paper:ResNet strikes back: An improved training procedure in timm
official implementation:https://github.com/huggingface/pytorch-image-models
背景
ResNet(残差网络)架构自He等人引入以来,一直在各种科学出版物中占据重要地位,并作为新模型的基准。然而,自2015年ResNet问世以来,训练神经网络的最佳实践取得了显著进展,包括优化和数据增强技术,但这些进展并未完全融入ResNet的标准训练程序中。
出发点
本文重新评估了在整合这些最新进展的训练程序下,标准ResNet-50的性能。研究发现,许多文献中报告的ResNet-50在ImageNet上的表现(75.2%-79.5%)仍远未达到该架构的最大潜力。本文旨在通过优化训练程序,提高ResNet-50的性能,从而提供更强大的基准供未来工作使用。
创新点
本文旨在填补以下空白:为原始ResNet-50架构找到最优的训练程序,并将其性能最大化。为此,研究团队提出了三种不同的训练程序,并提供了具体的训练设置和预训练模型,供社区使用和比较。
- 新的训练程序:提出了三个不同的训练程序,分别针对100、300和600个epochs进行优化,以适应不同的使用场景和计算资源。
A1方案:600个epochs,最优性能,适合长时间训练。
A2方案:300个epochs,与现代训练程序(如DeiT)相当,但使用了更大的batch size(2048)。
A3方案:100个epochs,较短的训练时间,适合探索性研究。 - 损失函数:引入了多标签分类目标,使用Mixup和CutMix数据增强,并采用二元交叉熵(BCE)损失函数,而非传统的交叉熵(CE),以更好地适应合成图像中的多个概念。
- 数据增强:采用了RandAugment、Mixup和CutMix的组合,增强了数据多样性和模型的泛化能力。
- 正则化技术:根据训练时长,调整了权重衰减、标签平滑、重复增强和随机深度等正则化方法,以减少过拟合并提高模型稳定性。
- 优化器:在大batch size下,使用LAMB优化器和余弦调度策略,以保证良好的收敛性和性能。
方法介绍
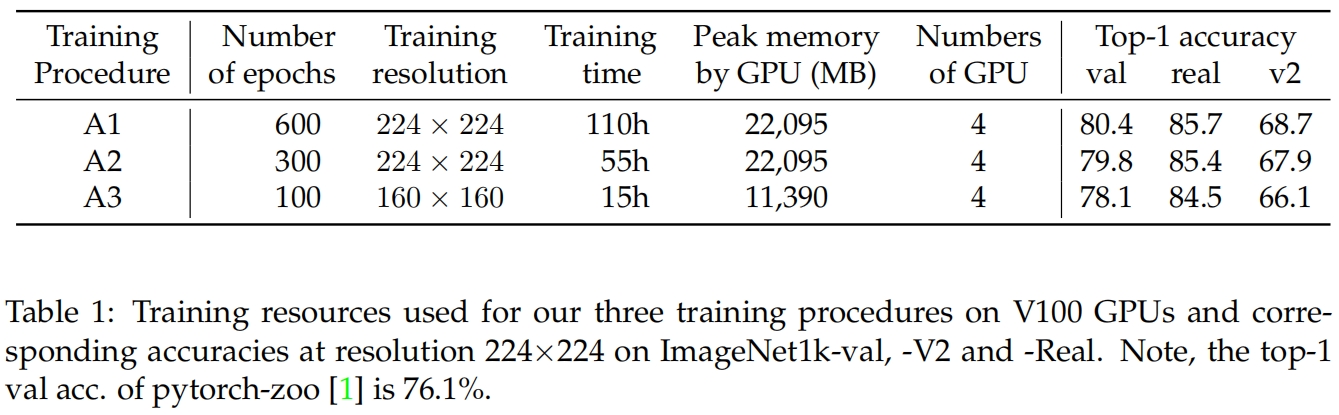
作者提供了三种不同的训练策略,具有不同的成本和性能,以覆盖不同的应用场景。资源的使用情况和对应的性能对表1所示。
三种训练策略具体包括:
Procedure A1 旨在为ResNet-50提供最佳的性能,因此它有最长的epochs(600)和训练时间(在具有4张32G V100 GPU的单个节点上需要4.6天)。
Procedure A2 训练300个epochs,可以与一些现代的策略如DeiT媲美,但有更大的batch size 2048和一些为三个策略引入的一些其他选择。
