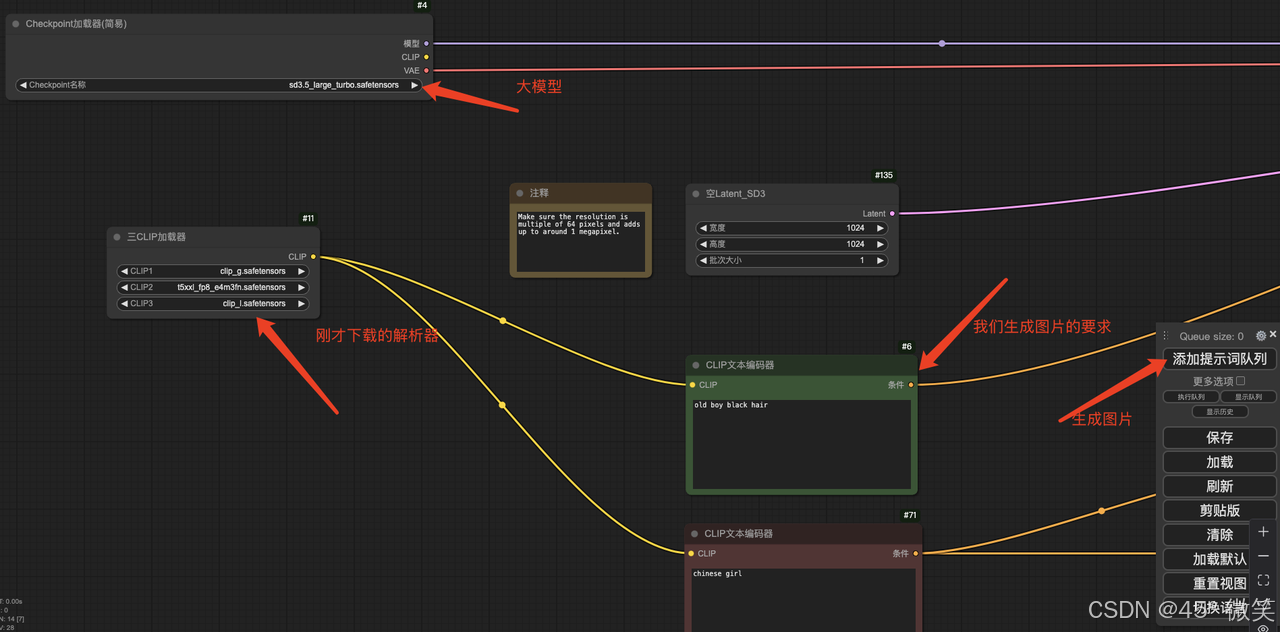
UI 使用推荐的ComfyUI,GitHub 地址,huggingface 需要注册登录,需要下载的文件下面有说明
- Dockerfile 文件如下:
FROM nvidia/cuda:12.4.0-base-ubuntu22.04
RUN apt-get update && apt-get install python3 pip git --no-install-recommends -y &&\
git clone https://github.com/comfyanonymous/ComfyUI.git &&\
pip install torch torchvision torchaudio --index-url https://pypi.tuna.tsinghua.edu.cn/simple --no-cache &&\
apt-get clean && apt-get autoclean && apt-get autoremove
WORKDIR /ComfyUI
EXPOSE 8188
RUN pip install --index-url https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt --no-cache
COPY AIGODLIKE-COMFYUI-TRANSLATION custom_nodes/AIGODLIKE-COMFYUI-TRANSLATION
COPY stable-diffusion/sd3.5_large_turbo.safetensors models/checkpoints/
COPY stable-diffusion/vae models/vae
COPY clip models/clip
CMD ["python3", "main.py", "--listen", "0.0.0.0"]
