一,概述
参考:
https://segmentfault.com/a/1190000008125359
二,编译和使用
1. 如何使能功能
CONFIG_MEMCG
=y 总开关 obj-$(CONFIG_MEMCG) += memcontrol.o page_cgroup.o vmpressure.o
CONFIG_MEMCG_SWAP
=y 扩展功能,控制内核是否支持Swap Extension, 限制cgroup中所有进程所能使用的交换空间总量
CONFIG_MEMCG_SWAP_ENABLED
=y,
目前看没啥用处?涉及到内存压力的计算!
CONFIG_MEMCG_KMEM
=y限制cgroup中所有进程所能使用的内核内存总量及其它一些内核资源。其实限制内核内存就是限制当前cgroup所能使用的内核资源,比如进程的内核栈空间,socket所占用的内存空间等,通过限制内核内存,当内存吃紧时,可以阻止当前cgroup继续创建进程以及向内核申请分配更多的内核资源。但这块功能被使用的较少。
mkdir
/dev/memcg
0700 root system
mount cgroup none
/dev/memcg
memory
# app mem cgroups, used by activity manager, lmkd and zygote
mkdir
/dev/memcg/
apps
/ 0755 system system
# cgroup for system_server and surfaceflinger
mkdir
/dev/memcg/
system
0550 system system
三,如何控制操作
1. 节点含义
apps
system
cgroup.clone_children
cgroup.event_control 用于eventfd的接口, 实现OOM的通知,当OOM发生时,可以收到相关的事件
cgroup.procs
show list of processes,往cgroup中添加进程只要将进程号写入cgroup.procs
cgroup.sane_behavior
memory.failcnt 显示内存使用量达到限制值的次数
memory.force_empty 触发系统立即尽可能的回收当前cgroup中可以回收的内存
memory.
usage_in_bytes
显示当前已用的内存
memory.
limit_in_bytes
设置/显示当前限制的内存额度
memory.max_usage_in_bytes 历史内存最大使用量
memory.memsw.failcnt
show the number of memory+Swap hits limits
memory.memsw.limit_in_bytes
set/show
limit of memory+Swap usage
memory.memsw.max_usage_in_bytes
show max memory+Swap usage recorded
memory.
memsw.usage_in_bytes
show current usage for memory+Swap
memory.move_charge_at_immigrate 设置当进程移动到其他cgroup中时,它所占用的内存是否也随着移动过去
memory.oom_control 设置/显示oom controls相关的配置
memory.pressure_level 设置内存压力的通知事件,配合cgroup.event_control一起使用
memory.
soft_limit_in_bytes
设置/显示当前限制的内存软额度
memory.stat 显示当前cgroup的内存使用情况
memory.swappiness 设置和显示当前的swappiness
memory.use_hierarchy 设置/显示是否将子cgroup的内存使用情况统计到当前cgroup里面
notify_on_release
release_agent
tasks
attach a task(thread) and show list of threads
2. 控制说明
2.1 memory.
limit_in_bytes
一旦设置了内存限制memory.
limit_in_bytes,将立即生效,并且当物理内存使用量达到limit的时候,memory.
failcnt的内容会加1,但这时进程不一定就会被kill掉,内核会尽量将物理内存中的数据移到swap空间上去,如果实在是没办法移动了(设置的limit过小,或者swap空间不足),默认情况下,就会kill掉cgroup里面继续申请内存的进程。
2.2 memory.
oom_control
当物理内存达到上限后,系统的默认行为是kill掉cgroup中继续申请内存的进程,那么怎么控制这样的行为呢?答案是配置memory.
oom_control
这个文件里面包含了一个控制是否为当前cgroup启动OOM-killer的标识。如果写0到这个文件,将启动OOM-killer,当内核无法给进程分配足够的内存时,将会直接kill掉该进程;如果写1到这个文件,表示不启动OOM-killer,当内核无法给进程分配足够的内存时,将会暂停该进程直到有空余的内存之后再继续运行;同时,memory.oom_control还包含一个只读的under_oom字段,用来表示当前是否已经进入oom状态,也即是否有进程被暂停了。
/dev/memcg/apps # cat memory.oom_control
oom_kill_disable 0
under_oom 0
注意:root cgroup的oom killer是不能被禁用的
2.3 memory.
force_empty
当向memory.force_empty文件写入0时(echo 0 > memory.
