概述
在Spark中很多地方都涉及网络通信,比如 Spark各个组件间的消息互通、用户文件与Jar包的上传、节点间的Shuffle过程、Block数据的复制与备份等。Spark1.6之前,Spark的Rpc是基于Akka来实现的,Akka是一个基于scala语言的异步的消息框架,但由于Akka不适合大文件的传输,在Spark1.6之前RPC通过Akka来实现,而大文件是基于Jetty实现的HttpFileServer。但在Spark1.6中移除了Akka(https://issues.apache.org/jira/plugins/servlet/mobile#issue/SPARK-5293),原因概括为:
- 很多Spark用户也使用Akka,但是由于Akka不同版本之间无法互相通信,这就要求用户必须使用跟Spark完全一样的Akka版本,导致用户无法升级Akka。
- Spark的Akka配置是针对Spark自身来调优的,可能跟用户自己代码中的Akka配置冲突。
- Spark用的Akka特性很少,这部分特性很容易自己实现。同时,这部分代码量相比Akka来说少很多,debug比较容易。如果遇到什么bug,也可以自己马上fix,不需要等Akka上游发布新版本。而且,Spark升级Akka本身又因为第一点会强制要求用户升级他们使用的Akka,对于某些用户来说是不现实的。
在Spark2.0.0中也移除了Jetty,在Spark2.0.0版本借鉴了Akka的设计,重构了基于Netty的Rpc框架体系,其中Rpc和大文件传输都是使用Netty。
注:
- [1] Akka是基于Actor并发编程模型实现的并发的分布式的框架。Akka是用Scala语言编写的,它提供了Java和Scala两种语言的API,减少开发人员对并发的细节处理,并保证分布式调用的最终一致性。
- [2] Jetty 是一个开源的Servlet容器,它为基于Java的Web容器,例如JSP和Servlet提供运行环境。Jetty是使用Java语言编写的,它的API以一组JAR包的形式发布。开发人员可以将Jetty容器实例化成一个对象,可以迅速为一些独立运行的Java应用提供网络和Web连接。在附录C中有对Jetty的简单介绍,感兴趣的读者可以选择阅读。
- [3] Netty是由Jboss提供的一个基于NIO的客户、服务器端编程框架,使用Netty 可以确保你快速、简单的开发出一个网络应用,例如实现了某种协议的客户,服务端应用。
注:如下涉及的源码版本为Spark2.4,下面部分图片摘之网上大佬博客。
基本概念
首先我们给出两张UML图(简易版 + 复杂版)
上图中继承RpcEndpoint接口的类是实现业务逻辑的重点,其中直接继承RpcEndpoint的类支持并发,而继承ThreadSafeRpcEndpoint不支持并发,保证了线程安全,上图继承类只列出了Master和Worker两个,不够全面,下面单独给出一张RpcEndpoint继承图供参考:
下面介绍一些重要概念:
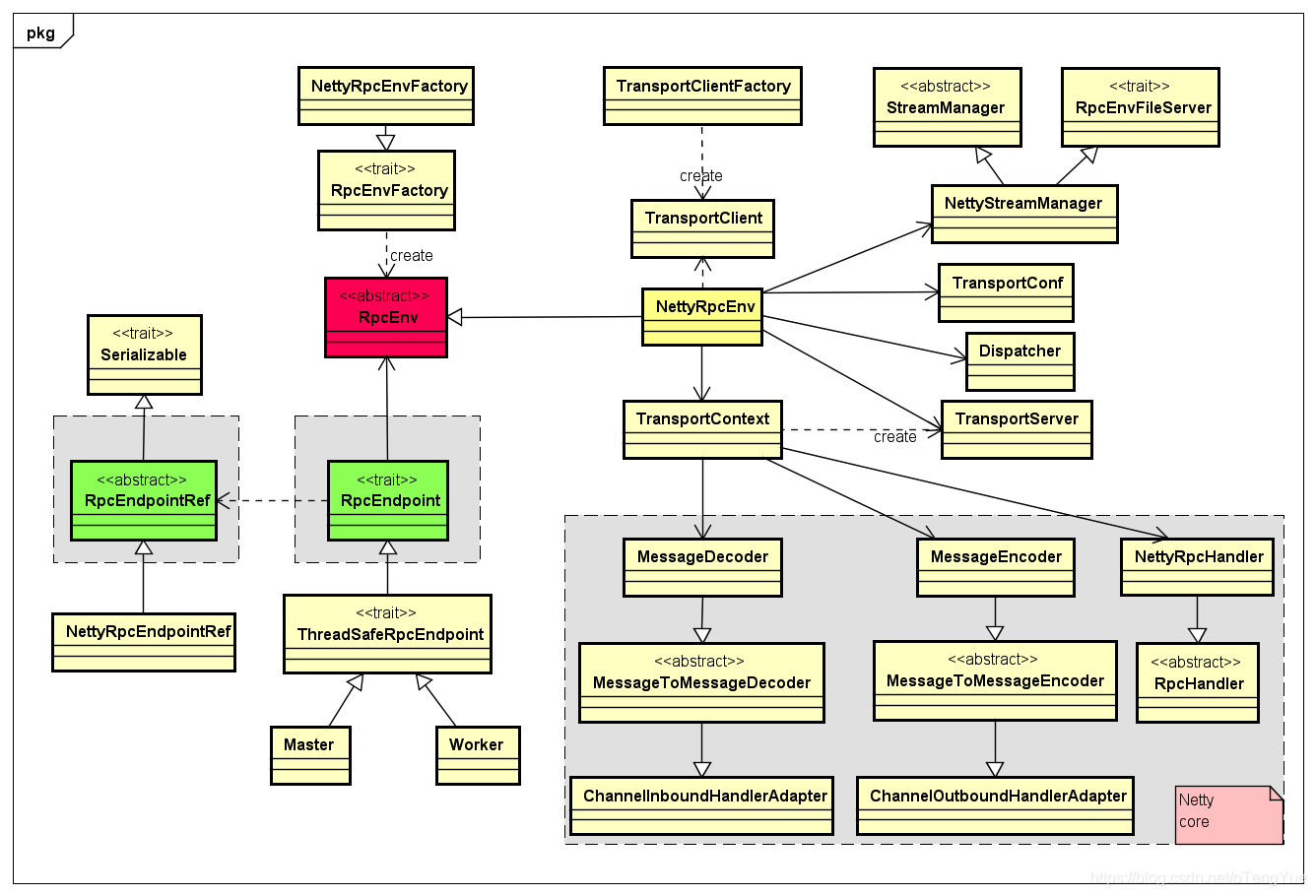
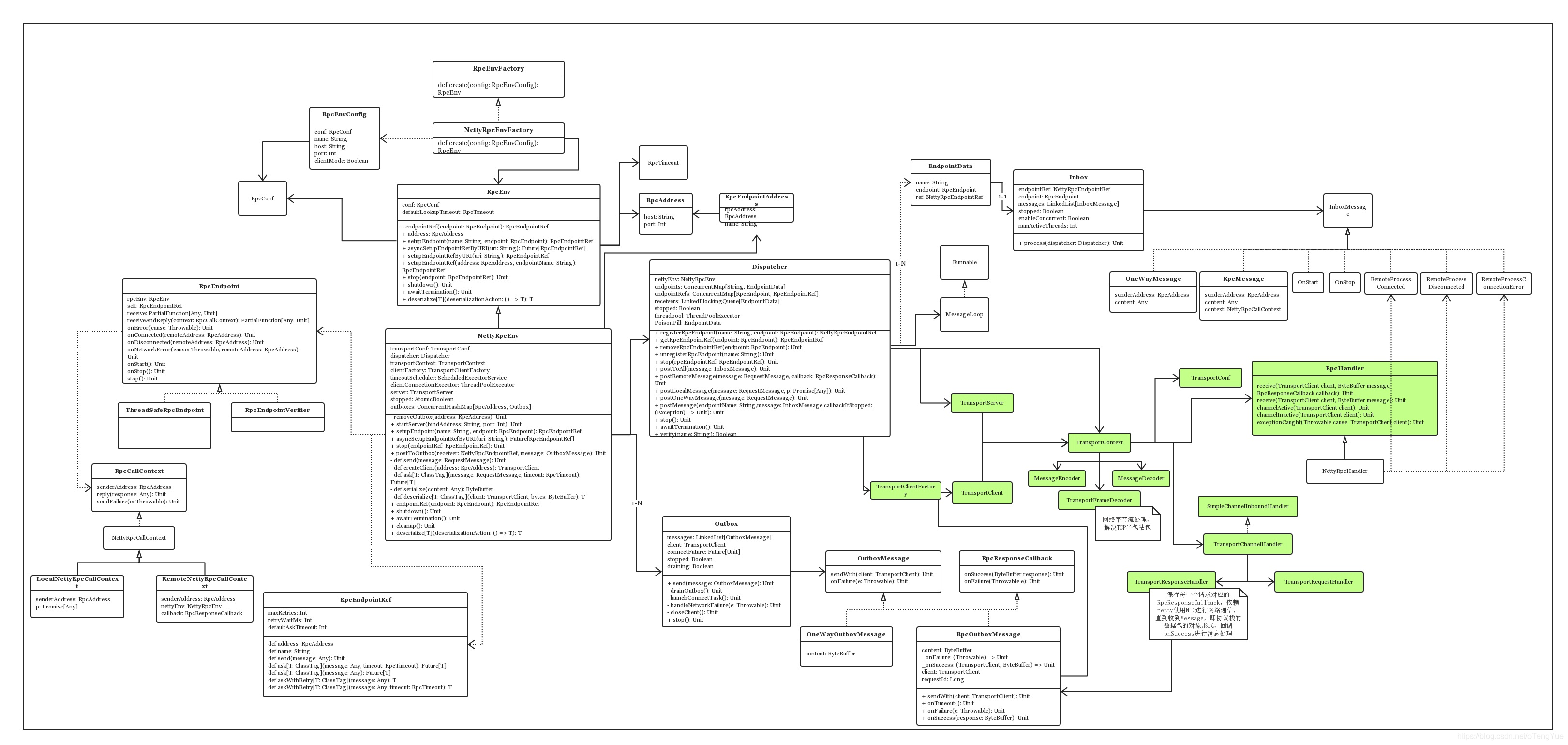
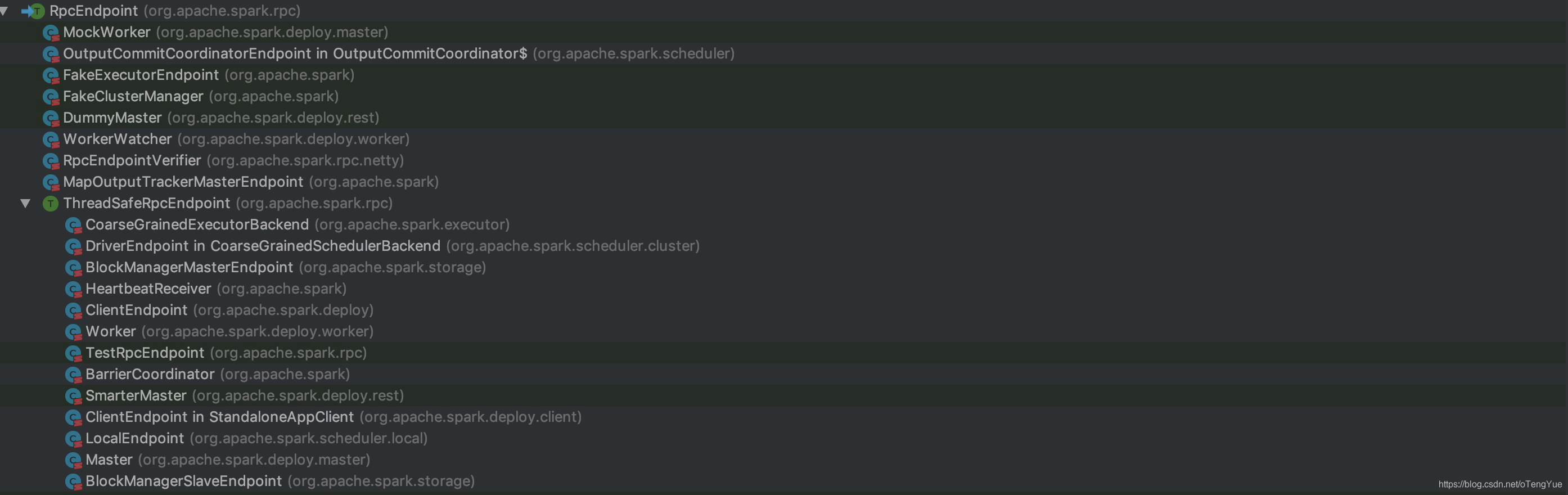
- RpcEnv:RpcEnv 抽象类表示一个 RPC Environment,管理着整个RpcEndpoint的生命周期,每个 Rpc 端点运行时依赖的环境称之为 RpcEnv。
- NettyRpcEnv: RpcEnv的唯一实现类
- RpcEndpoint:RPC 端点 ,Spark 将每个通信实体都都称之一个Rpc端点,且都实现 RpcEndpoint 接口,比如DriverEndpoint,MasterEndpont,内部根据不同端点的需求,设计不同的消息和不同的业务处理。
- Dispatcher:消息分发器(来自netty的概念),负责将 RpcMessage 分发至对应的 RpcEndpoint。Dispatcher 中包含一个 MessageLoop,它读取 LinkedBlockingQueue 中的投递 RpcMessage,根据客户端指定的 Endpoint 标识,找到 Endpoint 的 Inbox,然后投递进去,由于是阻塞队列,当没有消息的时候自然阻塞,一旦有消息,就开始工作。Dispatcher 的 ThreadPool 负责消费这些 Message。
- EndpointData:每个endpoint都有一个对应的EndpointData,EndpointData内部包含了RpcEndpoint、NettyRpcEndpointRef信息,与一个Inbox,收信箱Inbox内部有一个InboxMessage链表,发送到该endpoint的消息,就是添加到该链表,同时将整个EndpointData添加Dispatcher到阻塞队列receivers中,由Dispatcher线程异步处理
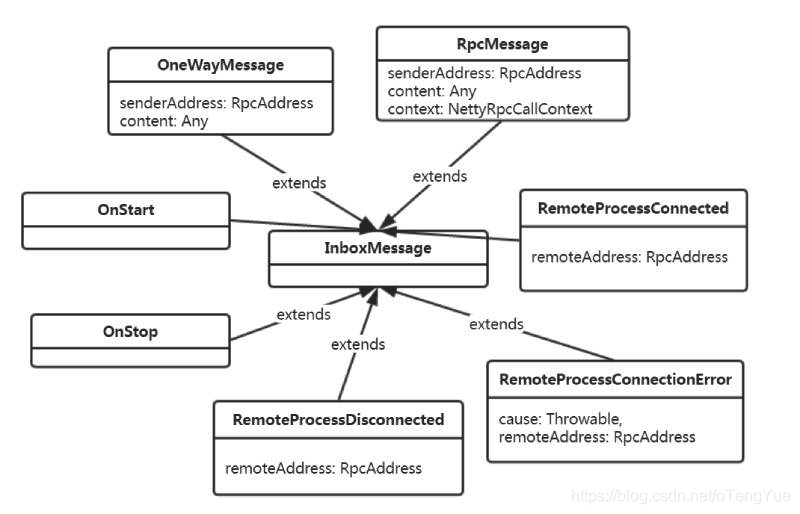
