背景
最近公司在做一些业务上的架构调整,有一部分是数据从mysql采集到Starrocks,之前的一套方法是走 debezium 到 puslar 到 starrocks,这一套下来比较需要配置很多东西,而且出现问题以后,需要修改很多配置,而且现阶段问题比较多,且采集的是所有线上的数据库,维护起来很费劲。
于是我们进行了采集的数据流调整,使用 Flink CDC这一套,这一套 是端到端的,且采用配置化的方式,支持schema的变更,无需再多一层中间存储层。
最终配置
关于flink cdc的使用配置可以参考Flink CDC 源码解析–整体流程,我能这里只贴出来我们最终使用的配置:
source:
type: mysql
name: Database mysql to Data warehouse
hostname: xxxx
port: 3306
username: xxx
password: xxx
tables: db1.table1
server-id: 556401-556500
scan.startup.mode: initial
scan.snapshot.fetch.size: 8096
scan.incremental.snapshot.chunk.size: 16192
debezium.max.queue.size: 162580
debezium.max.batch.size: 40960
debezium.poll.interval.ms: 50
scan.only.deserialize.captured.tables.changelog.enabled: true
scan.parallel-deserialize-changelog.enabled: true
heartbeat.interval: 5s
scan.newly-added-table.enabled: true
sink:
type: starrocks
name: StarRocks Sink
jdbc-url: xxx
load-url: xxx
username: xxx
password: xxx
sink.buffer-flush.interval-ms: 5000
table.create.properties.replication_num: 3
table.create.num-buckets: 3
route:
- source-table: db1.\.*
sink-table: db1.<>
replace-symbol: <>
description: route all tables to starrrocks
pipeline:
name: Sync mysql Database to StarRocks
parallelism: 1
schema.change.behavior: EVOLVE
遇到的问题
-
EventHeaderV4反序列化问题
报错如下:Caused by: io.debezium.DebeziumException: Failed to deserialize data of EventHeaderV4{timestamp=1732257303000, eventType=WRITE_ROWS, serverId=28555270, headerLength=19, dataLength=320, nextPosition=383299196, flags=0} at io.debezium.connector.mysql.MySqlStreamingChangeEventSource.wrap(MySqlStreamingChangeEventSource.java:1718) ... 5 more Caused by: com.github.shyiko.mysql.binlog.event.deserialization.EventDataDeserializationException: Failed to deserialize data of EventHeaderV4{timestamp=1732257303000, eventType=WRITE_ROWS, serverId=28555270, headerLength=19, dataLength=320, nextPosition=383299196, flags=0} at com.github.shyiko.mysql.binlog.event.deserialization.EventDeserializer.deserializeEventData(EventDeserializer.java:358) at com.github.shyiko.mysql.binlog.event.deserialization.EventDeserializer.nextEvent(EventDeserializer.java:252) at io.debezium.connector.mysql.MySqlStreamingChangeEventSource$1.nextEvent(MySqlStreamingChangeEventSource.java:388) at com.github.shyiko.mysql.binlog.BinaryLogClient.listenForEventPackets(BinaryLogClient.java:1187) ... 3 more Caused by: java.io.EOFException: Failed to read remaining 28 of 36 bytes from position 258280448. Block length: 183. Initial block length: 316. at com.github.shyiko.mysql.binlog.io.ByteArrayInputStream.fill(ByteArrayInputStream.java:115) at com.github.shyiko.mysql.binlog.io.ByteArrayInputStream.read(ByteArrayInputStream.java:105) at io.debezium.connector.mysql.RowDeserializers.deserializeVarString(RowDeserializers.java:264) at io.debezium.connector.mysql.RowDeserializers$WriteRowsDeserializer.deserializeVarString(RowDeserializers.java:192) at com.github.shyiko.mysql.binlog.event.deserialization.AbstractRowsEventDataDeserializer.deserializeCell(AbstractRowsEventDataDeserializer.java:189) at com.github.shyiko.mysql.binlog.event.deserialization.AbstractRowsEventDataDeserializer.deserializeRow(AbstractRowsEventDataDeserializer.java:143) at