force_empty),将会立即触发系统尽可能的回收该cgroup占用的内存。该功能主要使用场景是移除cgroup前(cgroup中没有进程),先执行该命令,可以尽可能的回收该cgropu占用的内存,这样迁移内存的占用数据到父cgroup或者root cgroup时会快些。
2.4 memory.
swappiness
该文件的值默认和全局的swappiness(/proc/sys/vm/swappiness)一样,修改该文件只对当前cgroup生效,其功能和全局的swappiness一样.有一点和全局的swappiness不同,那就是如果
这个文件被设置成0,就算系统配置的有交换空间,当前cgroup也不会使用交换空间。
2.5 memory.
soft_limit_in_bytes
有了hard limit(memory.
limit_in_bytes),为什么还要soft limit呢?hard limit是一个硬性标准,绝对不能超过这个值,而soft limit可以被超越,既然能被超越,要这个配置还有啥用?先看看它的特点
- 当系统内存充裕时,soft limit不起任何作用
- 当系统内存吃紧时,系统会尽量的将cgroup的内存限制在soft limit值之下(内核会尽量,但不100%保证)
从它的特点可以看出,它的作用主要发生在系统内存吃紧时,如果没有soft limit,那么所有的cgroup一起竞争内存资源,占用内存多的cgroup不会让着内存占用少的cgroup,这样就会出现某些cgroup内存饥饿的情况。如果配置了soft limit,那么当系统内存吃紧时,系统会让超过soft limit的cgroup释放出超过soft limit的那部分内存(有可能更多),这样其它cgroup就有了更多的机会分配到内存。
从上面的分析看出,这其实是系统内存不足时的一种妥协机制,给次等重要的进程设置soft limit,当系统内存吃紧时,把机会让给其它重要的进程。
注意: 当系统内存吃紧且cgroup达到soft limit时,系统为了把当前cgroup的内存使用量控制在soft limit下,在收到当前cgroup新的内存分配请求时,就会触发回收内存操作,所以一旦到达这个状态,就会频繁的触发对当前cgroup的内存回收操作,会严重影响当前cgroup的性能。
2.6 memory.
pressure_level
这个文件主要用
来监控当前cgroup的内存压力,当内存压力大时(即已使用内存快达到设置的限额),在分配内存之前需要先回收部分内存,从而影响内存分配速度,影响性能,而通过监控当前cgroup的内存压力,可以在有压力的时候采取一定的行动来改善当前cgroup的性能,比如关闭当前cgroup中不重要的服务等。目前有三种压力水平:
- low 意味着系统在开始为当前cgroup分配内存之前,需要先回收内存中的数据了,这时候回收的是在磁盘上有对应文件的内存数据。
- medium 意味着系统已经开始频繁为当前cgroup使用交换空间了。
- critical 快撑不住了,系统随时有可能kill掉cgroup中的进程。
如何配置相关的监听事件呢?和memory.oom_control类似,大概步骤如下:
- 利用函数eventfd(2)创建一个event_fd
- 打开文件memory.pressure_level,得到pressure_level_fd
- 往cgroup.event_control中写入这么一串:<event_fd> <pressure_level_fd> <level>
- 然后通过读event_fd得到通知
注意: 多个level可能要创建多个event_fd,好像没有办法共用一个(本人没有测试过)
2.7 memory
thresholds
我们可以通过cgroup的事件通知机制来实现对内存的监控,当内存使用量穿过(变得高于或者低于)我们设置的值时,就会收到通知。使用方法和memory.oom_control类似,大概步骤如下:
- 利用函数eventfd(2)创建一个event_fd
- 打开文件memory.usage_in_bytes,得到usage_in_bytes_fd
- 往cgroup.event_control中写入这么一串:<event_fd> <usage_in_bytes_fd> <threshold>
- 然后通过读event_fd得到通知
2.8 memory.stat
这个文件包含的统计项比较细,需要一些内核的内存管理知识才能看懂
cache 34369536
rss 1937408
rss_huge 0
mapped_file 10792960
writeback 0
swap 12288
pgpgin 40100
pgpgout 31236
pgfault 15948
pgmajfault 44
inactive_anon 1548288
active_anon 966656
inactive_file 12730368
active_file 19271680
unevictable 1789952
hierarchical_memory_limit 18446744073709551615
hierarchical_memsw_limit 18446744073709551615
total_cache 558436352
total_rss 179347456
total_rss_huge 0
total_mapped_file 266674176
total_writeback 0
total_swap 5857280
total_pgpgin 1723421
total_pgpgout 1543298
total_pgfault 2141583
total_pgmajfault 4166
total_inactive_anon 109481984
total_active_anon 71380992
total_inactive_file 219193344
total_active_file 335708160
total_unevictable 2015232
四,Android源码分析
1. @Service.cpp (system\core\init)
bool Service::Start() { 启动init.rc中各native process service, 则添加到dev/memcg/apps/uid_xxxx/pid_xxxx 的mem cgroup中????
