一、微信小程序获取要求:
获取前10页的内容,并保存
二、准备分析工作
1、先进入微信小程序页面,url= http://www.wxapp-union.com/;
2、进入首页,右击检查,或f12,如图;
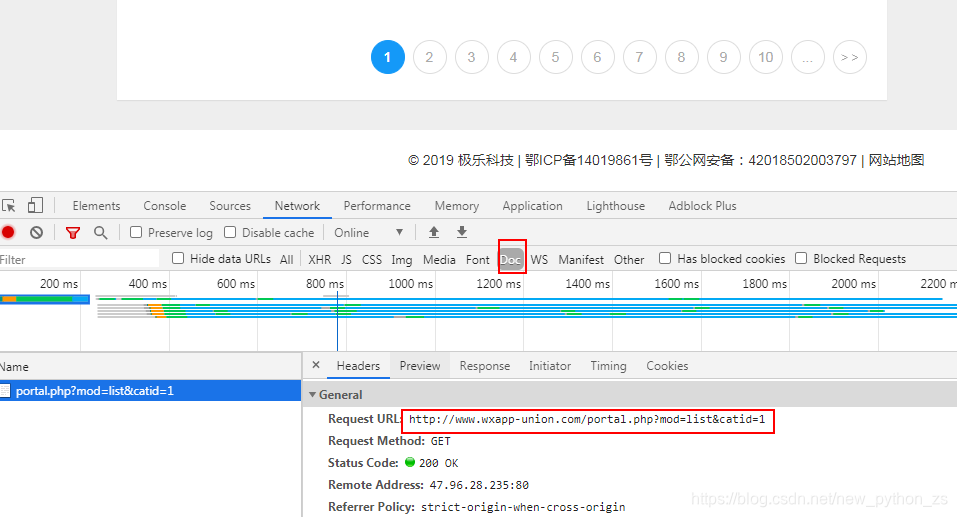
3、获取第一页的url,第二页的url…,分析找到url的规律;
三、代码
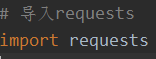
1、导入requests模块,如图
import requests
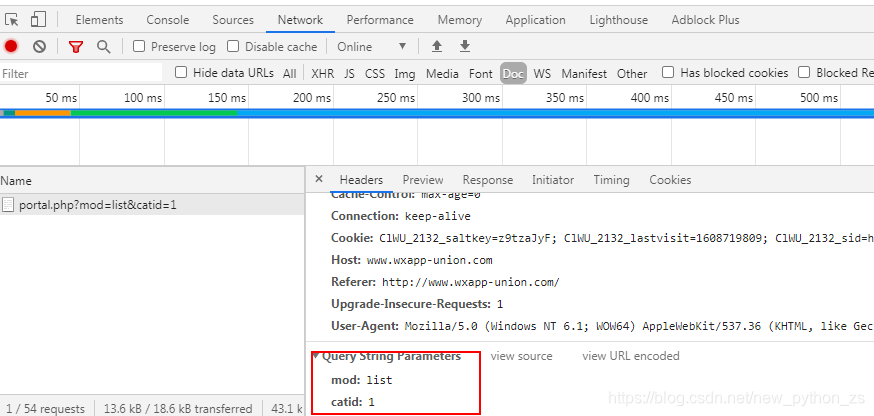
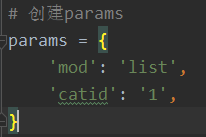
2、创建params字典,根据下图找到params里参数
params={
‘mod’: ‘list’,
‘catid’: ‘1’,
}
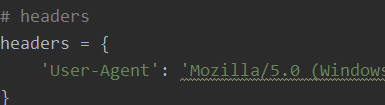
3、定义请求头headers,如图
headers={
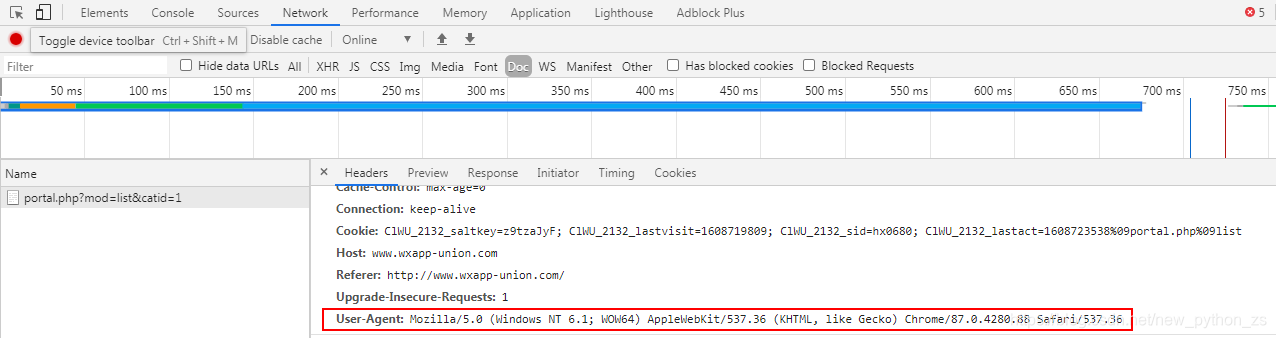
‘User-Agent’:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36’
}
4、因为要获取前10页的内容,设置page,把page添加到params字典里,如图
for page in range(1, 11):
params[‘page’] = page

5、发送请求,接收响应,如图
response = requests.get(url=‘http://www.wxapp-union.com/portal.php?’, params=params, headers=headers)

6、保存内容,如图
with open(f’小程序社区抓取{page}.html’, ‘w’, encoding=‘utf-8’) as f:
f.write(response.text)