- Inbox:一个本地端点对应一个收件箱,Inbox 里面有一个 InboxMessage 的链表,InboxMessage 有很多子类,可以是远程调用过来的 RpcMessage,可以是远程调用过来的 fire-and-forget 的单向消息 OneWayMessage,还可以是各种服务启动,链路建立断开等 Message,这些 Message 都会在 Inbox 内部的方法内做模式匹配,调用相应的 RpcEndpoint 的函数。
- RpcEndPointRef: RpcEndpointRef是一个对RpcEndpoint的远程引用对象,通过它可以向远程的RpcEndpoint端发送消息以进行通信。
- NettyRpcEndpointRef:RpcEndpointRef 的唯一实现类,RpcEndpointRef的NettyRpcEnv版本。此类的行为取决于它的创建位置。在“拥有”RpcEndpoint的节点上,它是RpcEndpointAddress实例的简单包装器。
- RpcEndpointAddress:主要包含了 RpcAddress (host和port) 和 rpc endpoint name的信息
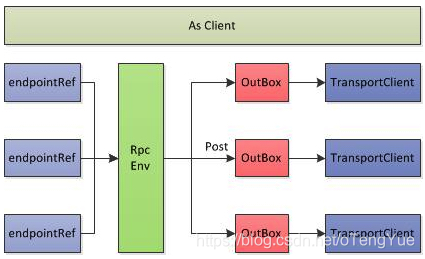
- Outbox:一个远程端点对应一个发件箱,NettyRpcEnv 中包含一个 ConcurrentHashMap[RpcAddress, Outbox]。当消息放入 Outbox 后,紧接着将消息通过 TransportClient 发送出去。
- TransportContext:是一个创建TransportServer, TransportClientFactory,使用TransportChannelHandler建立netty channel pipeline的上下文,这也是它的三个主要功能。TransportClient 提供了两种通信协议:控制层面的RPC以及数据层面的 “chunk抓取”。用户通过构造方法传入的 rpcHandler 负责处理RPC 请求。并且 rpcHandler 负责设置流,这些流可以使用零拷贝IO以数据块的形式流式传输。TransportServer 和 TransportClientFactory 都为每一个channel创建一个 TransportChannelHandler对象。每一个TransportChannelHandler 包含一个 TransportClient,这使服务器进程能够在现有通道上将消息发送回客户端。
- TransportServer:TransportServer是RPC框架的服务端,可提供高效的、低级别的流服务。
- TransportServerBootstrap:定义了服务端引导程序的规范,服务端引导程序旨在当客户端与服务端建立连接之后,在服务端持有的客户端管道上执行的引导程序。用于初始化TransportServer
- TransportClientFactory:创建传输客户端(TransportClient)的传输客户端工厂类。
- TransportClient:RPC框架的客户端,用于获取预先协商好的流中的连续块。TransportClient旨在允许有效传输大量数据,这些数据将被拆分成几百KB到几MB的块。简言之,可以认为TransportClient就是Spark Rpc 最底层的基础客户端类。主要用于向server端发送rpc 请求和从server 端获取流的chunk块。
- TransportClientBootstrap:是在TransportClient上执行的客户端引导程序,主要对连接建立时进行一些初始化的准备(例如验证、加密)。TransportClientBootstrap所作的操作往往是昂贵的,好在建立的连接可以重用。用于初始化TransportClient
- TransportChannelHandler:传输层的handler,负责委托请求给TransportRequestHandler,委托响应给TransportResponseHandler。在传输层中创建的所有通道都是双向的。当客户端使用RequestMessage启动Netty通道(由服务器的RequestHandler处理)时,服务器将生成ResponseMessage(由客户端的ResponseHandler处理)。但是,服务器也会在同一个Channel上获取句柄,因此它可能会开始向客户端发送RequestMessages。这意味着客户端还需要一个RequestHandler,而Server需要一个ResponseHandler,用于客户端对服务器请求的响应。此类还处理来自io.netty.handler.timeout.IdleStateHandler的超时。如果存在未完成的提取或RPC请求但是至少在“requestTimeoutMs”上没有通道上的流量,我们认为连接超时。请注意,这是双工流量;如果客户端不断发送但是没有响应,我们将不会超时。
当TransportChannelHandler读取到的request是RequestMessage类型时,则将此消息的处理进一步交给TransportRequestHandler,当request是ResponseMessage时,则将此消息的处理进一步交给TransportResponseHandler。 - TransportResponseHandler:用于处理服务端的响应,并且对发出请求的客户端进行响应的处理程序。
