最近没事的时候就爱爬小说玩,也不看,就是觉得爬小说好嗨皮(▽)。以前都是在网上下TXT,现在发现,有可能也是这么来的(▽)
但执行的时候一直有个问题,之前也没怎么注意,因为没有打印页面的信息,所以一直没注意,今天打印了下,在打印的页面中发现了"访问本页面,请开启JavaScript并刷新该页"。
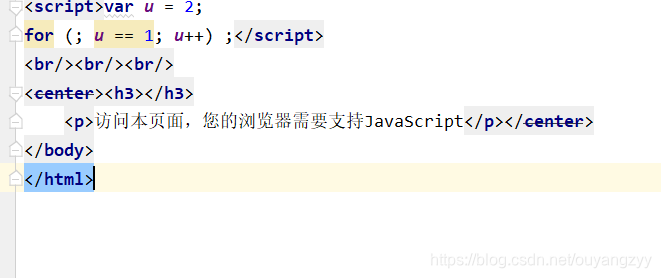
我仔细一想这大概是网站做的反爬。百度了下后,大概是知道了为什么会这样。
原因:页面加载是通过JS刷新页面,或者是中间有一个过渡的301或302跳转页面。由于直接请求获取后JS刷新不完全或者是请求的地址是301或302这样的跳转页面,自然就得不到想要的信息和数据了。
解决办法:
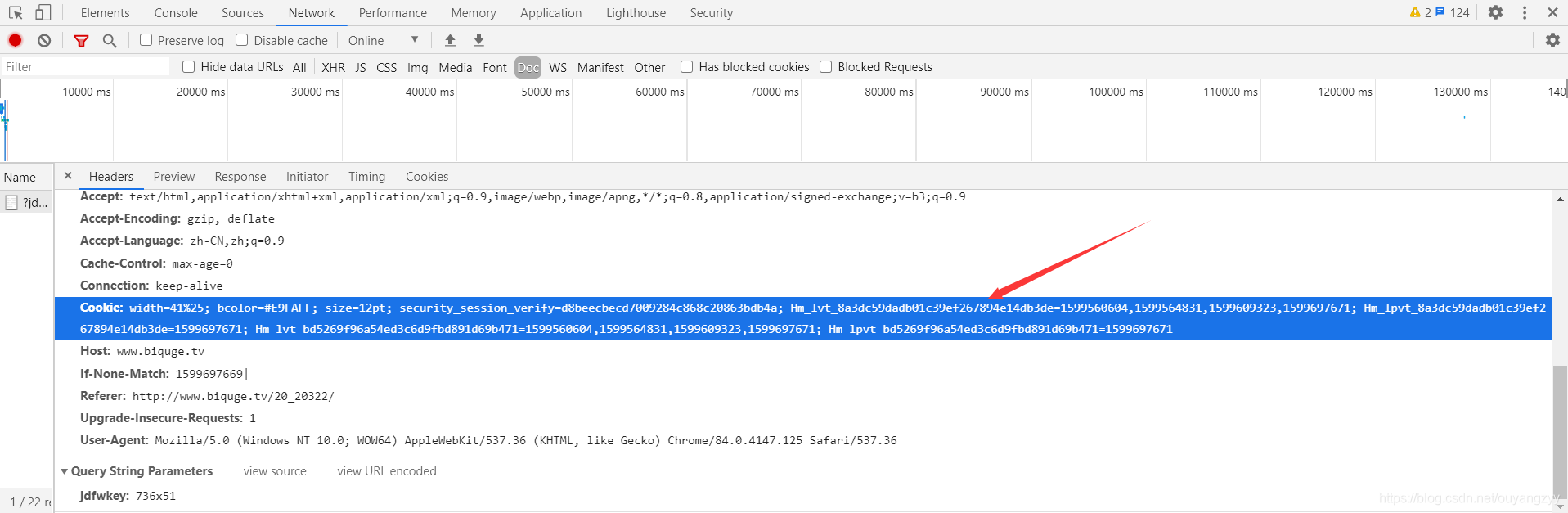
1、一种是在headers中添加该网站的Cookie,但需要注意的是Cookie的值过一段时间会发生变化,要重新获取。
但是,好像过段时间cookie就不管用了,就得重新获取新的。不知道是为啥。
2、第二种方法,我看搜的是用的是requests模块,这个模块可以很好的解决JS加载不完全的问题。目前对requests模块还不是特别熟悉,就不卖弄了。