errno = -createProcessGroup(uid_, pid_);
if (errno != 0) {
PLOG(ERROR) << "createProcessGroup(" << uid_ << ", " << pid_ << ") failed for service '"
<< name_ << "'";
} else {
if (swappiness_ != -1) {
if (!setProcessGroupSwappiness(uid_, pid_, swappiness_)) {
PLOG(ERROR) << "setProcessGroupSwappiness failed";
}
}
if (soft_limit_in_bytes_ != -1) {
if (!setProcessGroupSoftLimit(uid_, pid_, soft_limit_in_bytes_)) {
PLOG(ERROR) << "setProcessGroupSoftLimit failed";
}
}
if (limit_in_bytes_ != -1) {
if (!setProcessGroupLimit(uid_, pid_, limit_in_bytes_)) {
PLOG(ERROR) << "setProcessGroupLimit failed";
}
}
}
}
2. @com_android_internal_os_Zygote.cpp (frameworks\base\core\jni)
static jint com_android_internal_os_Zygote_nativeForkAndSpecialize(
JNIEnv* env, jclass, jint uid, jint gid,
{
return ForkAndSpecializeCommon(env, uid, gid, gids, . true, ..); //is_system_server=false
}
static jint com_android_internal_os_Zygote_nativeForkSystemServer( //只有system_server是用该函数fork的,所以dev/memcg/system/tasks中包含的全是其线程
JNIEnv* env, jclass, uid_t uid, gid_t gid, jintArray gids,
jint debug_flags, jobjectArray rlimits, jlong permittedCapabilities,
jlong effectiveCapabilities) {
pid_t pid = ForkAndSpecializeCommon(env, uid, gid, gids,
debug_flags, rlimits,
permittedCapabilities, effectiveCapabilities,
MOUNT_EXTERNAL_DEFAULT, NULL, NULL, true, NULL,
NULL, NULL, NULL); //is_system_server= true
if (pid > 0) {
// The zygote process checks whether the child process has died or not.
ALOGI("System server process %d has been created", pid);
gSystemServerPid = pid;
// There is a slight window that the system server process has crashed
// but it went unnoticed because we haven't published its pid yet. So
// we recheck here just to make sure that all is well.
int status;
if (waitpid(pid, &status, WNOHANG) == pid) {
ALOGE("System server process %d has died. Restarting Zygote!", pid);
RuntimeAbort(env, __LINE__, "System server process has died. Restarting Zygote!");
}
// Assign system_server to the correct memory cgroup.
if (!WriteStringToFile(StringPrintf("%d", pid), "/dev/memcg/system/tasks")) { 把运行与jvm中的system process,分配到memcg的dev/memcg/system/tasks
ALOGE("couldn't write %d to /dev/memcg/system/tasks", pid);
}
}
return pid;
}
static pid_t ForkAndSpecializeCommon(JNIEnv* env, uid_t uid, gid_t gid, ...)