- TransportRequestHandler:用于处理客户端的请求并在写完块数据后返回的处理程序。
- MessageEncoder:在将消息放入管道前,先对消息内容进行编码,防止管道另一端读取时丢包和解析错误。
- MessageDecoder:对从管道中读取的ByteBuf进行解析,防止丢包和解析错误;
- TransportFrameDecoder:对从管道中读取的ByteBuf按照数据帧进行解析;
- StreamManager:处理ChunkFetchRequest和StreamRequest请求
- RpcHandler:处理RpcRequest和OneWayMessage请求
- Message:Message是消息的抽象接口,消息实现类都直接或间接的实现了RequestMessage或ResponseMessage接口。
组件原理
Message消息
协议是应用层通信的基础,它提供了应用层通信的数据表示,以及编码和解码的能力。在Spark Network Common中,继承AKKA中的定义,将协议命名为Message,它继承Encodable,提供了encode的能力。
其中RequestMessage的具体实现有四种,分别是:

- StreamRequest:此消息表示向远程的服务发起请求,以获取流式数据。Stream消息主要用于driver到executor传输jar、file文件等。
- RpcRequest:此消息类型由远程的Rpc服务端进行处理的消息,是一种需要服务端向客户端回复的RPC请求信息类型。
- ChunkFetchRequest:请求获取流的单个块的序列。ChunkFetch消息用于抽象所有spark中涉及到数据拉取操作时需要传输的消息。
- OneWayMessage:此消息也需要由远程的RPC服务端进行处理,与RpcRequest不同的是不需要服务端向客户端回复。
由于OneWayMessage 不需要响应,所以ResponseMessage的对于成功或失败状态的实现各有两种,分别是:
- StreamResponse:处理StreamRequest成功后返回的消息;
- StreamFailure:处理StreamRequest失败后返回的消息;
- RpcResponse:处理RpcRequest成功后返回的消息;
- RpcFailure:处理RpcRequest失败后返回的消息;
- ChunkFetchSuccess:处理ChunkFetchRequest成功后返回的消息;
- ChunkFetchFailure:处理ChunkFetchRequest失败后返回的消息;
通信架构
Spark的Rpc框架是基于Actor模型,各个组件可以认为是一个个独立的实体,各个实体之间通过消息来进行通信。具体各个组件之间的关系图如下:
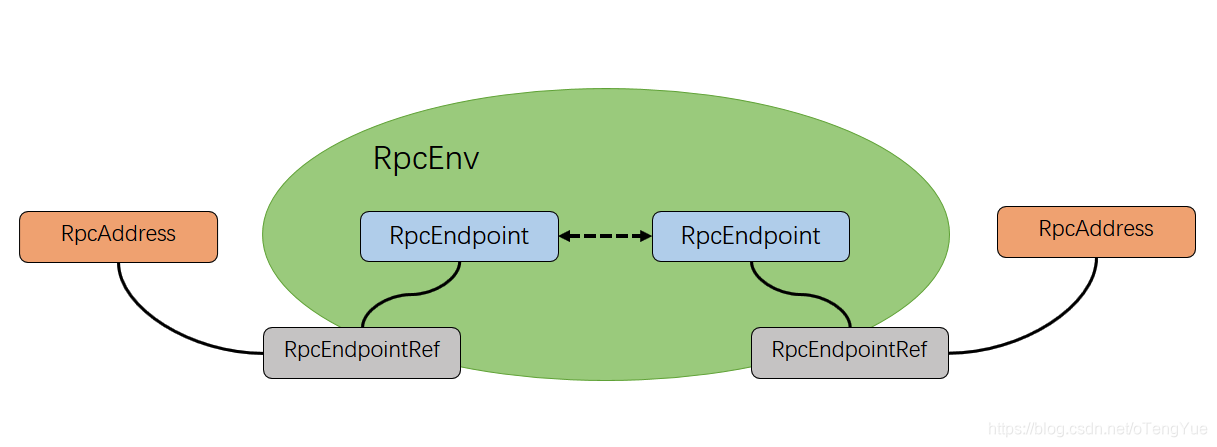
- RpcEnv:为RpcEndpoint提供处理消息的环境,是整个的核心。RpcEnv负责RpcEndpoint整个生命周期的管理,包括:注册endpoint,endpoint之间消息的路由,以及停止endpoint,而NettyRpcEnv目前是其唯一实现。
- RpcEndpoint:服务端,是根据接收的消息来进行对应的处理,一个RpcEndpoint经历的过程依次是:
create -> onStart -> receive -> onStop。其中onStart在接收任务消息前调用(在注册时候做为第一个自己处理的消息调用),receive和receiveAndReply分别用来接收send和ask过来的消息。 - RpcEndpointRef:客户端,是对远程RpcEndpoint的一个引用。当我们需要向一个具体的RpcEndpoint发送消息时,一般需要获取到该RpcEndpoint的引用,然后通过该引用发送消息,提供了
send(单向发送,提供fire-and-forget语义)和ask(带返回的请求,提供请求响应的语义)的消息发送方式,其中需要返回response的ask方式,带有超时机制,可以同步阻塞等待,也可以返回一个Future句柄,不阻塞发起请求的工作线程。另外RpcEndpointRef能够自动的区分做到本地调用或者远程Rpc调用。 - RpcAddress:表示远程的RpcEndpointRef的地址,包含【Host + Port】。
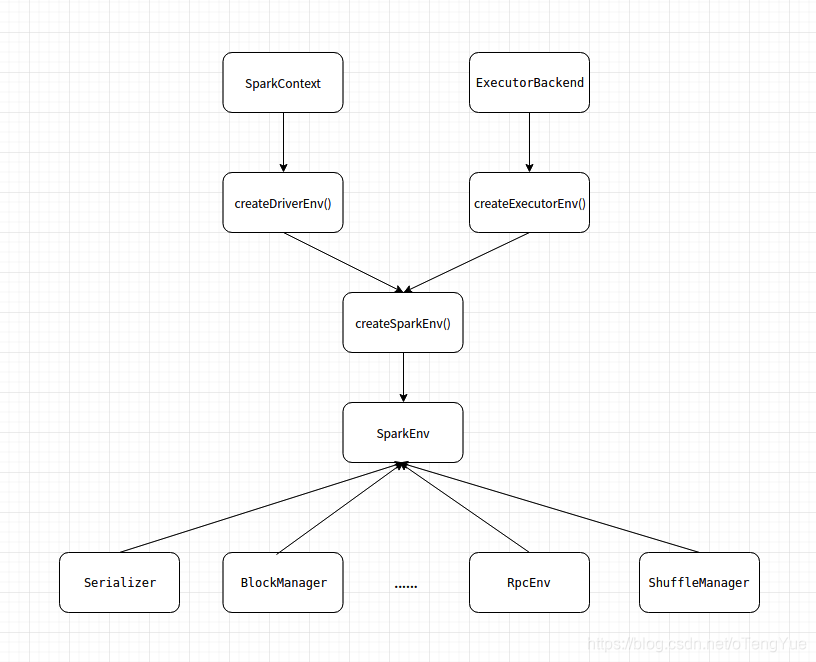
SparkEnv的初始化
SparkEnv保存着 Application 运行时的环境信息,包括 RpcEnv、Serializer、Block Manager 和 ShuffleManager 等,并为 Driver 端和 Executor 端分别提供了不同的创建方式。其中RpcEnv 维持着 Spark 节点间的通信,并负责将传递过来的消息转发给RpcEndpoint。
