课程地址:【韩顺平讲Java】Java集合专题 -ArrayList HashMap HashSet List Map TreeMap TreeSet等
课程资料:链接:https://pan.baidu.com/s/1GKg1SZicHhDXCQRNiSOhEA
提取码:x10f
文章目录
- 集合框架体系
- Collections方法
- 迭代器遍历
- 集合增强for
- 集合测试题
- List接口方法
- List接口练习
- List的三种遍历方式
- List排序练习
- ArrayList注意事项
- ArrayList源码剖析
- vector底层结构和源码剖析
- 双向链表模拟
- LinkedList源码图解
- list集合选择
- Set接口和方法
- HashSet全面说明
- 数组链表模拟
- HashSet扩容机制
- HashSet源码分析
- HashSet的最佳实践
- HasHSet思考题
- LinkedHashSet介绍
- LinkedHashSet源码分析
- LinkedHashSet课堂练习
- Map接口的特点
- Map接口方法
- Map的六大遍历方式
- Map课堂练习
- HashMap阶段小结
- HashMap底层机制
- HashMap扩容与树化触发
- HashTable使用
- Properties
- 集合选型规则
- TreeSet源码解读
- TreeMap源码解读
- Collections工具类
- 集合家庭作业1
- 集合家庭作业2
- 集合家庭作业3
- 集合家庭作业4
- 集合家庭作业5
- 集合家庭作业6
- 集合家庭作业7
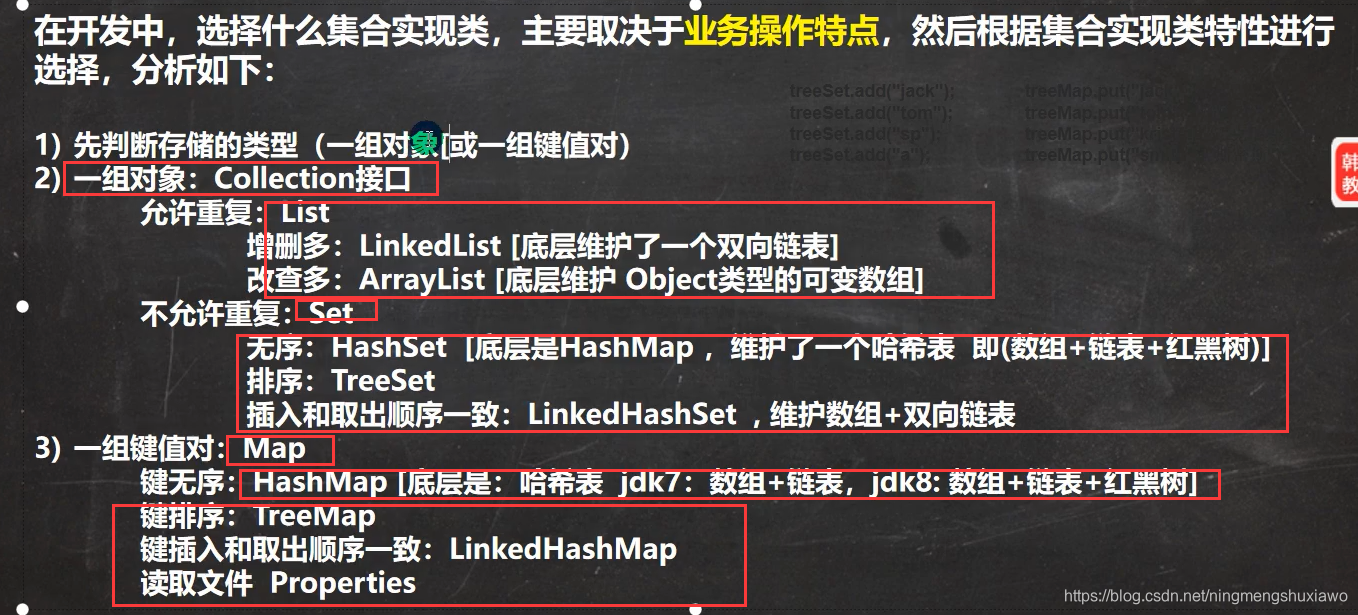
了解什么情况下用什么集合
前面我们保存多个数据使用的是数组,那么数组有不足的地方
1)长度开始时必须指定,而且一旦指定,不能更改
2)保存的必须为同一类型的元素
3)使用数组进行增加或者删除元素的示意代码-比较麻烦
数组管理对象比较麻烦,灵活性不够
集合:多种数据放到一起的数据结构/数据类型
集合的好处
1)可以动态保存任意多个对象,使用比较方便
2)提供了一系列方便的操作对象的方法:add、remove、set,get等
3)使用集合添加,删除新元素的示意代码-简洁了
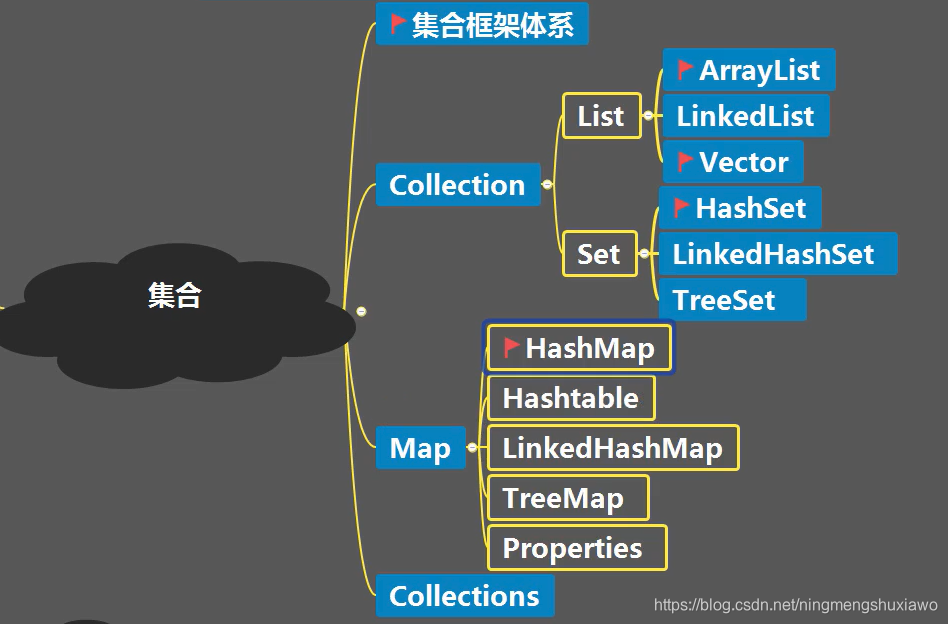
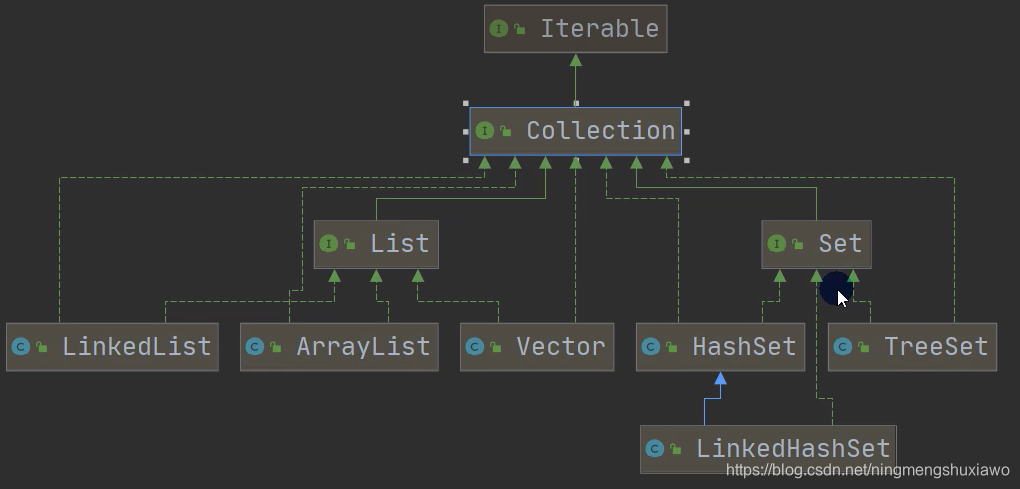
集合框架体系
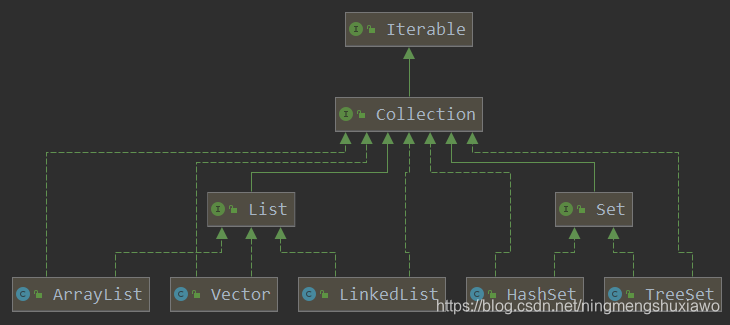
Collection接口继承了Iterable接口
List Set接口继承了Clllection接口
List常用的实现类有ArrayList,LinkedList,Set接口常用的实现类有HashSet,TreeSet
再来看看Map接口
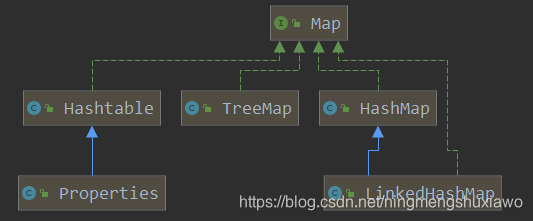
可以看到LinkedHashMap继承了HashMap同时实现了Map接口
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
集合主要有2组,
一组是单列集合(集合里面放的是的那个的对象),
另一组是双列集合,我那个网是键值对形式的
Collection接口有List和Set这两个主要的接口,他们的实现类都是单列集合
Map接口的实现子类是双列集合,存放key和value这样的数据
Collections方法
Collection接口继承了Iterable接口
1 collection实现子类可以存放多个元素,每个元素可以是Object
2 有些Coolection的实现类可以存放重复的元素,有些不可以
3 有些Collectiond的实现类,存放数据是有序的,有些是无序的
4 Collection接口没有直接的实现子类,是通过子接口Set和List来实现的
接口是不能直接被实例化的,只有实现了接口的这个类才能被实例化

package com.hspedu.collection_;
import java.util.ArrayList;
import java.util.List;
/**
* @author 韩顺平
* @version 1.0
*/
public class CollectionMethod {
@SuppressWarnings({"all"})
public static void main(String[] args) {
List list = new ArrayList();
// add:添加单个元素
list.add("jack");
list.add(10);//list.add(new Integer(10))
list.add(true);
System.out.println("list=" + list);
// remove:删除指定元素
//list.remove(0);//删除第一个元素
list.remove(true);//指定删除某个元素
System.out.println("list=" + list);
// contains:查找元素是否存在
System.out.println(list.contains("jack"));//T
// size:获取元素个数
System.out.println(list.size());//2
// isEmpty:判断是否为空
System.out.println(list.isEmpty());//F
// clear:清空
list.clear();
System.out.println("list=" + list);
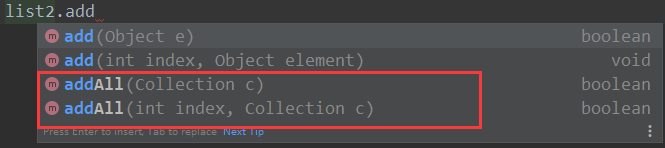
// addAll:添加多个元素
ArrayList list2 = new ArrayList();
list2.add("红楼梦");
list2.add("三国演义");
list.addAll(list2);
System.out.println("list=" + list);
// containsAll:查找多个元素是否都存在
System.out.println(list.containsAll(list2));//T
// removeAll:删除多个元素
list.add("聊斋");
list.removeAll(list2);
System.out.println("list=" + list);//[聊斋]
// 说明:以ArrayList实现类来演示.
}
}
代码解读
注意这里没有指定集合里面的数据类型,所以add的时候装了各种类型的数据
注意集合里面的数据本质上是对象, list.add(10)相当于list.add(new Integer(10)),这里并不是基本数据类型
remove函数是被重载了的,可以删除指定索引的元素,也可以删除指定对象,但是返回类型不一样