{
if (!is_system_server) { //启动于各JVM的process,则添加到dev/memcg/apps/uid_xxxx/pid_xxxx 的mem cgroup中
int rc = createProcessGroup(uid, getpid());
}
3. @Processgroup.cpp (system\core\libprocessgroup)
int createProcessGroup(uid_t uid, int initialPid)
{
char path[PROCESSGROUP_MAX_PATH_LEN] = {0};
convertUidToPath(path, sizeof(path), uid);
if (!mkdirAndChown(path, 0750, AID_SYSTEM, AID_SYSTEM)) { 创建/dev/memcg/apps/uid_xxxx/目录
PLOG(ERROR) << "Failed to make and chown " << path;
return -errno;
}
convertUidPidToPath(path, sizeof(path), uid, initialPid);
if (!mkdirAndChown(path, 0750, AID_SYSTEM, AID_SYSTEM)) {创建/dev/memcg/apps/uid_xxxx/pid_xxxx/目录
PLOG(ERROR) << "Failed to make and chown " << path;
return -errno;
}
strlcat(path, PROCESSGROUP_CGROUP_PROCS_FILE, sizeof(path)); 写入当前的pid到/dev/memcg/apps/uid_xxxx/pid_xxxx/cgroup.procs
int ret = 0;
if (!WriteStringToFile(std::to_string(initialPid), path)) {
ret = -errno;
PLOG(ERROR) << "Failed to write '" << initialPid << "' to " << path;
}
return ret;
}
static bool setProcessGroupValue(uid_t uid, int pid, const char* fileName, int64_t value) {
char path[PROCESSGROUP_MAX_PATH_LEN] = {0};
if (strcmp(getCgroupRootPath(), MEM_CGROUP_PATH)) { #define MEM_CGROUP_PATH "/dev/memcg/apps"
PLOG(ERROR) << "Memcg is not mounted." << path;
return false;
}
convertUidPidToPath(path, sizeof(path), uid, pid);
strlcat(path, fileName, sizeof(path));
if (!WriteStringToFile(std::to_string(value), path)) {
PLOG(ERROR) << "Failed to write '" << value << "' to " << path;
return false;
}
return true;
}
static int convertUidPidToPath(char *path, size_t size, uid_t uid, int pid)
{ 返回/dev/memcg/apps/uid_xxxx/pid_xxx
return snprintf(path, size, "%s/%s%d/%s%d",
getCgroupRootPath(),
PROCESSGROUP_UID_PREFIX, //#define PROCESSGROUP_UID_PREFIX "uid_"
uid,
PROCESSGROUP_PID_PREFIX, //#define PROCESSGROUP_PID_PREFIX "pid_"
pid);
}
4. @ProcessList.java (frameworks\base\services\core\java\com\android\server\am)
通过socket "lmkd"发命令给lmkd进程, 由此可知都是JVM的进程才会被 lmkd native进程管理控制!!!
applyDisplaySize
->updateOomLevels
private void updateOomLevels(int displayWidth, int displayHeight, boolean write) { 目前根据屏幕尺寸设置的LMK minfree&adj 会被后期的设置覆盖掉
...
if (write) {
ByteBuffer buf = ByteBuffer.allocate(4 * (2*mOomAdj.length + 1));
buf.putInt(LMK_TARGET);
for (int i=0; i<mOomAdj.length; i++) {
buf.putInt((mOomMinFree[i]*1024)/PAGE_SIZE);
buf.putInt(mOomAdj[i]);
}
writeLmkd(buf);
SystemProperties.set("sys.sysctl.extra_free_kbytes", Integer.toString(reserve));
}
}
public static final void setOomAdj(int pid, int uid, int amt) {
if (amt == UNKNOWN_ADJ)
return;
long start = SystemClock.elapsedRealtime();
ByteBuffer buf = ByteBuffer.allocate(4 * 4);
buf.putInt(LMK_PROCPRIO);
buf.putInt(pid);
buf.putInt(uid);
buf.putInt(amt);
writeLmkd(buf);
long now = SystemClock.elapsedRealtime();
if ((now-start) > 250) {
Slog.w("ActivityManager", "SLOW OOM ADJ: " + (now-start) + "ms for pid " + pid
+ " = " + amt);
}
}
public static final void remove(int pid) {
ByteBuffer buf = ByteBuffer.allocate(4 * 2);
buf.putInt(LMK_PROCREMOVE);
buf.putInt(pid);
writeLmkd(buf);
}
