这是我第一次接触python时,我们学校做的项目实训,其实整个项目实训过程很简单,并没有什么难度,认真学学就会。
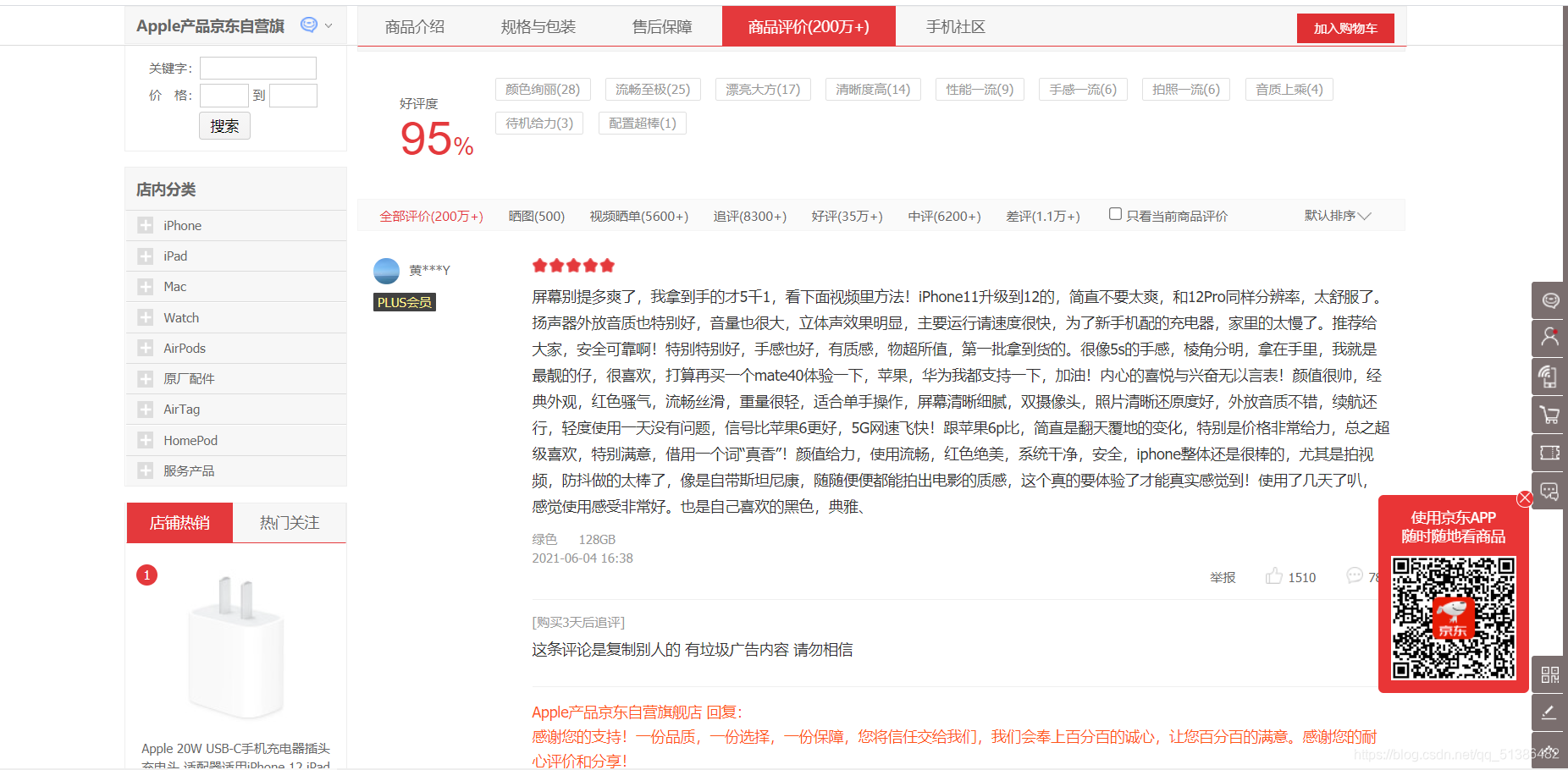
首先,我们要明确我们的目标:从京东上爬取产品的评论。一般评论都是进行情感分析,但我还没进行到那一步,只能先进行相关数据爬取下来,