AddAll:在集合中插入实现了Collection接口的集合
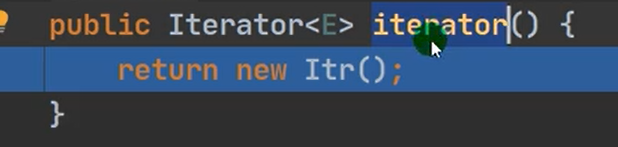
迭代器遍历
Collection接口遍历元素的方式
1迭代器Iterator
Iterator对象称为迭代器,主要用于遍历Collection集合中的元素
所有实现了Collection接口的集合类都有一个Iterator()方法,用以返回一个实现了Iterator接口的对象,即可以返回一个迭代器
Iterator仅用于遍历集合,Iterator本身并不存储对象
迭代器的执行原理:指针不断下移,直到遍历完集合中的元素
注意返回的是指针下移以后指向的那个元素(有点像链表)

老韩提示:在调用iterator.next()方法之前必须要调用iterator.hasNext()进行检测。若不调用,且下一条记录无效,直接调用it.next()会抛出NoSuchElementException异常。
package com.hspedu.collection_;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
* @author 韩顺平
* @version 1.0
*/
public class CollectionIterator {
@SuppressWarnings({"all"})
public static void main(String[] args) {
Collection col = new ArrayList();
col.add(new Book("三国演义", "罗贯中", 10.1));
col.add(new Book("小李飞刀", "古龙", 5.1));
col.add(new Book("红楼梦", "曹雪芹", 34.6));
//System.out.println("col=" + col);
//现在老师希望能够遍历 col集合
//1. 先得到 col 对应的 迭代器
Iterator iterator = col.iterator();
//2. 使用while循环遍历
// while (iterator.hasNext()) {//判断是否还有数据
// //返回下一个元素,类型是Object
// Object obj = iterator.next();
// System.out.println("obj=" + obj);
// }
//老师教大家一个快捷键,快速生成 while => itit
//显示所有的快捷键的的快捷键 ctrl + j
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
//3. 当退出while循环后 , 这时iterator迭代器,指向最后的元素
// iterator.next();//NoSuchElementException
//4. 如果希望再次遍历,需要重置我们的迭代器
iterator = col.iterator();
System.out.println("===第二次遍历===");
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
}
}
class Book {
private String name;
private String author;
private double price;
public Book(String name, String author, double price) {
this.name = name;
this.author = author;
this.price = price;
}
}
代码解读:
Object obj = iterator.next();
obj的编译类型是 Object ,但是运行类型取决于真正取出来的数据类型(编译看左边,运行看右边)
3. 当退出while循环后 , 这时iterator迭代器,指向最后的元素 则会报异常iterator.next();//NoSuchElementException
4. 如果希望再次遍历,需要重置我们的迭代器 iterator = col.iterator();
Iterator iterator = list2.iterator();
System.out.println(iterator .hashCode());
iterator = list2.iterator();
System.out.println(iterator .hashCode());
但是注意,迭代器对象已经遍历,不是同一个对象,因为哈希值都不一样了

集合增强for
基本语法
for(元素类型 元素名:集合或数组名){
访问元素
}
package com.hspedu.collection_;
import java.util.ArrayList;
import java.util.Collection;
/**
* @author 韩顺平
* @version 1.0
*/
public class CollectionFor {
@SuppressWarnings({"all"})
public static void main(String[] args) {
Collection col = new ArrayList();
col.add(new Book("三国演义", "罗贯中", 10.1));
col.add(new Book("小李飞刀", "古龙", 5.1));
col.add(new Book("红楼梦", "曹雪芹", 34.6));
//老韩解读
//1. 使用增强for, 在Collection集合
//2. 增强for, 底层仍然是迭代器
//3. 增强for可以理解成就是简化版本的 迭代器遍历
//4. 快捷键方式 I
// for (Object book : col) {
// System.out.println("book=" + book);
// }
for (Object o : col) {
System.out.println("book=" + o);
}
//增强for,也可以直接在数组使用
// int[] nums = {1, 8, 10, 90};
// for (int i : nums) {
// System.out.println("i=" + i);
// }
}
}
代码解读。增强for的底层仍然是迭代器,在for循环端点debug就可以看到了,会调用Iterator,增强for可以看成简易版的迭代器
集合测试题
package com.hspedu.collection_;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/**
* @author 韩顺平
* @version 1.0
*/
public class CollectionExercise {
@SuppressWarnings({"all"})
public static void main(String[] args) {
List list = new ArrayList();
list.add(new Dog("小黑", 3));
list.add(new Dog("大黄", 100));
list.add(new Dog("大壮", 8));
//先使用for增强
for (Object dog : list) {
System.out.println("dog=" + dog);
}
//使用迭代器
System.out.println("===使用迭代器来遍历===");
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object dog = iterator.next();
System.out.println("dog=" + dog);
}
}
}
/**
* 创建 3个 Dog {name, age} 对象,放入到 ArrayList 中,赋给 List 引用
* 用迭代器和增强for循环两种方式来遍历
* 重写Dog 的toString方法, 输出name和age
*/
class Dog {
private String name;
private int age;
public Dog(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
List接口方法
List接口是Collection接口的子接口
List的实现类中的元素是有序的,即添加顺序和取出元素的顺序是一样的,且可以重复
List集合中的每个额元素都有其对应的顺序索引,即支持索引
List容器的每个元素对应一个整数型的序号记载其在容器中的位置们可以根据序号存取容器中的元素(注意linkedList也是支持索引的哈)
List list3= new LinkedList();
list3.add(1);
list3.add(12);
list3.add(3);
System.out.println(list3.get(1));
List接口中常用的方法

package com.hspedu.list_;
import java.util.ArrayList;
import java.util.List;
/**
* @author 韩顺平
* @version 1.0
*/
public class ListMethod {
@SuppressWarnings({"all"})
public static void main(String[] args) {
List list = new ArrayList();
list.add("张三丰");
list.add("贾宝玉");
// void add(int index, Object ele):在index位置插入ele元素
//在index = 1的位置插入一个对象
list.add(1, "韩顺平");
System.out.println("list=" + list);
// boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来
List list2 = new ArrayList();
list2.add("jack");
list2.add("tom");
list.addAll(1, list2);
System.out.println("list=" + list);
// Object get(int index):获取指定index位置的元素
//说过
// int indexOf(Object obj):返回obj在集合中首次出现的位置
System.out.println(list.indexOf("tom"));//2
// int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置
list.add("韩顺平");
System.out.println("list=" + list);
System.out.println(list.lastIndexOf("韩顺平"));
// Object remove(int index):移除指定index位置的元素,并返回此元素
list.remove(0);
System.out.println("list=" + list);
// Object set(int index, Object ele):设置指定index位置的元素为ele , 相当于是替换.
list.set(1, "玛丽");
System.out.println("list=" + list);
// List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex位置的子集合
// 注意返回的子集合 fromIndex <= subList < toIndex
List returnlist = list.subList(0, 2);
System.out.println("returnlist=" + returnlist);
}
}
代码解读
list.subList(0, 2);注意返回的子集合 fromIndex <= subList < toIndex,就是不包含toIndex对应的元素,前闭后开,可以理解,size=toIndex- fromIndex
List接口练习
只要是实现来了Collection接口就可以使用迭代器
List接口是Collection鸡眼扣的子接口,所以也可以使用迭代器
package com.hspedu.list_;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/**
* @author 韩顺平
* @version 1.0
*/
public class ListExercise {
@SuppressWarnings({"all"})
public static void main(String[] args) {
/*
添加10个以上的元素(比如String "hello" ),在2号位插入一个元素"韩顺平教育",
获得第5个元素,删除第6个元素,修改第7个元素,在使用迭代器遍历集合,
要求:使用List的实现类ArrayList完成。
*/
List list = new ArrayList();
for (int i = 0; i < 12; i++) {
list.add("hello" + i);
}
System.out.println("list=" + list);
//在2号位插入一个元素"韩顺平教育"
list.add(1, "韩顺平教育");
System.out.println("list=" + list);
//获得第5个元素
System.out.println("第五个元素=" + list.get(4));
//删除第6个元素
list.remove(5);
System.out.println("list=" + list);
//修改第7个元素
list.set(6, "三国演义");
System.out.println("list=" + list);
//在使用迭代器遍历集合
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
}
}
List的三种遍历方式
迭代器 增强for 普通for
public class ListFor {
@SuppressWarnings({"all"})
public static void main(String[] args) {
//List 接口的实现子类 Vector LinkedList
//List list = new ArrayList();
//List list = new Vector();
List list = new LinkedList();
list.add("jack");
list.add("tom");
list.add("鱼香肉丝");
list.add("北京烤鸭子");
//遍历
//1. 迭代器
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println(obj);
}
System.out.println("=====增强for=====");
//2. 增强for
for (Object o : list) {
System.out.println("o=" + o);
}
System.out.println("=====普通for====");
//3. 使用普通for
for (int i = 0; i < list.size(); i++) {
System.out.println("对象=" + list.get(i));
}
}
}
List排序练习
package com.hspedu.list_;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Vector;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class ListExercise02 {
public static void main(String[] args) {
//List list = new ArrayList();
List list = new LinkedList();
//List list = new Vector();
list.add(new Book("红楼梦", "曹雪芹", 100));
list.add(new Book("西游记", "吴承恩", 10));
list.add(new Book("水浒传", "施耐庵", 19));
list.add(new Book("三国", "罗贯中", 80));
//list.add(new Book("西游记", "吴承恩", 10));
//如何对集合进行排序
//遍历
for (Object o : list) {
System.out.println(o);
}
//冒泡排序
sort(list);
System.out.println("==排序后==");
for (Object o : list) {
System.out.println(o);
}
}
//静态方法
//价格要求是从小到大
public static void sort(List list) {
int listSize = list.size();
for (int i = 0; i < listSize - 1; i++) {
for (int j = 0; j < listSize - 1 - i; j++) {
//取出对象Book
Book book1 = (Book) list.get(j);
Book book2 = (Book) list.get(j + 1);
if (book1.getPrice() > book2.getPrice()) {//交换
list.set(j, book2);
list.set(j + 1, book1);
}
}
}
}
}
排序也可以通过多BOOK类实现Comparable接口
ArrayList注意事项
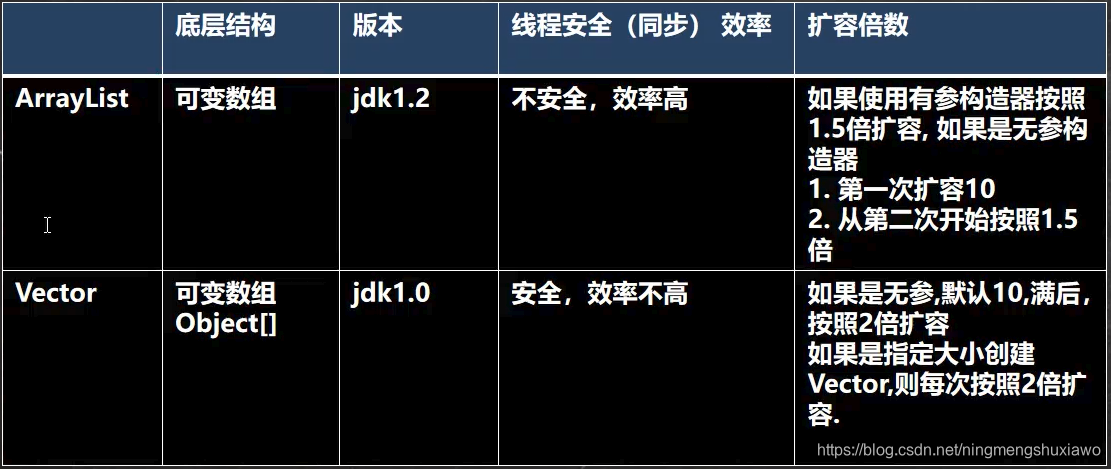
ArrayList可以存放空元素 arrayList.add(null);且可以存放多个空值,底层是用数组实现的,线程不安全,效率高
多线程情况下可以使用vector,vector是线程安全的
public class ArrayListDetail {
public static void main(String[] args) {
//ArrayList 是线程不安全的, 可以看源码 没有 synchronized
/*
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
*/
ArrayList arrayList = new ArrayList();
arrayList.add(null);
arrayList.add("jack");
arrayList.add(null);
arrayList.add("hsp");
System.out.println(arrayList);
}
}
ArrayList源码剖析
ArrayList的底层操作机制源码分析(重点,难点)
- ArrayList中维护了一个
Object类型的数组elementData. transient Object[] elementData;(Object类型的数组说明什么类型都可以放)
对象在序列化的时候,transient修饰的属性不会被序列化
2)当创建对象时,如果使用的是无参构造器,则初始elementData容量为0 (jdk7是10)
3)当添加元素时:先判断是否需要扩容,如果需要扩容,则调用grow方法,否则直接添加元素到合适位置
4)当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第1次添加,则扩容elementData为10,如需要再次扩容,则扩容elementData为1.5倍。
5)如果使用的是指定容量capacity的构造器,则初始elementData容量为capacity
6)如果使用的是指定容量capacity的构造器,如果需要扩容,则直接扩容elementData为1.5倍。
ArrayList的扩容方式