5. @ActivityManagerService.java (frameworks\base\services\core\java\com\android\server\am)
applyOomAdjLocked
->ProcessList.setOomAdj(app.pid, app.uid, app.curAdj);
handleAppDiedLocked 只能监控java process的死亡
cleanUpApplicationRecordLocked AMS正常清理流程
->ProcessList.remove(app.pid);
小结:
1. 目前Memcg只处理了,init.rc中启动的service进程 和所有JVM进程。
2. init.rc 中的进程全都会设置到dev/memcg/apps/uid_xxxx/pid_xxxx中
3. JVM运行的系统服务进程 system_server, 会设置到dev/memcg/system/tasks中
4. JVM运行的一般进程会设置到dev/memcg/apps/uid_xxxx/pid_xxxx中
5. 其余没有处理的进程会设置到dev/memcg/中
五,native源码分析
1. Lmkd.c (system\core\lmkd)
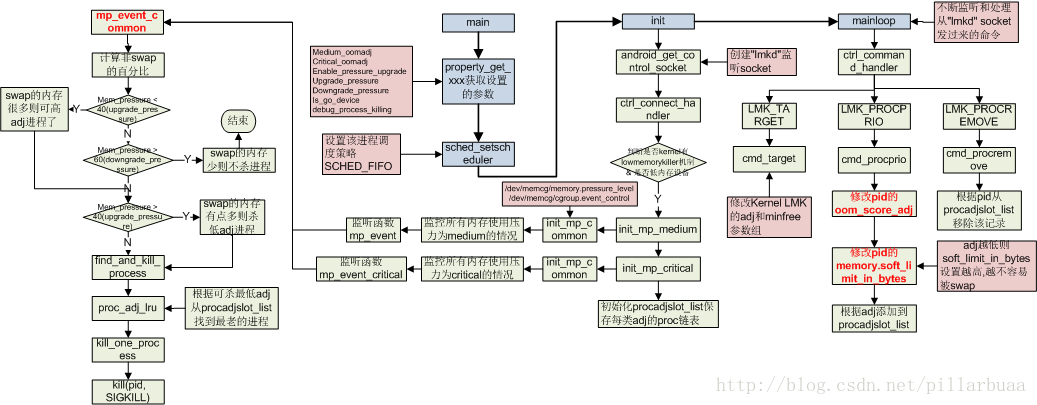
int main(int argc __unused, char **argv __unused) {
struct sched_param param = {
.sched_priority = 1,
};
//读取配置参数
medium_oomadj = property_get_int32("ro.lmk.medium", 800);
critical_oomadj = property_get_int32("ro.lmk.critical", 0);
debug_process_killing = property_get_bool("ro.lmk.debug", false);
enable_pressure_upgrade = property_get_bool("ro.lmk.critical_upgrade", false);
upgrade_pressure = (int64_t)property_get_int32("ro.lmk.upgrade_pressure", 50);
downgrade_pressure = (int64_t)property_get_int32("ro.lmk.downgrade_pressure", 60);
is_go_device = property_get_bool("ro.config.low_ram", false);
mlockall(MCL_FUTURE);
sched_setscheduler(0, SCHED_FIFO, ¶m); //实时运行高优先级
if (!init())
mainloop();
ALOGI("exiting");
return 0;
}| SCHED_NORMAL | (也叫SCHED_OTHER)用于普通进程,通过CFS调度器实现。SCHED_BATCH用于非交互的处理器消耗型进程。SCHED_IDLE是在系统负载很低时使用 | CFS |
| SCHED_BATCH | SCHED_NORMAL普通进程策略的分化版本。采用分时策略,根据动态优先级(可用nice()API设置),分配CPU运算资源。注意:这类进程比上述两类实时进程优先级低,换言之,在有实时进程存在时,实时进程优先调度。但针对吞吐量优化, 除了不能抢占外与常规任务一样,允许任务运行更长时间,更好地使用高速缓存,适合于成批处理的工作 | CFS |
| SCHED_IDLE | 优先级最低,在系统空闲时才跑这类进程(如利用闲散计算机资源跑地外文明搜索,蛋白质结构分析等任务,是此调度策略的适用者) | CFS-IDLE |
| SCHED_FIFO | 先入先出调度算法(实时调度策略),相同优先级的任务先到先服务,高优先级的任务可以抢占低优先级的任务 | RT |
| SCHED_RR | 轮流调度算法(实时调度策略),后者提供 Roound-Robin 语义,采用时间片,相同优先级的任务当用完时间片会被放到队列尾部,以保证公平性,同样,高优先级的任务可以抢占低优先级的任务。不同要求的实时任务可以根据需要用sched_setscheduler() API设置策略 | RT |
| SCHED_DEADLINE | 新支持的实时进程调度策略,针对突发型计算,且对延迟和完成时间高度敏感的任务适用。基于Earliest Deadline First (EDF) 调度算法 | DL |
linux内核实现的6种调度策略, 前面三种策略使用的是cfs调度器类,后面两种使用rt调度器类, 最后一个使用DL调度器类
static int init(void) {
struct epoll_event epev;
int i;
int ret;
//获取页面size
page_k = sysconf(_SC_PAGESIZE);
if (page_k == -1)
page_k = PAGE_SIZE;
page_k /= 1024;
epollfd = epoll_create(MAX_EPOLL_EVENTS);
if (epollfd == -1) {
ALOGE("epoll_create failed (errno=%d)", errno);
return -1;
}
ctrl_lfd = android_get_control_socket("lmkd"); //创建Android 本地socket
if (ctrl_lfd < 0) {
ALOGE("get lmkd control socket failed");
return -1;
}
ret = listen(ctrl_lfd, 1); //开始监听连接请求,但只允许同时响应一个连接请求
if (ret < 0) {
ALOGE("lmkd control socket listen failed (errno=%d)", errno);
return -1;
}
epev.events = EPOLLIN;
epev.data.ptr = (void *)ctrl_connect_handler;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, ctrl_lfd, &epev) == -1) { //设置socket监听到连接请求的处理函数ctrl_connect_handler
ALOGE("epoll_ctl for lmkd control socket failed (errno=%d)", errno);
return -1;
}
maxevents++;
has_inkernel_module = !access(INKERNEL_MINFREE_PATH, W_OK); //has_inkernel_module = true, kernel有LMK对应的节点"/sys/module/lowmemorykiller/parameters/minfree"