Procedure A3 旨在用2048的batch size在100个epochs内超越原始的ResNet-50,在4张16G的V100上它可以在15小时内完成训练,适用于探索性研究。
Loss: 多标签分类目标
Mixup和CutMix两种数据增强将多个具有不同标签的图像合成为一张,通过交叉熵损失,输出被隐式地视为每个目标存在的概率。本文作者假设所有目标都存在,将其视为一个多标签分类问题,这样对每一类都是用二元交叉熵BCE而不是原本的CE。BCE与Mixup和CutMix相一致:如果Mixup或CutMix选择了某一类,则BCE将这一类的目标设置为1,独立于其它类别。在本文的实验中,将所有混合类别的目标都设为1要比和为1的分布更有效。这也更符合Mixup和CutMix实际上在做的事情:人类很大概率能够识别出混合类别中的每一个。
Data-Augmentation
作者采用了以下数据增强的组合:在标准的Random Resized Crop(RRC)和horizontal flip的基础上,使用了timm中RandAugment、Mixup和CutMix的变体(具体介绍可参考RandAugment(NeurIPS 2020)论文速读-CSDN博客、数据增强Mixup原理与代码解读-CSDN博客、CutMix原理与代码解读-CSDN博客)。
Regularization
三种训练策略中,正则化的区别是最大的。除了weight decay外,还使用了label smoothing、Repeated Augmentation和Stochastic depth(具体介绍见Stochastic Depth 原理与代码解析-CSDN博客)。更长的训练策略采用了更多的正则化,例如只在A1中采用了标签平滑。RA和stochastic depth都可以提高收敛时的结果,但减缓了早期的训练,在较短的训练策略中,它们的效果较差甚至有害,因此本文只在A1和A2中使用它们。
Optimization
从AlexNet以来,卷积网络常用的优化器是SGD,而在Transformer和MLP中常用AdamW或LAMB。ViT论文中作者报告了SGD和AdamW在ResNet-50上相似的结果,这和本文对中等大小batch size(比如512)的观察结果是一致的。但本文使用了更大的batch size即2048,作者发现当与RA和BCE结合使用时,LAMB可以获得更好的结果,而使用SGD和BCE很难收敛。因此本文采用LAMB结合余弦学习率schedule作为训练ResNet-50的默认选择。
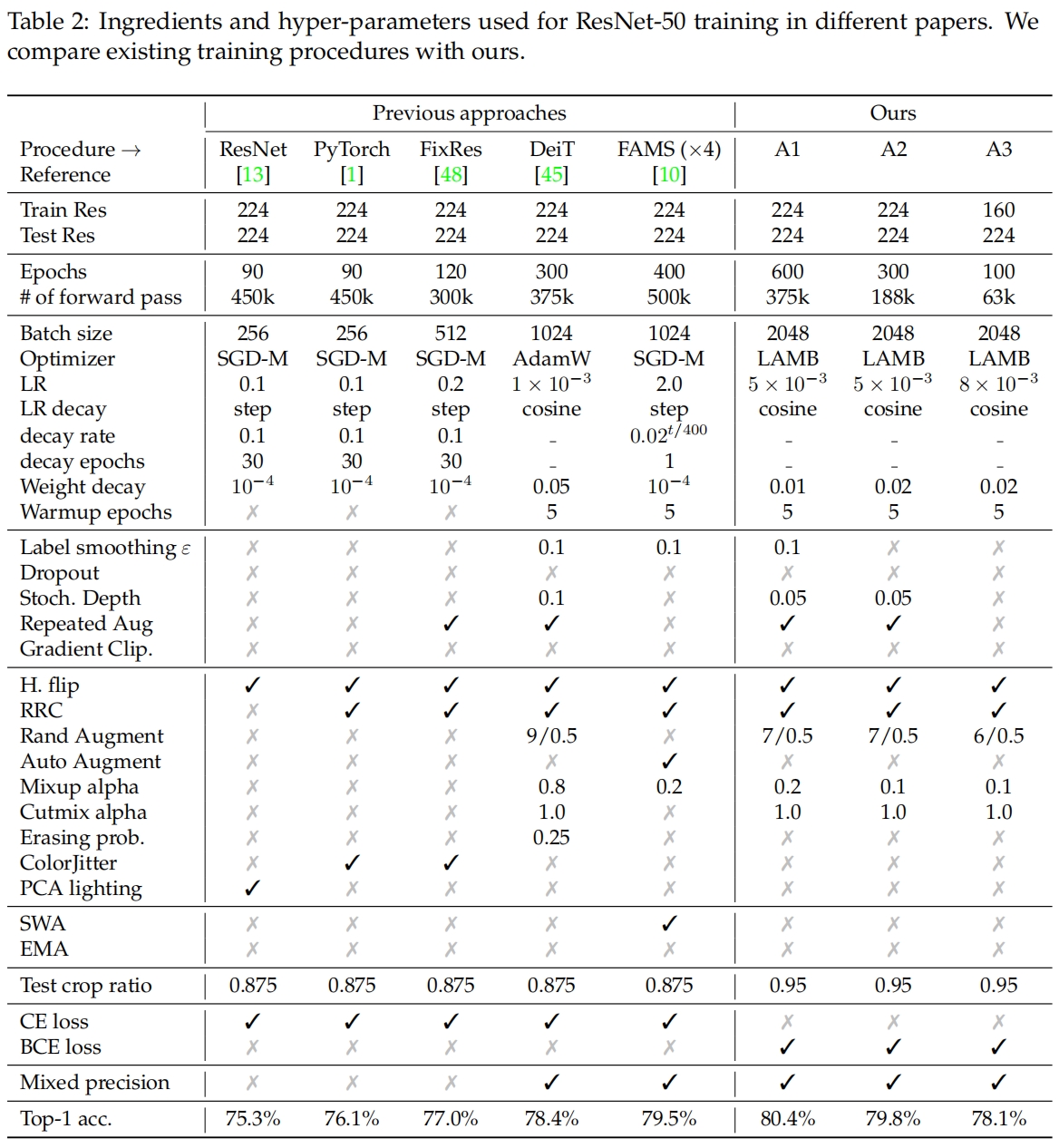
表2对比了本文的训练策略和其它文章中训练ResNet-50的策略,这里是原始的ResNet-50不包括对网络的改进如SE block和更高级的训练设置如蒸馏、自监督预训练等。
实验结果