ArrayList是空间不够了才扩容的,假设现在插入第11个元素,但是只有10个空间,就触发grow扩容

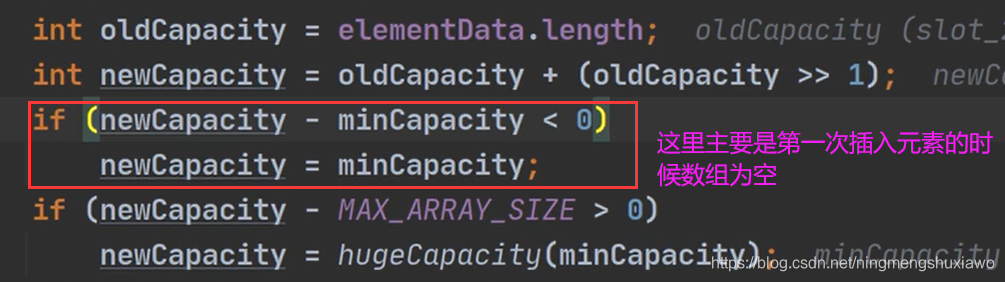
注意扩容之后调用了CopyOf函数

package com.hspedu.list_;
import java.util.ArrayList;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class ArrayListSource {
public static void main(String[] args) {
//老韩解读源码
//注意,注意,注意,Idea 默认情况下,Debug 显示的数据是简化后的,如果希望看到完整的数据
//需要做设置.
//使用无参构造器创建ArrayList对象
//ArrayList list = new ArrayList();
ArrayList list = new ArrayList(8);
//使用for给list集合添加 1-10数据
for (int i = 1; i <= 10; i++) {
list.add(i);
}
//使用for给list集合添加 11-15数据
for (int i = 11; i <= 15; i++) {
list.add(i);
}
list.add(100);
list.add(200);
list.add(null);
}
}
注意,注意,注意,Idea 默认情况下,Debug 显示的数据是简化后的(就是看不到全部数据),如果希望看到完整的数据需要做以下设置.
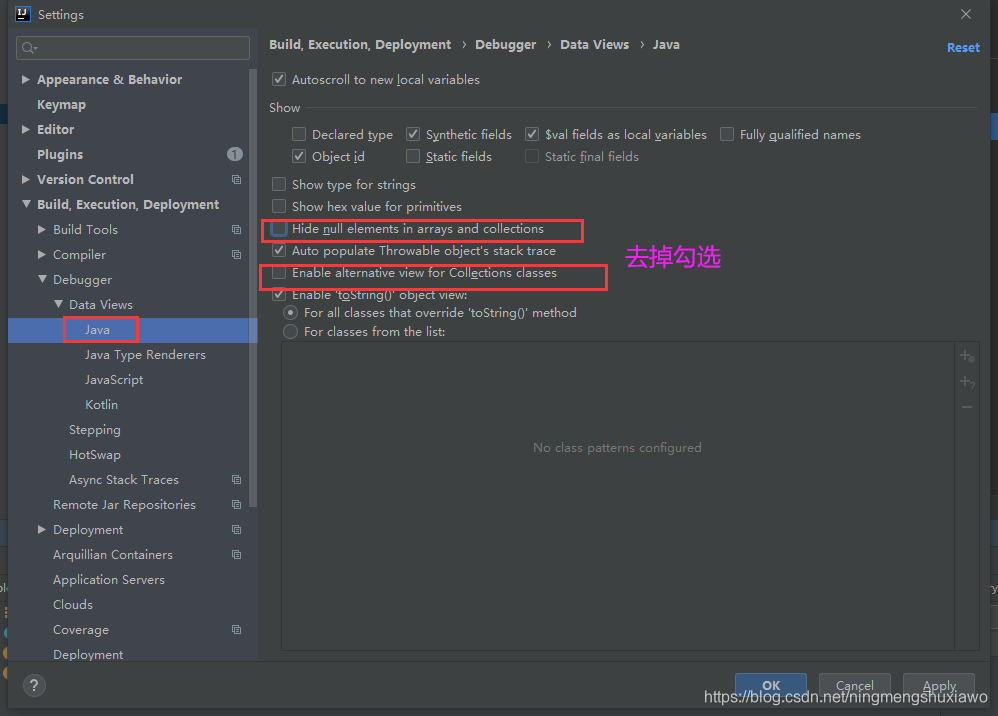
vector底层结构和源码剖析

可以看到,如果是无参构造,那么默认初始容量是10
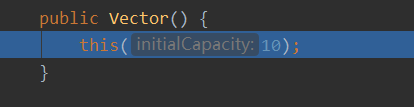
package com.hspedu.list_;
import java.util.Vector;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class Vector_ {
public static void main(String[] args) {
//无参构造器
//有参数的构造
Vector vector = new Vector(8);
for (int i = 0; i < 10; i++) {
vector.add(i);
}
vector.add(100);
System.out.println("vector=" + vector);
//老韩解读源码
//1. new Vector() 底层
/*
public Vector() {
this(10);
}
补充:如果是 Vector vector = new Vector(8);
走的方法:
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
2. vector.add(i)
2.1 //下面这个方法就添加数据到vector集合
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
2.2 //确定是否需要扩容 条件 : minCapacity - elementData.length>0
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
2.3 //如果 需要的数组大小 不够用,就扩容 , 扩容的算法
//newCapacity = oldCapacity + ((capacityIncrement > 0) ?
// capacityIncrement : oldCapacity);
//就是扩容两倍.
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
*/
}
}
双向链表模拟
LinkedList的全面说明
1)LinkedList底层实现了双向链表和双端队列特点
2)可以添加任意元素(元素可以重复),包括null
3)线程不安全,没有实现同步
LinkedList的底层操作机制
- LinkedList底层维护了一个双向链表.
- LinkedList中维护了两个属性first和last分别指向首节点和尾节点
3)每个节点(Node对象),里面又维护了prev、next、item三个属性,其中通过prev指向前一个,通过next指向后一个节点。最终实现双向链表.
4)所以LinkedList的元素的添加和删除,不是通过数组完成的,相对来说效率较高。
5)模拟一个简单的双向链表
LinkedList源码图解
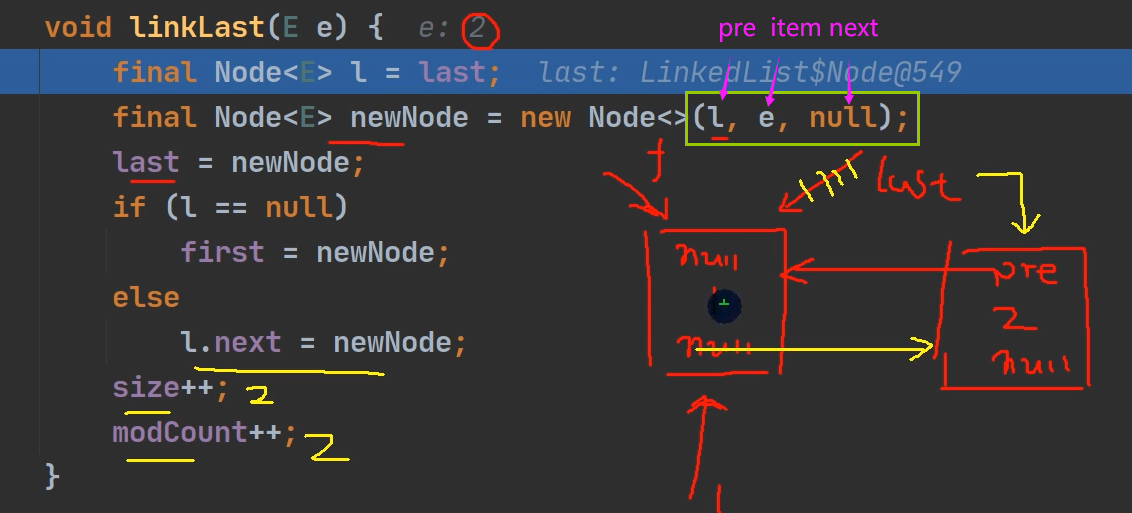
因为linkedList实现了list接口,所以它的遍历方式可以是迭代器,增强for循环以及传统的for循环遍历
package com.hspedu.list_;
import java.util.Iterator;
import java.util.LinkedList;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class LinkedListCRUD {
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
linkedList.add(1);
linkedList.add(2);
linkedList.add(3);
System.out.println("linkedList=" + linkedList);
//演示一个删除结点的
linkedList.remove(); // 这里默认删除的是第一个结点
//linkedList.remove(2);
System.out.println("linkedList=" + linkedList);
//修改某个结点对象
linkedList.set(1, 999);
System.out.println("linkedList=" + linkedList);
//得到某个结点对象
//get(1) 是得到双向链表的第二个对象
Object o = linkedList.get(1);
System.out.println(o);//999
//因为LinkedList 是 实现了List接口, 遍历方式
System.out.println("===LinkeList遍历迭代器====");
Iterator iterator = linkedList.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println("next=" + next);
}
System.out.println("===LinkeList遍历增强for====");
for (Object o1 : linkedList) {
System.out.println("o1=" + o1);
}
System.out.println("===LinkeList遍历普通for====");
for (int i = 0; i < linkedList.size(); i++) {
System.out.println(linkedList.get(i));
}
//老韩源码阅读.
/* 1. LinkedList linkedList = new LinkedList();
public LinkedList() {}
2. 这时 linkeList 的属性 first = null last = null
3. 执行 添加
public boolean add(E e) {
linkLast(e);
return true;
}
4.将新的结点,加入到双向链表的最后
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
*/
/*
老韩读源码 linkedList.remove(); // 这里默认删除的是第一个结点
1. 执行 removeFirst
public E remove() {
return removeFirst();
}
2. 执行
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
3. 执行 unlinkFirst, 将 f 指向的双向链表的第一个结点拿掉
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
*/
}
}
list集合选择
ArrayList插入数据涉及扩容操作,效率低,改和查的效率比较高,因为可以通过索引定位