use_inkernel_interface = has_inkernel_module && !is_go_device;//is_go_device=true, 设置了ro.config.low_ram=true,为低内存终端, 所以use_inkernel_interface = false
if (use_inkernel_interface) {
ALOGI("Using in-kernel low memory killer interface");
} else {
ret = init_mp_medium(); //设置系统已经开始频繁为当前 “根cgroup” 使用交换空间时的监听
ret |= init_mp_critical(); //设置系统随时有可能kill掉该“根cgroup”中的进程时 的监听
if (ret)
ALOGE("Kernel does not support memory pressure events or in-kernel low memory killer");
}
for (i = 0; i <= ADJTOSLOT(OOM_SCORE_ADJ_MAX); i++) {
procadjslot_list[i].next = &procadjslot_list[i];
procadjslot_list[i].prev = &procadjslot_list[i];
}
return 0;
}
init_mp_medium和int init_mp_critical都是调用init_mp_common
static int init_mp_common(char *levelstr, void *event_handler, bool is_critical)
{
int mpfd;
int evfd;
int evctlfd;
char buf[256];
struct epoll_event epev;
int ret;
int mpevfd_index = is_critical ? CRITICAL_INDEX : MEDIUM_INDEX;
//打开/dev/memcg/memory.pressure_level"的文件句柄
mpfd = open(MEMCG_SYSFS_PATH "memory.pressure_level", O_RDONLY | O_CLOEXEC);
if (mpfd < 0) {
ALOGI("No kernel memory.pressure_level support (errno=%d)", errno);
goto err_open_mpfd;
}
//打开/dev/memcg/cgroup.event_control的文件句柄
evctlfd = open(MEMCG_SYSFS_PATH "cgroup.event_control", O_WRONLY | O_CLOEXEC);
if (evctlfd < 0) {
ALOGI("No kernel memory cgroup event control (errno=%d)", errno);
goto err_open_evctlfd;
}
evfd = eventfd(0, EFD_NONBLOCK | EFD_CLOEXEC);
if (evfd < 0) {
ALOGE("eventfd failed for level %s; errno=%d", levelstr, errno);
goto err_eventfd;
}
ret = snprintf(buf, sizeof(buf), "%d %d %s", evfd, mpfd, levelstr); //组合控制命令 levelstr = "medium" 或者 “critical”
if (ret >= (ssize_t)sizeof(buf)) {
ALOGE("cgroup.event_control line overflow for level %s", levelstr);
goto err;
}
ret = write(evctlfd, buf, strlen(buf) + 1); // 写入控制监听命令,通过读evctlfd得到通知
if (ret == -1) {
ALOGE("cgroup.event_control write failed for level %s; errno=%d",
levelstr, errno);
goto err;
}
epev.events = EPOLLIN;
epev.data.ptr = event_handler;
ret = epoll_ctl(epollfd, EPOLL_CTL_ADD, evfd, &epev); //设置evfd的监听回调函数
if (ret == -1) {
ALOGE("epoll_ctl for level %s failed; errno=%d", levelstr, errno);
goto err;
}
maxevents++;
mpevfd[mpevfd_index] = evfd;
return 0;
}
mp_event和mp_event_critical都是调用mp_event_common
static void mp_event_common(bool is_critical) {
int ret;
unsigned long long evcount;
int index = is_critical ? CRITICAL_INDEX : MEDIUM_INDEX;
int64_t mem_usage, memsw_usage;
int64_t mem_pressure;
ret = read(mpevfd[index], &evcount, sizeof(evcount));
if (ret < 0)
ALOGE("Error reading memory pressure event fd; errno=%d",
errno);
mem_usage = get_memory_usage(MEMCG_MEMORY_USAGE); 获取"/dev/memcg/memory.usage_in_bytes"当前系统已用的内存
memsw_usage = get_memory_usage(MEMCG_MEMORYSW_USAGE); 获取"/dev/memcg/memory.memsw.usage_in_bytes"当前系统已用的内存 + swap使用的内存
if (memsw_usage < 0 || mem_usage < 0) { 获取内存使用值则异常直接开杀
find_and_kill_process(is_critical);
return;
}
// Calculate percent for swappinness. 计算当前使用非SWAP内存占比
mem_pressure = (mem_usage * 100) / memsw_usage;
if (enable_pressure_upgrade && !is_critical) { //enable_pressure_upgrade = false (default)
// We are swapping too much.
