闭集与开集分类问题
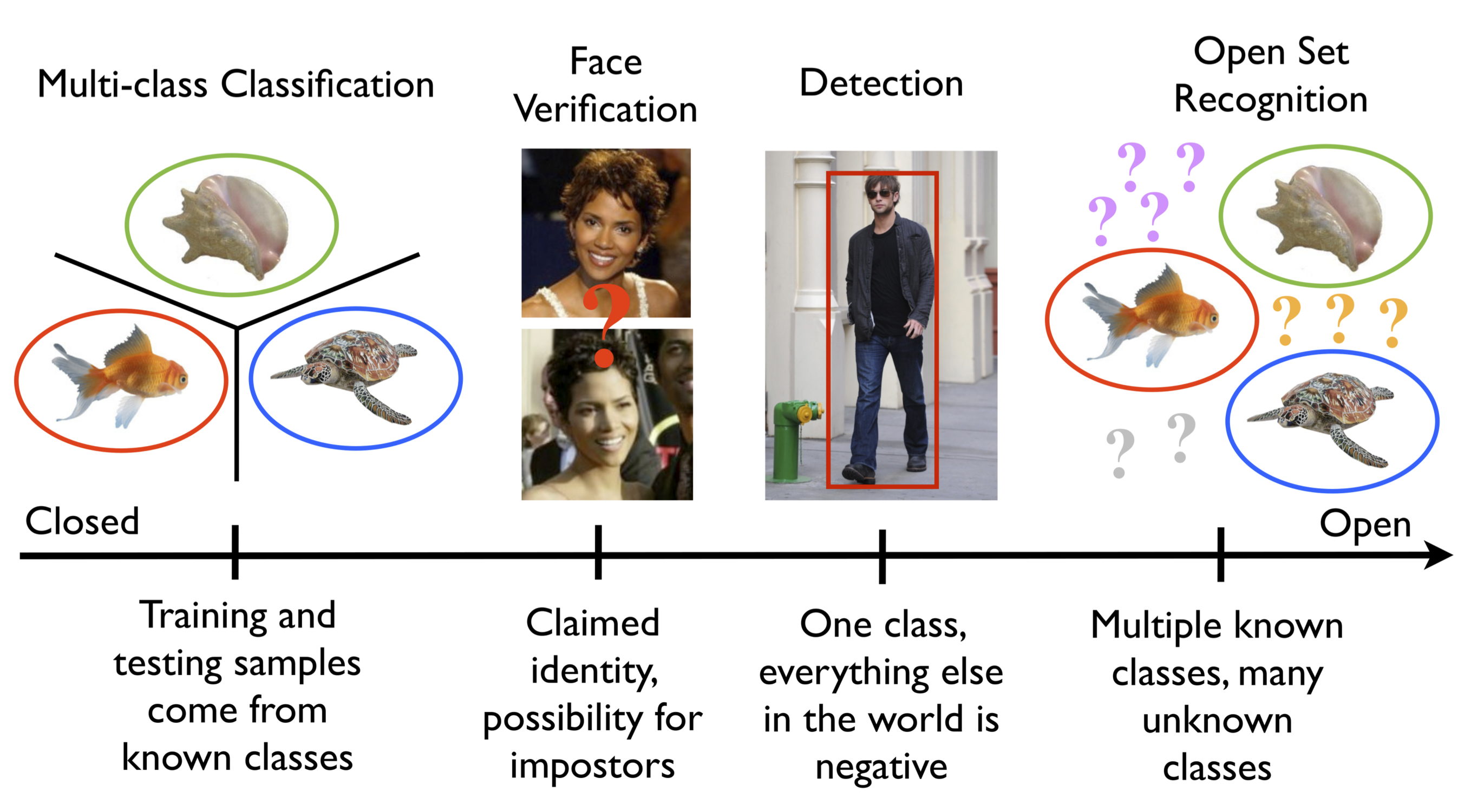
闭集分类问题(closed-set problem),即测试和训练的每个类别都有具体的标签,不包含未知的类别(unknown category or unseen category); 如著名的MNIST和ImageNet数据集,里面包含的每个类别为确定的。以MNIST(字符分类)为例,里面包含了0~9的数字类别,测试时也是0~9的类别,并不包含如字母A~Z等的未知类别,闭集分类问题即:区分这10个类别
开集分类问题(open-set problem)不仅仅包含0~9的数字类别,还包含其他如A~Z等等的未知类别,但是这些未知的类别并没有标签,分类器无法知道这些未知类别里面图像的具体类别,如:是否是A,这些许许多多的不同类别图像共同构成了一个类别:未知类别,在检测里面我们叫做背景类别(background),而开集分类问题即:区分这10个类别且拒绝其他未知类别 [1-3]
更形式化,可定义为
闭集分类问题:集合S包含N个有限类别,且该N个类别有具体标签,闭集分类问题即划分这N个类别
开集分类问题:集合S包含N个有具体标签的有限类别,且S包含K个有限或无限未知类别,开集分类问题即划分这N个类别且拒绝这K个未知类别
人脸的开集识别问题
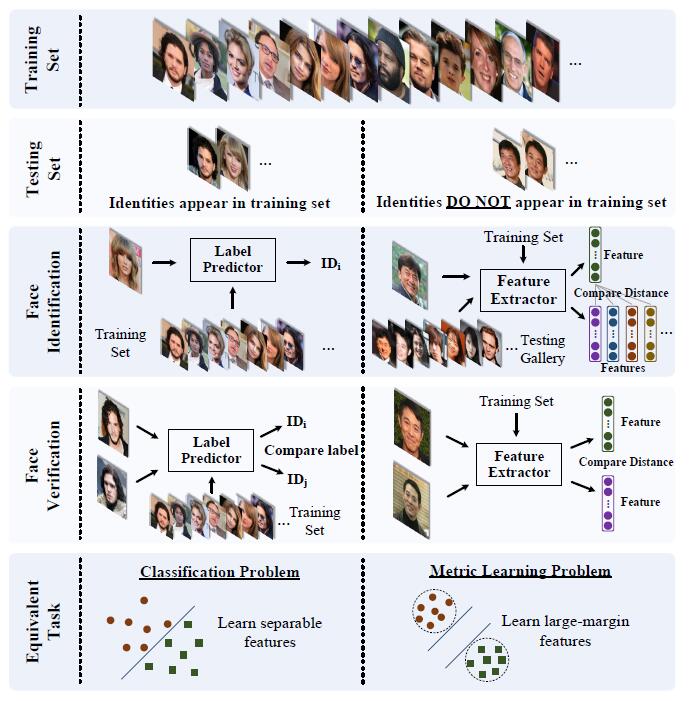
人脸识别,现在已经成为了被广泛使用的技术,我们所使用的电脑,手机几乎都具备这样的基础功能。通常我们使用的人脸识别技术本身就是open-set problem,即人脸识别的训练集和测试集可能是非常不同的,而闭集测试对于普通的人脸识别商用意义有限,这里就存在测试集的Identities(ID)或不同人(或类别)远远超过训练集的问题; 以微软的开放数据集MS-Celeb-1M为例,它仅仅包含约100K的ID数量,和中国人的ID数相比差了4个数量级; 那么这个数据集这么小是否就没用的呢?并不是,但是从目前来看ID数量已经成为限制人脸识别精度的主要影响因素,也就是说数据集主要影响的是精度从而影响商用范围(不同的应用要求精度有差别,如社区门禁模型要求在 1 0 − 4 10^{-4} 10−4 FPR下 99%的 TPR 应该说就足够了)
