文章目录
一、初识 Mongoengineo
1. 简介
Mongoengine是一个Python的对象文档映射(ODM)库,用于在Python中操作MongoDB数据库。它提供了面向对象的编程方式,使开发人员可以使用Python对象来表示MongoDB中的文档,而不必关心底层的数据库操作。与MongoDB的文档结构相对应,Mongoengine支持定义模型类和字段,并提供了简单易用的API来进行查询、更新、删除等操作,易于使用和定制,是Python开发人员使用MongoDB数据库的良好选择。
2. mongoengine的优点
-
更加易用的API:mongoengine提供了Python风格的API,让开发人员可以更加方便地操作MongoDB数据库。开发人员不需要学习复杂的MongoDB语法或命令行,而是可以通过Python类和对象来操作数据库。
-
方便的对象操作:MongoEngine允许我们使用Python类和对象来操作MongoDB文档,这种方式更符合我们的编程思维,降低了开发难度。
-
文档嵌套:mongoengine支持嵌套文档,这意味着可以将一个文档嵌套到另一个文档中。这个特性对于处理具有层次结构的数据非常有用,可以更加灵活地表示数据结构。
-
自动验证:mongoengine提供了自动验证机制,可以确保数据的有效性。这样,开发人员就可以更加容易地处理数据错误和异常。
-
灵活的查询:mongoengine提供了丰富的查询语法,可以轻松地构建复杂的查询。它还支持聚合管道,可以用于处理大量数据。
二、安装及连接数据库
1. 安装
输入以下命令来安装Mongoengine:
pip install mongoengine
2. 连接Mongodb数据库
- 直接连接本地数据库
from mongoengine import connect
# 使用MongoClient连接到本地无权限校验的MongoDB数据库
connect('admin', host='localhost', port=27017)
- 使用URI连接远程数据库
from mongoengine import connect
# 使用URI连接到远程鉴权的MongoDB数据库
connect(host='mongodb://admin:[email protected]:27017/test_db')
URI的格式为mongodb://[username:password@]host:port/[database],其中[username:password@]和/database是可选的,host和port指定MongoDB服务器的主机名和端口号。
- 连接多个数据库
from mongoengine import connect
# 连接多个MongoDB数据库
connect(host='mongodb://admin:[email protected]:27017/test_db',alias='db1')
connect(host='mongodb://admin:[email protected]:27017/test_db2',alias='db2')
在上面的代码中,alias声明了连接的别名,若不填写,则默认别名为default,且存在多个连接时,只能有一个连接使用默认别名。
三、字段类型和模型定义
1. 字段类型介绍
| 字段类型 | 说明 |
|---|---|
| StringField | 字符串类型字段。 |
| IntField | 整数类型字段。 |
| FloatField | 浮点数类型字段。 |
| BooleanField | 布尔类型字段。 |
| DateTimeField | 日期时间类型字段。 |
| URLField | URL类型字段。 |
| EmailField | 电子邮件类型字段。 |
| ListField | 列表类型字段,可以嵌套其他字段类型。 |
| DictField | 字典类型字段,可以嵌套其他字段类型。 |
| ReferenceField | 引用类型字段,用于关联其他集合中的文档。 |
| EmbeddedDocumentField | 嵌入式文档类型字段,可以嵌套其他文档类型 |
| SequenceField | 自动产生一个数列、 递增的 |
2. 模型定义
2.1 普通模型定义
from mongoengine import Document, StringField, IntField
class User(Document):
name = StringField(required=True,unique=True) # 字符型字段name,必选
age = IntField(default=0) # 整数型字段age,默认值为0
这里定义的模型User有两个字段name和age,对应的字段类型分别是字符串和整形,且通过参数设置了字段相关的属性。常见的一些属性有:default默认值、required是否可选、db_field集合中的字段名称、unique是否唯一、max_length最大长度、primary_key是否为主键、choices取值范围、validation合法检验等。
注意
这里定义的文档类User只有name和age两个字段,如果创建对象时想要扩充字段,例如u2 = User(name=‘张三’, addr=‘合肥’)则会报错FieldDoesNotExist,想要支持动态新增字段,则定义文档时,需要继承DynamicDocument类。