Set接口和方法
set接口无序(添加和取出元素的顺序不一样),且没有索引,不支持随机访问
不允许有重复元素,所以最多有一个null
和List接口一样,Set接口也是Collection接口的子接口,因此,常用方法和Collection接口一样
同Collection接口遍历方式一样,因为Set接口是Collection接口的子接口,所以Set接口的遍历可以使用迭代器和增强for循环
不能使用索引来获取
HashSet全面说明
HashSet实现了Set接口
HashSet底层实际上是HashMap
public HashSet() {
map = new HashMap<>();
}
add也用的map的方法????
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
key值默认是PRESENT
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
3)可以存放null值,但是只能有一个null
4) HashSet不保证元素是有序的,取决于hash后,再确定索引的结果.(即,不保证存放元素的顺序和取出顺序一致)
5)不能有重复元素/对象.在前面Set 接口使用已经讲过
在存储对象进HashSet时,对象重写equals方法一定要重写hashCode方法,不然就会出现两个对象里面的数据一模一样,但是都可以存进HashSet集合中,因为如果没有重写HashCode方法,对象会使用父类Object类的hashCode方法,而Object的HashCode方法是根据地址来计算的,一定不会一样
==使用的比较地址就是用的hashcode()喽
为什么重写equals方法的同时也要重写hashcode方法
数组链表模拟
HashSet的底层是HashMap,HashMap的底层是数组加链表/红黑树
数组的元素存放节点
package com.hspedu.set_;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class HashSetStructure {
public static void main(String[] args) {
//模拟一个HashSet的底层 (HashMap 的底层结构)
//1. 创建一个数组,数组的类型是 Node[]
//2. 有些人,直接把 Node[] 数组称为 表
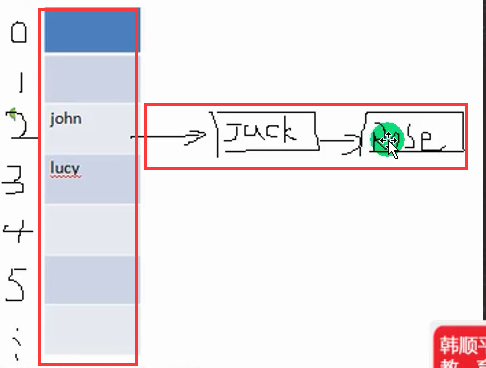
Node[] table = new Node[16];
//3. 创建结点
Node john = new Node("john", null);
table[2] = john;
Node jack = new Node("jack", null);
john.next = jack;// 将jack 结点挂载到john
Node rose = new Node("Rose", null);
jack.next = rose;// 将rose 结点挂载到jack
Node lucy = new Node("lucy", null);
table[3] = lucy; // 把lucy 放到 table表的索引为3的位置.
System.out.println("table=" + table);
}
}
class Node { //结点, 存储数据, 可以指向下一个结点,从而形成链表
Object item; //存放数据
Node next; // 指向下一个结点
public Node(Object item, Node next) {
this.item = item;
this.next = next;
}
}
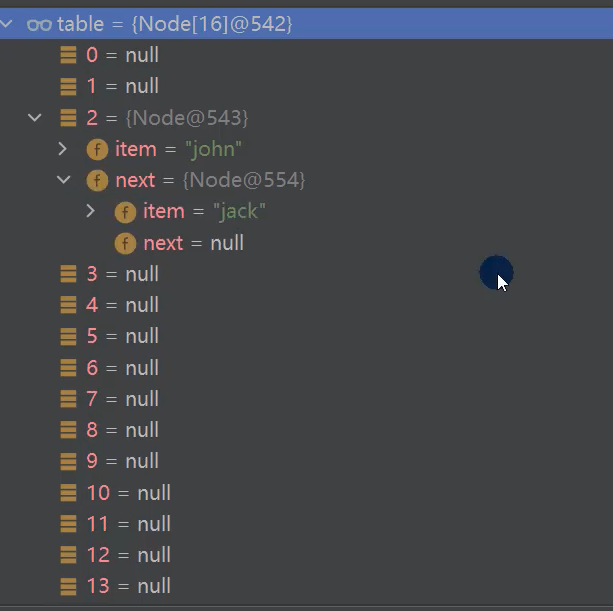
在hashmap底层,如果一条链表的节点的个数达到一定数量,就会变成红黑树,因为红黑树的存取效率更高
为什么不直接把数据放在一个数组里面?
答:数组的效率太低了
HashSet扩容机制
元素是怎么添加的?
为什么相同的对象无法添加?
上图中的equals是我们自己可以重写的

如果单条链表节点超过了8但是总的节点数没达到64怎么办了?
答:扩容,按2倍扩
HashSet源码分析
package com.hspedu.set_;
import java.util.HashSet;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class HashSetSource {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("java");//到此位置,第1次add分析完毕.
hashSet.add("php");//到此位置,第2次add分析完毕
hashSet.add("java");
System.out.println("set=" + hashSet);
/*
老韩对HashSet 的源码解读
1. 执行 HashSet()
public HashSet() {
map = new HashMap<>();
}
2. 执行 add()
public boolean add(E e) {//e = "java"
return map.put(e, PRESENT)==null;//(static) PRESENT = new Object();
}
3.执行 put() , 该方法会执行 hash(key) 得到key对应的hash值 算法h = key.hashCode()) ^ (h >>> 16)
public V put(K key, V value) {//key = "java" value = PRESENT 共享
return putVal(hash(key), key, value, false, true);
}
4.执行 putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i; //定义了辅助变量
//table 就是 HashMap 的一个数组,类型是 Node[]
//if 语句表示如果当前table 是null, 或者 大小=0
//就是第一次扩容,到16个空间.
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//(1)根据key,得到hash 去计算该key应该存放到table表的哪个索引位置
//并把这个位置的对象,赋给 p
//(2)判断p 是否为null
//(2.1) 如果p 为null, 表示还没有存放元素, 就创建一个Node (key="java",value=PRESENT)
//(2.2) 就放在该位置 tab[i] = newNode(hash, key, value, null)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//一个开发技巧提示: 在需要局部变量(辅助变量)时候,在创建
Node<K,V> e; K k; //
//如果当前索引位置对应的链表的第一个元素和准备添加的key的hash值一样
//并且满足 下面两个条件之一:
//(1) 准备加入的key 和 p 指向的Node 结点的 key 是同一个对象
//(2) p 指向的Node 结点的 key 的equals() 和准备加入的key比较后相同
//就不能加入
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//再判断 p 是不是一颗红黑树,
//如果是一颗红黑树,就调用 putTreeVal , 来进行添加
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {//如果table对应索引位置,已经是一个链表, 就使用for循环比较
//(1) 依次和该链表的每一个元素比较后,都不相同, 则加入到该链表的最后
// 注意在把元素添加到链表后,立即判断 该链表是否已经达到8个结点
// , 就调用 treeifyBin() 对当前这个链表进行树化(转成红黑树)
// 注意,在转成红黑树时,要进行判断, 判断条件
// if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY(64))
// resize();
// 如果上面条件成立,先table扩容.
// 只有上面条件不成立时,才进行转成红黑树
//(2) 依次和该链表的每一个元素比较过程中,如果有相同情况,就直接break
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD(8) - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//size 就是我们每加入一个结点Node(k,v,h,next), size++
if (++size > threshold)
resize();//扩容
afterNodeInsertion(evict);
return null;
}
*/
}
}
可以看到,不仅打印顺序和插入顺序不一样,也不能添加重复元素
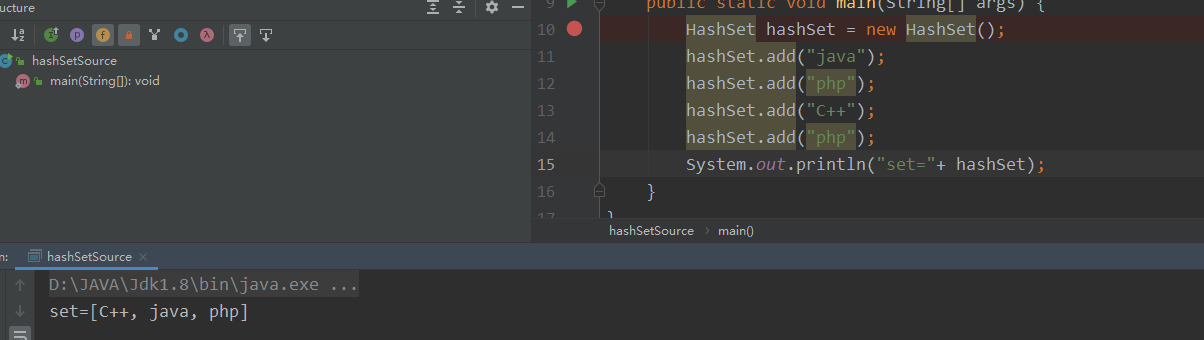

看到没有进来了,也就是说hashset底层的hash函数是利用了我们的key的hashcode()函数的,这里可以思考一下为什么重写了equals还要重写hashcode();
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这里无符号右移16位,主要是为了防止冲突,让不同的key得到不同的hash值,避免碰撞
看到了吗,key=null的时候返回0,这也就可以解释为什么你往set里面添加null元素的时候,你再遍历,输出的第一个值就是null,即null放在第一个位置
现在我们来拆解putVal方法
table是一个Node<K,V>类型的数组
transient Node<K,V>[] table;
他如果table为空数组,就先扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
接下来进入resize函数
先把table赋值给一个oldTab,然后计算这个oldTab的大小关系
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
当我们第一次扩容,oldCap=0,执行下面的代码
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
newCap表示新开辟的数组空间
newThr是临界值,表示下一次数组里面的容量达到了这么多之后就要进行扩容了,初始容量16的时候,用来12个空间我们就要扩容了
加载因子 DEFAULT_LOAD_FACTOR是为了在空间利用率和哈希冲突之间平衡的一个参数
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
至于16为什么写成1<<4,有注释,提醒我们数组大小必须是2的n次方
/**
* The default initial capacity - MUST be a power of two.
*/
然后根据newCap初始化一个newTab并赋值给table
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
接下来扩容之后,根据key计算出来的hash值来计算新的节点在tab中的索引,并把这个位置的对象赋值给辅助变量p
如果p为null,说明这个位置还没有存放过元素,就根据key,value创建一个node放在这个位置,为甚要把hash也存进去?因为将来要进行比较
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
++modCount代表修改了一次
++modCount;
下面这个方法在hashMap里面是空的,没有作用,只是为了让HashMap的子类比如LinkedHashMap去实现
void afterNodeInsertion(boolean evict) { }
最后的return null其实是代表添加成功
如下是hashSet的add方法,当putVal方法返回空,add会返回true
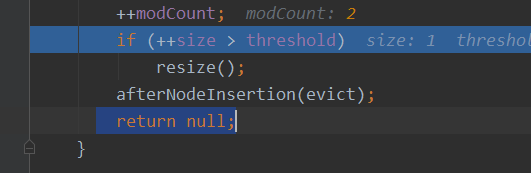
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
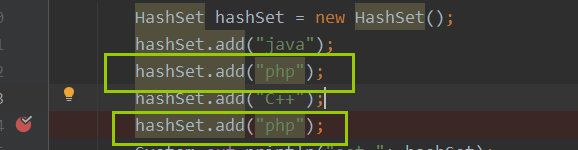
对于添加两个相同元素的情况,如此下代码,直接执行 e.value = value;即保留key,覆盖value,并把就得value值返回。
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
下面这段代码是当判断到新插入的元素产生哈希冲突后,遍历该数组位置上的链表,如果在链表上有重复元素,就停止加入,如果走到链表的尾部都还没有重复元素,就把新插入的元素挂载到链表的尾部,
而且可以看出,jdk1.8对于链表用的是尾插法
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
如果添加元素之后,链表的节点数大于等于了(8个)TREEIFY_THRESHOLD - 1,就把当前这个链表转化成红黑树转成红黑树时会判断,如果节点数小于64,不会进行树化,而是扩容)
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();