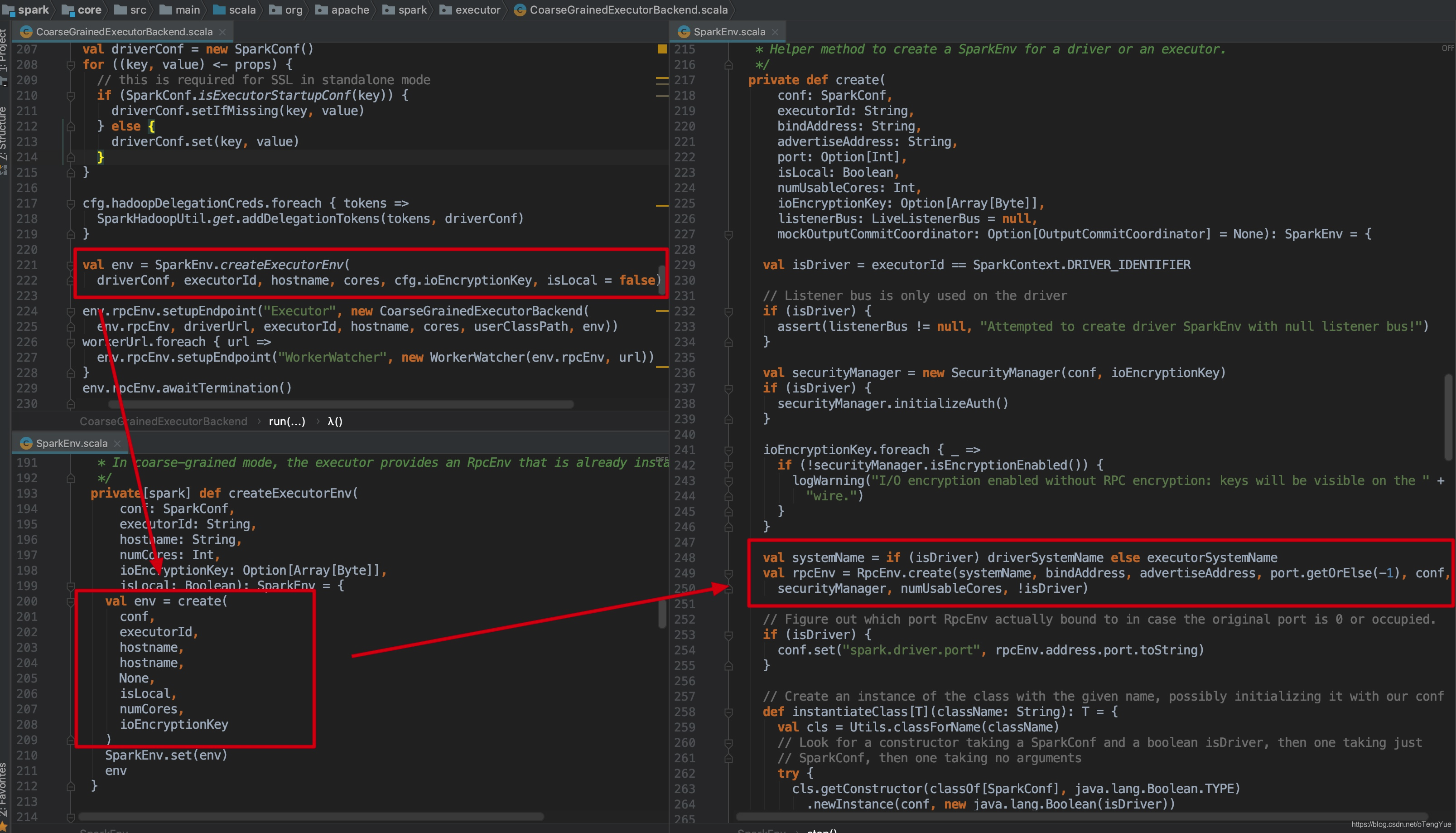
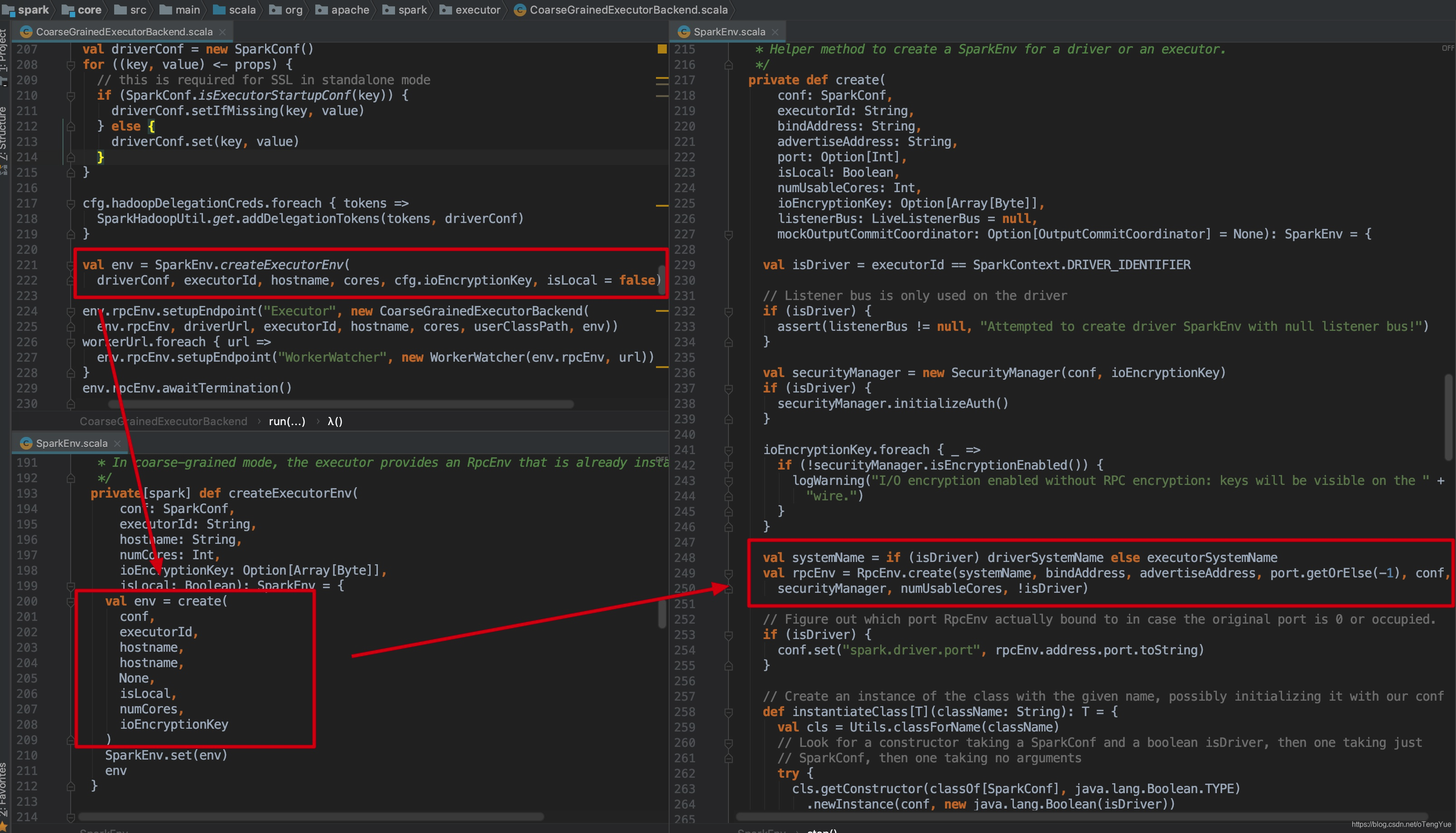
我们知道Executor启动是由CoarseGrainedExecutorBackend为入口类的,我们以sparkExecutor的RpcEnv初始化说明为例,看一下createExecutorEnv()的代码逻辑:
RpcEnv
RpcEnv不仅从外部接口与Akka基本一致,在内部的实现上,也基本差不多,都是按照MailBox的设计思路来实现的;
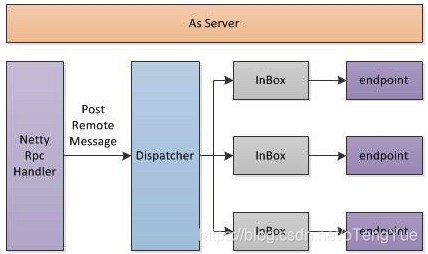
如上图所示,RpcEnv即充当着Server,同时也为Client内部实现。 当As Server,RpcEnv会初始化一个Server,并注册NettyRpcHandler,一般情况下,简单业务可以在RpcHandler直接完成请求的处理,但是考虑一个RpcEnv的Server上会挂载了很多个RpcEndpoint,每个RpcEndpoint的RPC请求频率不可控,因此需要对一定的分发机制和队列来维护这些请求,其中Dispatcher为分发器,InBox即为请求队列;
在将RpcEndpoint注册到RpcEnv过程中,也间接的将RpcEnv注册到Dispatcher分发器中,Dispatcher针对每个RpcEndpoint维护一个InBox,在Dispatcher维持一个线程池(线程池大小默认为系统可用的核数,当然也可以通过spark.rpc.netty.dispatcher.numThreads进行配置),线程针对每个InBox里面的请求进行处理。当然实际的处理过程是由RpcEndpoint来完成。
其次RpcEnv也完成Client的功能实现,RpcEndpointRef是以RpcEndpoint为单位,即如果一个进程需要和远程机器上N个RpcEndpoint服务进行通信,就对应N个RpcEndpointRef(后端的实际的网络连接是公用,这个是TransportClient内部提供了连接池来实现的),当调用一个RpcEndpointRef的ask/send等接口时候,会将把“消息内容+RpcEndpointRef+本地地址”一起打包为一个RequestMessage,交由RpcEnv进行发送。注意这里打包的消息里面包括RpcEndpointRef本身是很重要的,从而可以由Server端识别出这个消息对应的是哪一个RpcEndpoint。
和发送端一样,在RpcEnv中,针对每个remote端的host:port维护一个队列,即OutBox,RpcEnv的发送仅仅是把消息放入到相应的队列中,但是和发送端不一样的是:在OutBox中没有维护一个所谓的线程池来定时清理OutBox,而是通过一堆synchronized来实现的
下面我们看下RpcEnv相关类图:
RpcEnv相对于ActorSystem,主要提供以下作用:

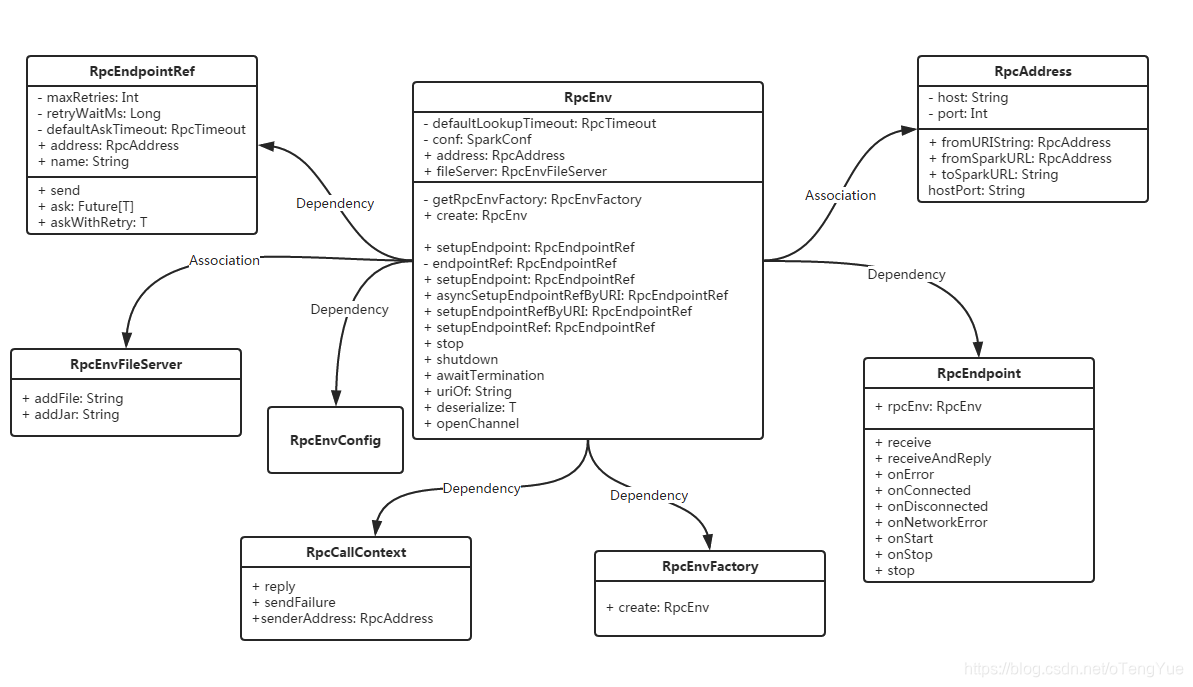
- 首先As Server,它通过NettyRpcHandler来提供了Server的服务能力,
- 其次它作为RpcEndpoint的容器,它提供了
setupEndpoint(name: String, endpoint: RpcEndpoint))接口,从而实现将一个RpcEndpoint以一个Name对应关系注册到容器中,从而通过Server对外提供Service - As Client的适配器,它提供了
setupEndpointRef(address: RpcAddress, endpointName: String)|setupEndpointRefByURI(uri: String)接口,通过指定Server端的Host和PORT,并指定RpcEndpointName,从而获取服务端Endpoint通信的引用。
Rpc服务端的启动流程
首先我们看下Rpc服务端启动过程,我们以sparkExecutor的RpcEnv初始化说起,由前面章节可知RpcEnv最终会调用RpcEnv.create()函数,我们从此开始分析:
经过上图中的三步之后就正式的开始初始化netty server,首先我们先看Spark对netty的封装,先看类图:
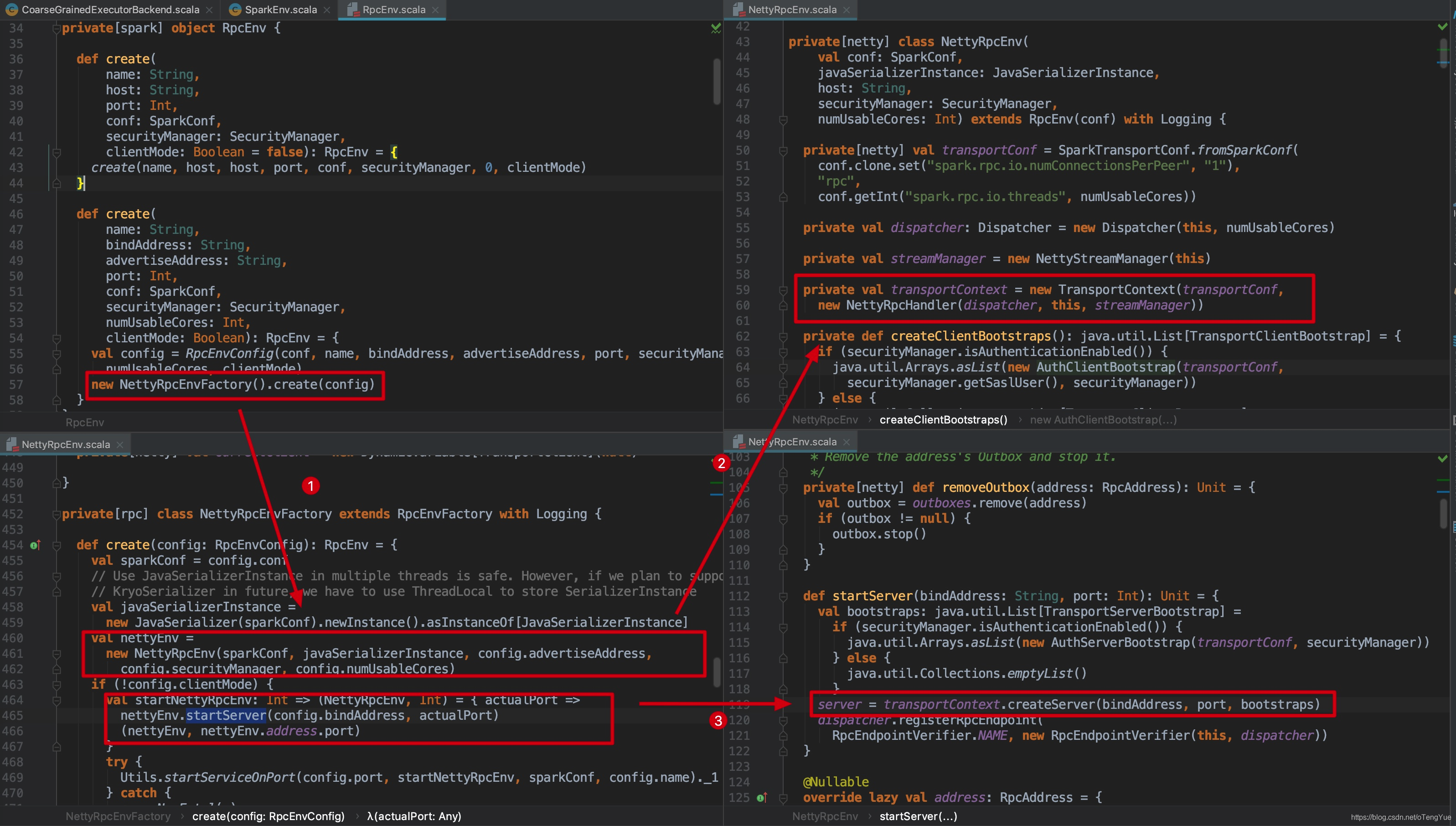
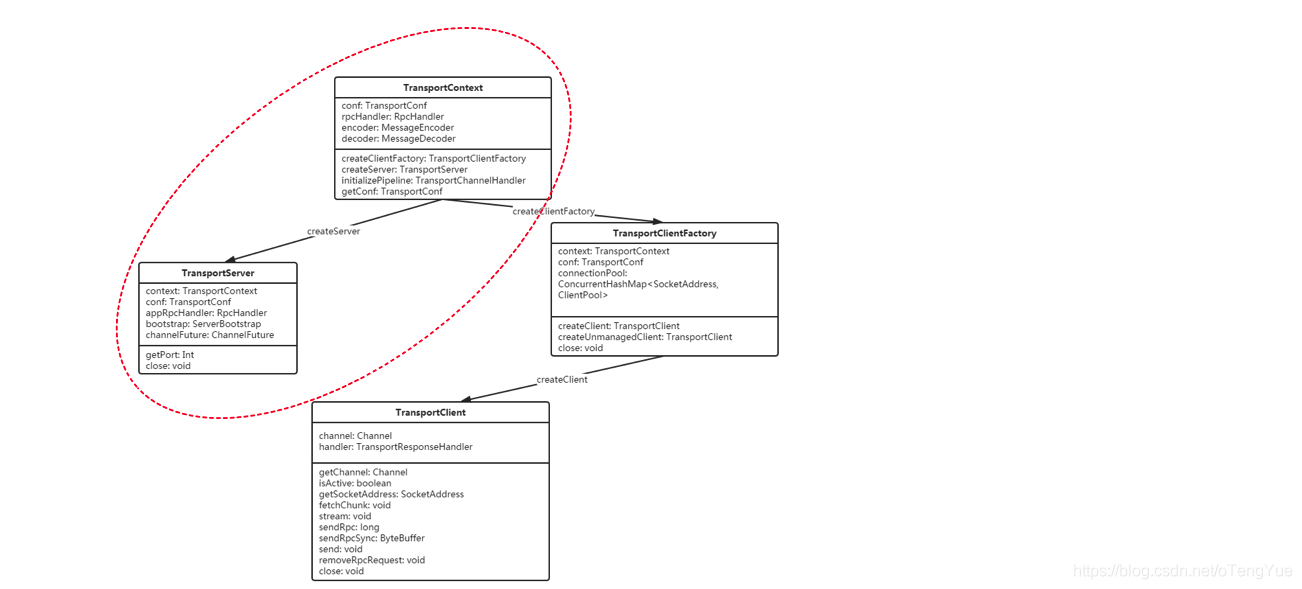
- TransportContext维护Transport的上下文环境,主要用来创建TransportServer和TransportClientFactory。
- TransportServer通过构造函数启动netty,提供响应请求服务。
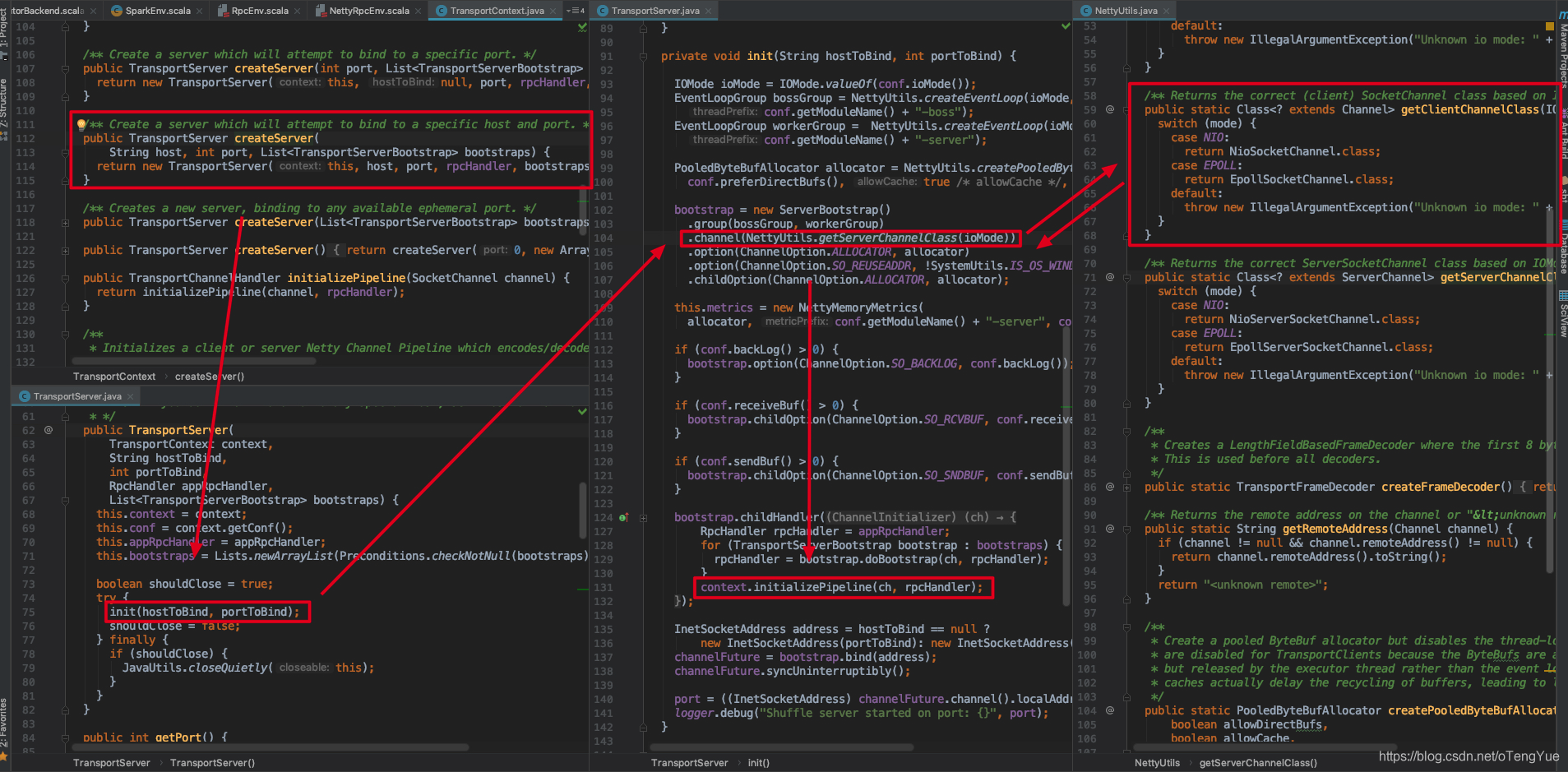
本节启动过程分析只涉及TransportContext和TransportServer(如上图虚线框住部分),我们接上面的源码继续分析如下:
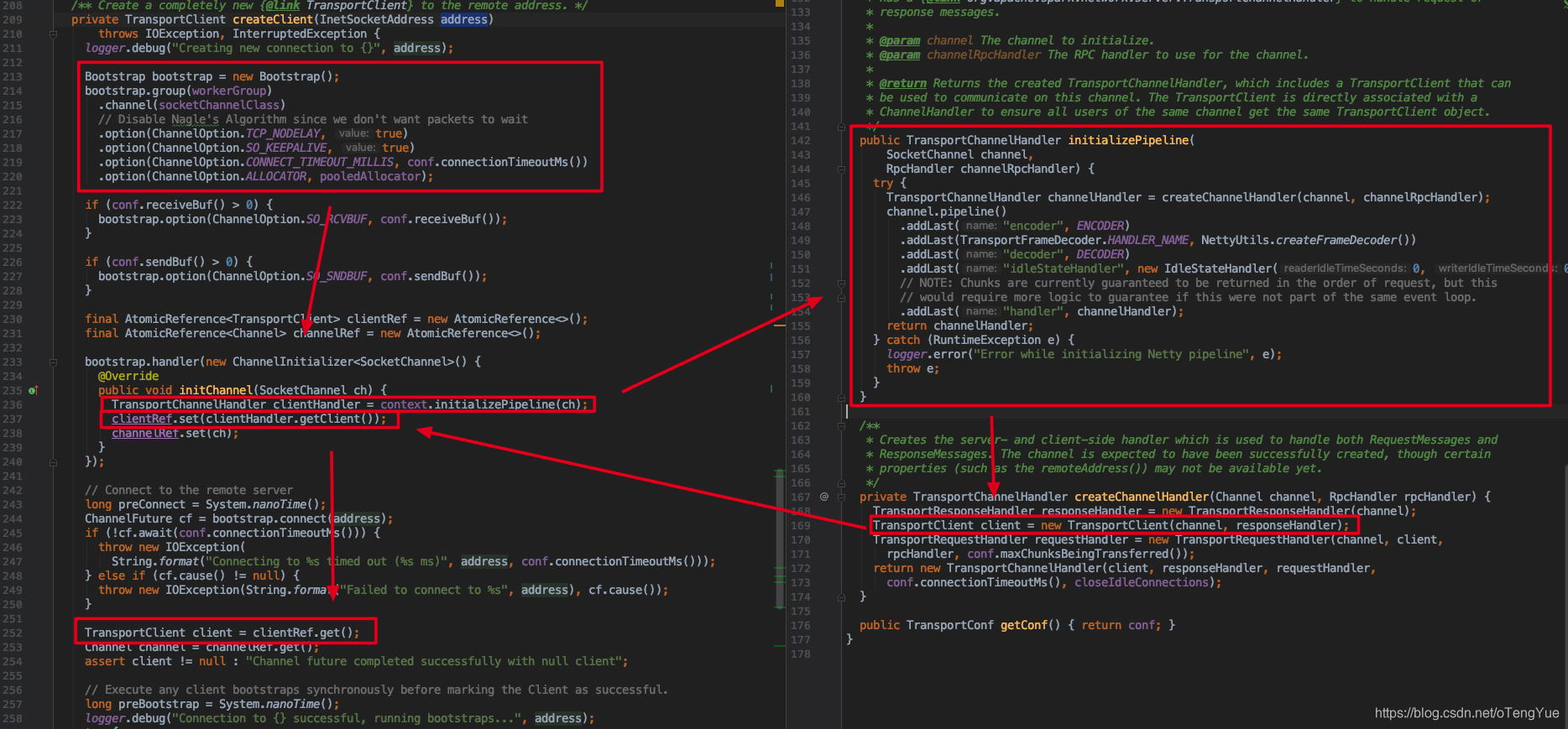