然后把爬到的数据以csv或者json格式保存成文件。
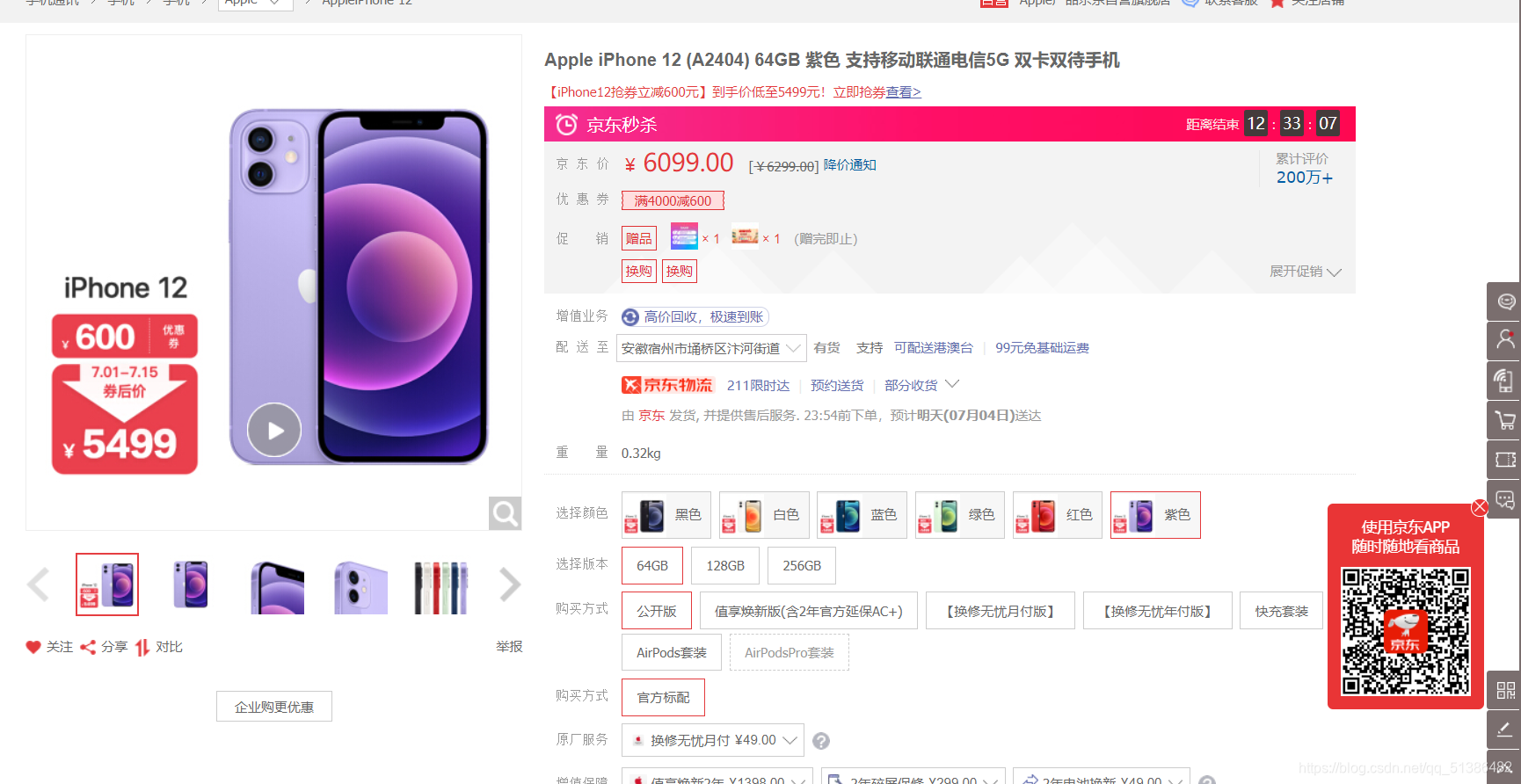
其次,找到数据源的京东官网首页,然后点击搜索框填入手机,拿苹果手机举例
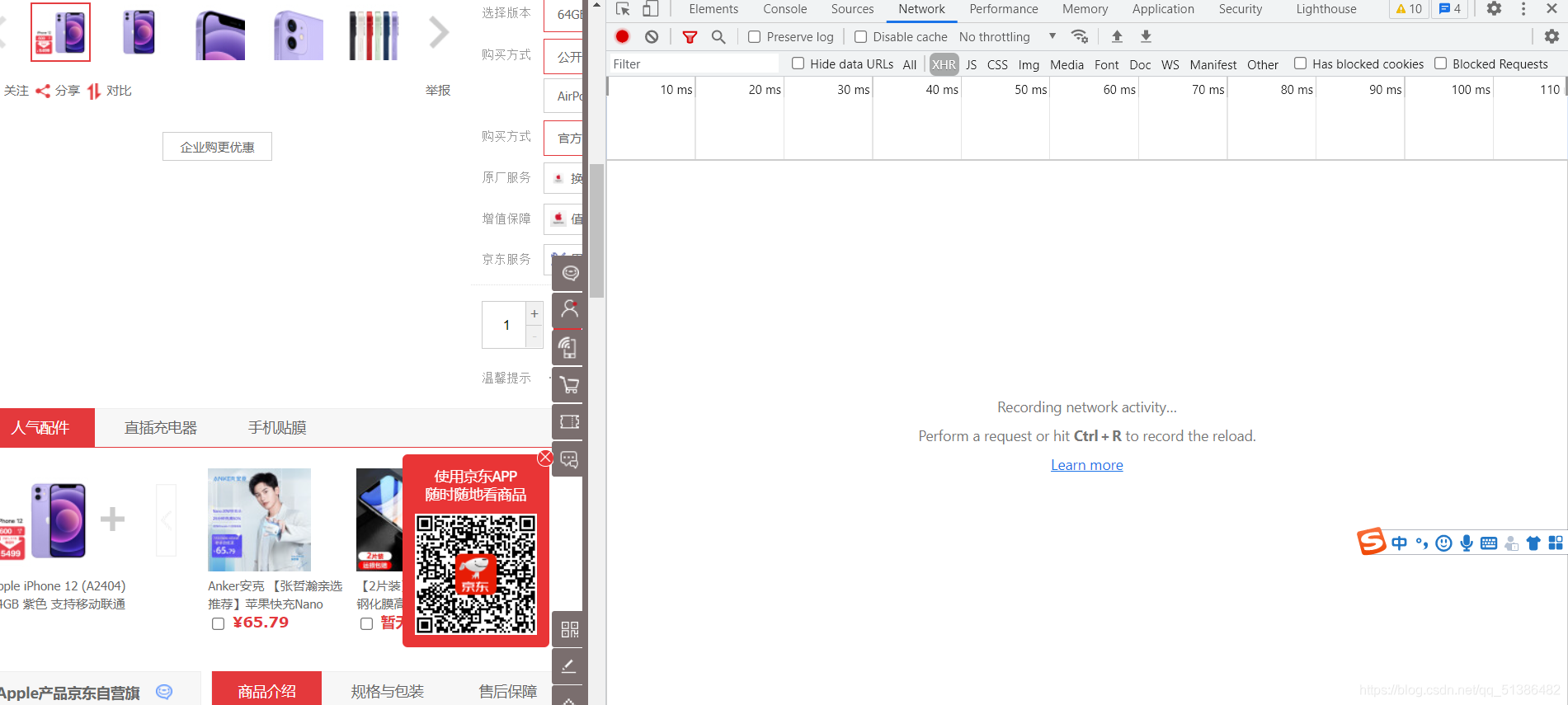