测试链表转红黑树,自定义类,重写hashcode函数,返回一个固定值就可以了
package com.hspedu.set_;
import java.util.HashSet;
import java.util.Objects;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class HashSetIncrement {
public static void main(String[] args) {
/*
HashSet底层是HashMap, 第一次添加时,table 数组扩容到 16,
临界值(threshold)是 16*加载因子(loadFactor)是0.75 = 12
如果table 数组使用到了临界值 12,就会扩容到 16 * 2 = 32,
新的临界值就是 32*0.75 = 24, 依次类推
*/
HashSet hashSet = new HashSet();
// for(int i = 1; i <= 100; i++) {
// hashSet.add(i);//1,2,3,4,5...100
// }
/*
在Java8中, 如果一条链表的元素个数到达 TREEIFY_THRESHOLD(默认是 8 ),
并且table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树),
否则仍然采用数组扩容机制
*/
// for(int i = 1; i <= 12; i++) {
// hashSet.add(new A(i));//
// }
/*
当我们向hashset增加一个元素,-> Node -> 加入table , 就算是增加了一个size++
*/
for(int i = 1; i <= 7; i++) {//在table的某一条链表上添加了 7个A对象
hashSet.add(new A(i));//
}
for(int i = 1; i <= 7; i++) {//在table的另外一条链表上添加了 7个B对象
hashSet.add(new B(i));//
}
}
}
class B {
private int n;
public B(int n) {
this.n = n;
}
@Override
public int hashCode() {
return 200;
}
}
class A {
private int n;
public A(int n) {
this.n = n;
}
@Override
public int hashCode() {
return 100;
}
}
对于下面这段代码,首先Hashmap会扩容到16,一直插入元素的时候,会形成一条链表,因为它们的hash值相同。当链表长度等于8的时候,因为数组长度没有达到64,所以不会转化为红黑树,会执行扩容,现在数组的长度是32,接着插入元素的时候,链表的长度又达到了8个还是会继续扩容,阔刀64之后,转化成红黑树
for(int i = 1; i <= 12; i++) {
hashSet.add(new A(i));//
}
扩容之后,原来的元素会移动位置的,扩容之后,再插入的元素的计算hash的n就又改变了,所以不会挂载在同一根链表上面了
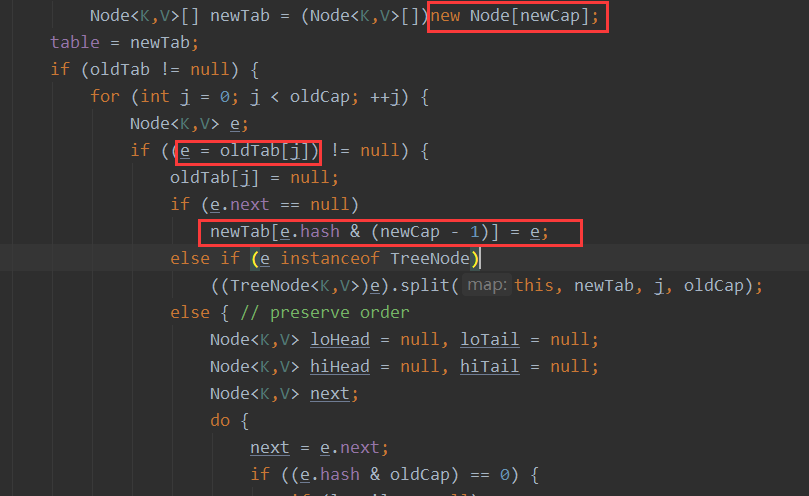
问题:假设元素达到12个就会扩容嘛,那么这个12是指的是table表的空间还是说要加上链表上面的节点呢?
我们来看源码
++modCount;
if (++size > threshold)
resize();
加入一个元素的时候,不管是加载table表的某一个位置还是说table表的某一条链表上,都会执行size++
验证
就是下面这段代码,先加的7个A在一条链表上面,那么,我们在加入B的时候,加到5个的时候,链表就会扩容了,A B的hashcode不一样是为了把它们放到不同的链表上面。
for(int i = 1; i <= 7; i++) {//在table的某一条链表上添加了 7个A对象
hashSet.add(new A(i));//
}
for(int i = 1; i <= 7; i++) {//在table的另外一条链表上添加了 7个B对象
hashSet.add(new B(i));//
}
HashSet的最佳实践
HashSet课堂练习1
定义一个Employee类,该类包含:private成员属性name.age
1.创建3个Employee对象放入HashSet中
2.当name和age的值相同时,认为是相同员工,不能添加到HashSet集合中
这是不重写equals和hashcode的情况

重写equals和hashcode的情况
package hspCollection.set_;
import java.util.HashSet;
import java.util.Objects;
import java.util.Set;
/**
* Created by 此生辽阔 on 2021/7/22 10:56
*/
public class test1 {
public static void main(String[] args) {
Set<Employee>set=new HashSet<>();
set.add(new Employee("张三",25));
set.add(new Employee("张三",25));
set.add(new Employee("张三",25));
System.out.println(set);
}
}
class Employee{
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return age == employee.age &&
Objects.equals(name, employee.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
重写toString();
@Override
public String toString() {
return "Employee{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}

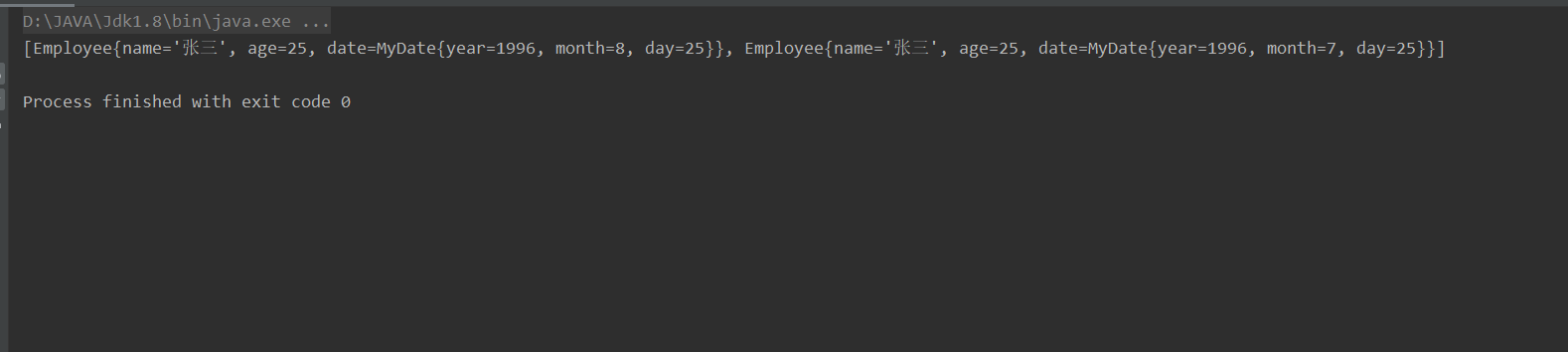
HasHSet思考题
定义一个Employee类,该类包含:private成员属性name,sal,birthday(MyDate类型),其中 birthday 为 MyDate类型(属性包括:year, month, day),要求:
1.创建3个Employee 放入HashSet中
2.当name和birthday的值相同时,认为是相同员工,不能添加到HashSet集合中
package hspCollection.set_;
import java.util.HashSet;
import java.util.Objects;
import java.util.Set;
/**
* Created by 此生辽阔 on 2021/7/22 10:56
*/
public class test1 {
public static void main(String[] args) {
Set<Employee>set=new HashSet<>();
set.add(new Employee("张三",25,new MyDate(1996,7,25)));
set.add(new Employee("张三",25,new MyDate(1996,8,25)));
set.add(new Employee("张三",25,new MyDate(1996,7,25)));
System.out.println(set);
}
}
class Employee{
private String name;
private int age;
private MyDate date;
public Employee(String name, int age, MyDate date) {
this.name = name;
this.age = age;
this.date = date;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return date.equals(employee.date) &&
Objects.equals(name, employee.name);
}
@Override
public int hashCode() {
return Objects.hash(name,date);
}
@Override
public String toString() {
return "Employee{" +
"name='" + name + '\'' +
", age=" + age +
", date=" + date +
'}';
}
}
class MyDate{
private int year;
private int month;
private int day;
public MyDate(int year, int month, int day) {
this.year = year;
this.month = month;
this.day = day;
}
@Override
public boolean equals(Object o)
{
if(this==o) return true;//地址相同,是两个相同的对象
if(o == null ||o.getClass()!=this.getClass()) return false;//不是同一类,返回false
MyDate date=(MyDate) o;
return (year==date.year&&month==date.month&&day==date.day) ;
}
@Override
public int hashCode()
{
return Objects.hash(year, month,day);
}
@Override
public String toString() {
return "MyDate{" +
"year=" + year +
", month=" + month +
", day=" + day +
'}';
}
}
LinkedHashSet介绍
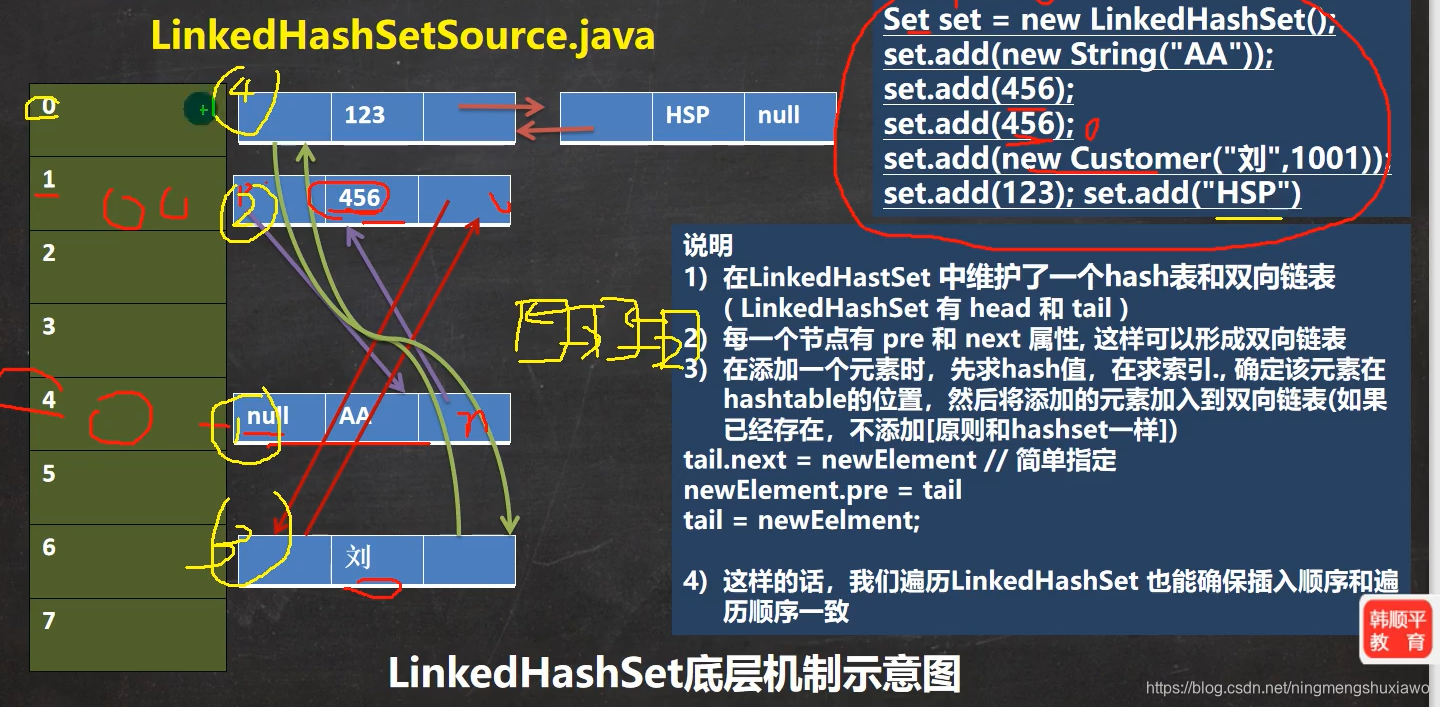
LinkedHashSet源码分析
LinkedHashSet底层是LinkedHashMap,数组+双向链表
LinkedHashMaps是HashMap的子类
hashMap的table存放的是Node,而LinkedHashMap的table存放的是Entry
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
package com.hspedu.set_;
import java.util.LinkedHashSet;
import java.util.Set;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class LinkedHashSetSource {
public static void main(String[] args) {
//分析一下LinkedHashSet的底层机制
Set set = new LinkedHashSet();
set.add(new String("AA"));
set.add(456);
set.add(456);
set.add(new Customer("刘", 1001));
set.add(123);
set.add("HSP");
System.out.println("set=" + set);
//老韩解读
//1. LinkedHashSet 加入顺序和取出元素/数据的顺序一致
//2. LinkedHashSet 底层维护的是一个LinkedHashMap(是HashMap的子类)
//3. LinkedHashSet 底层结构 (数组table+双向链表)
//4. 添加第一次时,直接将 数组table 扩容到 16 ,存放的结点类型是 LinkedHashMap$Entry
//5. 数组是 HashMap$Node[] 存放的元素/数据是 LinkedHashMap$Entry类型
/*
//继承关系是在内部类完成.
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
*/
}
}
class Customer {
private String name;
private int no;
public Customer(String name, int no) {
this.name = name;
this.no = no;
}
}
LinkedHashSet课堂练习
Car 类(属性:name,price),如果name和price一样,则认为是相同元素,就不能添加。
package hspCollection.set_;
import java.util.LinkedHashSet;
import java.util.Objects;
/**
* Created by 此生辽阔 on 2021/7/24 9:23
*/
public class linkedHashSetTest {
public static void main(String[] args) {
LinkedHashSet linkedHashSet = new LinkedHashSet();
linkedHashSet.add(new Car("dazong",16020));
linkedHashSet.add(new Car("dazong",16020));
System.out.println(linkedHashSet);
}
}
class Car
{
private String name;
private double price;
public Car(String name, double price) {
this.name = name;
this.price = price;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Car car = (Car) o;
return Double.compare(car.price, price) == 0 &&
Objects.equals(name, car.name);
}
@Override
public int hashCode() {
return Objects.hash(name, price);
}
}
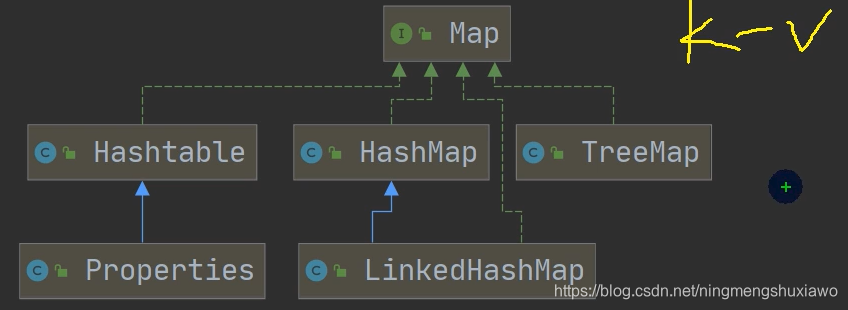
Map接口的特点