if (mem_pressure < upgrade_pressure) { //upgrade_pressure = 40, 如果swap的内存过多,则内存压力大,需要杀进程
ALOGI("Event upgraded to critical.");
is_critical = true;
}
}
// If the pressure is larger than downgrade_pressure lmk will not
// kill any process, since enough memory is available.
if (mem_pressure > downgrade_pressure) { //downgrade_pressure = 60, 说明内存swap的较少,压力不大,则不处理
if (debug_process_killing) {
ALOGI("Ignore %s memory pressure", is_critical ? "critical" : "medium");
}
return;
} else if (is_critical && mem_pressure > upgrade_pressure) {//upgrade_pressure = 40, 如果触发的是内存紧张的事件,但同时swap的内存不是很多,则降级处理
if (debug_process_killing) {
ALOGI("Downgrade critical memory pressure");
}
// Downgrade event to medium, since enough memory available.
is_critical = false;
}
if (find_and_kill_process(is_critical) == 0) {
if (debug_process_killing) {
ALOGI("Nothing to kill");
}
}
}
static int find_and_kill_process(bool is_critical) {
int i;
int killed_size = 0;
int min_score_adj = is_critical ? critical_oomadj : medium_oomadj; //critical_oomadj = 0, medium_oomadj = 800, 这个设置很关键,有可能导致无进程可杀
for (i = OOM_SCORE_ADJ_MAX; i >= min_score_adj; i--) { //OOM_SCORE_ADJ_MAX = 1000, 从最高的adj开始查找可以被杀的进程
struct proc *procp;
retry:
procp = proc_adj_lru(i); //从procadjslot_list对应的adj链表中获取最早添加的进程信息,也就是尽量杀最老的进程
if (procp) {
killed_size = kill_one_process(procp, min_score_adj, is_critical);
if (killed_size < 0) {
goto retry;
} else {
return killed_size;
}
}
}
return 0;
}
static int kill_one_process(struct proc* procp, int min_score_adj, bool is_critical) {
int pid = procp->pid;
uid_t uid = procp->uid;
char *taskname;
int tasksize;
int r;
taskname = proc_get_name(pid); //从/proc/%d/cmdline 获取进程名字,获取失败则表明该进程已经不存在了
if (!taskname) {
pid_remove(pid);
return -1;
}
tasksize = proc_get_size(pid); //从/proc/%d/statm获取进程实际占用的物理内存大小
if (tasksize <= 0) {
pid_remove(pid);
return -1;
}
ALOGI(
"Killing '%s' (%d), uid %d, adj %d\n"
" to free %ldkB because system is under %s memory pressure oom_adj %d\n",
taskname, pid, uid, procp->oomadj, tasksize * page_k, is_critical ? "critical" : "medium",
min_score_adj);
r = kill(pid, SIGKILL); //杀进程
pid_remove(pid);
if (r) {
ALOGE("kill(%d): errno=%d", procp->pid, errno);
return -1;
} else {
return tasksize;
}
1. 如果memcg打开,LMKD会根据当前adj的情况修改每个
dev/memcg/apps/uid_xxxx/pid_xxxx的memory.soft_limit_in_bytes
,
这个值会触发啥时候swap。该值越低,说明越容易被触发swap。
2. 如果还使能了ro.config.low_ram低端设备,则会监听整个系统内存的使用情况(目前监听media和critical), 然后根据最小adj,查找最老的一个进程杀之。
3. 原有功能是能设置kernel lowmemorykiller 的adj和minfree参数,用于控制kernel的lowmemorykiller的行为。
六,kernel源码分析
1. @Vmpressure.c (mm)
/*
* These thresholds are used when we account memory pressure through
* scanned/reclaimed ratio. The current values were chosen empirically. In
* essence, they are percents: the higher the value, the more number
* unsuccessful reclaims there were.