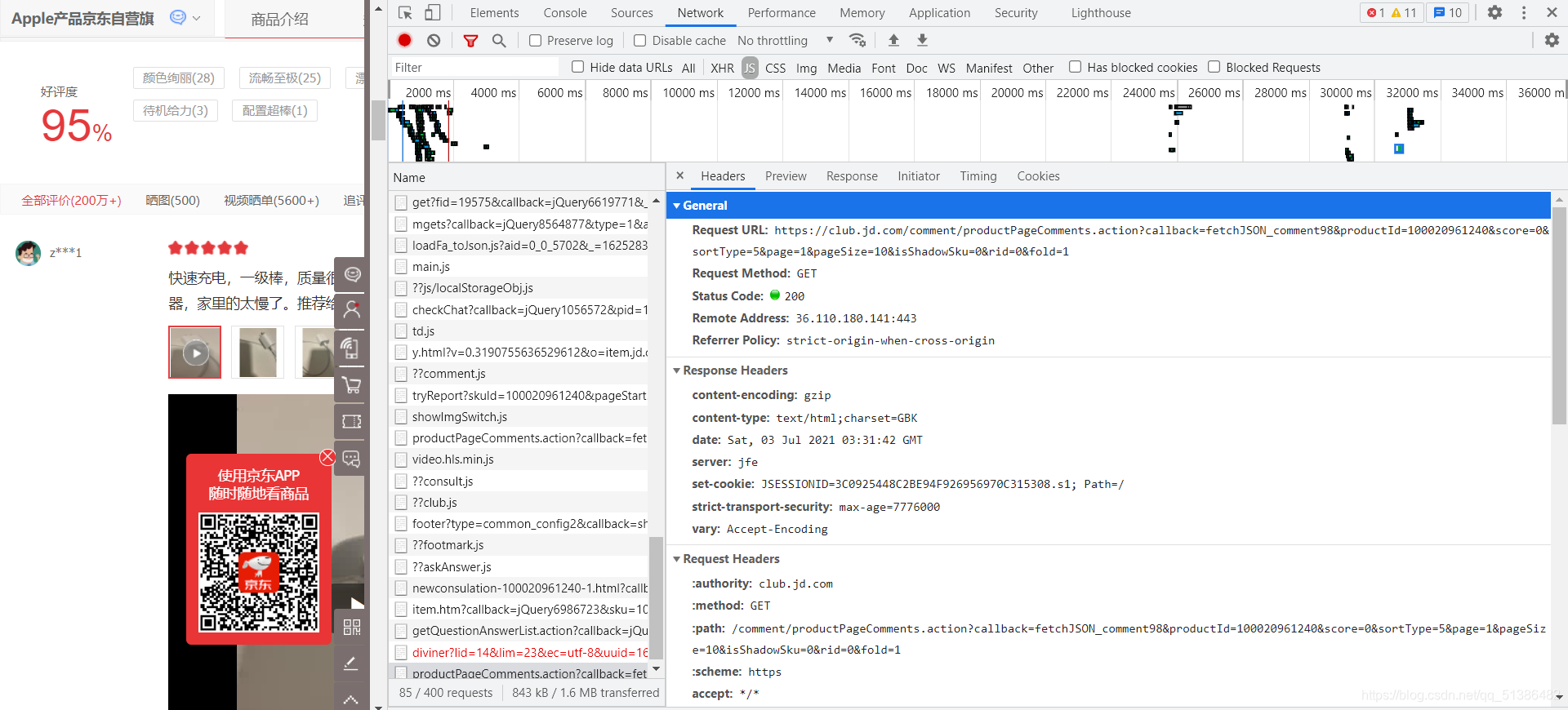
由于可以看到我们的评论是动态的,且可能不断更新,我们便在谷歌网页右键,点击检查或者直接F12快捷键,之后就是显示以下这种界面:
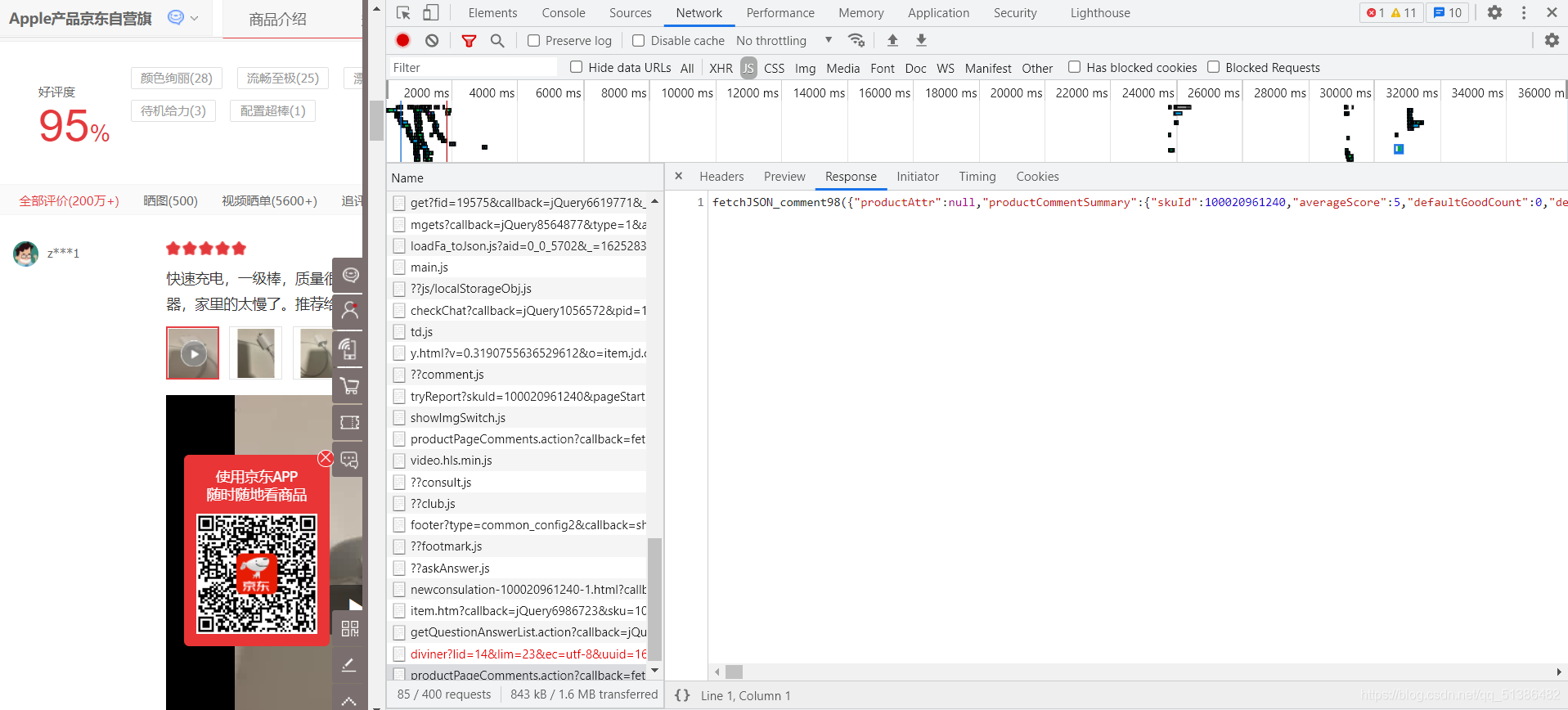
点击右上角的network,发现下面是空的,我们刷新页面,network下面就有东西了,但是我们需要评论,直接下拉到评论,网址不会改变,我们可以点击下一页,多了comment部分,但同时在右边找到了评论所在的JS,具体怎么找呢,我们先点击JS,然后从最下面找,主要看Response,若是在Response里面找到了评论,那就是在那里,然后点击Headers,找到我们需要的URL
然后,我们便开始进行相应的爬虫第一步:
import scrapy
import re, json
from JDSpider.items import JDCommentItem
# 定义一个爬虫类,继承自scrapy框架的spider
class JDSpider(scrapy.Spider):
# 定义爬虫名,保证在项目中