关注公众号,发现CV技术之美
本篇文章由粉丝 @美索不达米亚平原 投稿,原文地址:
https://zhuanlan.zhihu.com/p/477707304
本文介绍我们 CVPR 2022 关于目标检测的知识蒸馏工作: Focal and Global Knowledge Distillation for Detectors,只需要 30 行代码就可以在 anchor-base, anchor-free 的单阶段、两阶段各种检测器上稳定涨点,现在代码已经开源。

论文链接:https://arxiv.org/abs/2111.11837
项目链接:https://github.com/yzd-v/FGD
01
针对问题
1. 目标检测中前背景不平衡问题
前背景的不平衡对于目标检测而言是一个重要的问题,这个问题同样影响着知识蒸馏。
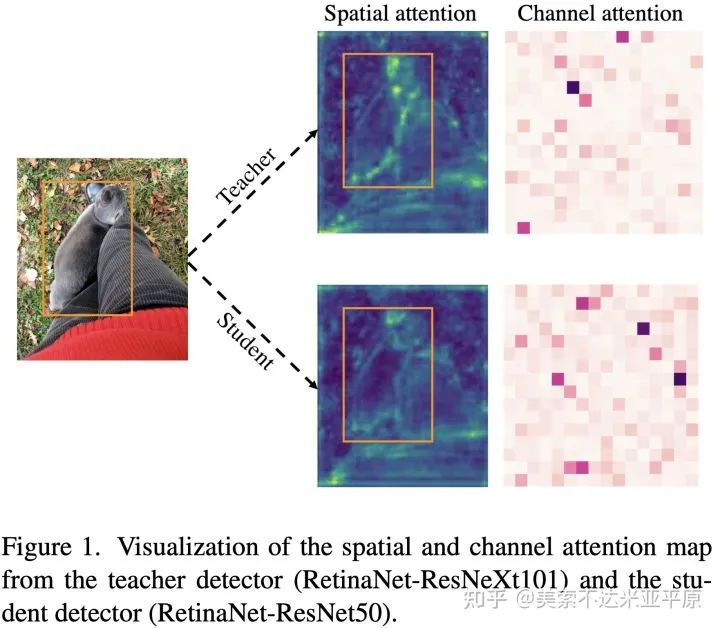
知识蒸馏旨在使学生学习教师的知识,以获得相似的输出从而提升性能。为了探索学生与教师在特征层面的差异,我们首先对二者的特征图进行了可视化。可以看到在空间与通道注意力上,教师与学生均存在较大的差异。其中在空间注意力上,二者在前景中的差异较大,在背景中的差异较小,这会给蒸馏中的学生带来不同的学习难度。
