CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
标题:T2I-Adapter:学习Adapter,为Text-to-Image扩散模型挖掘更多可控能力
作者:Chong Mou, Xintao Wang, Liangbin Xie, Jian Zhang, Zhongang Qi, Ying Shan, XiaoHu Qie
文章链接:https://arxiv.org/abs/2302.08453v1
项目代码:hhttps://github.com/tencentarc/t2i-adapter


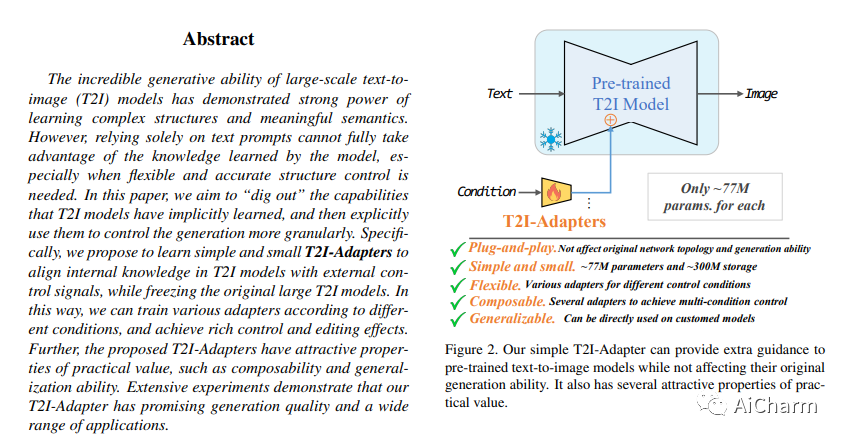
摘要:
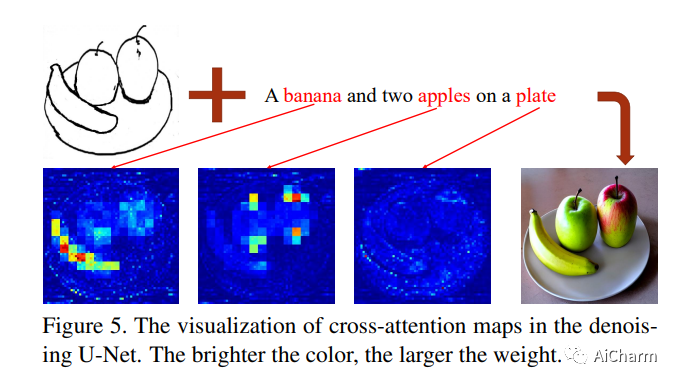
大规模文本到图像 (T2I) 模型令人难以置信的生成能力已经证明了学习复杂结构和有意义的语义的强大能力。然而,仅仅依靠文本提示并不能充分利用模型学到的知识,尤其是在需要灵活准确的结构控制时。在本文中,我们的目标是“挖掘”出 T2I 模型隐式学习的能力,然后显式地使用它们来更细粒度地控制生成。具体来说,我们建议学习简单和小型的 T2I-Adapters 以对齐内部知识具有外部控制信号的T2I模型,同时冻结原有的大型T2I模型。这样,我们可以根据不同的条件训练各种适配器,实现丰富的控制和编辑效果。此外,所提出的T2I-Adapters具有实用价值的吸引人的特性,例如可组合性和泛化能力。大量实验表明,我们的 T2I-Adapter 具有良好的生成质量和广泛的应用范围。
2.3D Human Pose Lifting with Grid Convolution

标题:网格卷积的 3D 人体姿态提升
作者:Yangyuxuan Kang, Yuyang Liu, Anbang Yao, Shandong Wang, Enhua Wu
文章链接:https://arxiv.org/abs/2302.08760v1
项目代码:https://github.com/osvai/gridconv