from mongoengine import DynamicDocument, StringField, IntField
class User(DynamicDocument): # 这里如果继承的是Document,则声明对象时,只能对name和age两个字段赋值,不支持添加新的字段
name = StringField(required=True) # 字符型字段name,必选
age = IntField(default=0) # 整数型字段age,默认值为0
u1 = User(name='张三', addr='合肥',createDate=datetime.datetime.utcnow()) # 这里可以自定义新增字段
u1.save()
2.2 引用模型定义
有些时候文档中的部分字段是取自其他指定文档的字段(外链),我们在创建模型的时候可以通过创建引用关系。
class MarkModel(Document):
m_id = StringField(required=True, unique=True)
name = StringField(max_length=20, required=True)
createDate = DateTimeField(default=datetime.datetime.utcnow())
class TaskBatch(Document):
b_id = StringField(required=True, unique=True)
name = StringField(max_length=20)
createDate = DateTimeField(default=datetime.datetime.utcnow())
model_info = ReferenceField(MarkModel)
m1 = MarkModel.objects.create(m_id='abcde', name='作业机')
m2 = MarkModel.objects.create(m_id='abcdf', name='学习机')
t1 = TaskBatch.objects.create(b_id='bbcdf', name='批次1', model_info=m1)
res = TaskBatch.objects(name='批次1').first()
print(json.loads(res.to_json(), encoding='utf8'))
# 输出
{'_id': {'$oid': '640584f1f8684a202c3b4f62'}, 'b_id': 'bbcdf', 'name': '批次1', 'createDate': {'$date': 1678083313610}, 'model_info': {'$oid': '640584f1f8684a202c3b4f60'}}
2.3 嵌入式模型定义
class MarkModel(EmbeddedDocument): # 嵌入式文档类型 EmbeddedDocument ,不会生成集合,仅作数据校验
m_id = StringField(required=True, unique=True)
name = StringField(max_length=20, required=True)
createDate = DateTimeField(default=datetime.datetime.utcnow())
class TaskBatch(Document):
b_id = StringField(required=True, unique=True)
name = StringField(max_length=20)
createDate = DateTimeField(default=datetime.datetime.utcnow())
model_info = ListField(EmbeddedDocumentField(MarkModel)) # 引入嵌入式文档
m1 = MarkModel(m_id='abcdg', name='长语流')
m2 = MarkModel(m_id='abcdh', name='短语流')
t1 = TaskBatch.objects.create(b_id='bbcdg', name='批次2', model_info=[m1, m2]) # 对嵌入字段进行赋值
res = TaskBatch.objects(name='批次2').first()
print(json.loads(res.to_json(), encoding='utf8'))
# 输出
{'_id': {'$oid': '640589609f56006adea1d456'}, 'b_id': 'bbcdg', 'name': '批次2', 'createDate': {'$date': 1678084448255}, 'model_info': [{'m_id': 'abcdg', 'name': '长语流', 'createDate': {'$date': 1678084448254}}, {'m_id': 'abcdh', 'name': '短语流', 'createDate': {'$date': 1678084448254}}]}