*/
unsigned int vmpressure_level_med = 60;
unsigned int vmpressure_level_critical = 95;
2. @Memcontrol.c (mm)
struct cgroup_subsys memory_cgrp_subsys = {
.css_alloc = mem_cgroup_css_alloc,
.css_online = mem_cgroup_css_online,
.css_offline = mem_cgroup_css_offline,
.css_free = mem_cgroup_css_free,
.css_reset = mem_cgroup_css_reset,
.can_attach = mem_cgroup_can_attach,
.cancel_attach = mem_cgroup_cancel_attach,
.attach = mem_cgroup_move_task,
.bind = mem_cgroup_bind,
.legacy_cftypes = mem_cgroup_files,
.early_init = 0,
};
static struct cftype mem_cgroup_files[] = {
{
.name = "cgroup.event_control", /* XXX: for compat */
.write = memcg_write_event_control,
.flags = CFTYPE_NO_PREFIX,
.mode = S_IWUGO,
},
{
.name = "pressure_level",
},
}
static ssize_t memcg_write_event_control(struct kernfs_open_file *of,
char *buf, size_t nbytes, loff_t off)
{
//获取传入的参数:<evfd> <mpfd> <levelstr>
efd = simple_strtoul(buf, &endp, 10); //<evfd>
cfd = simple_strtoul(buf, &endp, 10); //<mpfd>
buf = endp + 1; //<levelstr>
efile = fdget(efd);//打开传入的eventfd文件路径句柄
event->eventfd = eventfd_ctx_fileget(efile.file);
cfile = fdget(cfd);//打开传入的"memory.pressure_level"文件路径句柄
name = cfile.file->f_dentry->d_name.name;
else if (!strcmp(name, "memory.pressure_level")) {
event->register_event = vmpressure_register_event;
event->unregister_event = vmpressure_unregister_event;
}
ret = event->register_event(memcg, event->eventfd, buf);
}
3. @Vmpressure.c (mm)
// Bind vmpressure notifications to an eventfd
int vmpressure_register_event(struct mem_cgroup *memcg,
struct eventfd_ctx *eventfd, const char *args)
{
struct vmpressure *vmpr = memcg_to_vmpressure(memcg);
struct vmpressure_event *ev;
int level;
//根据名称找到等级index, 只能是"low", "medium", "critical"
for (level = 0; level < VMPRESSURE_NUM_LEVELS; level++) {
if (!strcmp(vmpressure_str_levels[level], args))
break;
}
ev = kzalloc(sizeof(*ev), GFP_KERNEL);
ev->efd = eventfd; //上层传入的epoll文件句柄
ev->level = level;
list_add(&ev->node, &vmpr->events); //添加到监听队列中
}
如何触发内存压力检测?
void vmpressure(gfp_t gfp, struct mem_cgroup *memcg,
unsigned long scanned, unsigned long reclaimed)
{
schedule_work(&vmpr->work); //调用vmpressure_work_fn
}
static void vmpressure_work_fn(struct work_struct *work)
->vmpressure_event(vmpr, scanned, reclaimed)
static bool vmpressure_event(struct vmpressure *vmpr,
unsigned long scanned, unsigned long reclaimed)
{
level = vmpressure_calc_level(scanned, reclaimed);//计算当前VM内存压力情况
list_for_each_entry(ev, &vmpr->events, node) { //循环触发注册的监听epoll
if (level >= ev->level) {
eventfd_signal(ev->efd, 1); //往该epoll句柄中写数,增加1,触发上层的监听
signalled = true;
}
}
}
[email protected] (mm)
static bool shrink_zone(struct zone *zone, struct scan_control *sc)
{
do {
nr_reclaimed = sc->nr_reclaimed;
nr_scanned = sc->nr_scanned;
vmpressure(sc->gfp_mask, sc->target_mem_cgroup,
sc->nr_scanned - nr_scanned,
sc->nr_reclaimed - nr_reclaimed);
}while (should_continue_reclaim(zone, sc->nr_reclaimed - nr_reclaimed,
sc->nr_scanned - nr_scanned, sc));