com.github.shyiko.mysql.binlog.event.deserialization.WriteRowsEventDataDeserializer.deserializeRows(WriteRowsEventDataDeserializer.java:75) at com.github.shyiko.mysql.binlog.event.deserialization.WriteRowsEventDataDeserializer.deserialize(WriteRowsEventDataDeserializer.java:65) at com.github.shyiko.mysql.binlog.event.deserialization.WriteRowsEventDataDeserializer.deserialize(WriteRowsEventDataDeserializer.java:38) at com.github.shyiko.mysql.binlog.event.deserialization.EventDeserializer.deserializeEventData(EventDeserializer.java:352) ... 6 more过段时间自己恢复
这个现象比较诡异,过段时间就自己恢复了,目前怀疑的点:- mysql连接数和带宽问题
- msyql服务端的配置问题,可以参考Flink CDC FAQ
mysql> set global slave_net_timeout = 120; mysql> set global thread_pool_idle_timeout = 120; - 作业反压导致,参考阿里云Flink
execution.checkpointing.interval=10min execution.checkpointing.tolerable-failed-checkpoints=100 debezium.connect.keep.alive.interval.ms = 40000
-
Starrocks Be 内存受限
java.lang.RuntimeException: com.starrocks.data.load.stream.exception.StreamLoadFailException: Transaction prepare failed, db: shoufuyou_fund, table: fund_common_repay_push, label: flink-4c6c8cfb-5116-4c38-a60e-a1b87cd6f2f2, responseBody: { "Status": "MEM_LIMIT_EXCEEDED", "Message": "Memory of process exceed limit. QUERY Backend: 172.17.172.251, fragment: 9048ed6e-6ffb-04db-081b-a4966b179387 Used: 26469550752, Limit: 26316804096. Mem usage has exceed the limit of BE" } errorLog: null at com.starrocks.data.load.stream.v2.StreamLoadManagerV2.AssertNotException(StreamLoadManagerV2.java:427) at com.starrocks.data.load.stream.v2.StreamLoadManagerV2.write(StreamLoadManagerV2.java:252) at com.starrocks.connector.flink.table.sink.v2.StarRocksWriter.write(StarRocksWriter.java:143) at org.apache.flink.streaming.runtime.operators.sink.SinkWriterOperator.processElement(SinkWriterOperator.java:182) at org.apache.flink.cdc.runtime.operators.sink.DataSinkWriterOperator.processElement(DataSinkWriterOperator.java:178) at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.pushToOperator(CopyingChainingOutput.java:75) at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:50) at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:29) at org.apache.flink.streaming.api.operators.StreamMap.processElement(StreamMap.java:38) at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:245) at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:217) at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:169) at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:68) at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:616) at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:231) at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:1071) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:1020) at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:959) at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:938) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:751) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:567) at java.lang.Thread.run(Thread.java:879) Caused by: com.starrocks.data.load.stream.exception.StreamLoadFailException: Transaction prepare failed, db: shoufuyou_fund, table: fund_common_repay_push, label: flink-4c6c8cfb-5116-4c38-a60e-a1b87cd6f2f2, responseBody: { "Status": "MEM_LIMIT_EXCEEDED", "Message": "Memory of process