四、增删改查文档
1. 新增文档
- **save()**方法:将对象保存到数据库中。
**save()**方法用于创建或更新一个已经存在的文档对象。如果文档对象存在,则执行更新操作,否则执行创建操作。
# 创建一个用户对象
user = User(name='Alice', age=25)
user.save() # 执行创建操作,插入一个新文档
# 更新一个用户对象
user.age = 26
user.save() # 执行更新操作,更新已有文档
- **create()**方法:创建一个新的对象,并将其保存到数据库中。
**create()方法用于创建一个新的文档对象,并将其插入到数据库中。与save()**方法不同,**create()**方法不能更新已有的文档对象。
# 创建一个新的用户对象
user = User.objects.create(name='Bob', age=30)
在创建文档对象时,**create()方法会自动执行save()方法,因此不需要再调用save()**方法。
2. 删除文档
**delete()**方法可以用来删除一个文档对象,如果对象不存在,则不进行任何操作。如果文档对象存在,则删除该对象。
# 删除一个用户对象
user = User.objects(name='Alice').first()
user.delete()
3. 更新文档
- **update()**方法:根据指定的查询条件,将文档的一个或多个字段更新为新的值,并返回影响的文档数。
- **modify()**方法:根据指定的查询条件,修改文档的一个或多个字段的值,并返回修改后的文档。
class User(Document):
nm = StringField(required=True, db_field='name', max_length=6) # 字符型字段name,必选
age = IntField(default=0) # 整数型字段age,默认值为0
addr = StringField(default='合肥') # 整数型字段age,默认值为0
createDate = DateTimeField(default=datetime.datetime.utcnow()) # 创建时间
friend_info = ListField()
edu_info = DictField()
User(nm='张3', age=13).save()
User(nm='张4', age=13).save()
User(nm='李4', age=18).save()
User(nm='李4', age=19).save()
res=User.objects(nm__startswith='张').update(set__age=12) # 批量对张姓同学进行年龄更新
print(res) # 2
print(User.objects(nm__startswith='张').to_json())
print(User.objects(nm='李4').modify(age=17).to_json()) # 这里可以直接输出modify之后的文档
注意
使用update方法更新字段时要记得写关键字set (查了资料说是不写set则只更新对应字段,其他的字段会丢失,目前没发现此问题,建议加上set)
3. 查询文档
3.1 查询所有
res=User.objects
for r in res:
print(r.name)
3.2 带条件查询
res=User.objects(age=20)
for r in res:
print(r.name)
3.3 运算符查询
User.objects(age__lte=20) # 小于等于 ; age__lt 小于; age__gte 大于等于; age__gt 大于; age__ne 不等于;age__in在取值列表内 ...
3.4 字符串查询
User.objects(name__contains='alice') # 包含‘斯基’;icontains 包含(不区分大小写);startswith 以开头;istartswith 以开头(不区分大小写);endswith 以结尾;iendswith 以结尾(不区分大小写) ...
3.5 字典类型查询
class User(Document):
nm = StringField(required=True, db_field='name', max_length=6) # 字符型字段name,必选
age = IntField(default=0) # 整数型字段age,默认值为0
addr = StringField(default='合肥') # 整数型字段age,默认值为0
createDate = DateTimeField(default=datetime.datetime.utcnow()) # 创建时间
edu_info = DictField()
# 实例化对象
u1 = User.objects.create(nm='王二', edu_info={'xx': '第一小学', 'zx': '第三中学'})
# 查询
res = User.objects(edu_info__xx='第一小学').first() # 使用字段名称__字典key的方式查询,如果要查询中学则 edu_info__zx='第三中学'