表3是不做任何修改用本文提出的三种训练策略训练其它模型的结果与原始结果的对比,表4进一步补充了A1训练策略的结果。从中我们可以看到它们是否能很好地推广到其它模型。其中很多模型用本文的训练策略重新训练后的性能都优于原始论文中的结果。在某些情况下例如ViT-B,A2的结果优于A1,这表明超参不适用于更长的训练(通常需要更多的正则)。
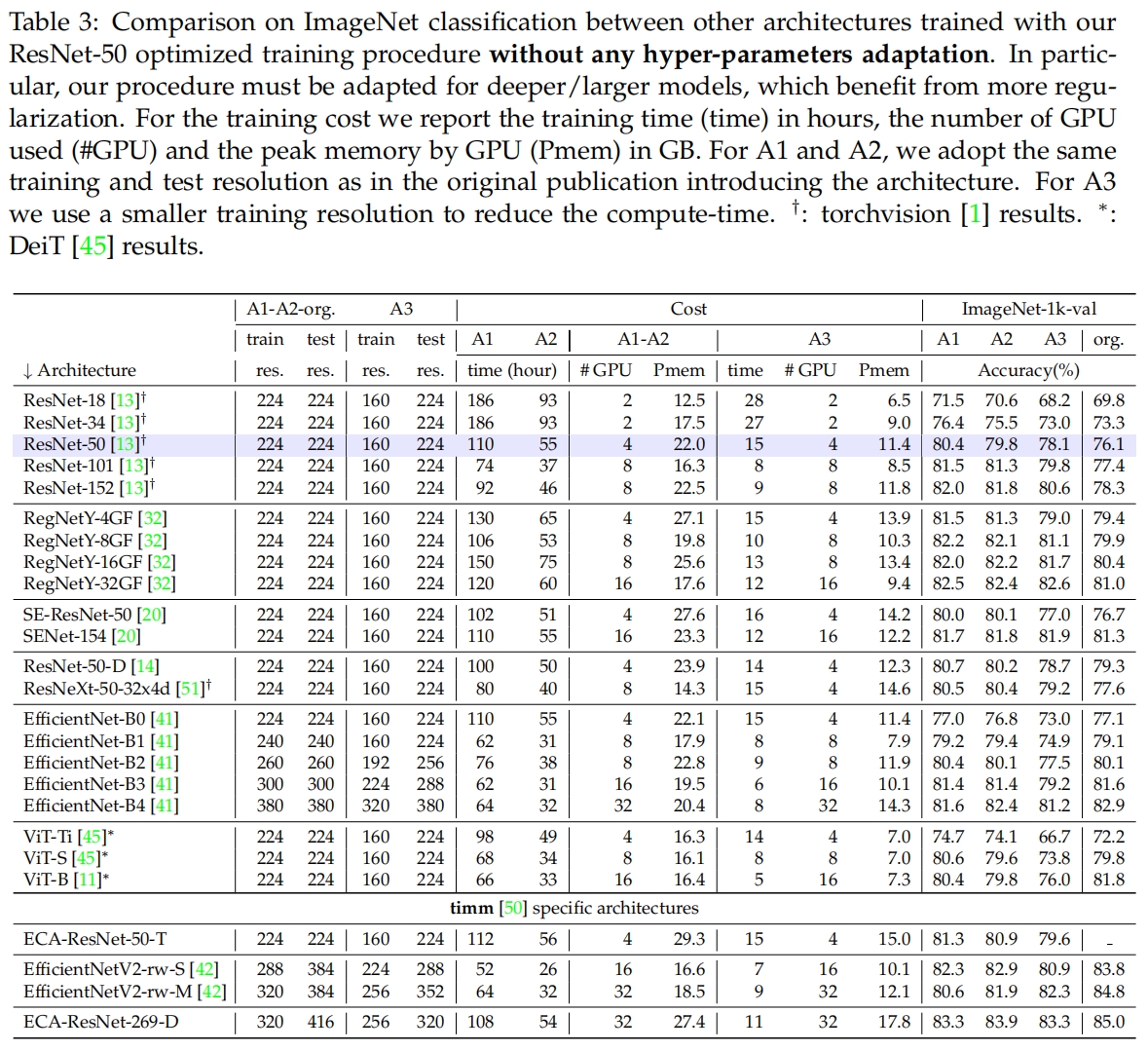
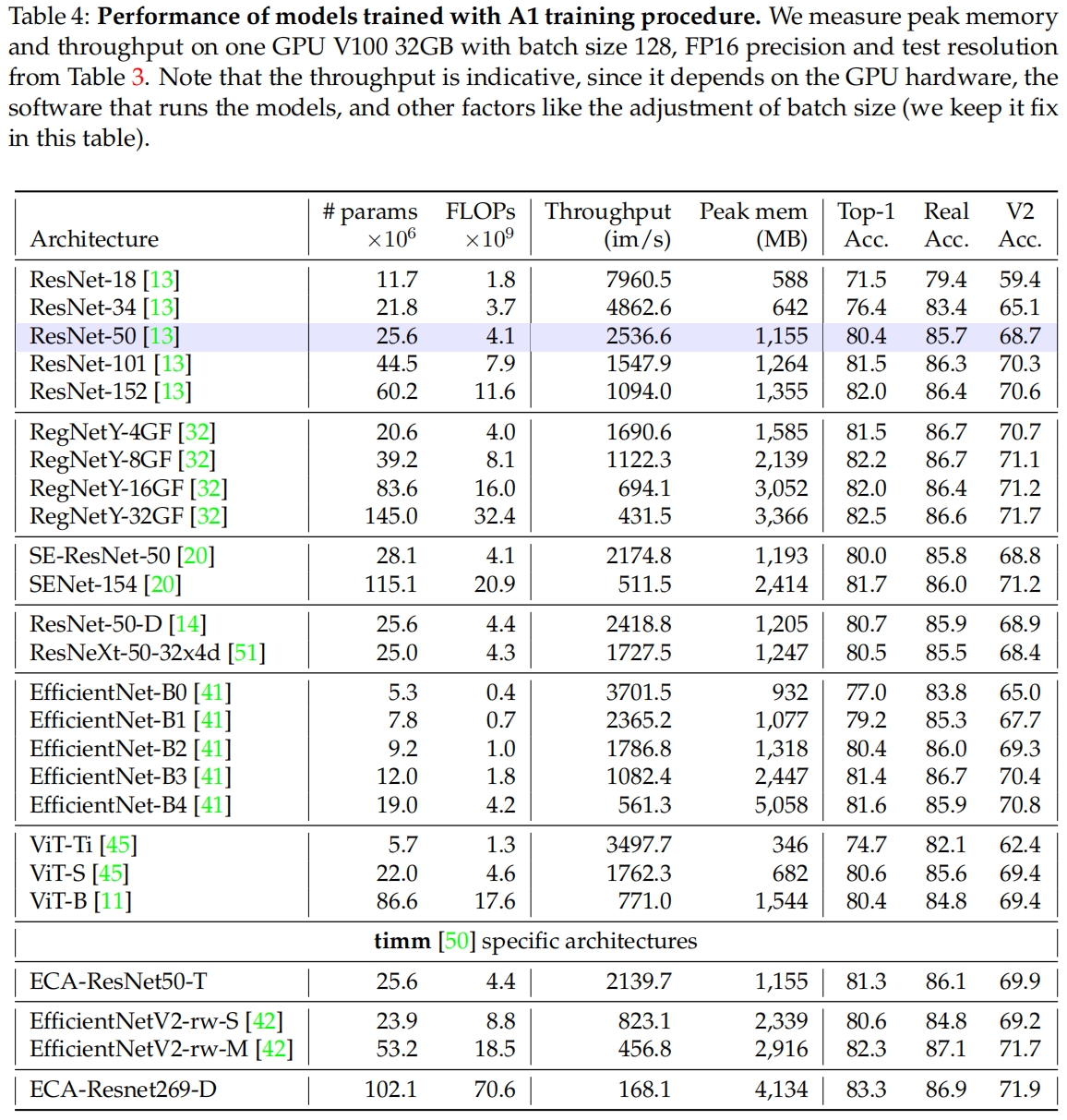
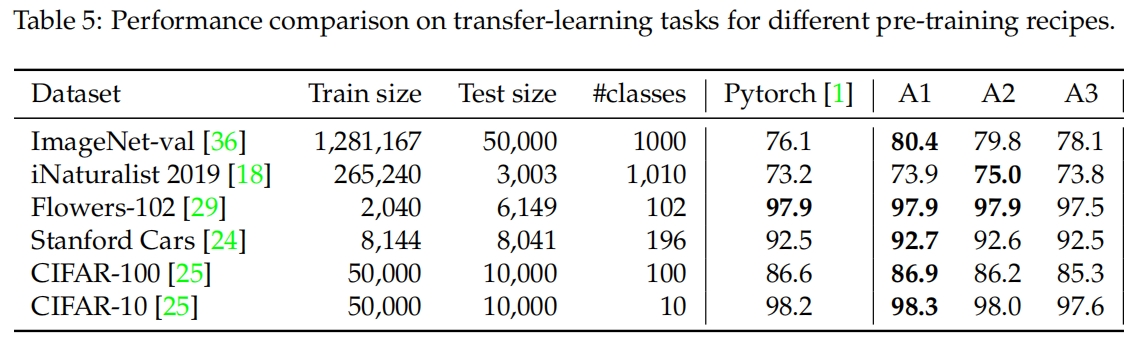
表5给出了本文训练策略和Pytorch中默认训练策略预训练的模型在其它小数据集上微调的迁移学习性能。总体来说,A1在下游任务中的性能最好。A2和Pytorch默认策略的效果相似,但在ImageNet-val和iNaturalist上明显更好。A3在下游任务上的效果明显落后,这可能与160x160的较低训练分辨率有关。
比较架构和训练策略:一个矛盾结论的例子
这部分作者说明了在相同的训练策略下比较两种架构是多么的困难,或者用同一架构比较不同的训练策略是多么的困难。作者选择了ResNet-50和DeiT-S,两者参数量近似。对每个架构,作者都投入了大量的精力来优化,在相同的300个epochs和同样的batch size下最大化在ImageNet-val上的性能。在此限制下,为ResNet-50设计的最佳训练策略就是A2,T2表示对应于DeiT-S的最佳训策略。结果如下