从人脸识别的pipline来看(检测-对齐-识别),人脸识别有两个地方会涉及到open-set问题,第一个就是人脸检测,人脸检测直接面对的就是开放世界的场景,各种各样的物体; 第二个即识别,识别面对的物体要比检测单一,即各种不同ID的人脸
如果没有检测这一步,人脸识别将会更加困难,这个时候人脸特征失效会非常严重,你无法想象,放一张猫脸或者其他乱七八糟的图片会发生什么(当然识别模型有部分outlier detection能力,但是很弱)。从人脸识别的整个pipline来看,是先拒绝了非人脸,然后再拒绝非注册ID,本质还是拒绝非注册ID,并区分注册ID; 而非注册ID本身可能是人脸且不是其他非人脸的物体,所以从定义上说和open-set problem是一致的,这里涉及到粗粒度分类和细粒度分类问题,遵循先粗后细的原则
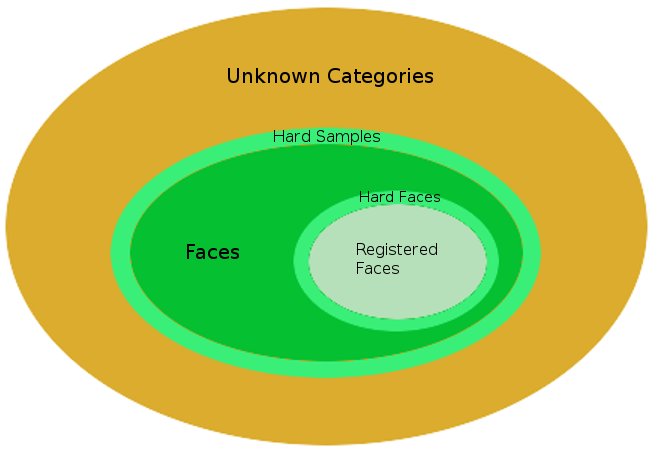
特征完备性
目前人脸识别的识别这个过程包含:特征提取(如上图是由metric learning所学习到的,各种loss,包括center loss,sphere loss,arcface loss等等),特征比对(距离度量,包括cosine similarity,
L
k
L_k
Lk distance等等)。特征提取模型的特征涉及到特征完备性问题,假设模型能完备的编码了所有人的人脸ID为独有的特征,即任意两个人如果能被区分,则其人脸特征能被以接近0的误差区分
如果训练的人脸ID足够多到模型所提取的特征接近或已经达到特征完备性,那么实际所需要的训练ID数将存在一个上界。换句话说,如果你的ID数据多到可以达到或接近特征完备性,开集测试和闭集测试将不存在显著差别。
但是这里其实忽略了一个问题,即两个人真的能被区分吗?假设我们任选一个人脸为注册ID,在足够大的ID集合中,总会存在某人脸ID与该注册ID的相似度接近于100%,意味着不管你的模型有多好,是否是特征完备的,只要在一个足够大的ID集合中去搜索总会存在不能被识别的ID(世界上没有完全相同的两片树叶,但是却有两片相似度足够高的树叶),这里的足够大可以衍生为很大的ID集合,如一个市,一个国家等等,所以人脸识别并不总是靠谱的,还需要其他特征,如:地理位置,人体姿态,日常穿着等等来缩小我们的待搜索ID集合,减小识别的不确定性; 这也是为什么我们做大规模人脸识别检索要使用TopK的原因
普通物体的开集识别问题
普通物体的开集识别问题和人脸识别雷同,其实完全可以按照相同的pipline来做,区别是普通物体本身包含了许许多多的粗粒度分类问题和细粒度分类问题,如注册类别为3只不同ID的猫和5只不同ID的狗,可以用2个pipline来识别,甚至还有不同品种的狗和猫等等这个pipline就会长一些,其他关于Hard Samples的问题可参考本人的另一篇文章 Online Hard Sample Mining
参考
- Open Set Recognition
- Toward Open Set Recognition
- Towards Open Set Deep Networks
- Open Set Face Recognition Using Transduction
- Deep Learning Face Representation from Predicting 10,000 Classes
- FaceNet: A Unified Embedding for Face Recognition and Clustering[Triplet Loss]
- A Discriminative Feature Learning Approach for Deep Face Recognition[Center Loss]
- DeepID3: Face Recognition with Very Deep Neural Networks
- CosFace: Large Margin Cosine Loss for Deep Face Recognition
- SphereFace: Deep Hypersphere Embedding for Face Recognition
- ArcFace: Additive Angular Margin Loss for Deep Face Recognition