如上图,初始化流程最终会调用 context.initializePipeline(ch, rpcHandler) ,这个会初始化Netty的消息处理Pipeline,在继续介绍之前我们先介绍TransportChannelHandler,Netty处理Rpc类型请求依赖TransportChannelHandler,在TransportServer初始化时添加到pipeline中,其中TransportChannelHandler包含两个重要变量TransportResponseHandler和TransportRequestHandler,分别处理Response和Request请求。继续分析如下:
首先创建消息处理TransportChannelHandler添加到消息处理Pipline后,最后就可以设置为Netty的childHandler(),启动Netty监控即可接受消息,至此Rpc服务器的启动就完全完成了。
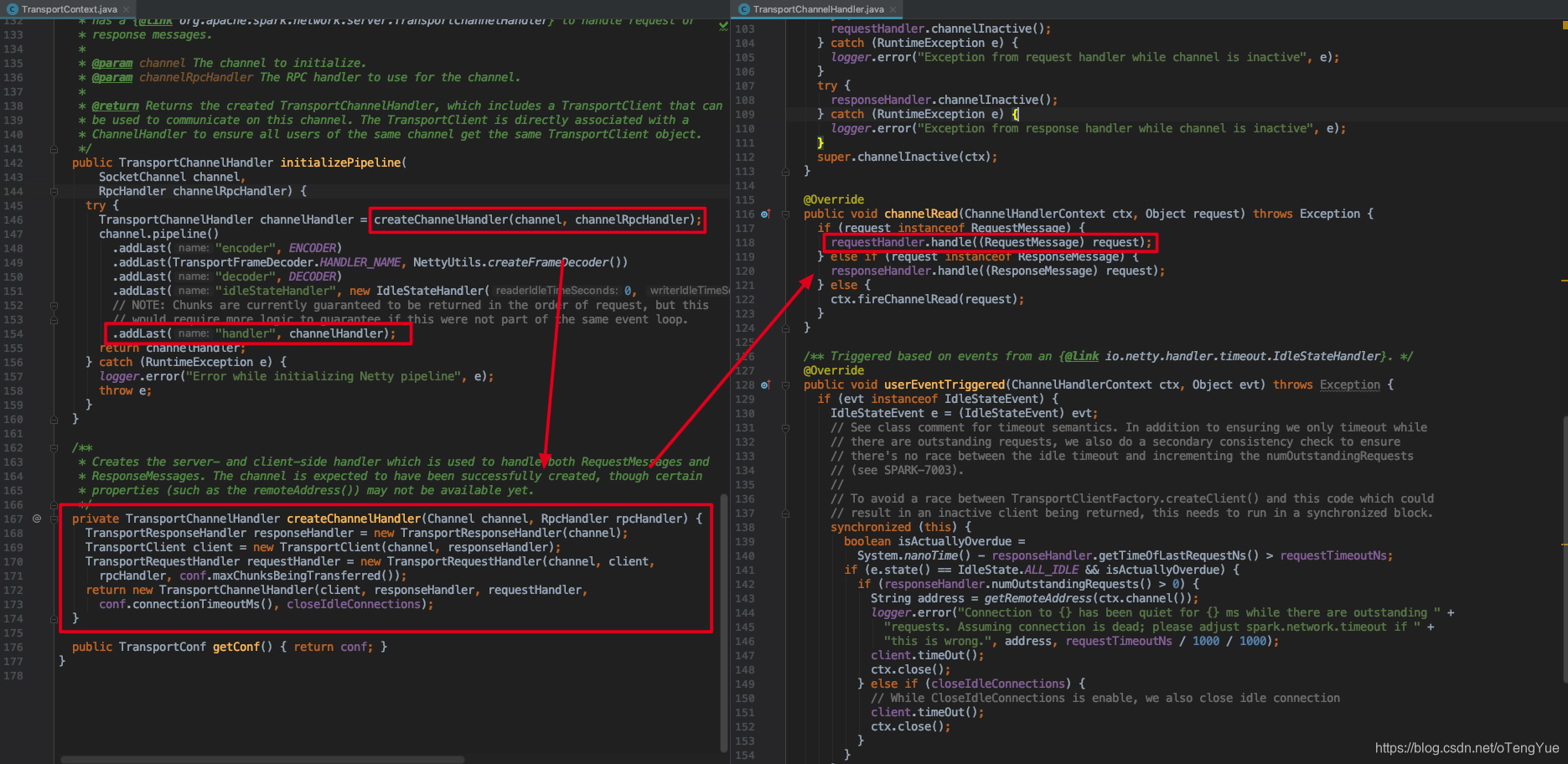
但我们还需要分析Netty服务器启动后,在接受到消息后如何做进行请求消息的处理流转,如下:
接受的消息首先在Pipline中先进行解码等处理,然后进行消息业务处理(即 TransportChannelHandler.channelRead()),根据消息请求类型调用不同的Handler处理,由于本次分析涉及到Request请求,我们继续分析:
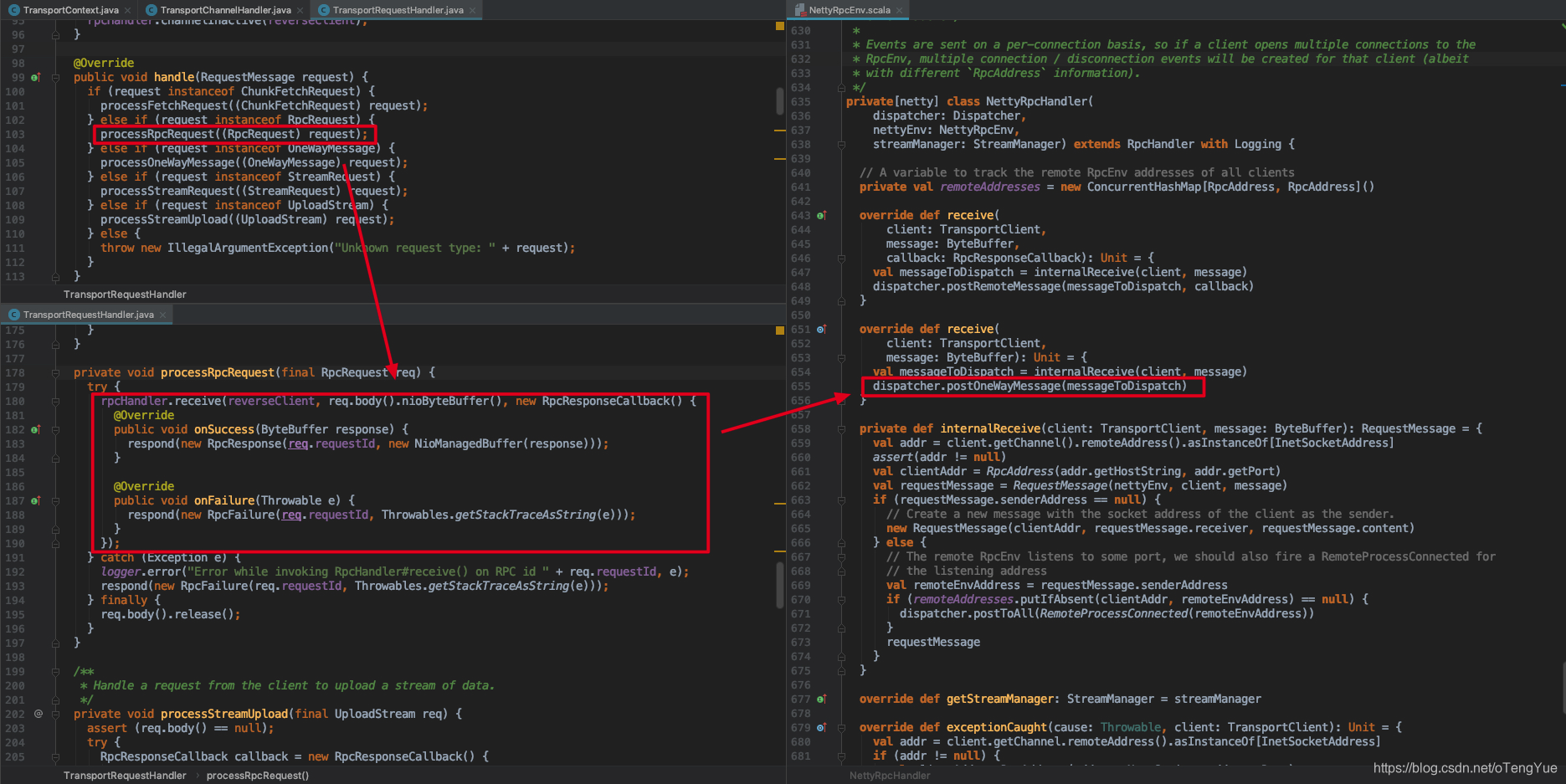
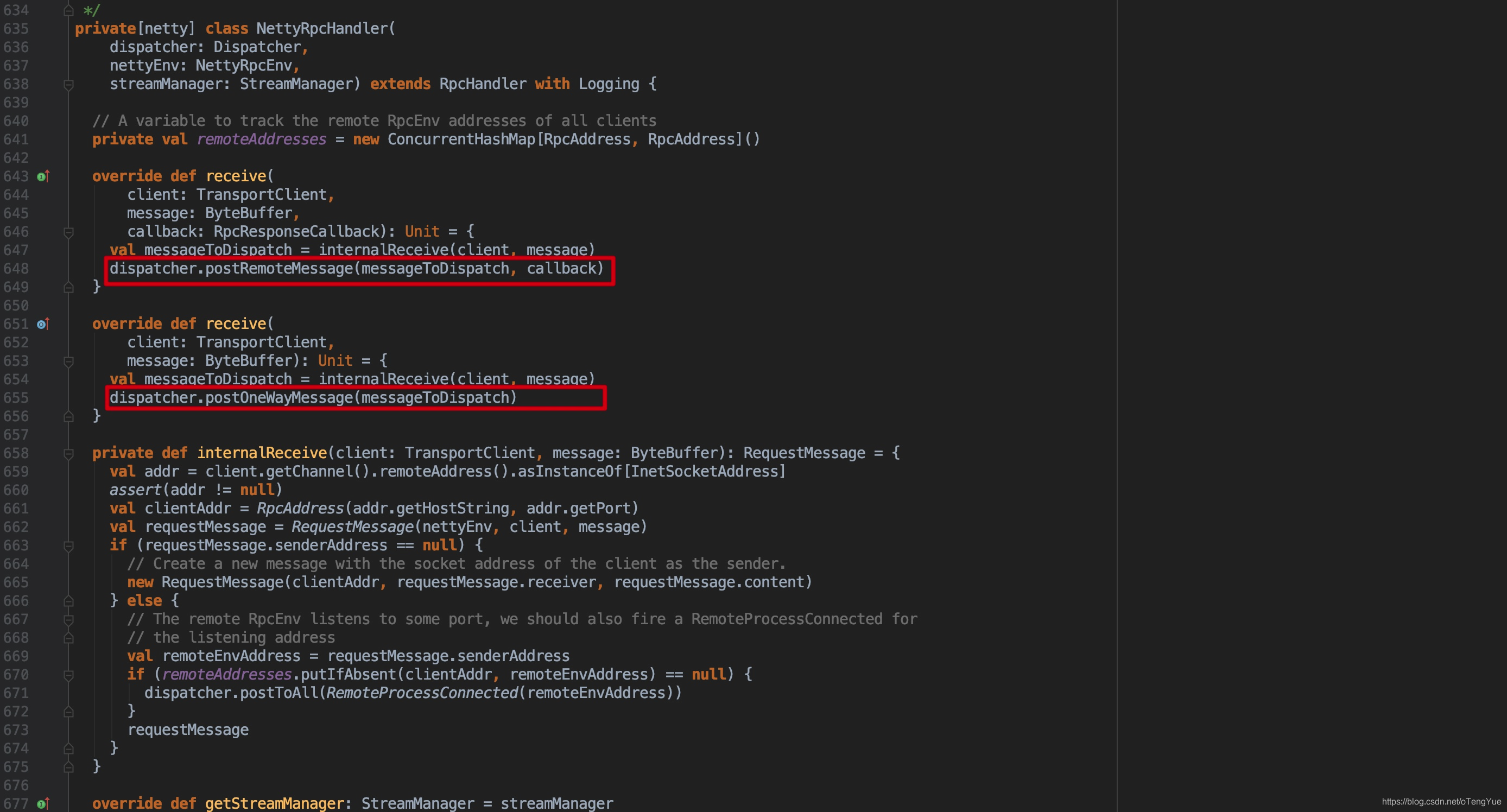
在TransportRequestHandler.handle()中根据消息类型调用不同的处理方法,如果是RpcRequest消息则会调用rpcHandler.receive()处理,由于RpcRequest提供有Response,所以在回调函数中返回Response,由于RpcHandler的实现类是NettyRpcHandler,也即是发送给NettyRpcHandler.receive()函数,从上图可以看出其实现是转发消息给dispatcher进行后续的消息调度分发。
最后我们给出一张Rpc框服务端处理请求、响应流程图:
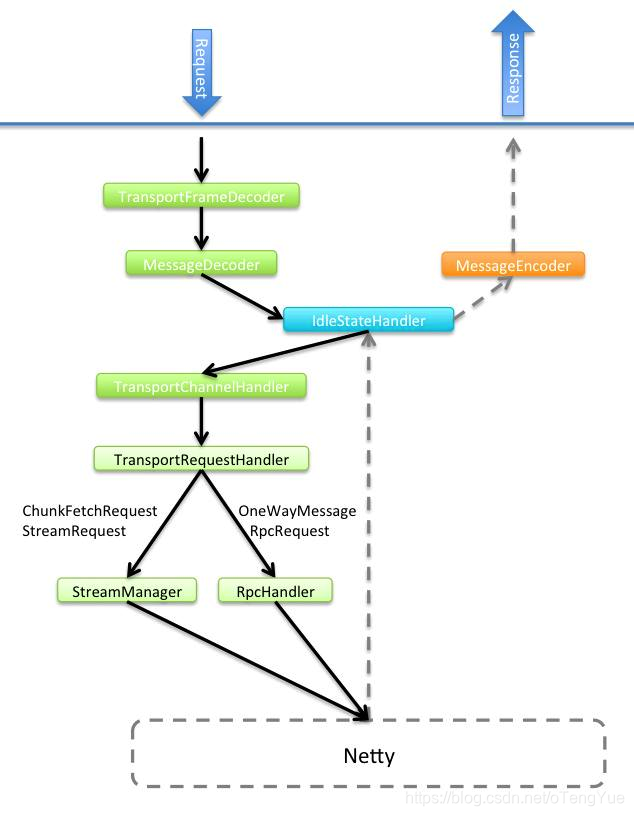
Rpc服务端处理请求流程
如上图介绍服务端通过NettyRpcHandler来提供了Server的服务能力,即NettyRpcHandler接受转发消息给Dispatcher进行消息的调度处理,代码如下:
RpcRequest的请求处理依赖于Dispatcher和Inbox的协调工作,首先看下 Dispatcher 的UML图:
Dispatcher主要职责如下:
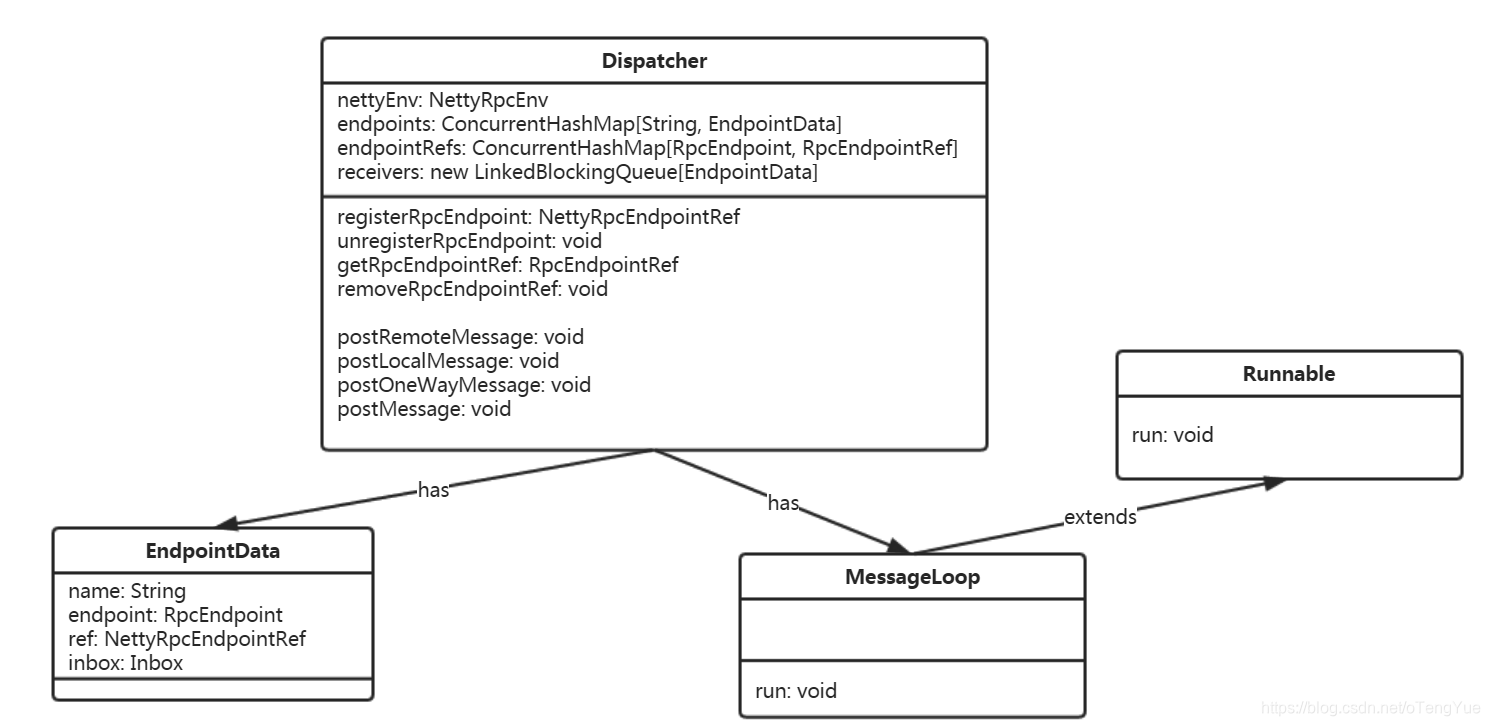
- 内部使用集合endpoints和endpointRefs维护Endpoint、EndpointRef,对外通过registerRpcEndpoint、removeRpcEndpointRef、getRpcEndpointRef等方法提供Endpoint注册删除和获取EndpointRef等服务。
- 利用EndpointData和Inbox结构完成消息的存储。
- 创建线程池threadpool,执行MessageLoop线程,消费消息。
接着看下 Inbox 的类定义:
Inbox的作用:

- 内部了维护了链表messages,用于存储消息,同时维护该消息对应消费者Endpoint,其实现类包含两个:OneWayMessage(单向)和RpcMessage(双向,带回调函数)
- 提供了post和process两个方法,分别用于添加消息到messages和消费消息,process方法在MessageLoop中被调用。
因为最后会根据消息类型做对应的处理,所以有必要先了解一下Inbox的消息类型,其子类包含:
下面看下Dispatcher的消息分发处理过程:
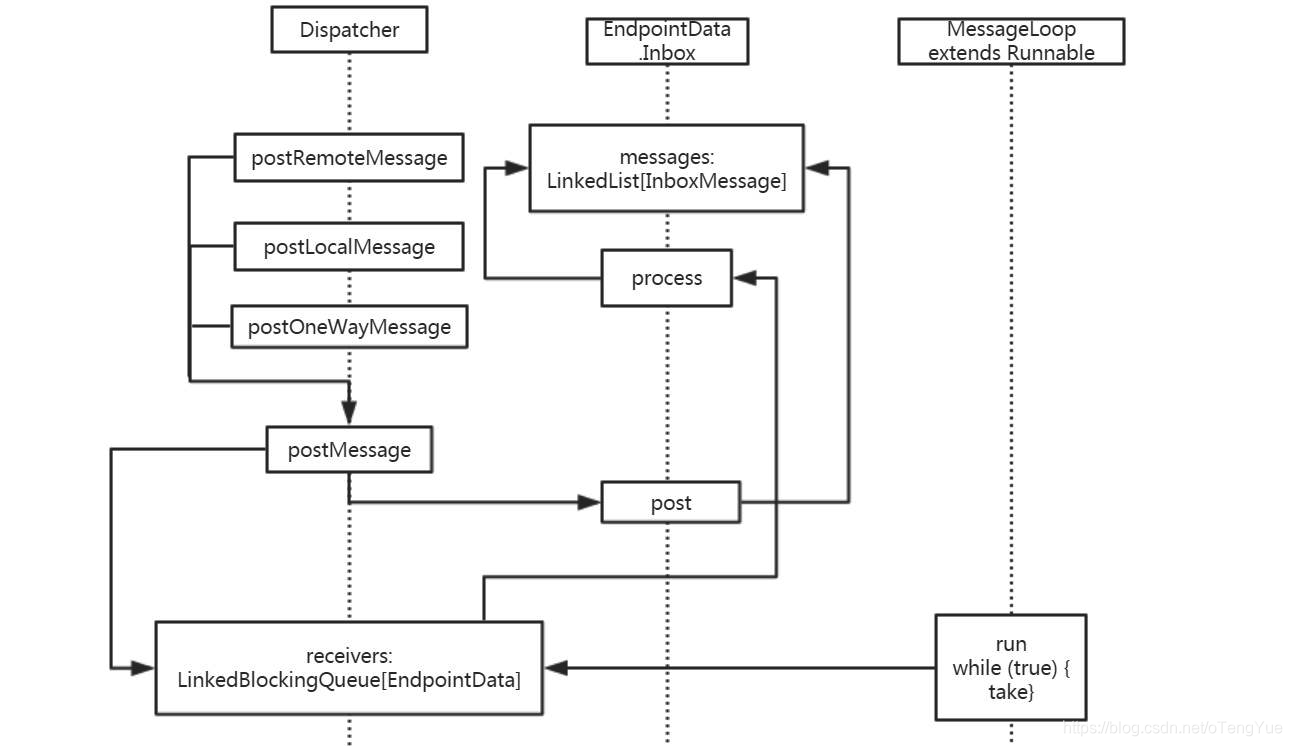
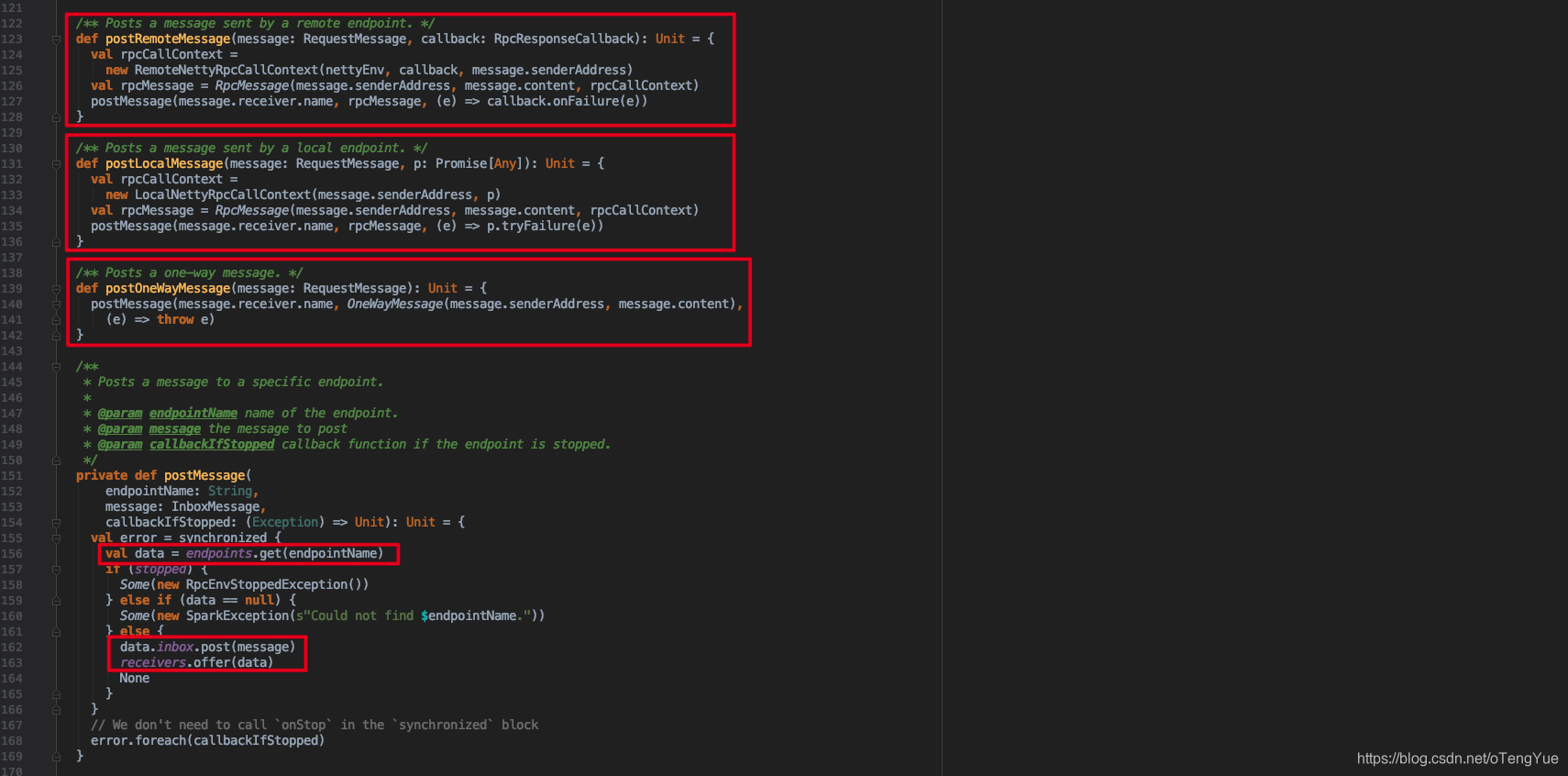
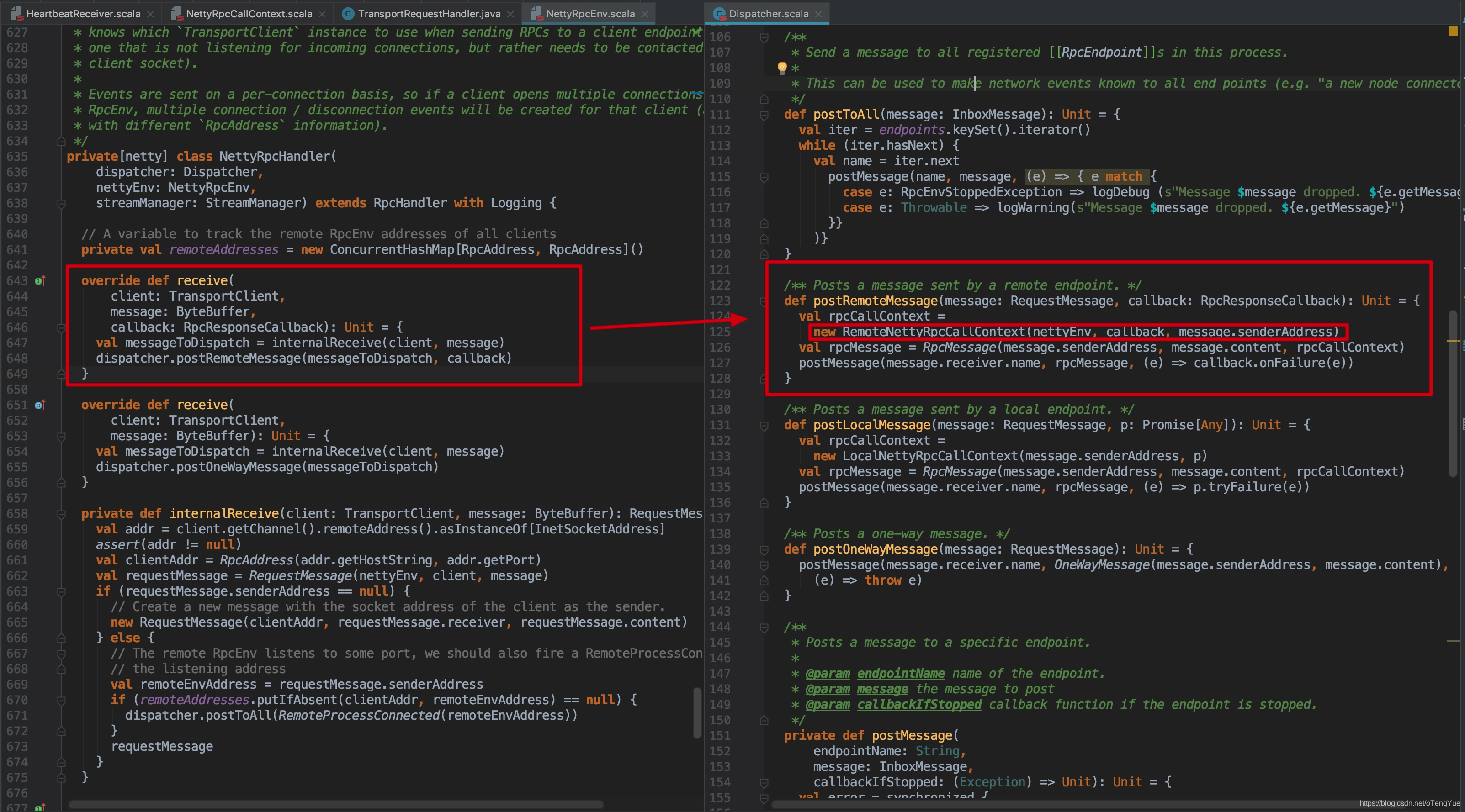
首先Dispatcher通过postRemoteMessage(message: RequestMessage, callback: RpcResponseCallback)、postLocalMessage(message: RequestMessage, p: Promise[Any])和postOneWayMessage(message: RequestMessage)三种方式接受消息后,首先都会封装消息RequestMessage -> RpcMessage,然后调用postMessage(endpointName: String, message: InboxMessage, callbackIfStopped: (Exception) => Unit),首先调用val data = endpoints.get(endpointName)根据endpointName获得已注册的的EndpointData(包含inbox和endpoint,前者用于投递消息,后者在消费端用于调用其业务逻辑代码),然后把EndpointData添加到Dispatcher的receivers,代码如下图:
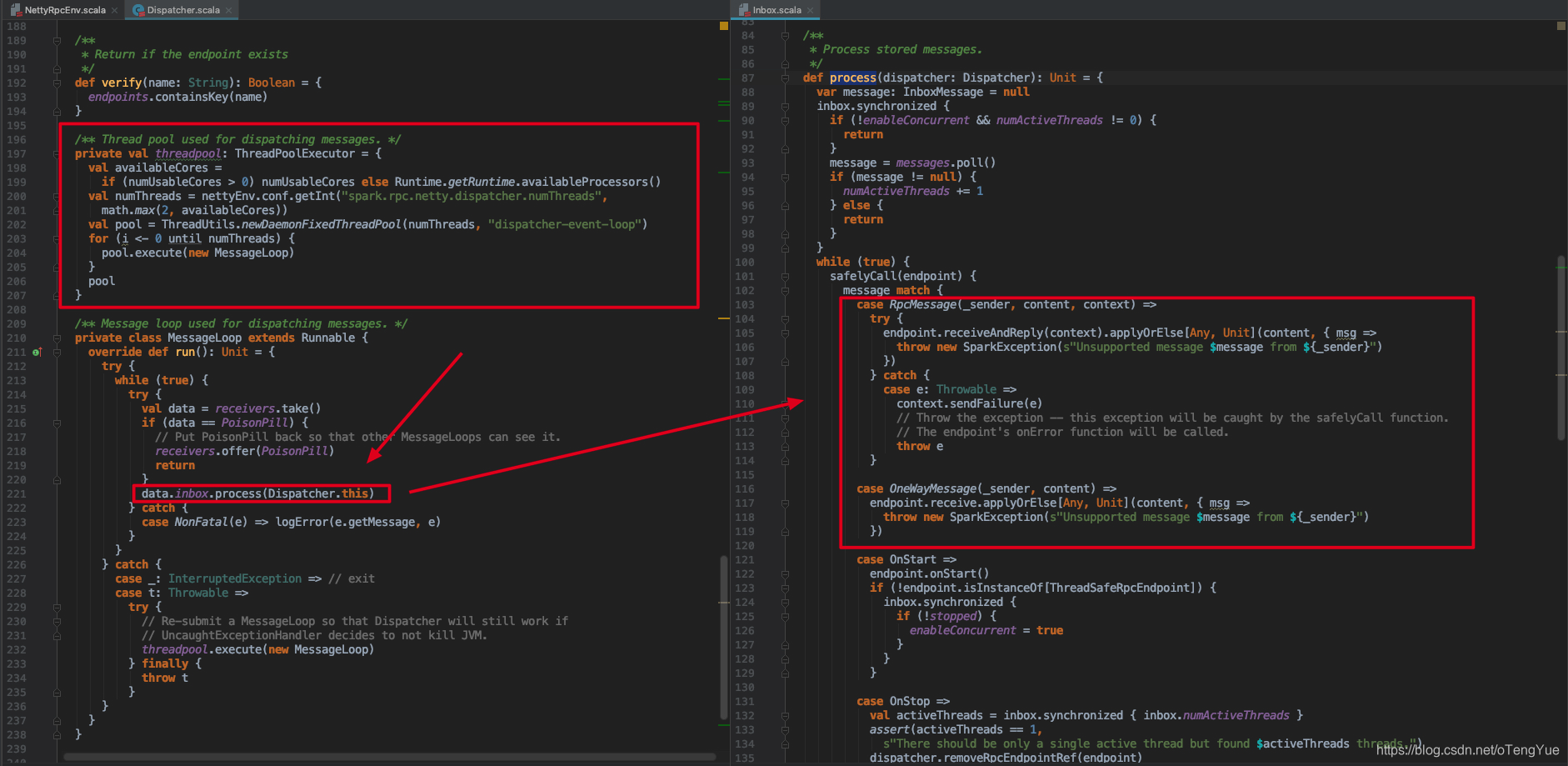
消息添加进来后,那又如何消费消息呢?继续分析Dispatcher,我们会发现在创建Dispatcher时候,会在其内部创建一个threadpool线程池后台循环消费receivers变量,执行函数体在内部类的MessageLoop.run()函数,继续跟踪代码可以发现取出变量中存储的EndpointData并调用其Inbox.process()处理,代码如下:
在上面在Inbox.process()函数中根据消息的类型调用对应的endpoint中的函数进行最终的业务处理。
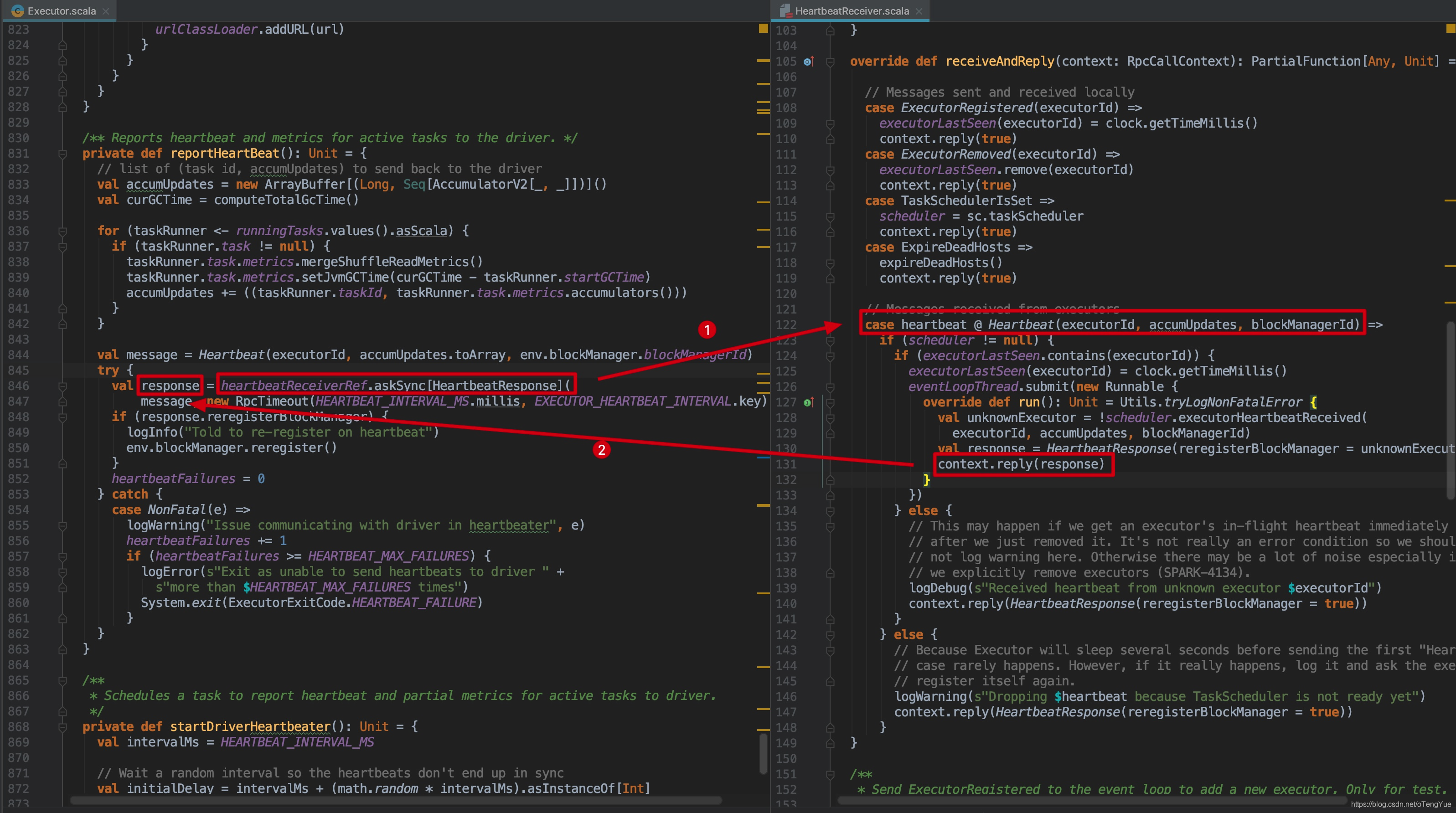
下面我们以心跳交互演示整个过程(主要这部分功能简单,利于分析):
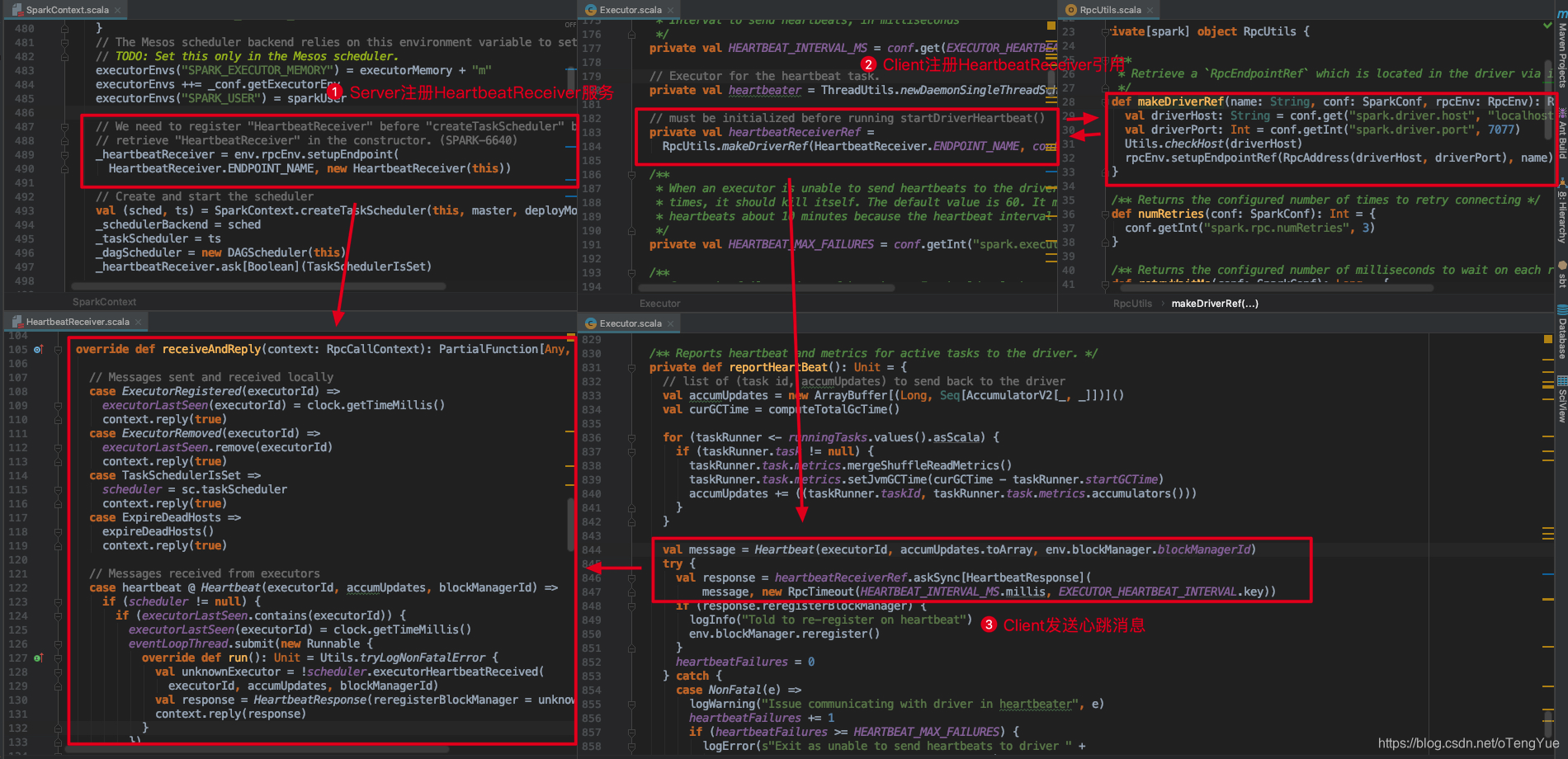
Rpc客户端发送请求流程
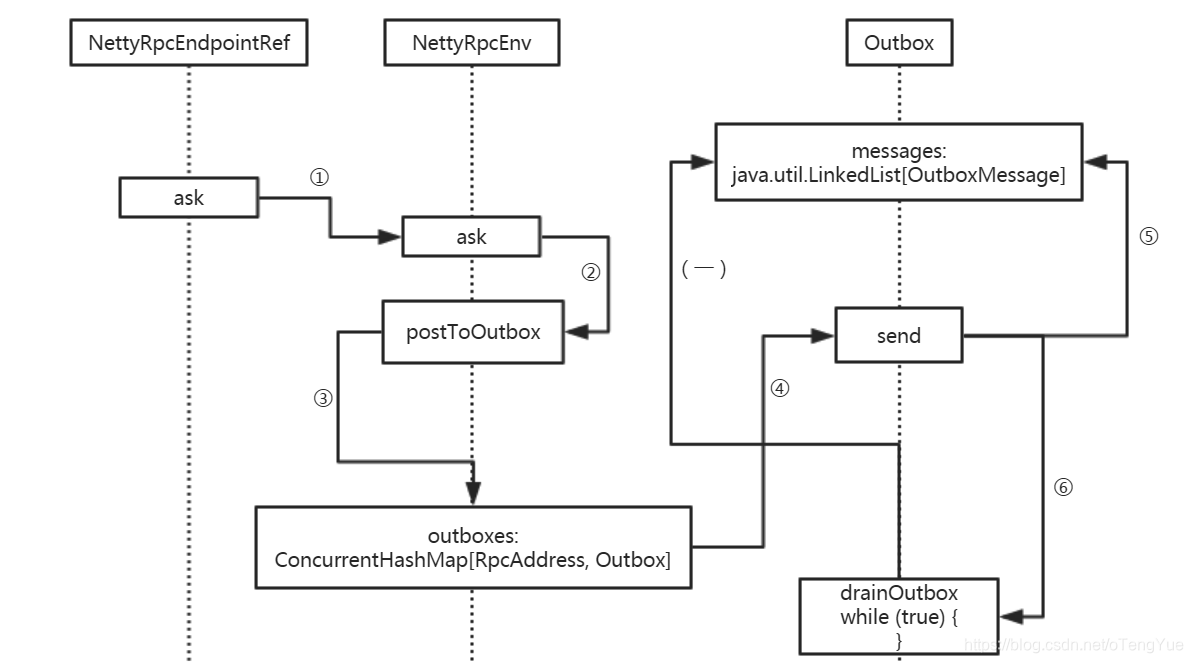
如上图介绍,客户端发送消息用的是持有RpcEndpoint的RpcEndpointRef,最终消息的实际发送是通过 Outbox 发送,RpcEnv的实现类中NettyRpcEnv维护了outboxes变量用于存储不同的Outbox,而Outbox内部除了维护messages用于存储消息外,还存储有client用于与Rpc服务器进行通信。Outbox类结构如下:
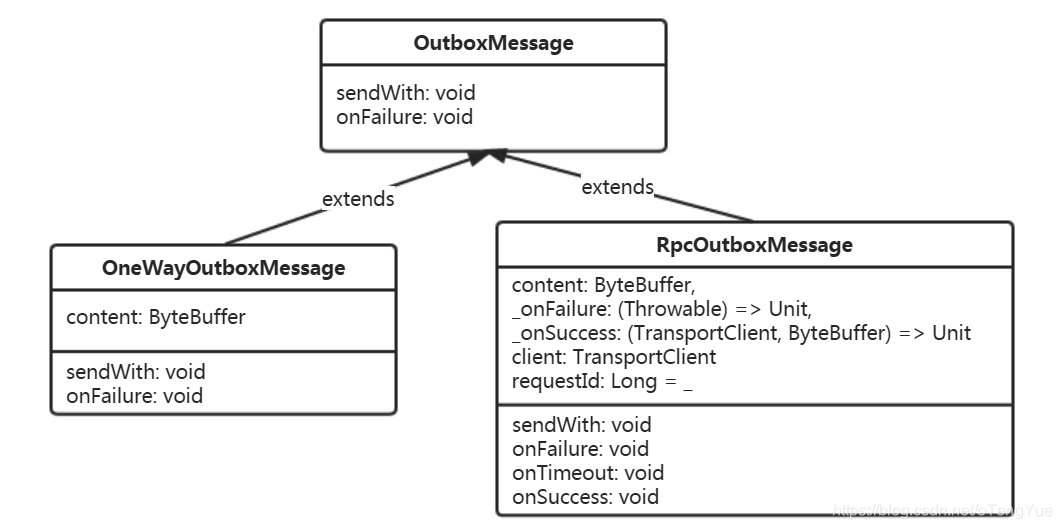
由于消息的发送是通过OutboxMessage的sendWith完成的,所以有必要先了解一下OutboxMessage,Outbox对应的消息类型为OutboxMessage,对应子类有RpcOutboxMessage(有返回值)和OneWayOutboxMessage(无返回值),其类图如下:
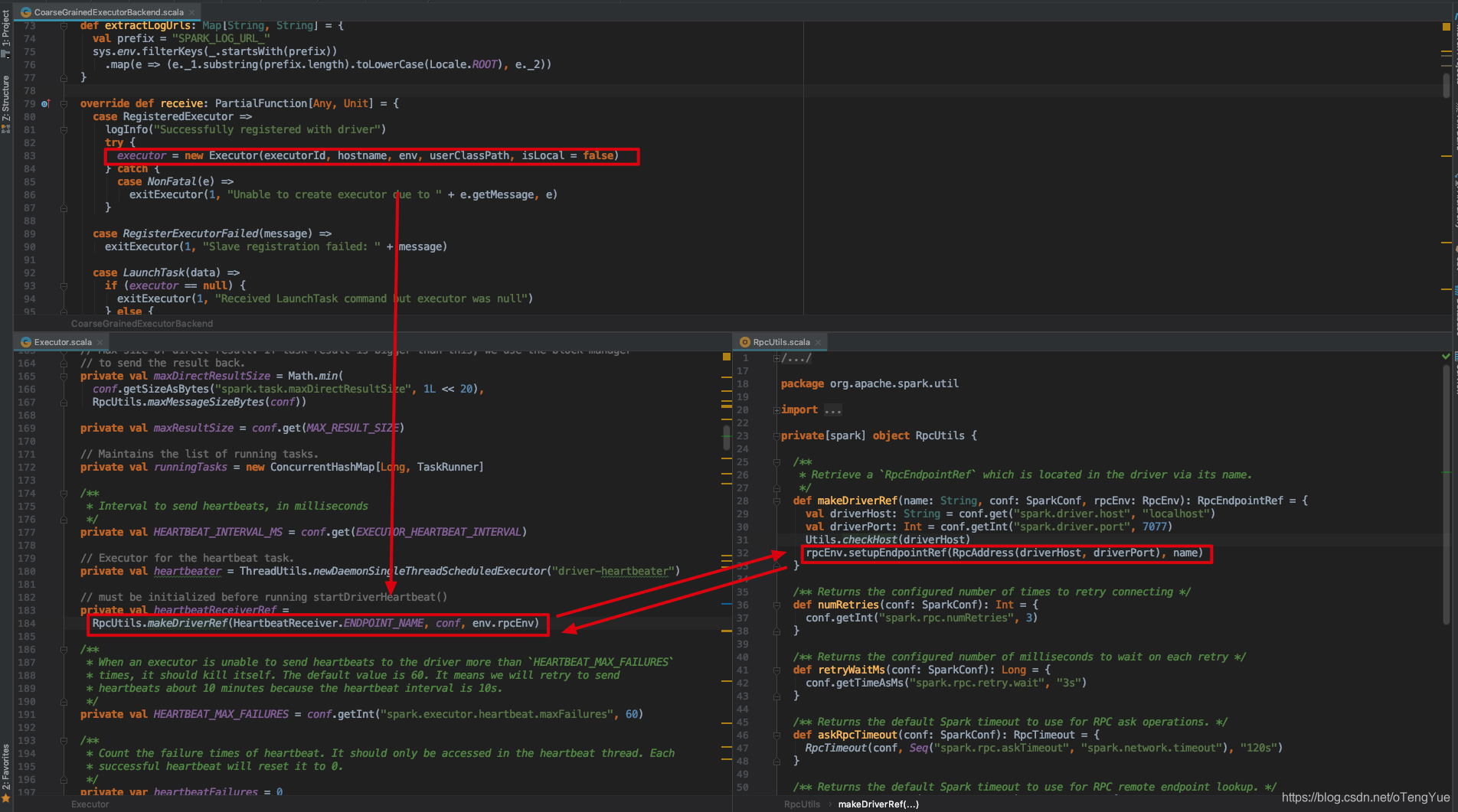
我们依然以上节中的心跳交互为例,首先需要明确无论是注册Endpoint还是注册EndpointRef都需要先初始化RpcEnv,经分析发现客户端发送心跳消息用的RpcEnv初始化是在CoarseGrainedExecutorBackend.run()函数中,其初始化过程上文已介绍,为了便于介绍再次给出截图:
初始化RpcEnv后就可以使用注册EndpointRef了,代码分析如下(在进入以下代码前会经过executor向driver发送【RegisterExecutor】消息,然后driver向executor发送【RegisteredExecutor】消息,由于此部分的交互不是我们的重点,我们直接跳过进入心跳过程):
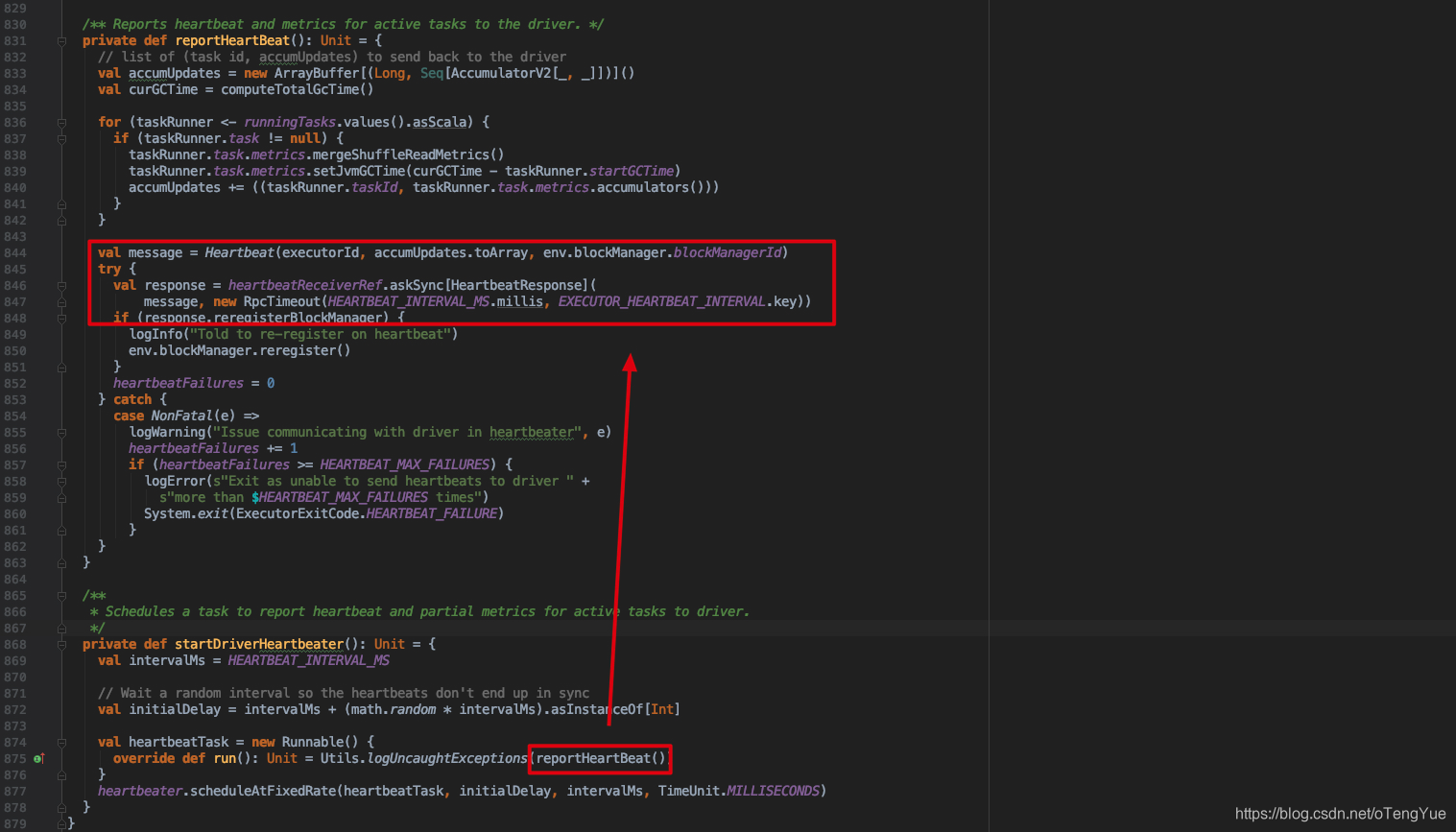
注册完成后即可获得heartbeatReceiverRef,然后在 Executor 中开辟一个线程定时向Driver发送心跳。如下图:
到这,我们终于进入我们的主题 heartbeatReceiverRef.askSync[HeartbeatResponse](),下面我们重点分析发送请求流程:
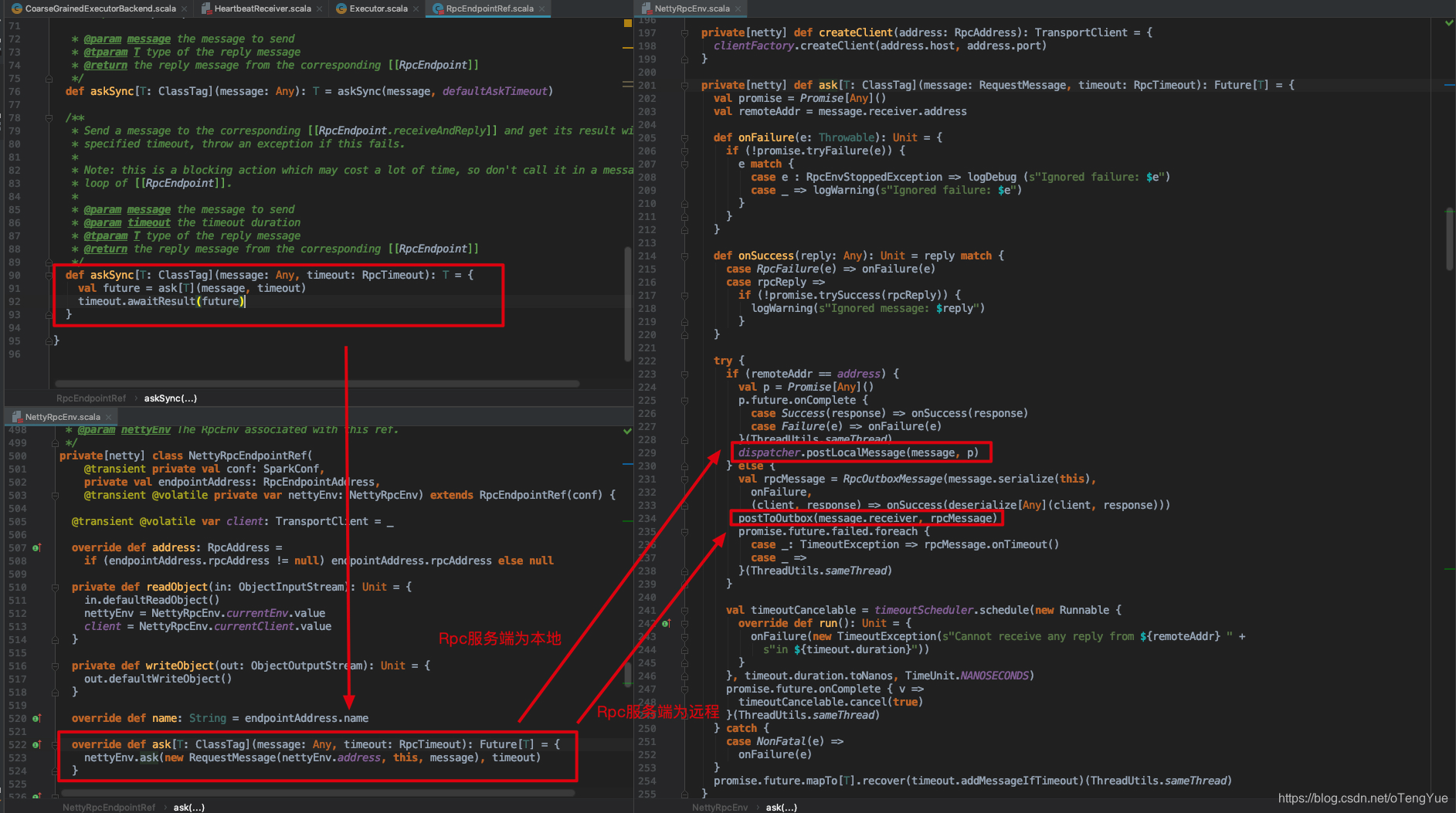
下面代码分析如下:
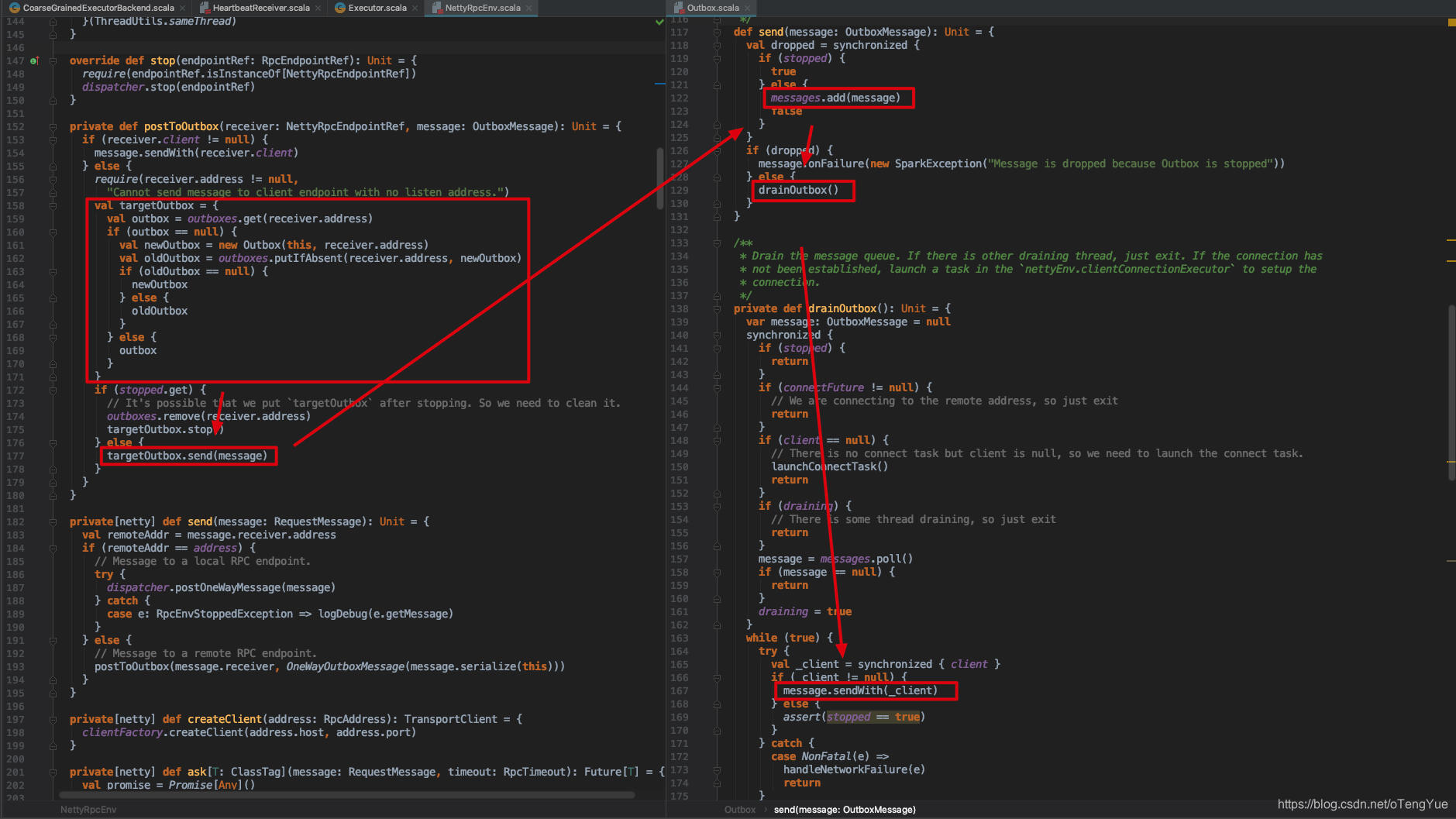
如上图,如果消息的远程服务器地址和本地服务器一样,就直接发送给本机Dispatcher进行消息的响应处理(继续分析见上节);否则把参数封装为RpcOutboxMessage,调用postToOutbox()函数,我们继续分析
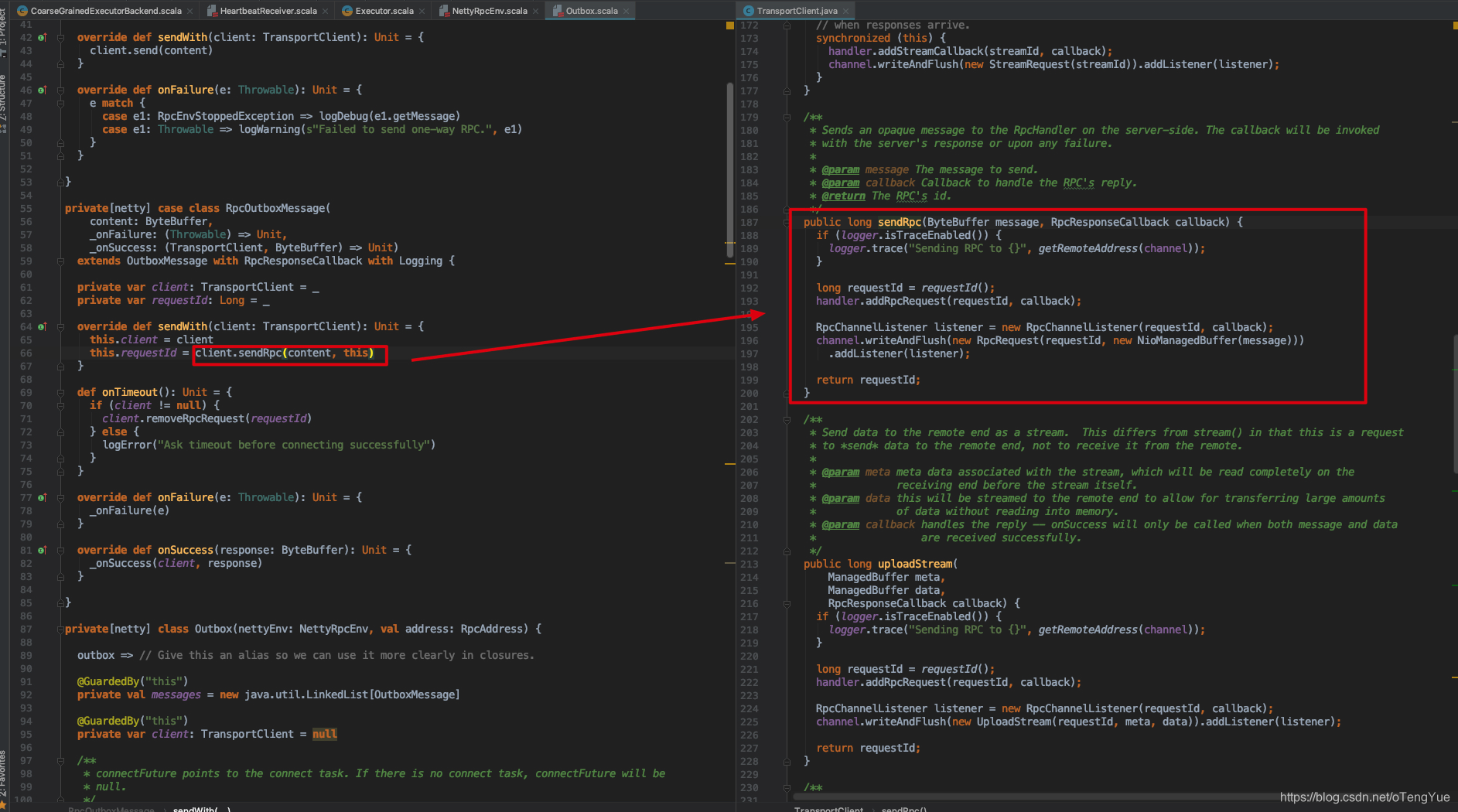
OutBox并没有启动单独线程进行发送而是在drainOutbox()函数中调用message.sendWith(_client)方法发送消息,由于前面把心跳消息封装为RpcOutboxMessage类型了,所以继续调用RpcOutboxMessage.sendWith()函数继续发送消息,最后消息再通过TransportClient.sendRpc()函数调用Netty客户端向远程服务器发送,代码如下:
至此,Rpc客户端发送请求流程也分析完成了,但我们的分析过程并没有结束,因为还有一个问题就是Netty客户端是如何初始化的呢?我们继续分析,Netty客户端的初始化即是TransportClient的初始化,我们同样给出类图(上文已给出过此图,但此处分析Client端的封装,如虚线框住部分):

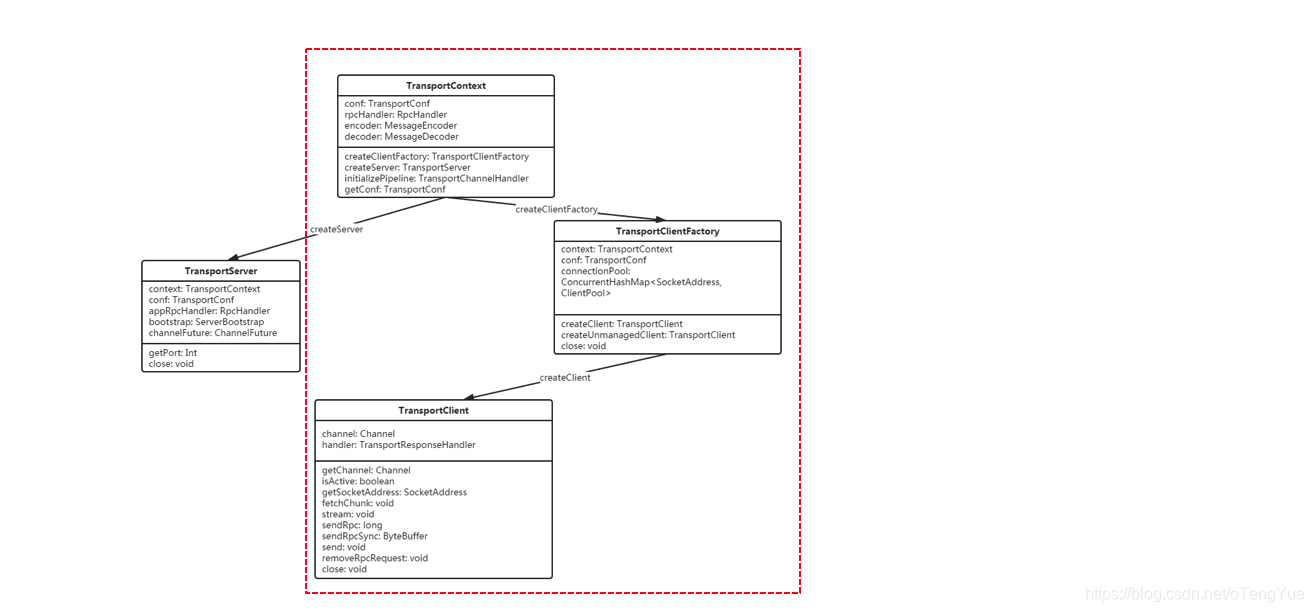
- TransportContext维护Transport的上下文环境,主要用来创建TransportServer和TransportClientFactory。
- TransportClientFactory用来创建TransportClient。