3.6 查询列表
class Page(Document):
topics = ListField(DictField())
p1 = Page(topics=[{'t_id': '1', 'ocr': '第一题'}, {'t_id': '2', 'ocr': '第二题'}]).save()
p2 = Page(topics=[{'t_id': '2', 'ocr': '第二题'}, {'t_id': '3', 'ocr': '第三题'}]).save()
# 从所有文档中查询有topics列表中第1个对象的t_id等于'2'的文档
print(Page.objects(topics__0__t_id='2').to_json())
3.7 查询数量过滤
class Page(Document):
topics = ListField(DictField())
p1 = Page(topics=[{'t_id': '1', 'ocr': '第一题'}, {'t_id': '2', 'ocr': '第二题'}]).save()
p2 = Page(topics=[{'t_id': '2', 'ocr': '第二题'}, {'t_id': '3', 'ocr': '第三题'}]).save()
p3 = Page(topics=[{'t_id': '3', 'ocr': '第三题'}, {'t_id': '4', 'ocr': '第4题'}]).save()
p4 = Page(topics=[{'t_id': '4', 'ocr': '第4题'}, {'t_id': '5', 'ocr': '第5题'}]).save()
p5 = Page(topics=[{'t_id': '5', 'ocr': '第5题'}, {'t_id': '6', 'ocr': '第6题'}]).save()
print(Page.objects.skip(2).limit(3).to_json()) # 限制查询结果取第3-5条
3.8 排序
class Page(Document):
p_id = SequenceField() # 序列计数器,自增长
topics = ListField(DictField())
createDate = DateTimeField(default=datetime.datetime.utcnow()) # 创建时间
Page.objects.delete()
p1 = Page(topics=[{'t_id': '1', 'ocr': '第一题'}, {'t_id': '2', 'ocr': '第二题'}]).save()
p2 = Page(topics=[{'t_id': '2', 'ocr': '第二题'}, {'t_id': '3', 'ocr': '第三题'}]).save()
p3 = Page(topics=[{'t_id': '3', 'ocr': '第三题'}, {'t_id': '4', 'ocr': '第4题'}]).save()
p4 = Page(topics=[{'t_id': '4', 'ocr': '第4题'}, {'t_id': '5', 'ocr': '第5题'}]).save()
p5 = Page(topics=[{'t_id': '5', 'ocr': '第5题'}, {'t_id': '6', 'ocr': '第6题'}]).save()
print(Page.objects().order_by('-p_id').first().to_json()) # 使用order_by方法进行排序
如果要对多个字段进行排序可以使用order_by(‘p_id’,‘-createTime’)传入多个字段。
3.9 组合查询
组合查询(多条件查询)需要引入Q方法
from mongoengine import connect, Document, StringField, DateTimeField, ListField, SequenceField, Q
import datetime
connect(host='mongodb://admin:[email protected]:27017/test_db')
class Page(Document):
p_id = SequenceField() # 序列计数器,自增长
topics = ListField(DictField())
createDate = DateTimeField(default=datetime.datetime.utcnow()) # 创建时间
# Page.objects.delete()
p1 = Page(topics=[{'t_id': '1', 'ocr': '第一题'}, {'t_id': '2', 'ocr': '第二题'}]).save()
p2 = Page(topics=[{'t_id': '2', 'ocr': '第二题'}, {'t_id': '3', 'ocr': '第三题'}]).save()
p3 = Page(topics=[{'t_id': '3', 'ocr': '第三题'}, {'t_id': '4', 'ocr': '第4题'}]).save()