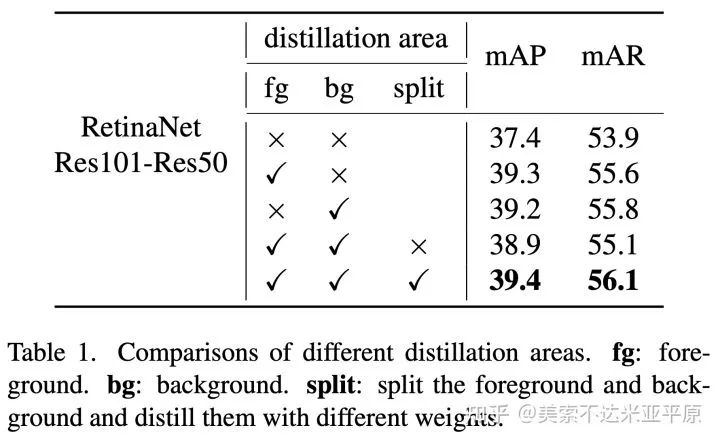
为了进一步探索前背景对于知识蒸馏的影响,我们分离出前背景进行了蒸馏实验,全图一起蒸馏会导致蒸馏性能的下降,将前景与背景分开学生能够获得更好的表现。
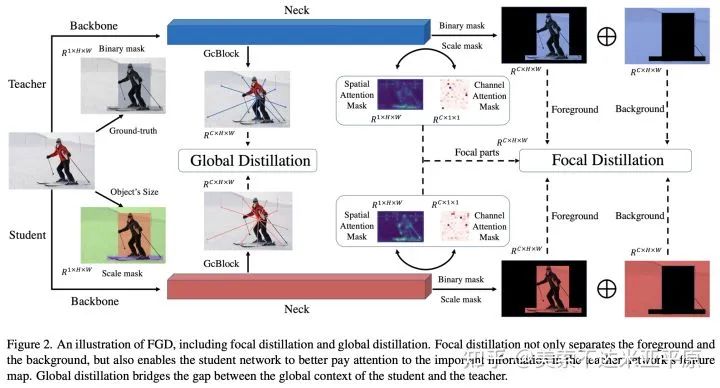
针对学生与教师注意力的差异,前景与背景的差异,我们提出了重点蒸馏Focal Distillation:分离前背景,并利用教师的空间与通道注意力作为权重,指导学生进行知识蒸馏,计算重点蒸馏损失。
2.全局信息的丢失
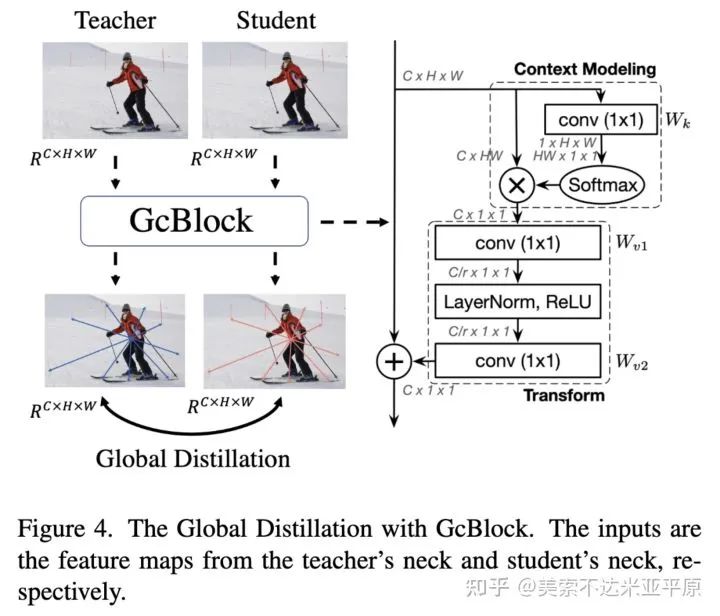
如前所述,Focal Distillation将前景与背景分开进行蒸馏,割断了前背景的联系,缺乏了特征的全局信息的蒸馏。为此,我们提出了全局蒸馏Global Distillation:利用GcBlock分别提取学生与教师的全局信息,并进行全局蒸馏损失的计算。
02
整体框架
FGD仅需要获取学生与教师的特征图,便可完成重点蒸馏损失与全局蒸馏损失的计算,可以很方便的应用到各种类型的检测器上。
03
实验结果
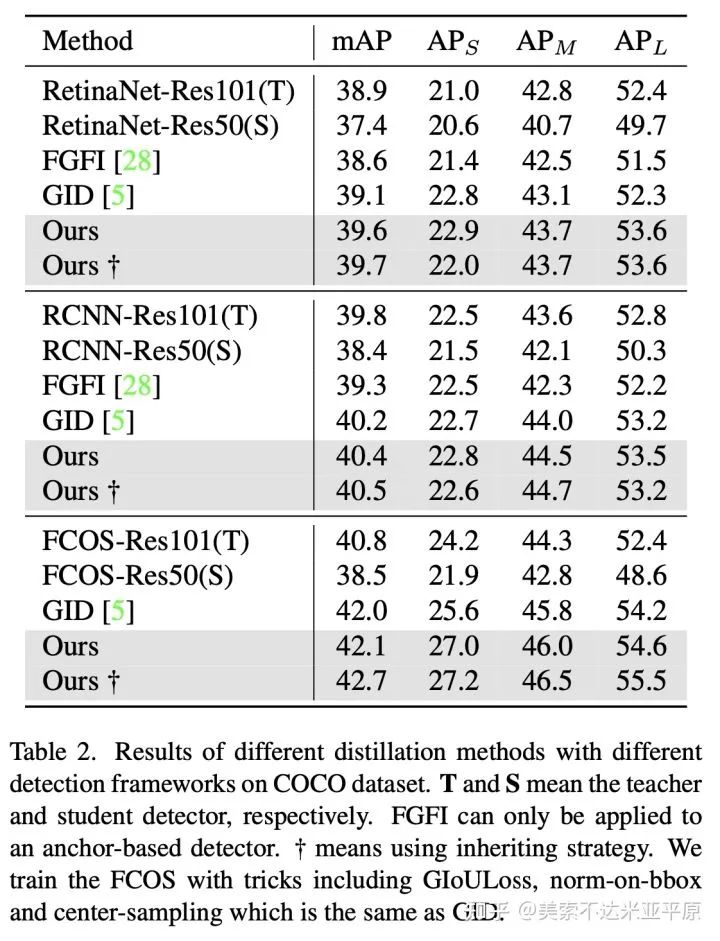