package com.hspedu.map_;
import java.util.HashMap;
import java.util.Map;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class Map_ {
public static void main(String[] args) {
//老韩解读Map 接口实现类的特点, 使用实现类HashMap
//1. Map与Collection并列存在。用于保存具有映射关系的数据:Key-Value(双列元素)
//2. Map 中的 key 和 value 可以是任何引用类型的数据,会封装到HashMap$Node 对象中
//3. Map 中的 key 不允许重复,原因和HashSet 一样,前面分析过源码.
//4. Map 中的 value 可以重复
//5. Map 的key 可以为 null, value 也可以为null ,注意 key 为null,
// 只能有一个,value 为null ,可以多个
//6. 常用String类作为Map的 key
//7. key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到对应的 value
Map map = new HashMap();
map.put("no1", "韩顺平");//k-v
map.put("no2", "张无忌");//k-v
map.put("no1", "张三丰");//当有相同的k , 就等价于替换.
map.put("no3", "张三丰");//k-v
map.put(null, null); //k-v
map.put(null, "abc"); //等价替换
map.put("no4", null); //k-v
map.put("no5", null); //k-v
map.put(1, "赵敏");//k-v
map.put(new Object(), "金毛狮王");//k-v
// 通过get 方法,传入 key ,会返回对应的value
System.out.println(map.get("no2"));//张无忌
System.out.println("map=" + map);
}
}
虽然null是第二个打印出来的,但是从debug可以看出,key为null时是存在索引为0的位置的

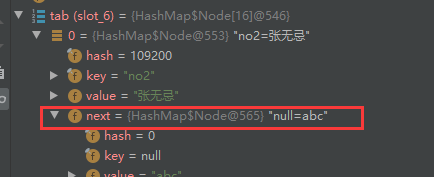
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
我们来看看根据key获取value的过程
首先会获取key的hash值,根据这个hash值获取key所在的索引,然后根据这个索引值找到该索引下的第一个节点,判断该节点是否是我们要找的节点,如果是,就返回该节点,如果不是,再判断该节点处是否形成了红黑树,如果是,就根据红黑树的查找方法,如果不是,就再判断是否形成链表,是就遍历链表的节点,依次匹配,如果最终没有找到匹配的节点,就返回null
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
Map接口方法

Map的六大遍历方式
package com.hspedu.map_;
import java.util.*;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class MapFor {
public static void main(String[] args) {
Map map = new HashMap();
map.put("邓超", "孙俪");
map.put("王宝强", "马蓉");
map.put("宋喆", "马蓉");
map.put("刘令博", null);
map.put(null, "刘亦菲");
map.put("鹿晗", "关晓彤");
//第一组: 先取出 所有的Key , 通过Key 取出对应的Value
Set keyset = map.keySet();
//(1) 增强for
System.out.println("-----第一种方式-------");
for (Object key : keyset) {
System.out.println(key + "-" + map.get(key));
}
//(2) 迭代器
System.out.println("----第二种方式--------");
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
//第二组: 把所有的values取出
Collection values = map.values();
//这里可以使用所有的Collections使用的遍历方法
//(1) 增强for
System.out.println("---取出所有的value 增强for----");
for (Object value : values) {
System.out.println(value);
}
//(2) 迭代器
System.out.println("---取出所有的value 迭代器----");
Iterator iterator2 = values.iterator();
while (iterator2.hasNext()) {
Object value = iterator2.next();
System.out.println(value);
}
//第三组: 通过EntrySet 来获取 k-v
Set entrySet = map.entrySet();// EntrySet<Map.Entry<K,V>>
//(1) 增强for
System.out.println("----使用EntrySet 的 for增强(第3种)----");
for (Object entry : entrySet) {
//将entry 转成 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
//(2) 迭代器
System.out.println("----使用EntrySet 的 迭代器(第4种)----");
Iterator iterator3 = entrySet.iterator();
while (iterator3.hasNext()) {
Object entry = iterator3.next();
//System.out.println(next.getClass());//HashMap$Node -实现-> Map.Entry (getKey,getValue)
//向下转型 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
}
}
Map课堂练习
MapExercise.java
使用HashMap添加3个员工对象,要求键:员工id
值:员工对象
并遍历显示工资>18000的员工(遍历方式最少两种)员工类:姓名、工资、员工id
package hspCollection.map;
import java.util.*;
/**
* Created by 此生辽阔 on 2021/7/24 10:58
*/
public class exercise1 {
public static void main(String[] args) {
HashMap hashMap = new HashMap();
hashMap.put(1, new employee("zs", 20000, 1));
hashMap.put(2, new employee("ls", 17000, 2));
hashMap.put(3, new employee("ww", 21000, 3));
// System.out.println(hashMap);
Set set = hashMap.entrySet();
for (Object obj : set) {
Map.Entry entry = (Map.Entry) obj;
employee emp = (employee) entry.getValue();
if (emp.salary > 18000) {
System.out.println(entry.getKey() + "--" + entry.getValue());
}
}
System.out.println("-----------------------");
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
Map.Entry entry = (Map.Entry) next;
System.out.println(entry.getKey() + "--" + entry.getValue());
}
System.out.println("-----------------------");
Set set1 = hashMap.keySet();
for(Object key:set1)
{
employee emp = (employee) hashMap.get(key);
if(emp.salary>18000)
{
System.out.println(key+"---"+emp);
}
}
}
}
class employee{
public String name;
public double salary;
public int id;
public employee(String name, double salary, int id) {
this.name = name;
this.salary = salary;
this.id = id;
}
@Override
public String toString() {
return "employee{" +
"name='" + name + '\'' +
", salary=" + salary +
", id=" + id +
'}';
}
}
HashMap阶段小结

HashMap底层机制

HashMap扩容与树化触发
树化
public class HashMapSource2 {
public static void main(String[] args) {
HashMap hashMap = new HashMap();
for(int i = 1; i <= 12; i++) {
hashMap.put(new A(i), "hello");
}
hashMap.put("aaa", "bbb");
System.out.println("hashMap=" + hashMap);//12个 k-v
//布置一个任务,自己设计代码去验证,table 的扩容
//0 -> 16(12) -> 32(24) -> 64(64*0.75=48)-> 128 (96) ->
//自己设计程序,验证-》 增强自己阅读源码能力. 看别人代码.
}
}
class A {
private int num;
public A(int num) {
this.num = num;
}
//所有的A对象的hashCode都是100
@Override
public int hashCode() {
return 100;
}
@Override
public String toString() {
return "\nA{" +
"num=" + num +
'}';
}
}
可以看到现在i已经加到8了,底层的table有7个元素(因为i对应的8还没有执行第8次添加元素)

这是底层的排列情况,一条长度为7的链表
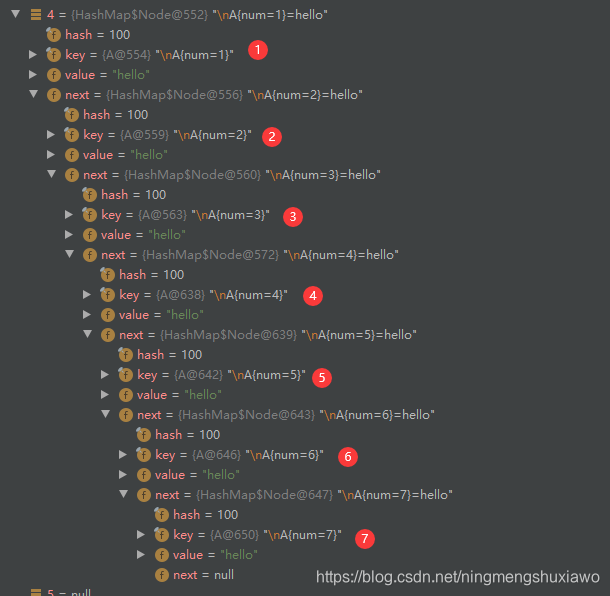
现在我们再执行第8次添加
容量是15,链表的长度是8
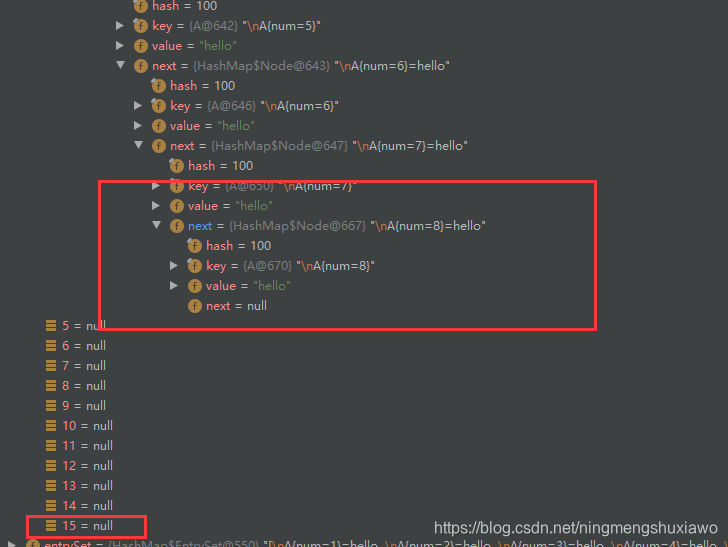
继续添加
由于链表长度到达了8,在添加第9个节点的时候,判断应该进行转化为红黑树,但是由于table中总的节点数没有达到64,所以只是进行了扩容,没有转化为红黑树,且此时链表的长度为9,

