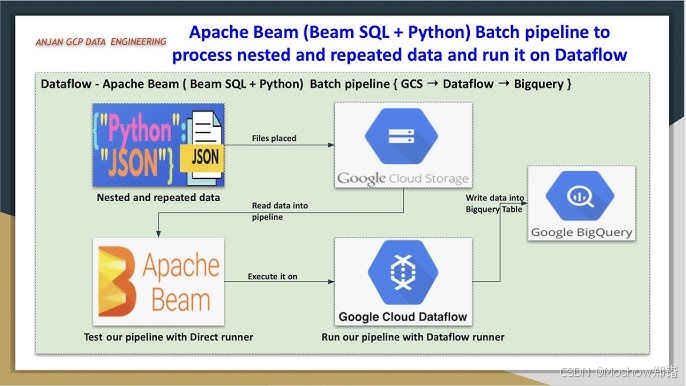
在 Google Cloud Platform (GCP) 中,Pub/Sub、Dataflow 和 BigQuery 是构建数据处理和分析管道的强大工具。以下是它们的架构搭配及详细实现攻略。
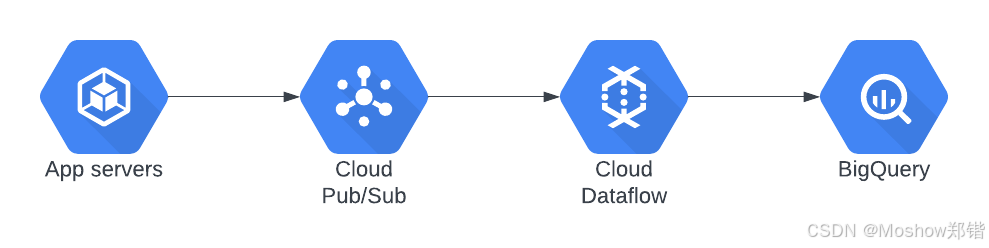
架构概述
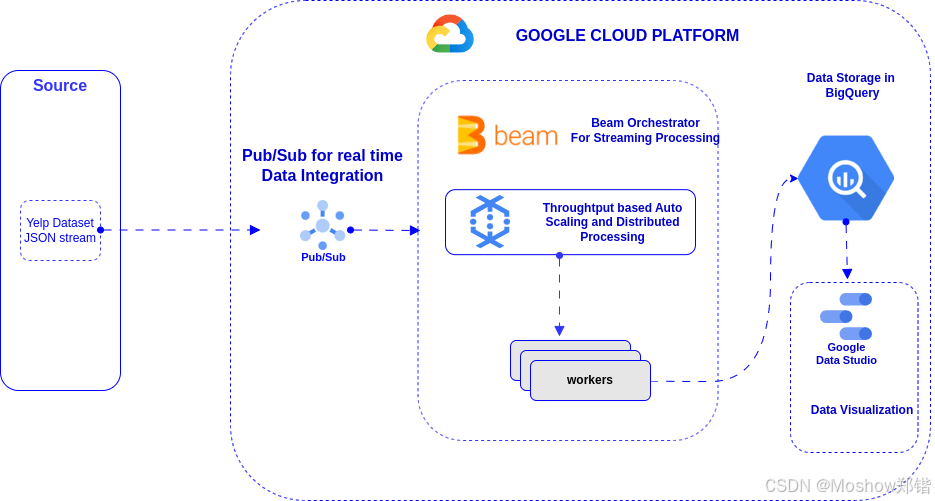
-
Pub/Sub:作为消息队列,Pub/Sub 用于接收和传输实时数据流。它能够处理高吞吐量的消息,并将数据分发到多个订阅者。
-
Dataflow:用于数据处理和转换。Dataflow 支持流式和批处理,可以从 Pub/Sub 中读取数据,进行实时处理,然后将结果写入 BigQuery 或其他存储。
-
BigQuery:作为数据仓库,BigQuery 用于存储和分析大规模数据。经过 Dataflow 处理的数据可以直接写入 BigQuery,以便后续的分析和查询。
架构图
+-----------+ +-----------+ +-----------+
| | | | | |
| Pub/Sub +------>+ Dataflow +------>+ BigQuery |
| | | | | |
+-----------+ +-----------+ +-----------+
实现攻略
1. 设置 Pub/Sub
-
创建 Pub/Sub 主题:
- 登录到 GCP 控制台。
- 导航到 Pub/Sub 服务。
- 创建一个新的主题,命名为
my-topic。
-
发布消息:
- 可以使用 GCP 提供的 SDK 或命令行工具(如
gcloud)发布消息到主题。
- 可以使用 GCP 提供的 SDK 或命令行工具(如
gcloud pubsub topics publish my-topic --message "Hello, World!"2. 设置 Dataflow
-
创建 Dataflow 作业:
- 使用 Apache Beam SDK 创建 Dataflow 作业。可以选择 Java 或 Python 语言。
?为什么Java语言的Pipeline更加高效和快速
在 Google Cloud Dataflow 中,使用 Java 编写的 Dataflow pipeline 通常比使用 JavaScript(jjs)编写的 pipeline 更加高效和快速。这主要是因为以下几个原因:
1. 性能优化
-
Java 生态系统:Java 是 Dataflow 的原生语言,Google 对 Java 的支持和优化更加深入,能够充分利用 JVM 的性能优势。
-
编译优化:Java 是编译型语言,经过编译后的代码在运行时通常会更快,而 JavaScript 是解释型语言,可能在性能上有所欠缺。
2. 资源利用
-
资源管理:Java 版的 Dataflow 可能会更好地利用底层资源(如 CPU 和内存),因为它可以更直接地与 Dataflow 的执行引擎交互。
-
并行处理:Java 的并行处理能力在 Dataflow 中得到了很好的实现,能够更高效地处理大规模数据集。
3. 功能支持
-
API 支持:Java 版本的 Dataflow API 功能更为全面,能够利用更多的 Dataflow 特性和优化。
4. 复杂性处理
-
复杂逻辑:对于复杂的数据处理逻辑,Java 的类型系统和语言特性可能会提供更好的性能和可维护性。
示例代码(JJS)
在 Google Cloud Dataflow 中,使用 JavaScript(jjs)编写的 pipeline 类是通过 Apache Beam 的 JavaScript SDK 实现的。虽然 JavaScript SDK 仍在不断发展中,但它主要用于快速原型开发和小规模数据处理。以下是一些关于如何使用 JavaScript 编写 Dataflow pipeline 的基本信息和示例。
注意事项
-
性能:如前所述,JavaScript 版本的 Dataflow 在性能上可能不如 Java 版本,尤其是在处理大规模数据时。
-
功能限制:JavaScript SDK 可能不支持所有 Apache Beam 的功能,因此在使用时需仔细检查文档。
-
调试和测试:确保在本地进行充分的测试,尤其是在处理复杂的转换时。
你可以使用 JavaScript 编写 Dataflow pipeline,以下是一个简单的示例:
const { Pipeline } = require('@apache-beam/beam');
const { TextIO } = require('@apache-beam/beam/transforms/textio');
const { MapElements } = require('@apache-beam/beam/transforms/map');
const { ParDo } = require('@apache-beam/beam/transforms/par_do');
// 创建一个新的 pipeline
const pipeline = new Pipeline();
// 读取文本文件
const input = pipeline.apply(TextIO.read().from('gs://your-bucket/input.txt'));
// 处理数据
const output = input.apply(
ParDo.of(MapElements.via((line) => {
// 处理每一行
return line.toUpperCase(); // 示例:将每一行转换为大写