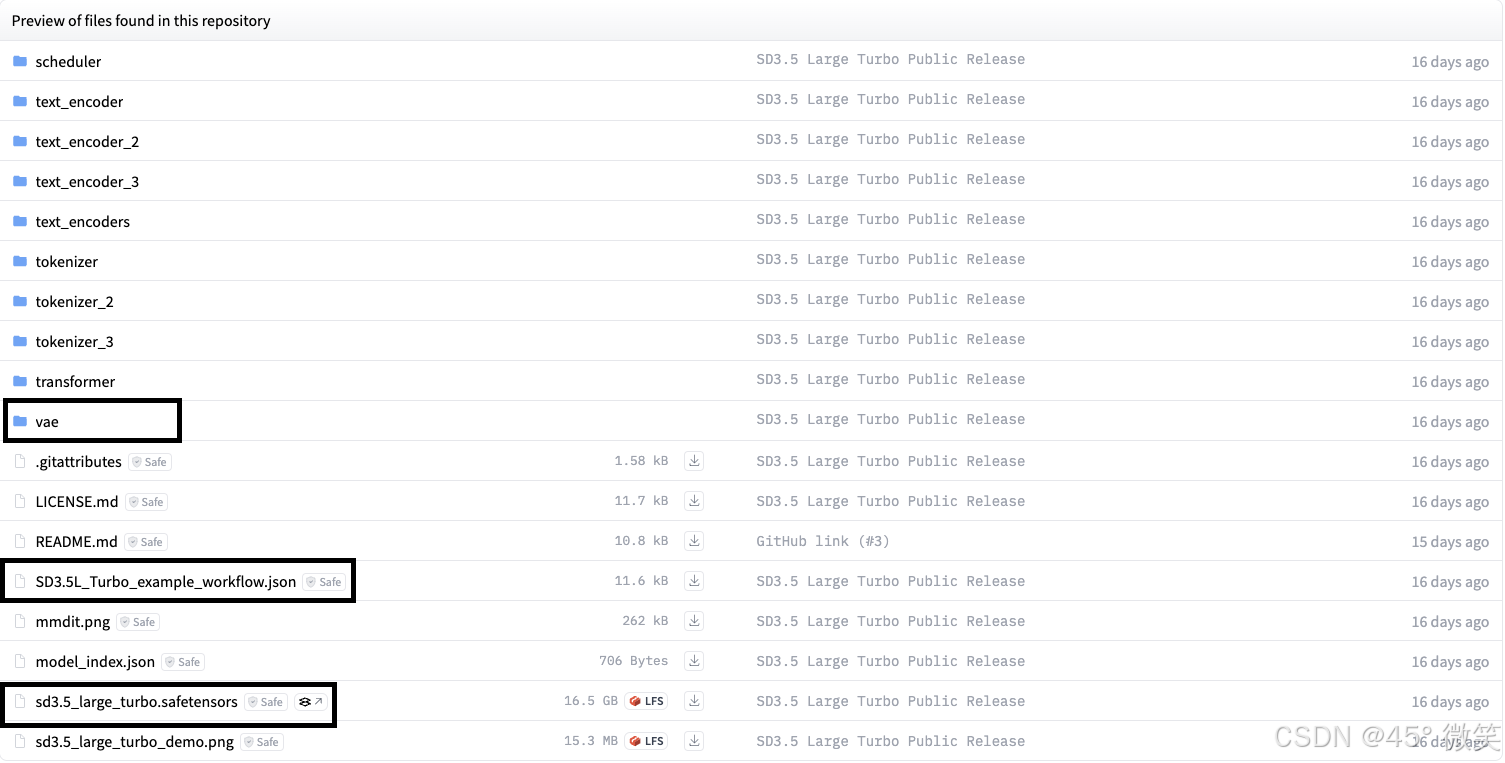
- 把需要的文件下载下来拷贝到一个目录,文件夹目录结构如下:
.
├── AIGODLIKE-COMFYUI-TRANSLATION # 中文包
│ ├── example
│ ├── __init__.py
│ ├── ja-JP
│ ├── ko-KR
│ ├── LocaleMap.js
│ ├── main.js
│ ├── MenuTranslate.js
│ ├── pyproject.toml
│ ├── readme.md
│ ├── ru-RU
│ ├── zh-CN
│ └── zh-TW
├── clip # 解析器
│ ├── clip_g.safetensors
│ ├── clip_l.safetensors
│ └── t5xxl_fp8_e4m3fn.safetensors
├── Dockerfile
└── stable-diffusion ## 大模型
├── sd3.5_large_turbo.safetensors
├── SD3.5L_Turbo_example_workflow.json
└── vae

- 构建镜像,并运行
docker build -t stable-diffusion:3.5-large-turbo-ubuntu22.04-cuda12.4-py310-torch2.5.1 .
docker run --runtime=nvidia --gpus all --rm -p 8188:8188 stable-diffusion:3.5-large-turbo-ubuntu22.04-cuda12.4-py310-torch2.5.1
- 访问ComfyUI,把刚才下载的 SD3.5L_Turbo_example_workflow.json 拖到 UI 上,按照步骤执行,在预览图像框里查看生成的图像