exceed limit. QUERY Backend: 172.17.172.251, fragment: 9048ed6e-6ffb-04db-081b-a4966b179387 Used: 26469550752, Limit: 26316804096. Mem usage has exceed the limit of BE" } errorLog: null at com.starrocks.data.load.stream.TransactionStreamLoader.prepare(TransactionStreamLoader.java:221) at com.starrocks.data.load.stream.v2.TransactionTableRegion.commit(TransactionTableRegion.java:247) at com.starrocks.data.load.stream.v2.StreamLoadManagerV2.lambda$init$0(StreamLoadManagerV2.java:210) ... 1 more由于我们 Starrocks BE的内存是在 32GB,开启多个Flink CDC 任务,会导致CDC初始化的时候,写入BE的数据太多,从而BE内存不够,
解决: 降低 写入Starrocks的并行读,不要太多CDC同时并行
也可以参考Troubleshooting StarRocks memory hog issues -
JobManager Direct buffer memory不够
java. lang.OutOfMemoryError: Direct buffer memory at lava.n10.B1ts.reserveMemory(B1ts.lava:/08 ~ 7:1.8.0 312. at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123) ~[7:1.8.0_372] at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311) ~[7:1.8.0_3721 at sun.nio.ch.Util.getTemporaryDirectBuffer(Util.java:247) ~[7:1.8.0_372] at sun.nio.ch.IOUtil.write(IOUtil.java:60) ~[7:1.8.0_372] at sun.nio.ch.FileChannelImpl.write(FileChannelImpl.java:234) ~[?:1.8.0_372] at java.nio.channels.Channels.writeFullyImpl(Channels.java:78) ~[?:1.8.0_372] at java.nio.channels.Channels$1.write(Channels.java:174) ~[7:1.8.0_372] at org.apache.flink.core.fs.OffsetAware0utputStream.write(0ffsetAware0utputStream.java:48) ~[ververica-connector-vvp-1.17-vvr-8.0.9-2-SNAPSHOT-jar-with-dependencies.jar:1.17-vvr-8.0.9-2-SNAPSHOT] at org.apache.flink.core.fs.RefCountedFileWithStream.write(RefCountedFileWithStream.java:54) ~[ververica-connector-vvp-1.17-vvr-8.0.9-2-SNAPSHOT-jar-with-dependencies. jar: 1.17-vvr-8.0.9-2-SNAPSHOT at org.apache.flink.core.fs.RefCountedBufferingFileStream.write(RefCountedBufferingFileStream.java:88) ~[ververica-connector-vvp-1.17-vvr-8.0.9-2-SNAPSHOT-jar-with-dependencies.jar:1.17-vvr-8.0.9-2-SNAPSHOT] at ora.aoache.flink.fs.osshadooo.writer.OSSRecoverableFsDataOutoutStream.write OSSRecoverableFsDataOutoutStream.1ava:130) ~?:? at org.apache.flink. runtime.state.filesystem.FsCheckpointMetadata0utputStream.write(FsCheckpointMetadata0utputStream.java:78) ~[flink-dist-1.17-vvr-8.0.9-2-SNAPSHOT. jar:1.17-vvr-8.0.9-2-SNAPSHOT] at java.io.Data0utputStream.write(DataOutputStream.java:107) ~[7:1.8.0_372] at java.io.Filter0utputStream.write(FilterOutputStream.java:97) ~[7:1.8.0_372] at org.apache.flink. runtime.checkpoint.metadata.MetadataV2V3SerializerBase.serializeStreamStateHandle(MetadataV2V3SerializerBase.java:703) ~[flink-dist-1.17-vvr-8.0.9-2-SNAPSHOT. jar:1.17-vvr-8.0.9-2-SNAPSHOT] at org.apache. flink.runtime.checkpoint.metadata.MetadataV3Serializer.serializeStreamStateHandle(MetadataV3Serializer.java:264) ~[flink-dist-1.17-vvr-8.0.9-2-SNAPSHOT.jar:1.17-vvr-8.0.9-2-SNAPSHOT] at org.apache.flink. runtime.checkpoint.metadata.MetadataV3Serializer.serialize0peratorState(MetadataV3Serializer.java:109) ~[flink-dist-1.17-vvr-8.0.9-2-SNAPSHOT.jar:1.17-vvr-8.0.9-2-SNAPSHOT] at org.apache. flink. runtime.checkpoint.metadata.MetadataV2V3SerializerBase.serializeMetadata(MetadataV2V3SerializerBase.java:153) ~[flink-dist-1.17-vvr-8.0.9-2-SNAPSHOT.jar:1.17-vvr-8.0.9-2-SNAPSHOT] at org.apache.flink. runtime.checkpoint.metadata.MetadataV3Serializer.serialize(MetadataV3Serializer.java:83) ~[flink-dist-1.17-vvr-8.0.9-2-SNAPSHOT.jar:1.17-vvr-8.0.9-2-SNAPSHOT] at org.apache.flink.runtime.checkpoint.metadata.MetadataV4Serializer.serialize(MetadataV4Serializer.java:56) ~[flink-dist-1.17-vvr-8.0.9-2-SNAPSHOT.jar:1.17-vvr-8.0.9-2-SNAPSHOT]| at org.apache. flink. runtime.checkpoint.Checkpoints.storeCheckpointMetadata(Checkpoints. java:102) ~[flink-dist-1.17-vvr-8.0.解决:
增加配置:jobmanager.memory.off-heap.size: 512mb -
TaskManager jvm内存不够
java.util.concurrent.TimeoutException: Heartbeat of TaskManager with id job-da2375f5-405b-4398-a568-eaba9711576d-taskmanager-1-34 timed out. at org.apache.flink.runtime.jobmaster.JobMaster$TaskManagerHeartbeatListener.notifyHeartbeatTimeout(JobMaster.java:1714) at org.apache.flink.runtime.heartbeat.DefaultHeartbeatMonitor.run(DefaultHeartbeatMonitor.java:158) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.lambda$handleRunAsync$4(AkkaRpcActor.java:453) at org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.runWithContextClassLoader(ClassLoadingUtils.java:68) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:453) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:218) at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:84) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:168) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:24) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:20) at scala.PartialFunction.applyOrElse(PartialFunction.scala:127) at scala.PartialFunction.applyOrElse$(PartialFunction.scala:126) at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:20) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:175) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:176) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:176) at akka.actor.Actor.aroundReceive(Actor.scala:537) at akka.actor.Actor.aroundReceive$(Actor.scala:535) at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:220) at akka.actor.ActorCell.receiveMessage(ActorCell.scala:579) at akka.actor.ActorCell.invoke(ActorCell.scala:547) at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:270) at akka.dispatch.Mailbox.run(Mailbox.scala:231) at akka.dispatch.Mailbox.exec(Mailbox.scala:243) at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289) at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056) at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692) at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:175)解决:
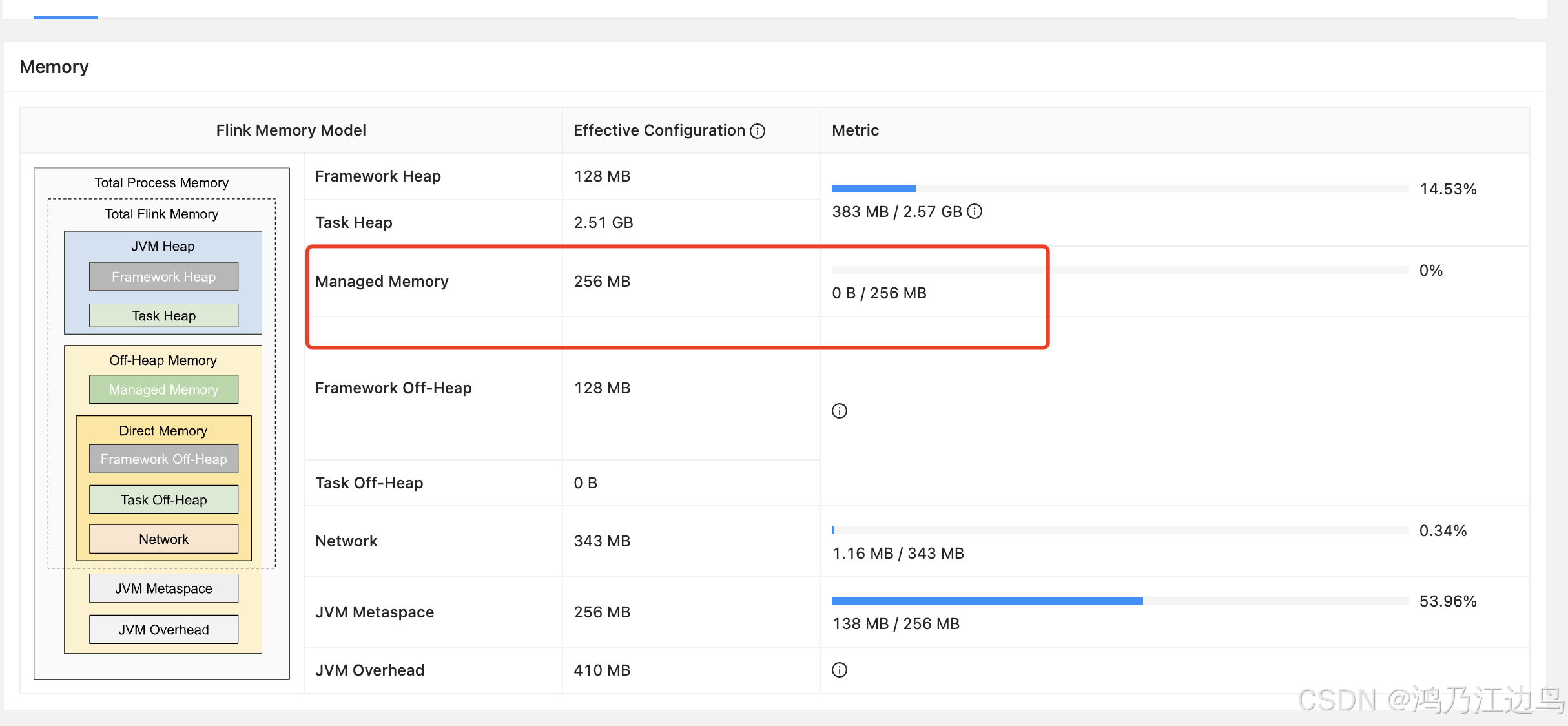
在运行的过程中我们发现TaskManager的taskmanager.memory.managed.size内存使用一直为0,这是因为我们这里没有状态的存储,只是ETL,可以参考Flink TaskManager Memory Model
所以增加以下配置
taskmanager.memory.managed.size: 256mb taskmanager.memory.process.size: 4096m table.exec.state.ttl: 1 m -
读取mysql数据过慢