}))
);
// 写入输出文件
output.apply(TextIO.write().to('gs://your-bucket/output.txt'));
// 运行 pipeline
pipeline.run().waitUntilFinish();
示例代码(Python)
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
#//sort out by https://zhengkai.blog.csdn.net/
class ProcessMessage(beam.DoFn):
def process(self, element):
# 处理消息
yield element.upper() # 示例转换
def run():
options = PipelineOptions()
with beam.Pipeline(options=options) as p:
(p
| 'ReadFromPubSub' >> beam.io.ReadFromPubSub(topic='projects/YOUR_PROJECT/topics/my-topic')
| 'ProcessMessages' >> beam.ParDo(ProcessMessage())
| 'WriteToBigQuery' >> beam.io.WriteToBigQuery(
'YOUR_PROJECT:YOUR_DATASET.YOUR_TABLE',
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND)
)
if __name__ == '__main__':
run()
- 部署 Dataflow 作业:
- 将作业打包并使用
gcloud命令行工具提交到 Dataflow。
- 将作业打包并使用
gcloud dataflow jobs run my-dataflow-job \
--gcs-location gs://YOUR_BUCKET/path/to/your/template \
--parameters inputTopic=projects/YOUR_PROJECT/topics/my-topic
示例代码(JAVA)*推荐
使用 Java 和 Apache Beam SDK 创建 Google Cloud Dataflow 作业的基本步骤如下。以下是一个简单的示例代码,演示如何从 Pub/Sub 读取消息,处理数据,并将结果写入 BigQuery。
设置环境
确保您已经安装了以下工具和库:
- Java Development Kit (JDK) 8 或更高版本
- Apache Maven
- Google Cloud SDK
- Apache Beam SDK for Java
POM.xml
创建一个 Maven 项目,pom.xml 文件应包含 Apache Beam 依赖项:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>dataflow-example</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
<beam.version>2.45.0</beam.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-io-google-cloud-platform</artifactId>
<version>${beam.version}</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-io-pubsub</artifactId>
<version>${beam.version}</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-io-bigquery</artifactId>
<version>${beam.version}</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
<version>${beam.version}</version>
</dependency>
</dependencies>
</project>
创建Java 管道处理类DataflowPipeline.java
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.transforms.DoFn;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.io.gcp.pubsub.PubsubIO;
import org.apache.beam.sdk.io.gcp.bigquery.BigQueryIO;
import org.apache.beam.sdk.transforms.MapElements;
import org.apache.beam.sdk.values.TypeDescriptor;
//sort out by https://zhengkai.blog.csdn.net/
public class DataflowPipeline {
public static void main(String[] args) {
// 创建 PipelineOptions
PipelineOptionsFactory.register(MyOptions.class);
MyOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().as(MyOptions.class);
// 创建 Pipeline
Pipeline pipeline = Pipeline.create(options);
// 从 Pub/Sub 读取数据,处理并写入 BigQuery
pipeline.apply("ReadFromPubSub", PubsubIO.readStrings().fromTopic(options.getInputTopic()))
.apply("ProcessMessages", ParDo.of(new ProcessMessageFn()))
.apply("WriteToBigQuery", BigQueryIO.writeTableRows()
.to(options.getOutputTable())
.withSchema(options.getOutputSchema())
.withWriteDisposition(BigQueryIO.Write.WriteDisposition.WRITE_APPEND));
// 运行 Pipeline
pipeline.run().waitUntilFinish();
}
// 处理消息的 DoFn
static class ProcessMessageFn extends DoFn<String, TableRow> {
@ProcessElement
public void processElement(ProcessContext context) {
String message = context.element();
// 处理消息,转换为 TableRow
TableRow row = new TableRow().set("message", message.toUpperCase());
context.output(row);
}
}
// 自定义 PipelineOptions
public interface MyOptions extends PipelineOptions {
@Description("Input Pub/Sub topic")
String getInputTopic();
void setInputTopic(String value);
@Description("Output BigQuery table")
String getOutputTable();
void setOutputTable(String value);
@Description("Output BigQuery schema")
String getOutputSchema();
void setOutputSchema(String value);
}
}
3. 设置 BigQuery
- 创建 BigQuery 数据集和表:
- 登录到 GCP 控制台。
- 导航到 BigQuery 服务。
- 创建一个新的数据集(例如
YOUR_DATASET)。 - 创建一个表(例如
YOUR_TABLE),定义其模式(schema),与 Dataflow 输出的数据结构相匹配。
BigQuery优化
在 Google BigQuery 中进行查询调优是提升查询性能和降低成本的关键。以下是一些有效的查询调优策略:
-
使用分区和聚簇表
- 分区表:将大表按日期或时间戳等列分区,这样查询时可以只扫描相关分区,减少数据读取量。
- 聚簇表:在分区表中使用聚簇,可以根据某些列的值对数据进行排序,从而加速查询。
- 使用适当的数据类型可以减少存储空间和提高查询性能。例如,尽量使用
INT64而不是FLOAT64,使用STRING而不是BYTES。 - WHERE 子句:在查询中使用
WHERE子句来过滤不必要的数据,减少扫描的数据量。 - LIMIT 子句:如果只需要部分结果,可以使用
LIMIT限制返回的行数。 - 只选择需要的列,避免使用
SELECT *。这可以减少数据传输量和提高查询性能。 - BigQuery 会缓存查询结果,如果相同查询在短时间内重复执行,使用缓存可以显著提高性能。
- 避免不必要的 JOIN:在查询中只包含必要的表,避免多余的 JOIN 操作。
- 使用 ARRAY 和 STRUCT:在适当的情况下,使用 ARRAY 和 STRUCT 类型来减少 JOIN 的需求。
- 对于复杂查询,可以将中间结果存储在临时表中,然后基于这些临时表进行后续查询,减少重复计算。
- 使用 BigQuery 的查询历史和查询计划分析工具,查看查询的执行时间、扫描的数据量和其他性能指标,找出瓶颈。
- 避免复杂的计算:在
SELECT和WHERE子句中避免复杂的计算,可以将计算移到数据加载阶段。 - 使用 WITH 子句:使用公用表表达式 (CTE) 来简化复杂查询。
4. 数据流动
- 数据流动过程:
- 消息发布到 Pub/Sub 主题。
- Dataflow 从 Pub/Sub 读取消息,进行处理(如转换、过滤等)。
- 处理后的数据写入 BigQuery 表中,供后续分析使用。
监控和优化
-
监控:
- 使用 GCP 的 Stackdriver 监控 Pub/Sub、Dataflow 和 BigQuery 的性能和健康状况。
-
优化:
- 根据数据流量和处理需求,调整 Dataflow 作业的并行度和资源配置。
- 使用 BigQuery 的分区和聚簇表功能,提高查询性能和降低成本。
总结
通过结合使用 Pub/Sub、Dataflow 和 BigQuery,您可以构建一个高效、可扩展的数据处理和分析管道。这个架构适用于实时数据处理场景,如日志分析、用户行为跟踪等。根据具体需求,您可以进一步扩展和定制这个架构。