- TransportClient和对应的TransportServer通信。
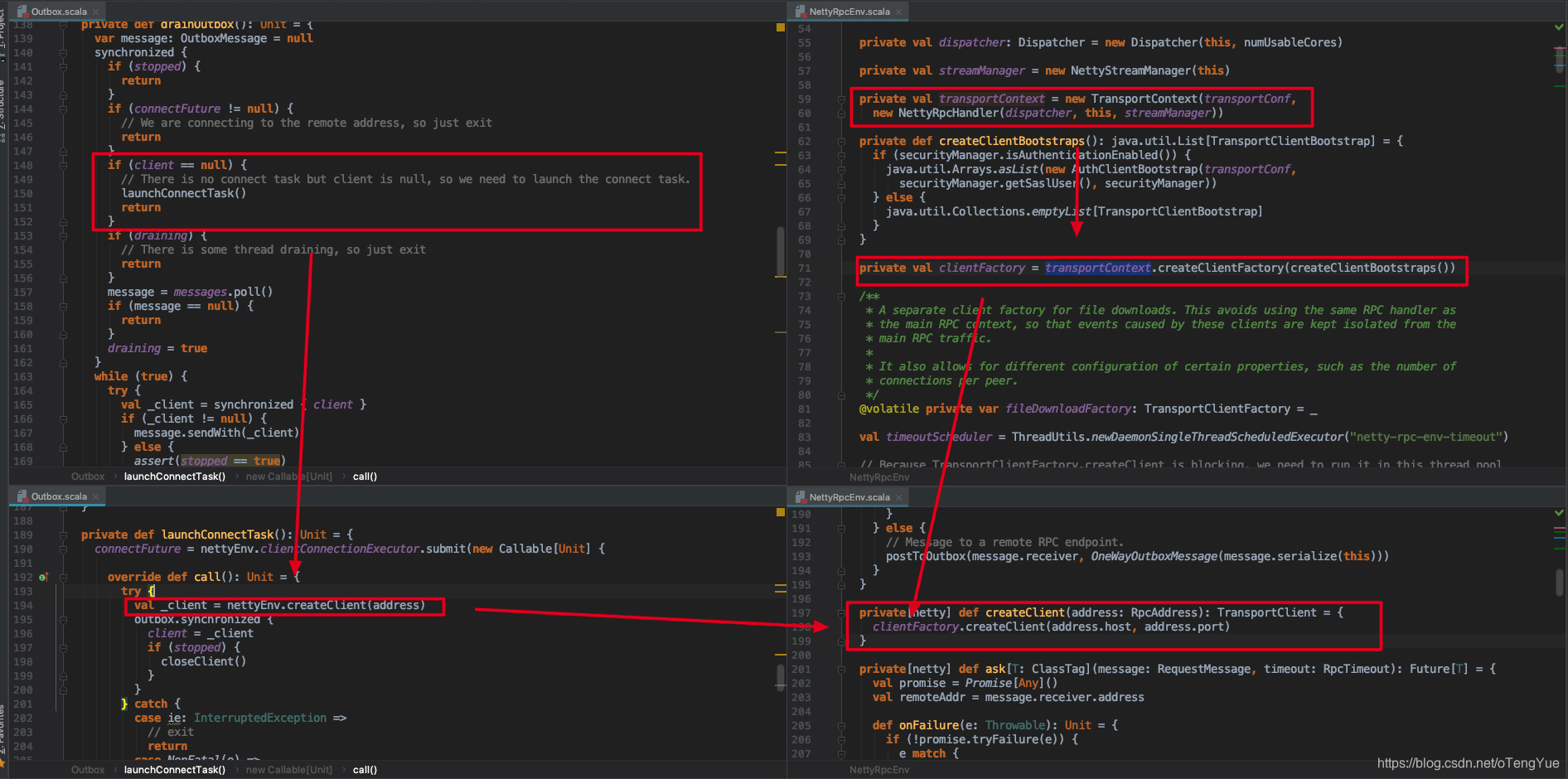
由前面的分析我们知道TransportContext初始化是在RpcEnv创建中完成的,那么我们直接看TransportClientFactory和TransportClient如何完成的初始化的,通过上面分析可知Client发送消息中间有一环节会调用Outbox.drainOutbox(),代码如下图:
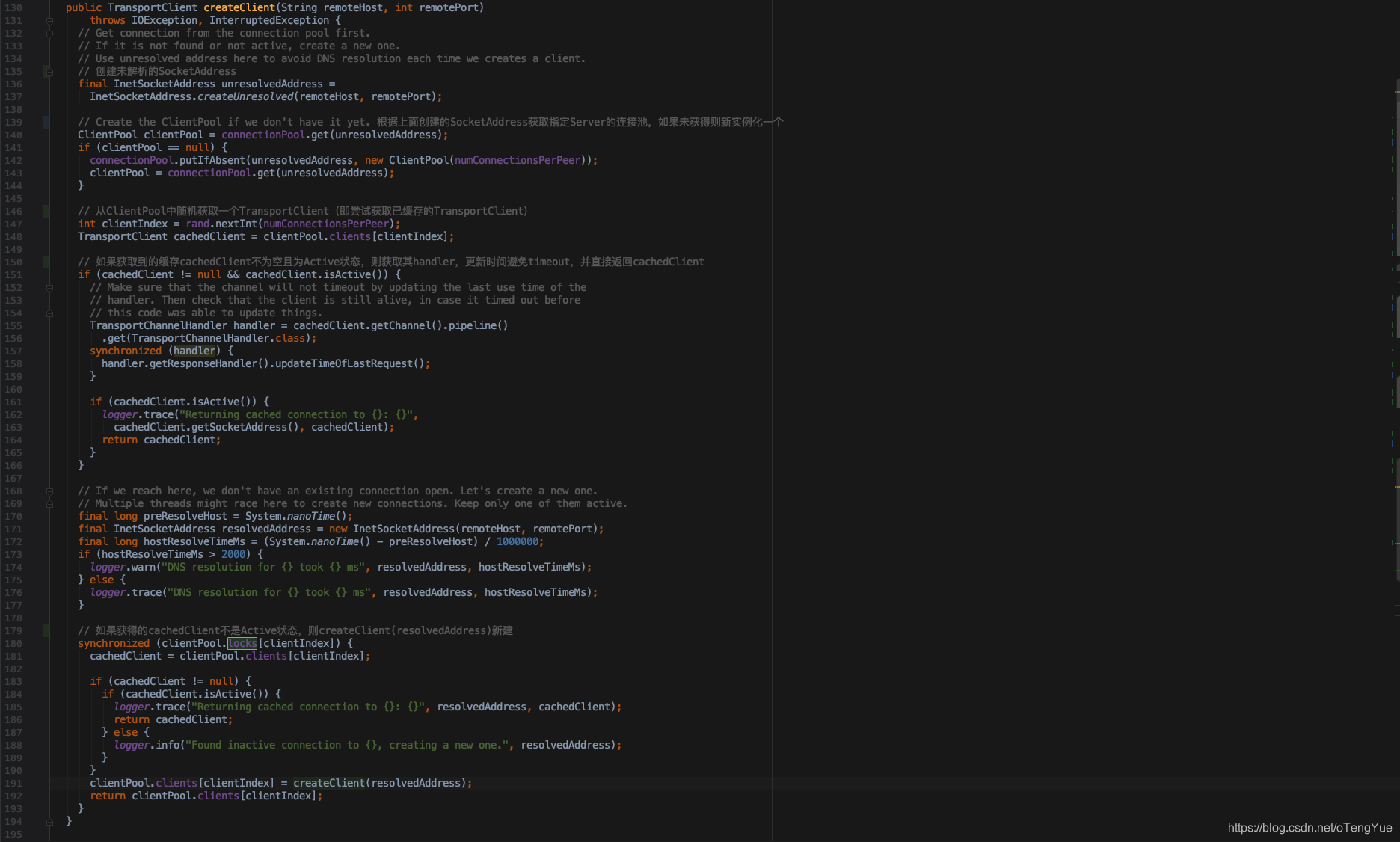
如上图NettyRpcEnv创建时候会初始化transportContext和clientFactory变量,之后在Outbox.drainOutbox()函数首先判断TransportClient类型的client变量是否为null,如果为null则调用Outbox.launchConnectTask() -> NettyRpcEnv.createClient() -> TransportClientFactory.createClient()新创建,下面我们重点分析TransportClientFactory.createClient(remoteHost, remotePort)函数。我们首先了解一下TransportClientFactory类,其内部会创建多个连接池(this.connectionPool = ConcurrentHashMap<SocketAddress, ClientPool>()),每个远程地址都对应一个连接池(ClientPool),ClientPool是TransportClientFactory的内部类,内部实现是创建数组存储TransportClient,每次连接时候随机去除一个空闲的用于和TransportServer交互(其实质就是连接池的作用),TransportClient类定义如下:
下面我们分析TransportClientFactory.createClient(remoteHost, remotePort)函数的实现,分析见代码注释:
我们继续分析TransportClientFactory.createClient(address)如下:
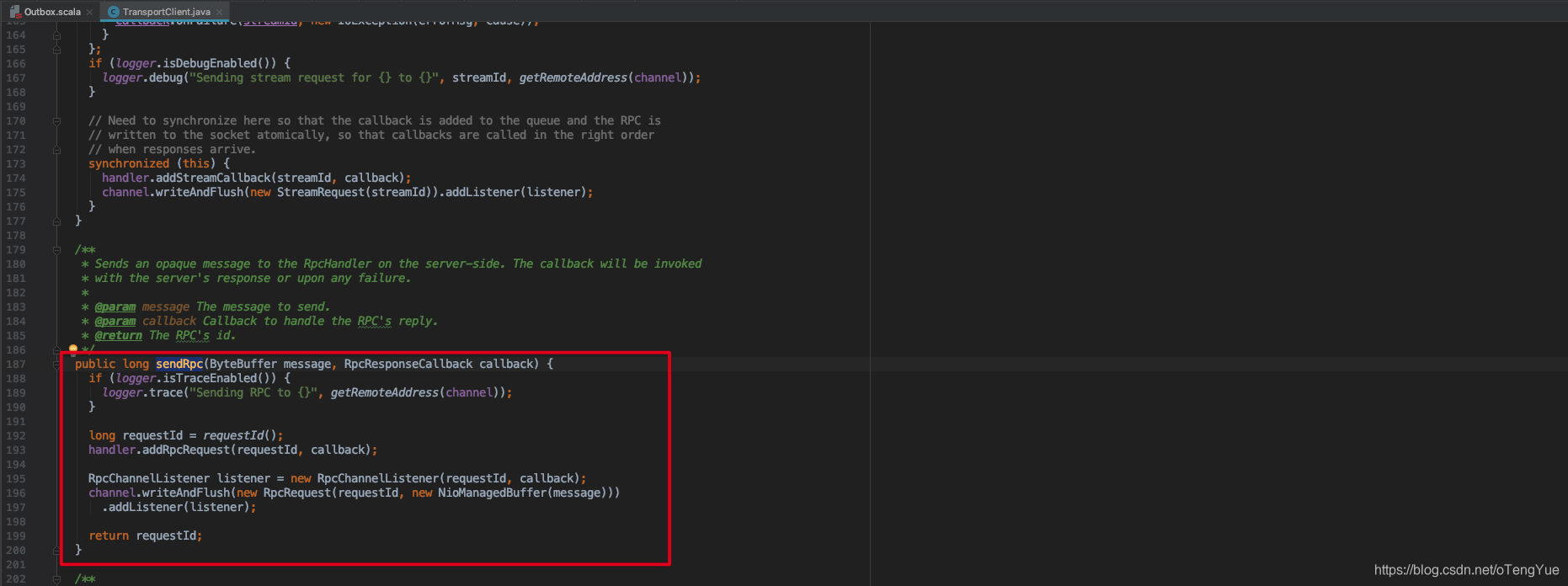
从上图可以看出实现了Netty客户端初始化,设置Pipline管道中,把SocketChannel传递给新建TransportClient实例,并把TransportClient实例返回即完成了TransportClient的初始化工作,这样向TransportServer发送消息即是在TransportClient实例中向SocketChannel发送消息。从我们上节的分析可以看出发送Rpc消息即是调用TransportClient.sendRpc()函数,代码如下:
最后再给出一个客户端请求、响应流程图:

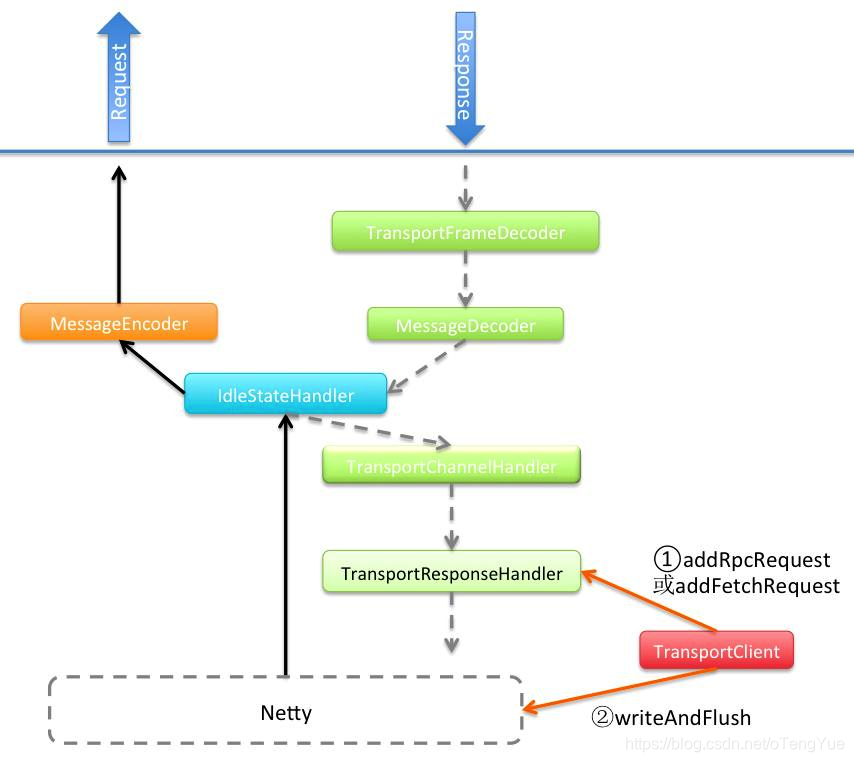
Rpc请求回调处理流程
如果客户端使用RpcEndpointRef.send()函数发送消息则是单向请求;如果使用RpcEndpointRef.ask()函数发送消息则是双向请求,此时需要用回调函数把服务端的结果返回给调用方。还拿心跳交互进行举例,首先我们跳过中间环节直接看Client和Server的处理过程:
可以看出客户端传入Heartbeat消息,返回HeartbeatResponse类型的返回值。我们看下RpcEndpointRef.ask函数的定义,参数解释见注释:
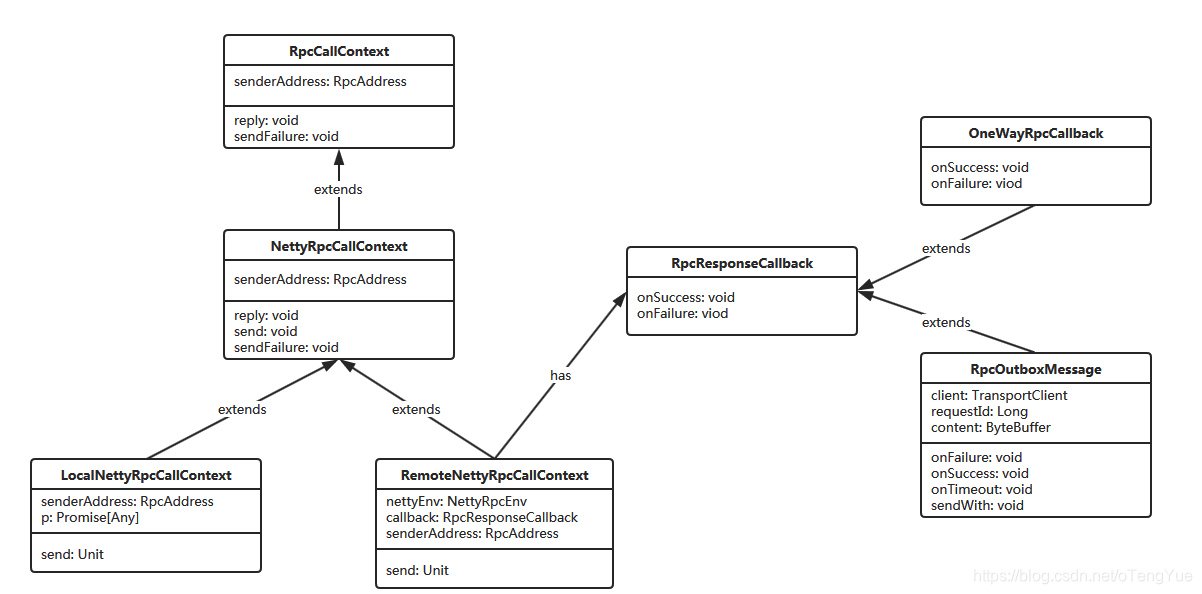
在分析源码之前,我们先看回调函数涉及的类:
其中,Client端是由RpcResponseCallback在负责异步提取结果;Server的回调过程是由RpcCallContext和RpcResponseCallback共同完成。
由于前面章节我们已经逐步分析了整个发送请求的过程,这次我们重点在分析回调过程,因此只分析关键环节:
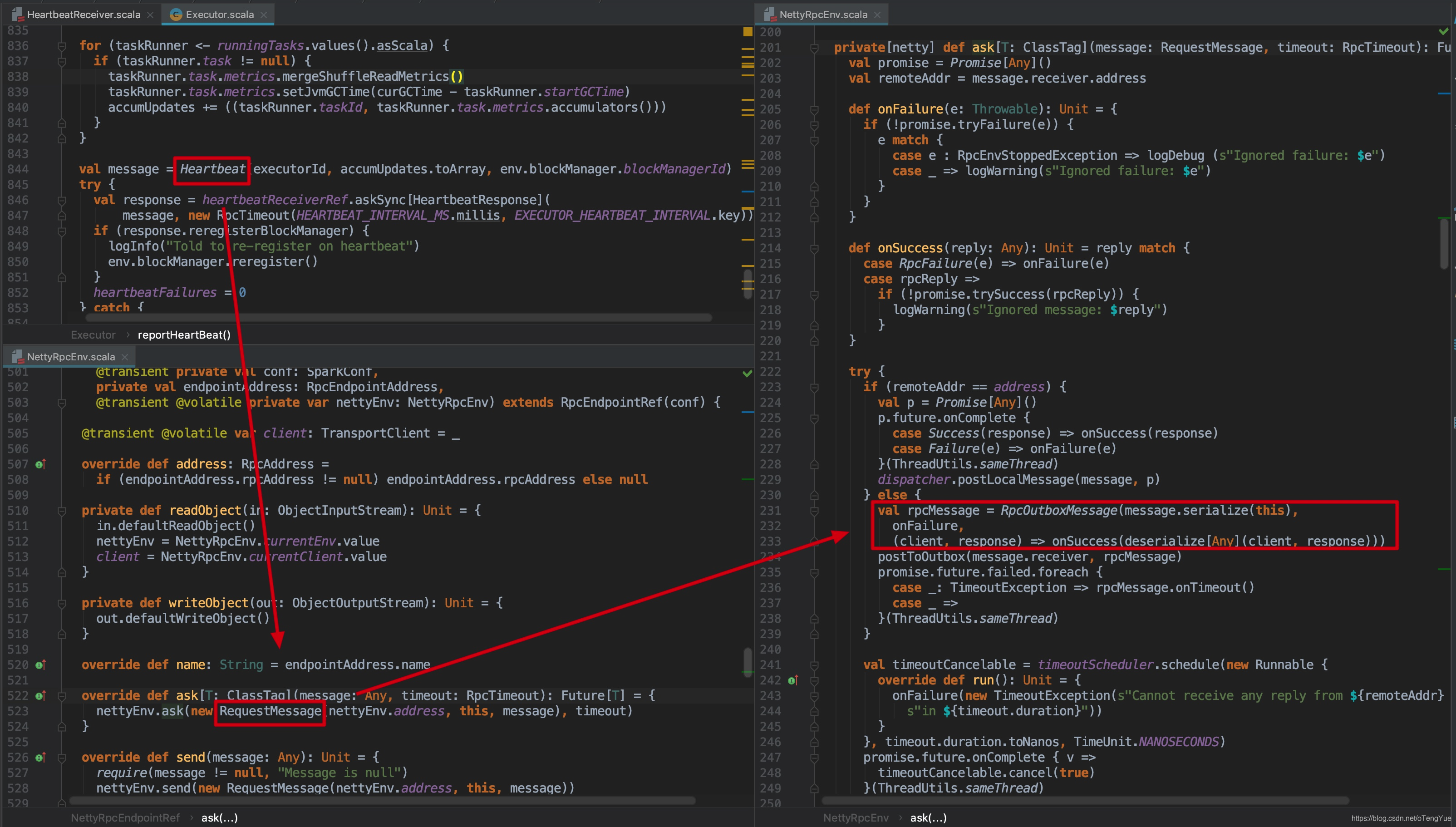
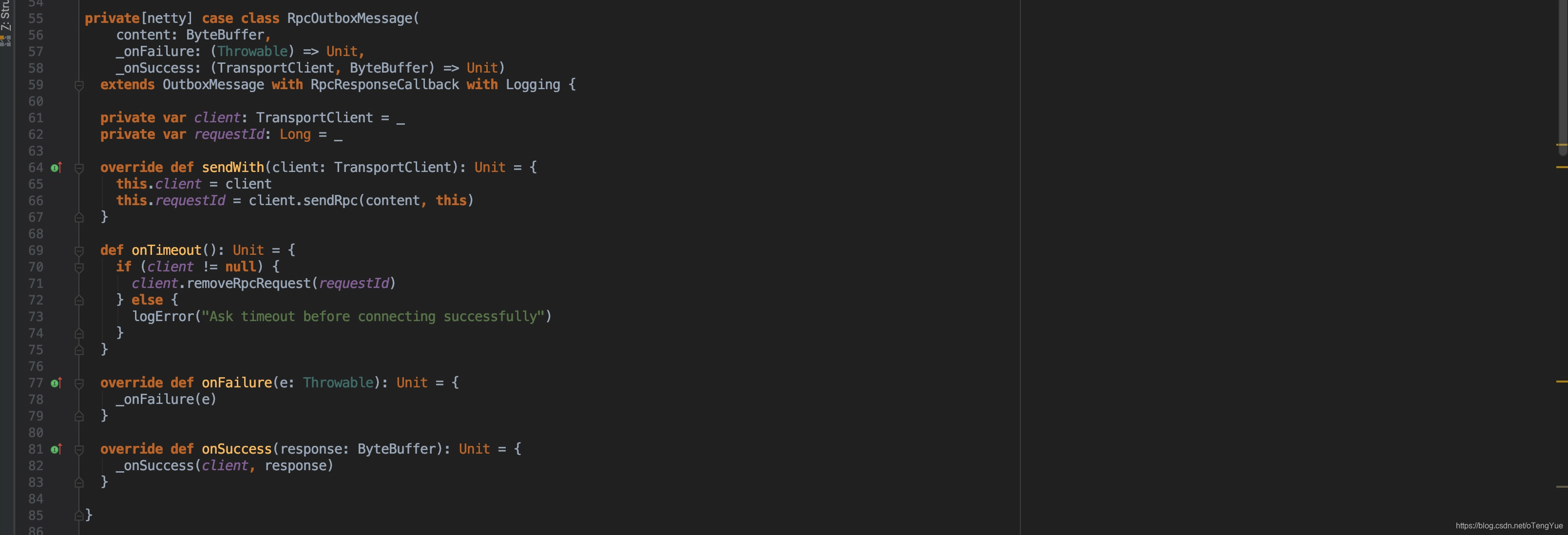
由上图我们可以看到,在NettyRpcEndpointRef.ask()函数中,首先把任意类型(Any)的消息封装为RequestMessage,然后进入NettyRpcEnv.ask()函数,此函数是重点,首先判断如果是调用本地服务(即client和server在同一台机器上),则使用scala.concurrent.Promise机制先定义两个Promise变量promise和p,在消息处理端完成对变量p的赋值后在p.future.onComplete回调函数对变量promise赋值,最后对promise值做函数的最终返回,这里比较简单不再深入分析;如果是远程调用,原理相同,对promise变量的处理相同,对消息处理端的返回采用了自定义回调机制,把RequestMessage封装为RpcOutboxMessage,在RpcOutboxMessage中主要工作是添加自定义回调函数,在后续调用返回后,在回调函数中完成对promise的赋值,最后对promise值做函数的最终返回。下面我们分析如何实现自定义回调的,我们先看下封装成的RpcOutboxMessage的类定义:
可以看出,可以关注下onSuccess()和onFailure()回调函数,并未做特殊处理,只是继续封装便于后续调用,发送消息会调用sendWith()函数(调用到sendWith函数的细节见上面章节分析),我们继续分析:
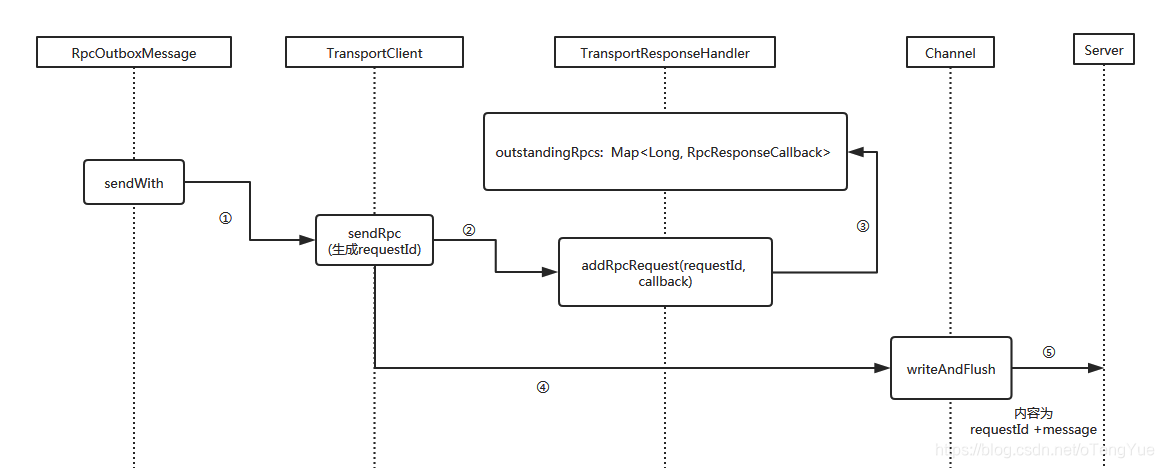
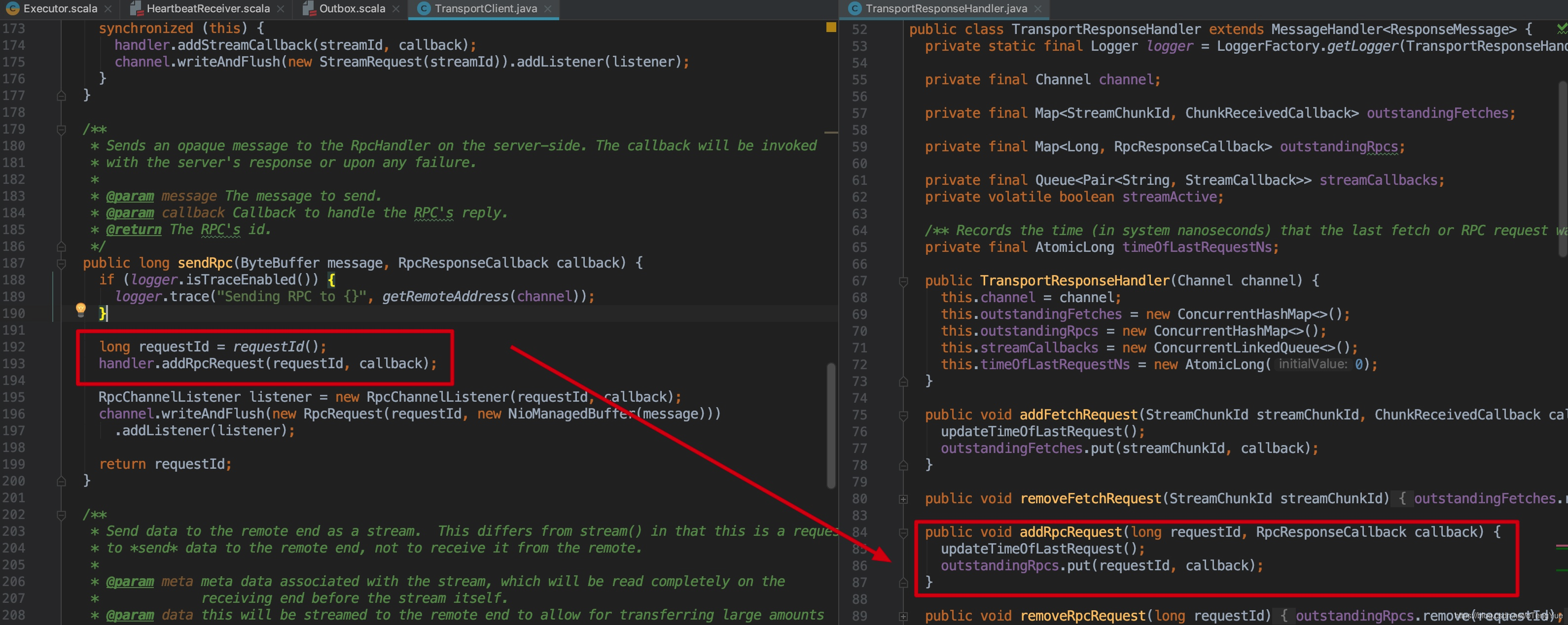
在TransportClient.sendRpc()函数中生成requestId,同时将(requestId, callback)信息添加到TransportResponseHandler的outstandingRpcs中,后续Client会根据这个requestId处理Server返回的信息,然后调用Netty的channel.writeAndFlush()方法发送给远程Server,RpcRequest内容为(requestId + message)。代码如下:
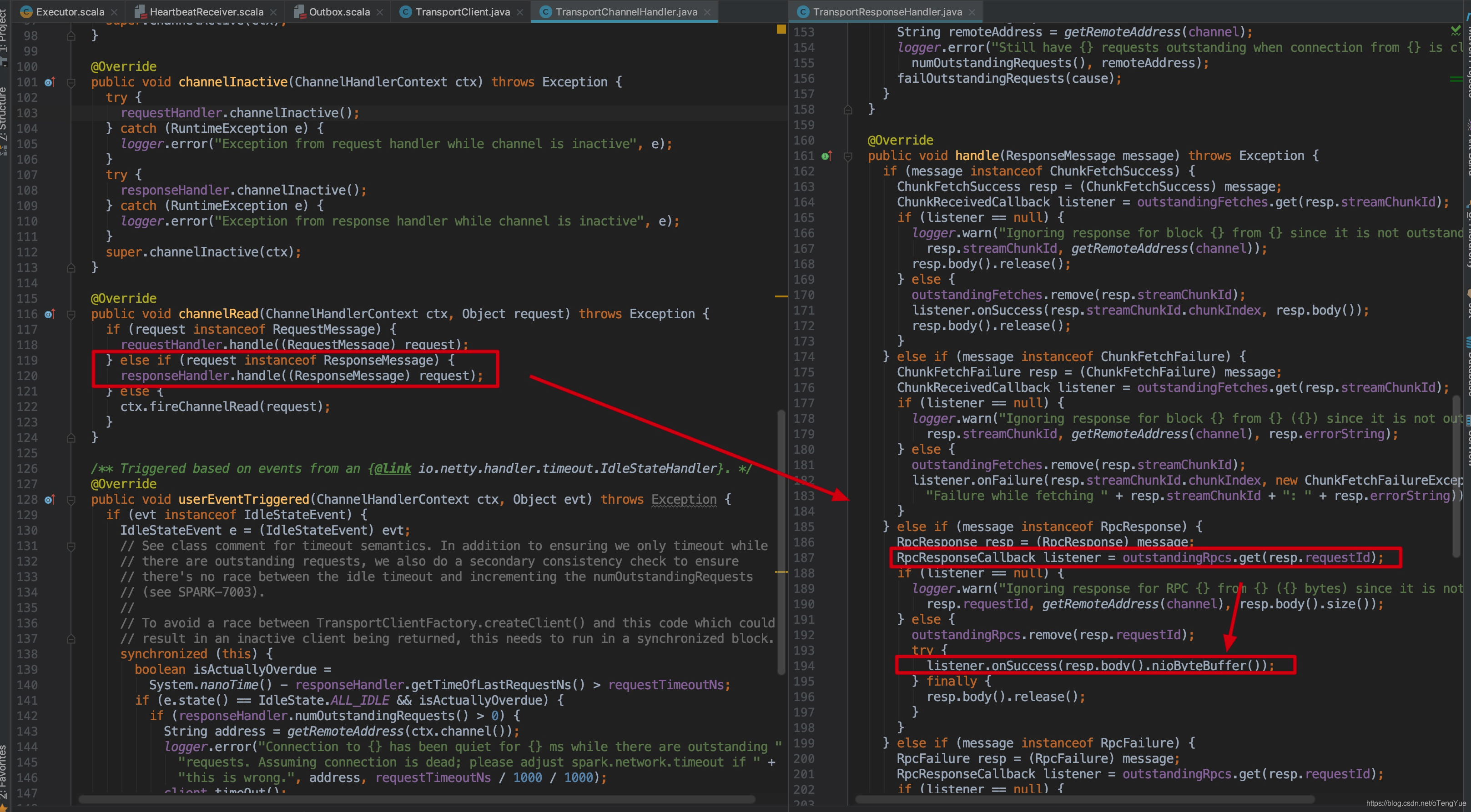
Server处理RpcRequest,会返回带requestId的RpcResponse。为了分析的连贯性,我们先跳过服务端的处理,后面再分析,直接看Client如何处理带requestId的RpcResponse,从上面章节分析可知,Client在创建TransportClient对象时,也会将TransportChannelHandler注册到底层的Netty的Pipeline中,因此返回的消息在TransportChannelHandler判断如果是ResponseMessage,则会把请求转给TransportResponseHandler进行处理。代码如下:
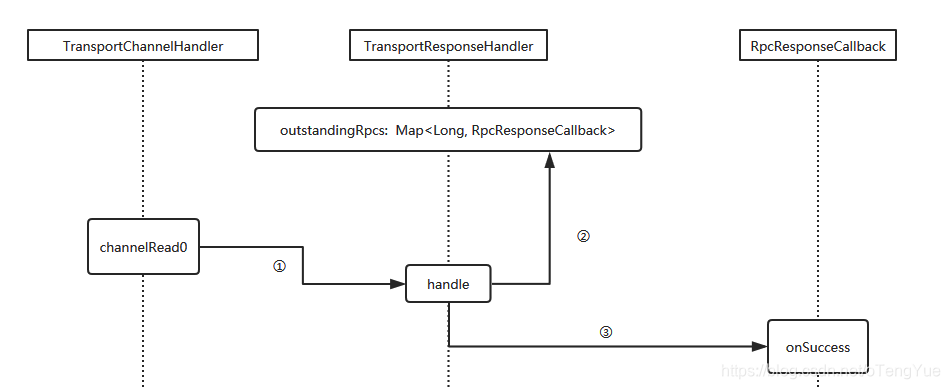
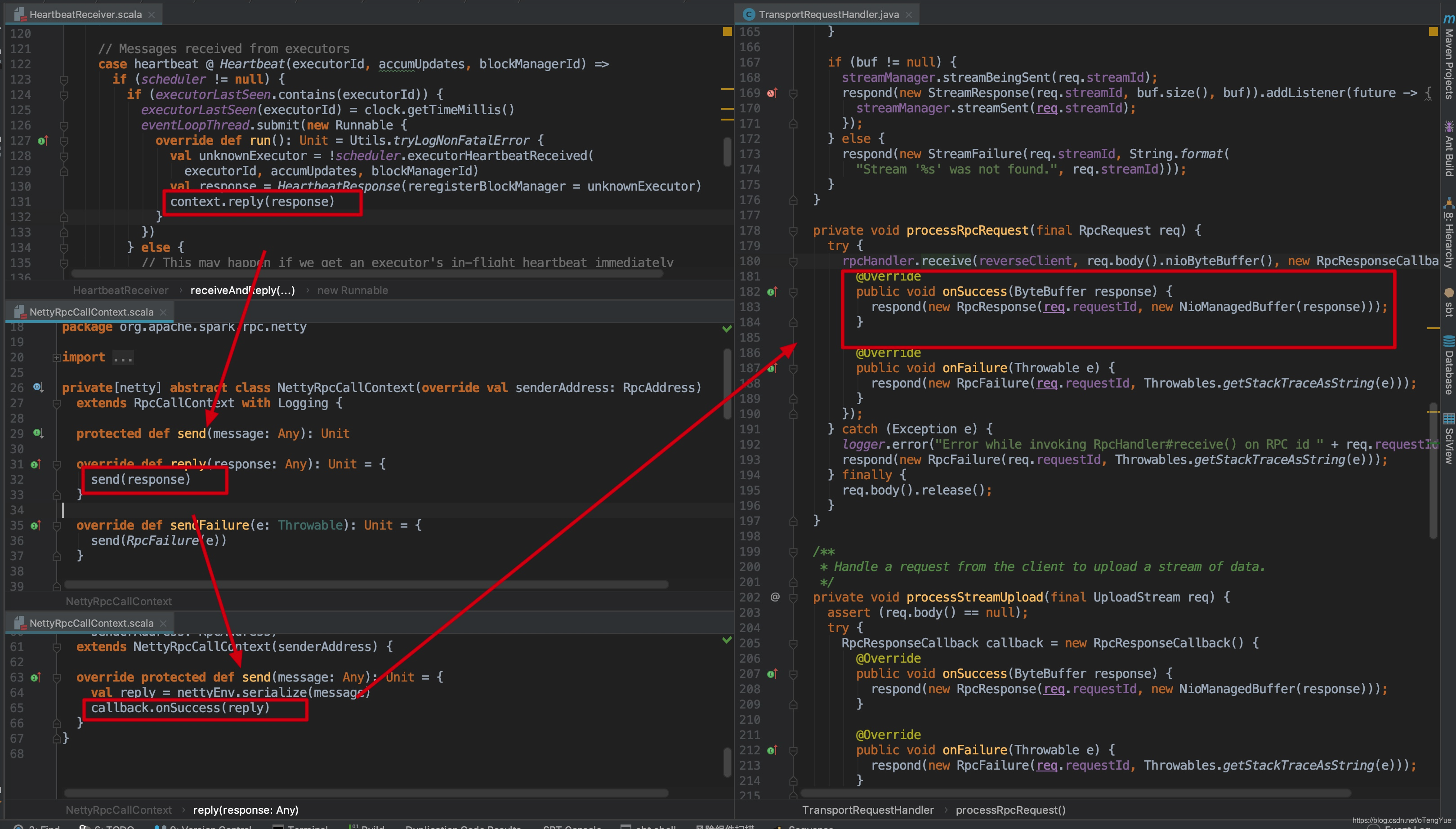
handle方法中根据server返回的requestId从集合outstandingRpcs中获取callback对象,这个callback对象就是前面说的RpcOutboxMessage,调用addRpcRequest(requestId, callback)方法添加进去的,然后调用回调函数的onSuccess函数将结果返回。
这样在前面说的NettyRpcEnv.ask()函数中的promise就能拿到返回值了,最终把结果返回给调用方。

那接下来我们分析一下,Server端如何处理带requestId的RpcRequest并返回带requestId的RpcResponse?
从上面章节我们可以知道Server的Netty服务启动后会将TransportChannelHandler注册到底层的Netty的Pipeline中,然后就开始监听接受消息,当Client发送带RpcRequest消息后,Server端注册的TransportChannelHandler判断如果是RequestMessage,则会把请求转给TransportRequestHandler进行处理。
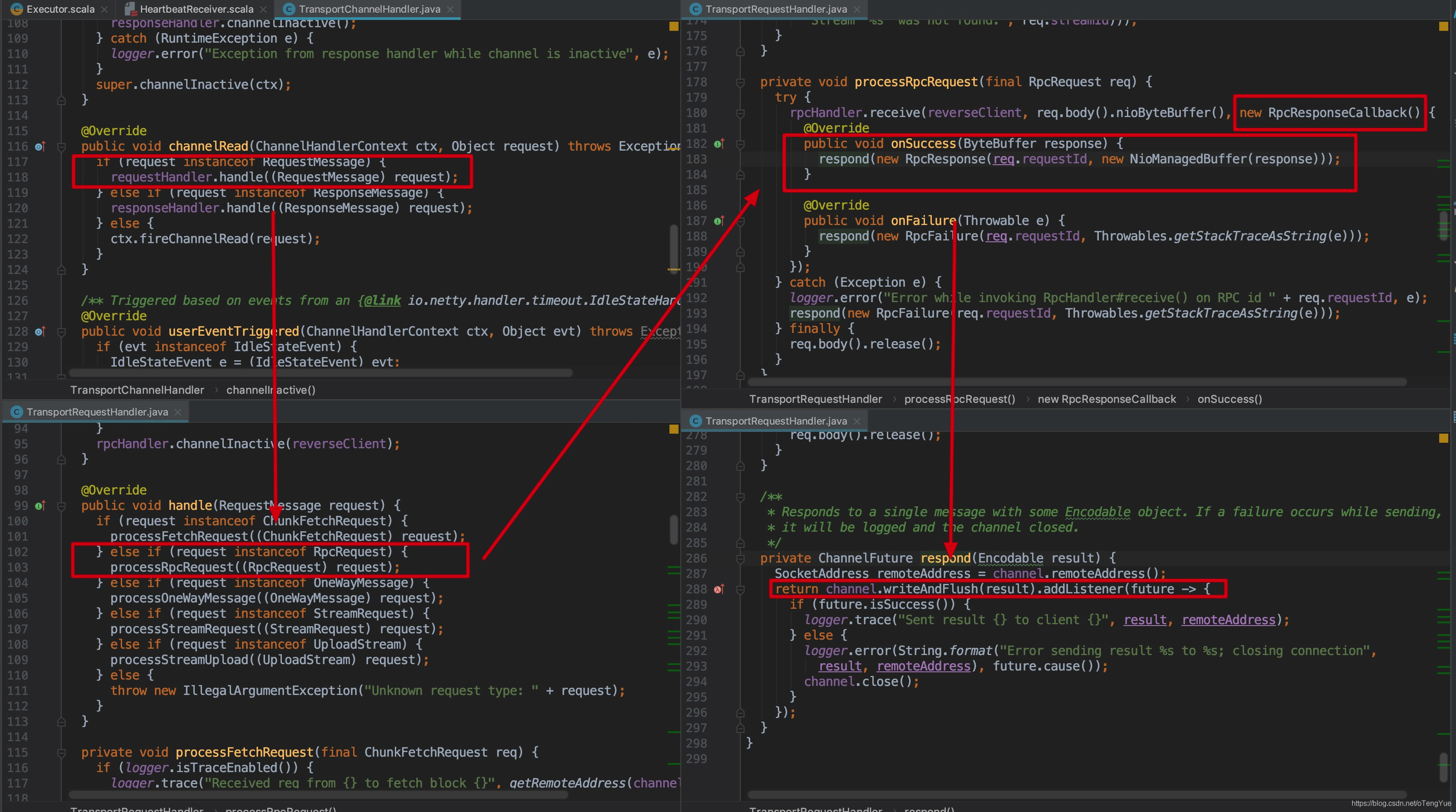
如上图,在TransportRequestHandler.handle()函数中判断是否如果是RpcRequest请求,则调用TransportRequestHandler.processRpcRequest()函数进行处理,处理过程为首先创建一个RpcResponseCallback回调函数做为参数,传给NettyRpcHandler.receive()做上游调用业务逻辑处理,处理完成会调用RpcResponseCallback.onSuccess()封装(requestId + message)为RpcResponse消息向Client进行返回。我们继续分析上游代码:
如上图在Dispatcher.postRemoteMessage()函数中会新新建RemoteNettyRpcCallContext封装RpcResponseCallback,之后使用RemoteNettyRpcCallContext作为参数继续调用,我们跳过中间环节直接看业务逻辑处理代码如何调用RpcResponseCallback的?同样以心跳交互为例代码如下:
至此,Server端处理RpcRequest并返回带requestId的RpcRespons的过程也分析完成了。
最后给出一张Request-Response流程简图:
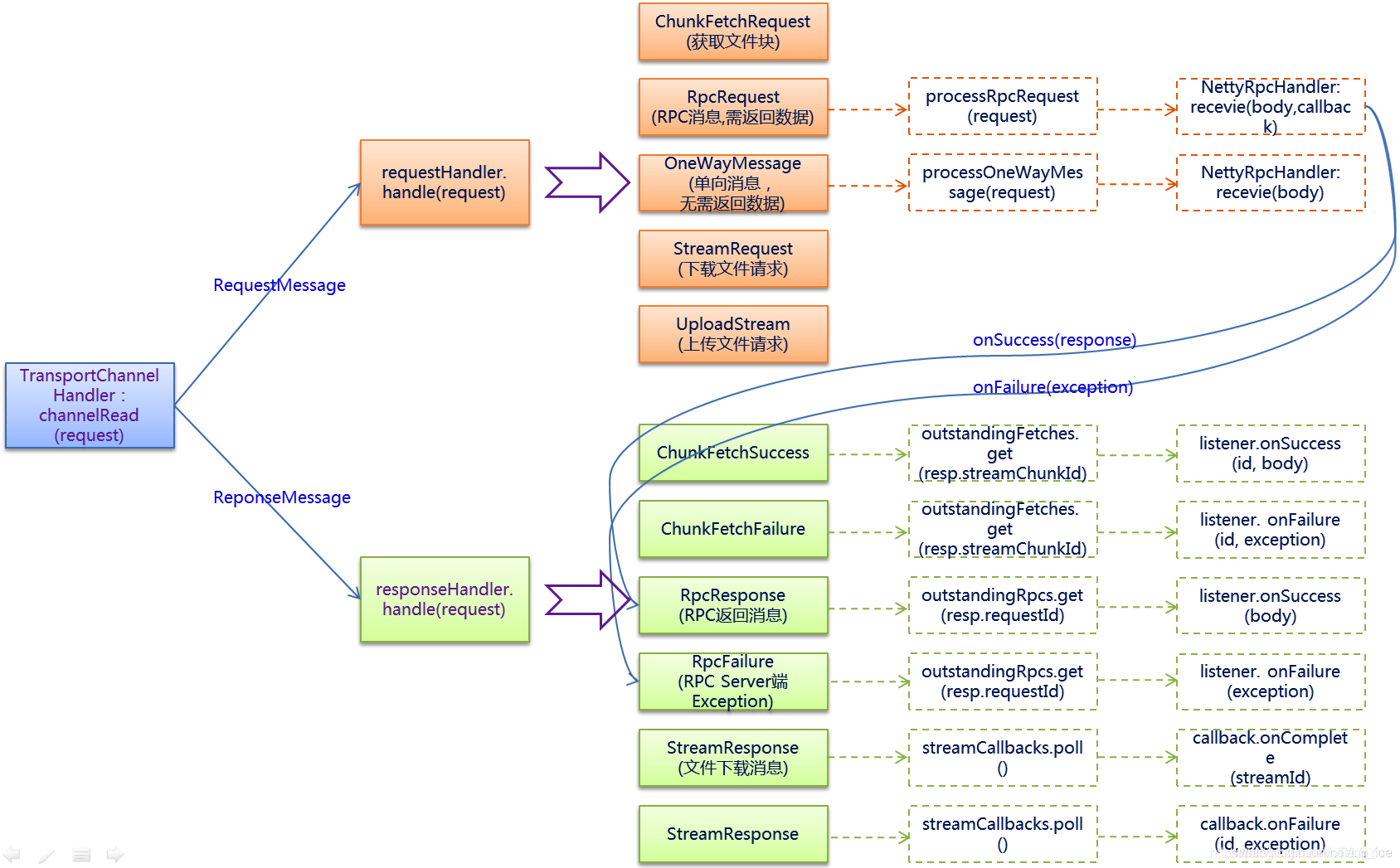
参考
Spark Network 模块分析
Spark RPC之RpcRequest请求处理流程
Spark RPC之Dispatcher、Inbox、Outbox
Spark RPC模块源码学习
kraps-rpc
Spark Netty通信传输层架构