我们对anchor-based与anchor-free的单阶段与二阶段检测器进行了实验,在COCO2017上学生检测器均获得了大幅的AP和AR提升。
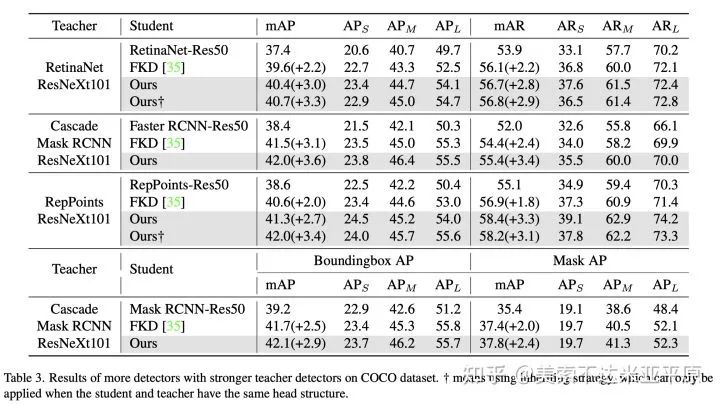
我们采用了具有更强的检测器对学生进行蒸馏,发现当使用更强的模型作为教师进行蒸馏时,FGD为模型能带来更大的性能的提升。例如RetinaNet-R50在ResNet-101和ResNeXt-101的老师蒸馏下,分别可达到39.7和40.7的mAP。
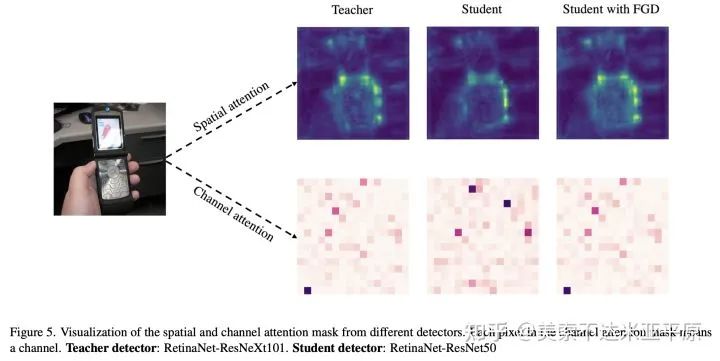
对于使用FGD蒸馏完成后的学生模型,我们再次进行了注意力的可视化。可以看到,经过FGD训练后的学生,空间注意力和通道注意力的分布与教师都非常相似,这表明学生通过蒸馏学到了教师的知识并获得了更好的特征,由此实现了性能的提升。
04
更多蒸馏设置
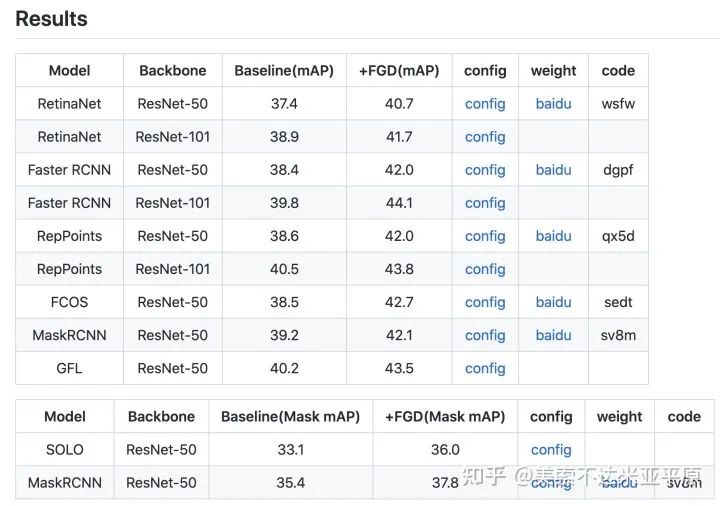
代码基于MMDetection实现,易于复现,且已添加更多的教师与学生蒸馏设置,相关结果也在代码中给出,欢迎大家使用。

END
欢迎加入「目标检测」交流群👇备注:OD