java.lang.RuntimeException: One or more fetchers have encountered exception at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager.checkErrors(SplitFetcherManager.java:261) ~[flink-connector-files-1.17-vvr-8.0.9-2-SNAPSHOT.jar:1.17-vvr-8.0.9-2-SNAPSHOT] at org.apache.flink.connector.base.source.reader.SourceReaderBase.getNextFetch(SourceReaderBase.java:185) ~[flink-connector-files-1.17-vvr-8.0.9-2-SNAPSHOT.jar:1.17-vvr-8.0.9-2-SNAPSHOT] at org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:144) ~[flink-connector-files-1.17-vvr-8.0.9-2-SNAPSHOT.jar:1.17-vvr-8.0.9-2-SNAPSHOT] at org.apache.flink.streaming.api.operators.SourceOperator.pollNext(SourceOperator.java:779) ~[flink-dist-1.17-vvr-8.0.9-2-SNAPSHOT.jar:1.17-vvr-8.0.9-2-SNAPSHOT] at org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:457) ~[flink-dist-1.17-vvr-8.0.9-2-SNAPSHOT. ... Caused by: java.lang.RuntimeException: SplitFetcher thread 0 received unexpected exception while polling the records at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:165) ~[flink-connector-files-1.17-vvr-8.0.9-2-SNAPSHOT.jar:1.17-vvr-8.0.9-2-SNAPSHOT] at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.run(SplitFetcher.java:114) ~[flink-connector-files-1.17-vvr-8.0.9-2-SNAPSHOT.jar:1.17-vvr-8.0.9-2-SNAPSHOT] at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_372] at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_372] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_372] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_372] ... 1 more Caused by: java.lang.IllegalStateException: The connector is trying to read binlog starting at Struct{version=1.9.8.Final,connector=mysql,name=mysql_binlog_source,ts_ms=1732052840471,db=,server_id=0,file=mysql-bin.051880,pos=347695811,row=0}, but this is no longer available on the server. Reconfigure the connector to use a snapshot when needed. at org.apache.flink.cdc.connectors.mysql.debezium.task.context.StatefulTaskContext.loadStartingOffsetState(StatefulTaskContext.java:212) ~[?:?] at org.apache.flink.cdc.connectors.mysql.debezium.task.context.StatefulTaskContext.configure(StatefulTaskContext.java:133) ~[?:?] at org.apache.flink.cdc.connectors.mysql.debezium.reader.BinlogSplitReader.submitSplit(BinlogSplitReader.java:105) ~[?:?] at org.apache.flink.cdc.connectors.mysql.debezium.reader.BinlogSplitReader.submitSplit(BinlogSplitReader.java:71) ~[?:?] at org.apache.flink.cdc.connectors.mysql.source.reader.MySqlSplitReader.pollSplitRecords(MySqlSplitReader.java:119) ~[?:?] at org.apache.flink.cdc.connectors.mysql.source.reader.MySqlSplitReader.fetch(MySqlSplitReader.java:90) ~[?:?] at org.apache.flink.connector.base.source.reader.fetcher.FetchTask.run(FetchTask.java:58) ~[flink-connector-files-1.17-vvr-8.0.9-2-SNAPSHOT.jar:1.17-vvr-8.0.9-2-SNAPSHOT] at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:162) ~[flink-connector-files-1.17-vvr-8.0.9-2-SNAPSHOT.jar:1.17-vvr-8.0.9-2-SNAPSHOT] at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.run(SplitFetcher.java:114) ~[flink-connector-files-1.17-vvr-8.0.9-2-SNAPSHOT.jar:1.17-vvr-8.0.9-2-SNAPSHOT] at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_372] at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_372] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_372] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_372] ... 1 more解决:
参考debezium connectors和阿里云,增加如下参数:debezium.max.queue.size: 162580 debezium.max.batch.size: 40960 debezium.poll.interval.ms: 50 scan.only.deserialize.captured.tables.changelog.enabled: true -
增量读取过慢,导致binlog 已经没了
参考阿里云,增加如下参数scan.parallel-deserialize-changelog.enabled: true scan.parallel-deserialize-changelog.handler.size: 4 heartbeat.interval: 5s