花眼了,我这个双非本科当然不行啦。
斗鱼(offer):
两道编程(区间合并),手写tensorflow cnn全套,二分类,机器学习深度学习基础。
阿里测开(offer):
阿里一共四个技术,一轮hr,第一轮技术冒泡排序、二分查找,java基础,线程进程等等;二面没有代码,问我项目,机器学习聊了很多;三面,open case;四面交叉面:比较难,问测试的内容,把我怼的一愣一愣,但好在我水过了。
先更新这么多吧,我想到什么再更新,我真的记不***了。
下面开始技术总结:
1、基础很重要,至少那些model不要求100%,七七八八个大概你要能讲吧。
2、刷题很重要,我是个小菜瓜,我什么都不行,所以没去的了BAT。
3、运气比前两个都重要。
我刷的一些题目,都放在了我的博客:我的博客八月份更新的,可想而知,我有多久没有刷题了,大家不能像我一样菜,不允许喷我,我不能接收你的批评(哼)