p4 = Page(topics=[{'t_id': '4', 'ocr': '第4题'}, {'t_id': '5', 'ocr': '第5题'}]).save()
p5 = Page(topics=[{'t_id': '5', 'ocr': '第5题'}, {'t_id': '6', 'ocr': '第6题'}]).save()
print(Page.objects(Q(topics__0__t_id='2') & Q(p_id__lt=5)).to_json())
这里的Q(topics__0__t_id=‘2’) & Q(p_id__lt=5)代表的是topics列表中的第0个对象的t_id为‘2’且p_id小于5,支持且(&)、或(|)两种查询方式。
3.10 聚合查询
先造一批测试数据
class User(Document):
name = StringField()
age = IntField()
gender = StringField(choices=['male', 'female'])
addr = StringField(choices=['合肥', '南京', '上海'])
User.objects.delete()
for i in range(20):
User(name='张' + str(i), age=random.choice([_ for _ in range(18, 25)]),
gender=random.choice(['male', 'female']),addr=random.choice(['合肥', '南京', '上海'])).save()
创建的数据为:
查询 年龄大于等于21岁、性别男的用户数,以地址聚类:
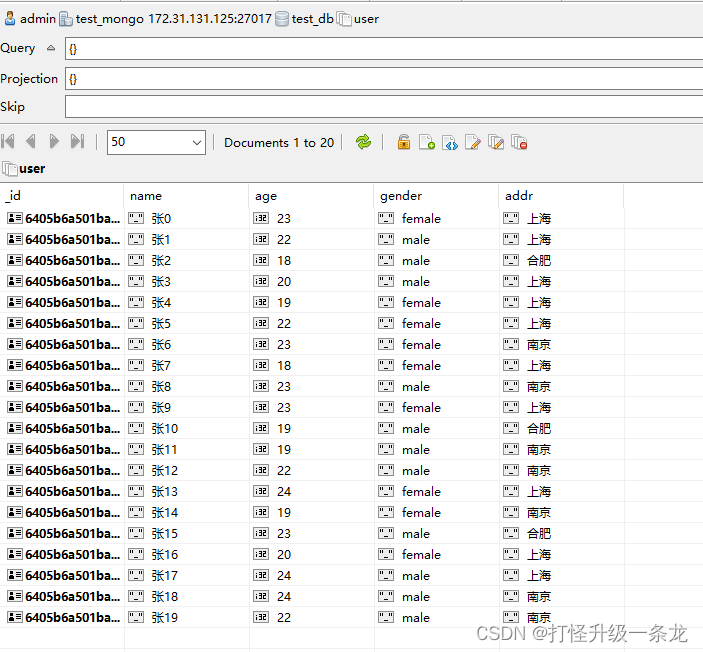
result = User.objects.aggregate(
{'$match': {'age': {'$gte': 21}, 'gender': 'male'}},
{'$group': {'_id': {'addr': '$addr'}, 'total': {'$sum': 1}}},
{'$sort': {'total': -1}}
)
for i in result:
print(i)
# 输出
{'_id': {'addr': '南京'}, 'total': 4}
{'_id': {'addr': '上海'}, 'total': 2}
{'_id': {'addr': '合肥'}, 'total': 1}
五、其他补充
1、上下文管理器
在日常使用中可能会存在多个数据库中有相同的集合,或者多个相同数据结构的集合在一个数据库下只是名称不同。我们如果想要查询不同的集合或数据库,需要来回切换,比较耗时。为了方便对查询数据库和查询集合进行切换,mongoengine提供了switch_db和switch_collection,再结合上下文管理器,我们可以狠便捷的进行数据库或集合的切换。
class TaskResult(Document):
id=
name=
...
task_id_li=['104008B94A014D879B7AE02601200B18','1EF14CFEFD93406E9D1FBE85FA617832','583C908B86F547D99BBBE8CF479F0B5F']
for task_id in task_id_li:
with switch_collection(TaskResult, task_id) as TR: # 定义的模型类TaskResult切换到task_id对应的集合
TR.objects(batchId='xxxxxx')
# 退出with后默认使用指定的集合
pass
connect(host='mongodb://admin:[email protected]:27017/test_db',alias='db1')
connect(host='mongodb://admin:[email protected]:27017/test_db2',alias='db2')
class TaskResult(Document):
createDate = DateTimeField(default=datetime.datetime.utcnow())
markInfo=DictField()
meta = {
'db_alias': 'db1',
'collection': 'UserTask',
'ordering': ['-createDate'] # 按创建时间倒序
}
with switch_db(TaskResult, 'db2') as TR: # 把TaskResult默认使用的db1切换成db2
TR.objects(batchId='xxxxxx')
# 退出with后默认使用指定的集合
pass
2、查询优化
由于mongo是文档型数据库,有时存储的数据结构非常复杂,在数据量特别大的情况下,查询可能非常慢,这时候就需要我们优化查询方法,或者使用查询索引。
# 1.查询指定数量的结果
Page.objects.skip(2).limit(3).to_json()
# 2.查询的结果只获取文档的部分字段
Page.objects.only('name','age').to_json()
# 3.定义索引查询
# 暂时用不到,测试目前仅作查询使用,模型定义自动生成索引一般研发会定义好