摘要:
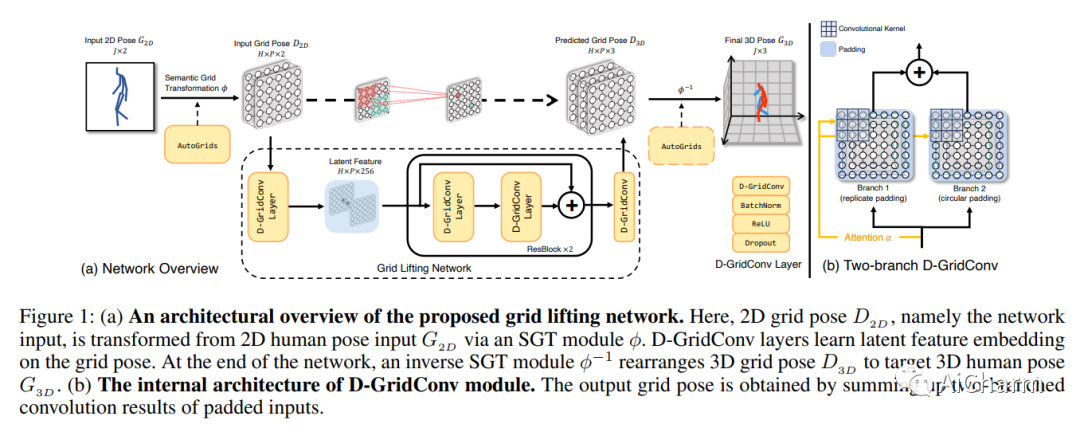
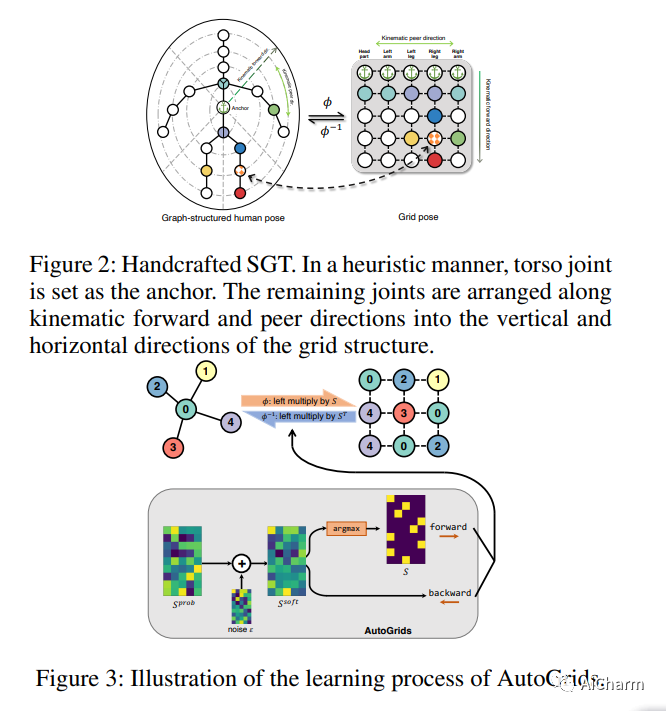
现有的用于从 2D 单视图姿势回归 3D 人体姿势的提升网络通常是用基于图结构表示学习的线性层构建的。与它们形成鲜明对比的是,本文提出了网格卷积 (GridConv),它模仿了图像空间中常规卷积运算的智慧。GridConv 基于一种新颖的语义网格变换 (SGT),它利用二进制分配矩阵将不规则图形结构的人体姿势逐个关节映射到规则的编织状网格姿势表示,从而通过 GridConv 操作实现逐层特征学习。我们提供两种实现 SGT 的方法,包括手工设计和可学习设计。令人惊讶的是,这两种设计都取得了有希望的结果,而且可学习的设计更好,证明了这种新的提升表示学习公式的巨大潜力。为了提高 GridConv 编码上下文线索的能力,我们在卷积核上引入了一个注意力模块,使网格卷积操作依赖于输入、空间感知和网格特定。我们表明,我们的全卷积网格提升网络优于最先进的方法,在 (1) Human3.6M 的常规评估和 (2) MPI-INF-3DHP 的交叉评估下具有明显的利润率。
Subjects: cs.LG
3.MiDi: Mixed Graph and 3D Denoising Diffusion for Molecule Generation

标题:MiDi:用于分子生成的混合图和 3D 去噪扩散
作者:Clement Vignac, Nagham Osman, Laura Toni, Pascal Frossard
文章链接:https://arxiv.org/abs/2302.09048v1
项目代码:https://github.com/cvignac/midi
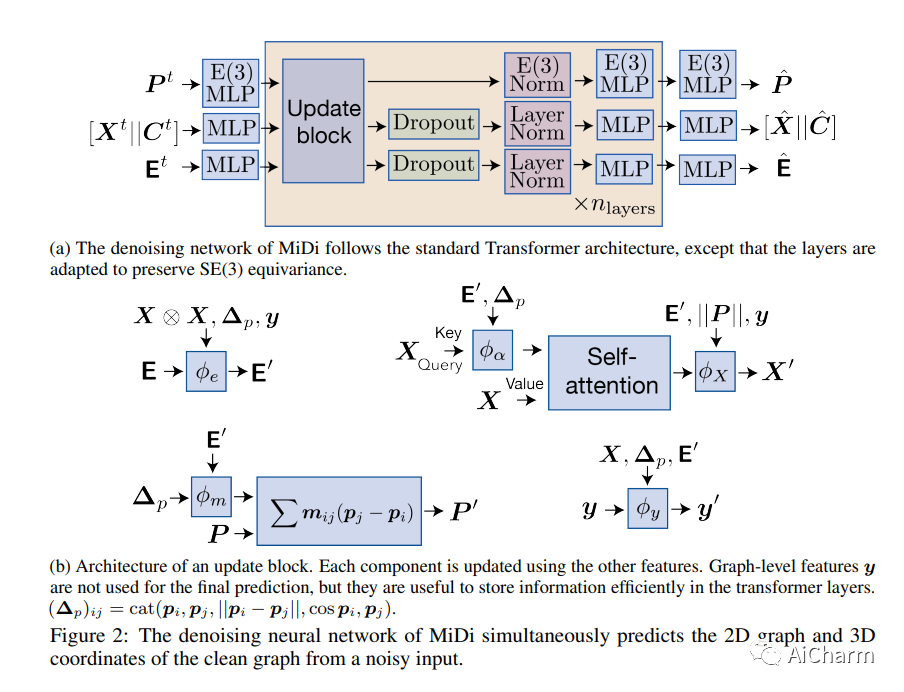
摘要:
这项工作介绍了 MiDi,这是一种用于联合生成分子图和相应的 3D 构象异构体的扩散模型。与使用预定义规则从构象中导出分子键的现有模型相比,MiDi 使用端到端可微分模型简化了分子生成过程。实验结果证明了这种方法的好处:在复杂的 GEOM-DRUGS 数据集上,我们的模型生成的分子图明显优于基于 3D 的模型,甚至超过了直接优化键顺序有效性的专门算法。我们的代码可在 github.com/cvignac/MiDi 获得。
更多Ai资讯:公主号AiCharm