继续添加第10个节点,数组容量依然没有达到64(此时是32),所以不会转化成红黑树,将会继续扩容(扩容到64),此时链表长度为10
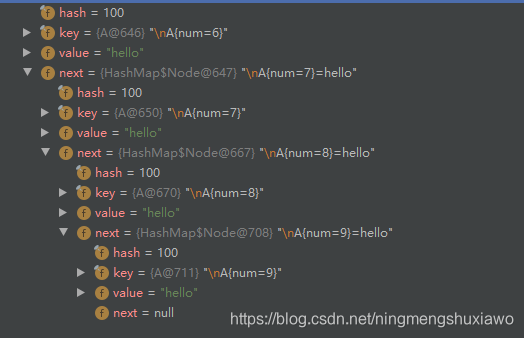
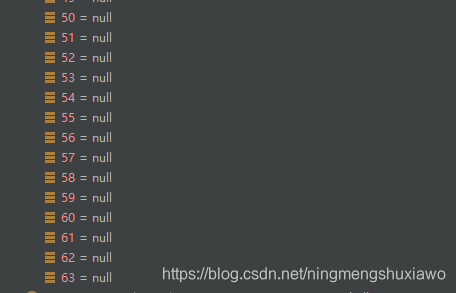
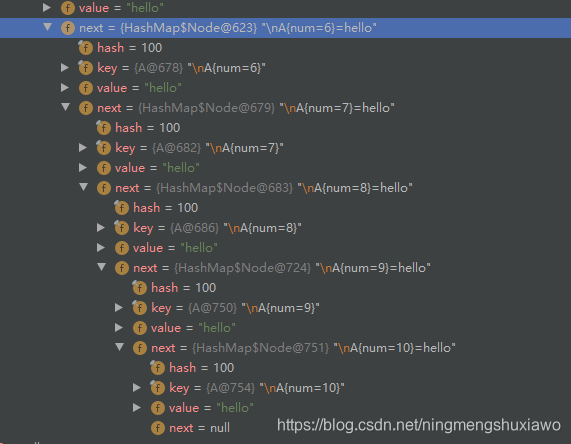
当添加第11个节点的时候,由于数组容量已经达到了64,所以会转化成红黑树,不再继续扩容
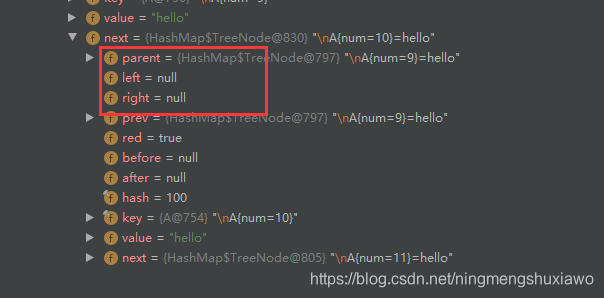
注意扩容后会影响元素的索引位置,因为hash值重新计算了
扩容
package hspCollection.map;
/**
* Created by 此生辽阔 on 2021/7/25 10:06
*/
import java.util.HashMap;
import java.util.Objects;
import java.util.Random;
public class HashMapSource2 {
public static void main(String[] args) {
Random r=new Random();
HashMap hashMap = new HashMap();
for(int i = 1; i <= 12; i++) {
hashMap.put(r.nextInt(100), "hello");
}
hashMap.put("aaa", "bbb");
System.out.println("hashMap=" + hashMap);//12个 k-v
}
}
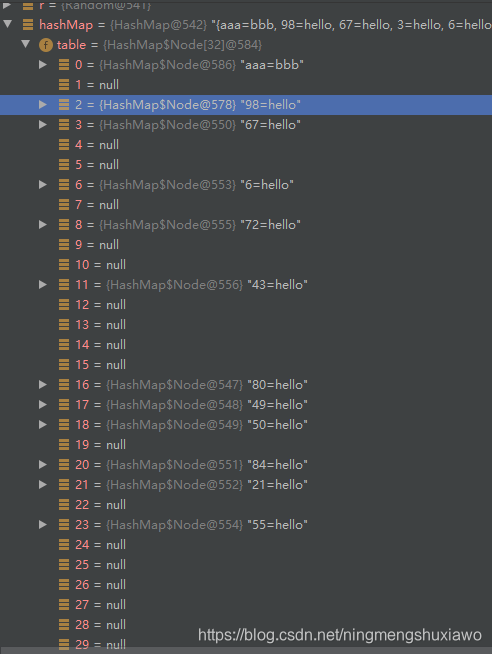
断点打在 hashMap.put(“aaa”, “bbb”);执行完结果如上图,现在还没有扩容,且节点数量刚好达到12各个,现在执行 hashMap.put(“aaa”, “bbb”);
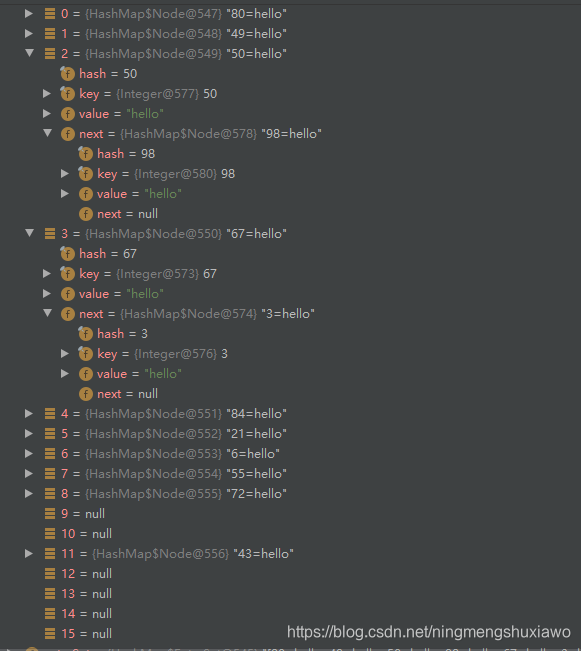
执行了扩容,且影响了原来元素的位置排列
HashTable使用

//简单说明一下Hashtable的底层
//1. 底层有数组 Hashtable$Entry[] 初始化大小为 11
//2. 临界值 threshold 8 = 11 * 0.75
//3. 扩容: 按照自己的扩容机制来进行即可.
//4. 执行 方法 addEntry(hash, key, value, index); 添加K-V 封装到Entry
//5. 当 if (count >= threshold) 满足时,就进行扩容
//6. 按照 int newCapacity = (oldCapacity << 1) + 1; 的大小扩容.(2倍加1)

Properties
properties是hashtable的子类,所以间接地实现了Map接口

public class Properties_ {
public static void main(String[] args) {
//老韩解读
//1. Properties 继承 Hashtable
//2. 可以通过 k-v 存放数据,当然key 和 value 不能为 null
//增加
Properties properties = new Properties();
//properties.put(null, "abc");//抛出 空指针异常
//properties.put("abc", null); //抛出 空指针异常
properties.put("john", 100);//k-v
properties.put("lucy", 100);
properties.put("lic", 100);
properties.put("lic", 88);//如果有相同的key , value被替换
System.out.println("properties=" + properties);
//通过k 获取对应值
System.out.println(properties.get("lic"));//88
//删除
properties.remove("lic");
System.out.println("properties=" + properties);
//修改
properties.put("john", "约翰");
System.out.println("properties=" + properties);
}
}
集合选型规则
TreeSet源码解读
TreeSet实现了Set接口,与HashSet最大的区别是可以排序
在向TreeSet添加元素时,如果不指定比较器,那么会将Key强制转化为比较器比较,因此key必须实现Comparable接口,不然无法添加元素
比如
public class treesettEST {
public static void main(String[] args) {
TreeSet<Object> treeSet = new TreeSet<>();
treeSet.add(new person(2));
treeSet.add(new person(3));
}
}
class person{
private int i;
public person(int i) {
this.i = i;
}
}

TreeSet底层是TreeMap,TreeMap有一个属性是comparator

package com.hspedu.set_;
import java.util.Comparator;
import java.util.TreeSet;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class TreeSet_ {
public static void main(String[] args) {
//老韩解读
//1. 当我们使用无参构造器,创建TreeSet时,仍然是无序的
//2. 老师希望添加的元素,按照字符串大小来排序
//3. 使用TreeSet 提供的一个构造器,可以传入一个比较器(匿名内部类)
// 并指定排序规则
//4. 简单看看源码
//老韩解读
/*
1. 构造器把传入的比较器对象,赋给了 TreeSet的底层的 TreeMap的属性this.comparator
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
2. 在 调用 treeSet.add("tom"), 在底层会执行到
if (cpr != null) {//cpr 就是我们的匿名内部类(对象)
do {
parent = t;
//动态绑定到我们的匿名内部类(对象)compare
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else //如果相等,即返回0,这个Key就没有加入
return t.setValue(value);
} while (t != null);
}
*/
// TreeSet treeSet = new TreeSet();
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//下面 调用String的 compareTo方法进行字符串大小比较
//如果老韩要求加入的元素,按照长度大小排序
//return ((String) o2).compareTo((String) o1);
return ((String) o1).length() - ((String) o2).length();
}
});
//添加数据.
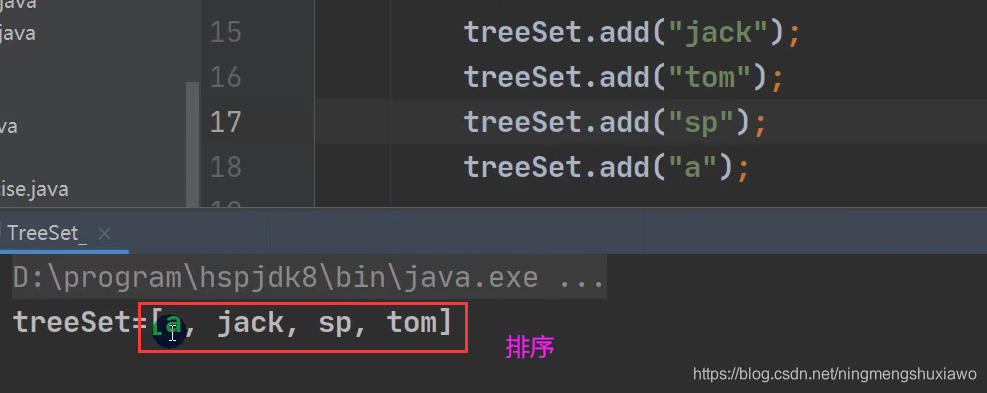
treeSet.add("jack");
treeSet.add("tom");//3
treeSet.add("sp");
treeSet.add("a");
treeSet.add("abc");//3
System.out.println("treeSet=" + treeSet);
}
}
TreeMap源码解读
package com.hspedu.map_;
import java.util.Comparator;
import java.util.TreeMap;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class TreeMap_ {
public static void main(String[] args) {
//使用默认的构造器,创建TreeMap, 是无序的(也没有排序)
/*
老韩要求:按照传入的 k(String) 的大小进行排序
*/
// TreeMap treeMap = new TreeMap();
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//按照传入的 k(String) 的大小进行排序
//按照K(String) 的长度大小排序
//return ((String) o2).compareTo((String) o1);
return ((String) o2).length() - ((String) o1).length();
}
});
treeMap.put("jack", "杰克");
treeMap.put("tom", "汤姆");
treeMap.put("kristina", "克瑞斯提诺");
treeMap.put("smith", "斯密斯");
treeMap.put("hsp", "韩顺平");//加入不了
System.out.println("treemap=" + treeMap);
/*
老韩解读源码:
1. 构造器. 把传入的实现了 Comparator接口的匿名内部类(对象),传给给TreeMap的comparator
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
2. 调用put方法
2.1 第一次添加, 把k-v 封装到 Entry对象,放入root
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
2.2 以后添加
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do { //遍历所有的key , 给当前key找到适当位置
parent = t;
cmp = cpr.compare(key, t.key);//动态绑定到我们的匿名内部类的compare
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else //如果遍历过程中,发现准备添加Key 和当前已有的Key 相等,就不添加
return t.setValue(value);
} while (t != null);
}
*/
}
}
Collections工具类


package com.hspedu.collections_;
import java.util.*;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class Collections_ {
public static void main(String[] args) {
//创建ArrayList 集合,用于测试.
List list = new ArrayList();
list.add("tom");
list.add("smith");
list.add("king");
list.add("milan");
list.add("tom");
// reverse(List):反转 List 中元素的顺序
Collections.reverse(list);
System.out.println("list=" + list);
// shuffle(List):对 List 集合元素进行随机排序
// for (int i = 0; i < 5; i++) {
// Collections.shuffle(list);
// System.out.println("list=" + list);
// }
// sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
Collections.sort(list);
System.out.println("自然排序后");
System.out.println("list=" + list);
// sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
//我们希望按照 字符串的长度大小排序
Collections.sort(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//可以加入校验代码.
return ((String) o2).length() - ((String) o1).length();
}
});
System.out.println("字符串长度大小排序=" + list);
// swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
//比如
Collections.swap(list, 0, 1);
System.out.println("交换后的情况");
System.out.println("list=" + list);
//Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
System.out.println("自然顺序最大元素=" + Collections.max(list));
//Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
//比如,我们要返回长度最大的元素
Object maxObject = Collections.max(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length() - ((String)o2).length();
}
});
System.out.println("长度最大的元素=" + maxObject);
//Object min(Collection)
//Object min(Collection,Comparator)
//上面的两个方法,参考max即可
//int frequency(Collection,Object):返回指定集合中指定元素的出现次数
System.out.println("tom出现的次数=" + Collections.frequency(list, "tom"));
//void copy(List dest,List src):将src中的内容复制到dest中
ArrayList dest = new ArrayList();
//为了完成一个完整拷贝,我们需要先给dest 赋值,大小和list.size()一样
for(int i = 0; i < list.size(); i++) {
dest.add("");
}
//拷贝
Collections.copy(dest, list);
System.out.println("dest=" + dest);
//boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值
//如果list中,有tom 就替换成 汤姆
Collections.replaceAll(list, "tom", "汤姆");
System.out.println("list替换后=" + list);
}
}
集合家庭作业1

package hspCollection.homework;
import java.util.ArrayList;
/**
* Created by 此生辽阔 on 2021/7/25 21:00
*/
public class homework01 {
public static void main(String[] args) {
news news = new news("新冠确诊病例超干方,数百万印度教信徒赴恒河“圣浴”引民众担忧");
news news2 = new news("男子突然想起2个月前钓的鱼还在网兜里,捞起一看赶紧放生");
ArrayList arrayList = new ArrayList();
arrayList.add(news );
arrayList.add(news2 );
for(int i=arrayList.size();i>0;i--)
{
news obj=(news)arrayList.get(i-1);
System.out.println(obj.getTitle().substring(0,15)+"...");
}
}
}
class news{
String title;
String type;
@Override
public String toString() {
return "news{" +
"title='" + title + '\'' +
'}';
}
public news(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
}
韩老师的代码
package com.hspedu.homework;
import java.util.ArrayList;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class Homework01 {
public static void main(String[] args) {
ArrayList arrayList = new ArrayList();
arrayList.add(new News("新冠确诊病例超千万,数百万印度教信徒赴恒河\"圣浴\"引民众担忧"));
arrayList.add(new News("男子突然想起2个月前钓的鱼还在网兜里,捞起一看赶紧放生"));
int size = arrayList.size();
for (int i = size - 1; i >= 0; i--) {
//System.out.println(arrayList.get(i));
News news = (News)arrayList.get(i);
System.out.println(processTitle(news.getTitle()));
}
}
//专门写一个方法,处理现实新闻标题 process处理
public static String processTitle(String title) {
if(title == null) {
return "";
}
if(title.length() > 15) {
return title.substring(0, 15) + "..."; //[0,15)
} else {
return title;
}
}
}
/**
* 按要求实现:
* (1) 封装一个新闻类,包含标题和内容属性,提供get、set方法,重写toString方法,打印对象时只打印标题;
* (2) 只提供一个带参数的构造器,实例化对象时,只初始化标题;并且实例化两个对象:
* 新闻一:新冠确诊病例超千万,数百万印度教信徒赴恒河“圣浴”引民众担忧
* 新闻二:男子突然想起2个月前钓的鱼还在网兜里,捞起一看赶紧放生
* (3) 将新闻对象添加到ArrayList集合中,并且进行倒序遍历;
* (4) 在遍历集合过程中,对新闻标题进行处理,超过15字的只保留前15个,然后在后边加“…”
* (5) 在控制台打印遍历出经过处理的新闻标题;
*/
class News {
private String title;
private String content;
public News(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
return "News{" +
"title='" + title + '\'' +
'}';
}
}
集合家庭作业2

package com.hspedu.homework;
import java.util.ArrayList;
import java.util.Iterator;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class Homework02 {
public static void main(String[] args) {
ArrayList arrayList = new ArrayList();
Car car = new Car("宝马", 400000);
Car car2 = new Car("宾利",5000000);
//1.add:添加单个元素
arrayList.add(car);
arrayList.add(car2);
System.out.println(arrayList);
//* 2.remove:删除指定元素
arrayList.remove(car);
System.out.println(arrayList);
//* 3.contains:查找元素是否存在
System.out.println(arrayList.contains(car));//F
//* 4.size:获取元素个数
System.out.println(arrayList.size());//1
//* 5.isEmpty:判断是否为空
System.out.println(arrayList.isEmpty());//F
//* 6.clear:清空
//System.out.println(arrayList.clear(););//clear是void无法打印
//* 7.addAll:添加多个元素
System.out.println(arrayList);
arrayList.addAll(arrayList);//2个宾利
System.out.println(arrayList);
//* 8.containsAll:查找多个元素是否都存在
arrayList.containsAll(arrayList);//T
//* 9.removeAll:删除多个元素
//arrayList.removeAll(arrayList); //相当于清空
//* 使用增强for和 迭代器来遍历所有的car , 需要重写 Car 的toString方法
for (Object o : arrayList) {
System.out.println(o);//
}
System.out.println("===迭代器===");
Iterator iterator = arrayList.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
}
}
/**
* 使用ArrayList 完成对 对象 Car {name, price} 的各种操作
* 1.add:添加单个元素
* 2.remove:删除指定元素
* 3.contains:查找元素是否存在
* 4.size:获取元素个数
* 5.isEmpty:判断是否为空
* 6.clear:清空
* 7.addAll:添加多个元素
* 8.containsAll:查找多个元素是否都存在
* 9.removeAll:删除多个元素
* 使用增强for和 迭代器来遍历所有的car , 需要重写 Car 的toString方法
*/
class Car {
private String name;
private double price;
public Car(String name, double price) {
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "Car{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
}
集合家庭作业3
我的

package hspCollection.homework;
import java.util.*;
/**
* Created by 此生辽阔 on 2021/7/25 21:18
*/
public class homework03 {
public static void main(String[] args) {
//(1)
Map<String,Integer> m= new HashMap();
m.put("jack",650);
m.put("tom",1200);
m.put("smith",2900);
//(2)
m.put("jack",2600);
//(3)
Set<String> strings = m.keySet();
for(String s:strings)
{
m.put(s,m.get(s)+100);
}
//(4)
for(String s:strings)
{
System.out.println(s);
}
//(5)
Collection<Integer> values = m.values();
Iterator<Integer> iterator ;
iterator = values.iterator();
while (iterator.hasNext()) {
Integer next = iterator.next();
System.out.println(next);
}
}
}
韩老师的
package com.hspedu.homework;
import java.util.*;
/**
* @author 韩顺平
* @version 1.0
*/
@SuppressWarnings({"all"})
public class Homework03 {
public static void main(String[] args) {
Map m = new HashMap();
m.put("jack", 650);//int->Integer
m.put("tom", 1200);//int->Integer
m.put("smith", 2900);//int->Integer
System.out.println(m);
m.put("jack", 2600);//替换,更新
System.out.println(m);
//为所有员工工资加薪100元;
//keySet
Set keySet = m.keySet();
for (Object key : keySet) {
//更新
m.put(key, (Integer)m.get(key) + 100);
}
System.out.println(m);
System.out.println("=============遍历=============");
//遍历 EntrySet
Set entrySet = m.entrySet();
//迭代器
Iterator iterator = entrySet.iterator();
while (iterator.hasNext()) {
Map.Entry entry = (Map.Entry)iterator.next();
System.out.println(entry.getKey() + "-" + entry.getValue());
}
System.out.println("====遍历所有的工资====");
Collection values = m.values();
for (Object value : values) {
System.out.println("工资=" + value);
}
}
}
/**
* 按要求完成下列任务
* 1)使用HashMap类实例化一个Map类型的对象m,键(String)和值(int)分别用于存储员工的姓名和工资,
* 存入数据如下: jack—650元;tom—1200元;smith——2900元;
* 2)将jack的工资更改为2600元
* 3)为所有员工工资加薪100元;
* 4)遍历集合中所有的员工
* 5)遍历集合中所有的工资
*/
集合家庭作业4


集合家庭作业5
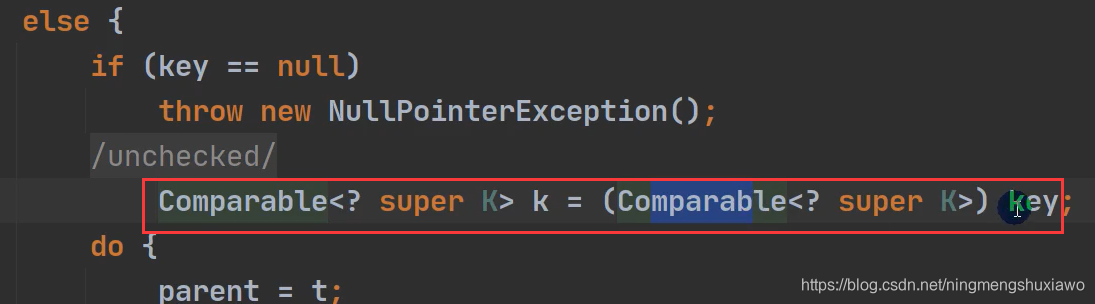
当没有传入匿名的comparator,底层会运行到这里,把key转成Comparable接口类型,然后调用key的CompareTo方法进行比较,如果person类没有实现Comparable接口,则会报错类型转换异常

集合家庭作业6

每个Node都会保存自己的hash,但是p1在put之后修改了name,remove的时候传入的p1的jhash值无法匹配,所以无法删除
你要是能删除,你肯定没有重写hashcode和equals
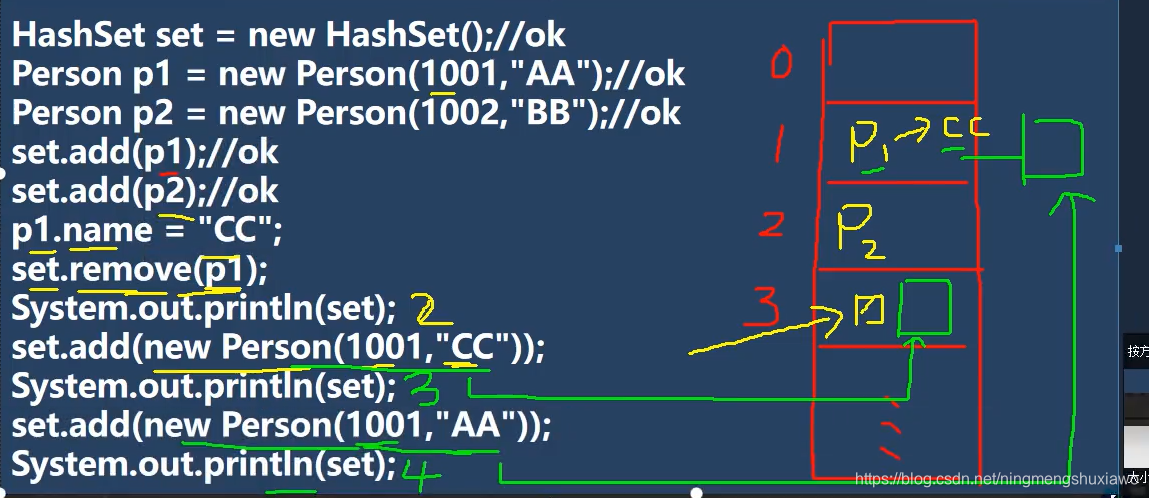
对于new person(1001,“CC”),是可以加进去的,因为它跟原来的p1(1001,“AA”)的hash值不一样,但是注意,现在hashSet里面的p1已经是(1001,“CC”)了,因为你本质上存进去的是p1的地址呀,现在原来地址上的内容已经改变了。
对于new person(1001,“AA”)也是可以加进去的,因为他跟之前的(1001,“AA”)的hash值是一样的,不过不equals,原来的现在是(1001,“CC”),插入的是1001,“AA”)所以会形成链表,最后set里面有四个元素
package homework;
/**
* Created by 此生辽阔 on 2021/7/28 11:42
*/
import java.util.HashSet;
import java.util.Objects;
@SuppressWarnings({"all"})
public class Homework06 {
public static void main(String[] args) {
HashSet set = new HashSet();//ok
Person p1 = new Person(1001,"AA");//ok
Person p2 = new Person(1002,"BB");//ok
set.add(p1);//ok
set.add(p2);//ok
p1.name = "CC";
set.remove(p1);
System.out.println(set);//2
set.add(new Person(1001,"CC"));
System.out.println(set);//3
set.add(new Person(1001,"AA"));
System.out.println(set);//4
}
}
class Person {
public String name;
public int id;
public Person(int id, String name) {
this.name = name;
this.id = id;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return id == person.id &&
Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, id);
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", id=" + id +
'}';
}
}

就算涉及扩容,也不会影响被修改后的p1,因为扩容后重新定位还是用的原来的hash值
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
集合家庭作业7

集合内容梳理