引言
随着业务的发展和用户规模的增长,数据库往往会面临着存储容量不足、性能瓶颈等问题。为了解决这些问题,数据库扩展成为了一种常见的解决方案。在数据库扩展的实践中,有许多不同的策略和技术可供选择,其中包括水平拆分、垂直拆分、分布式数据库等。本文将探讨数据库扩展的各种方式及其适用场景,以及在实践中的一些经验和注意事项。
1. 数据库扩展的背景
随着互联网的迅速发展和各种应用的兴起,用户量和数据量呈现出爆炸式增长的趋势。传统的数据库往往难以应对如此庞大的数据量和高并发访问的挑战,因此数据库扩展成为了必然的选择。数据库扩展可以通过水平拆分和垂直拆分两种方式实现,以满足业务需求。
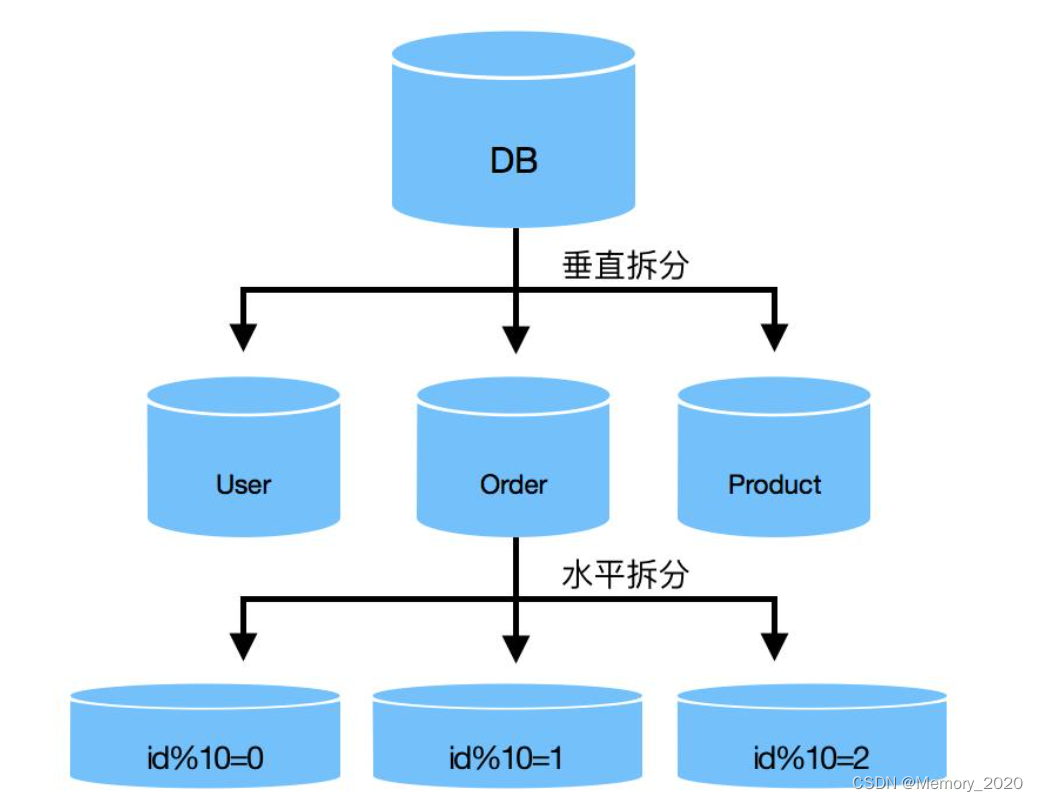
2. 水平拆分
水平拆分是将数据按照某种规则分散到多个数据库节点中,每个节点负责存储一部分数据。水平拆分的主要优势在于能够提高数据库的并发处理能力和扩展性。当数据量增长时,可以简单地增加数据库节点,从而实现线性的扩展。
2.1 水平拆分的策略
- 哈希分片:将数据的关键字段(如用户ID、订单ID等)进行哈希运算,然后根据哈希值将数据分散到不同的数据库节点中。
- 范围分片:将数据按照一定的范围进行分片,例如按照订单创建时间范围或者地理位置范围进行分片。
2.2 水平拆分的实践经验
- 数据一致性:在水平拆分的过程中,需要考虑数据的一致性和跨节点事务的处理方式,通常采用分布式事务或者最终一致性的方案。
- 负载均衡:需要考虑数据在不同节点上的分布情况,避免出现数据倾斜导致的性能问题。
- 故障恢复:需要设计合适的故障恢复机制,保证系统在节点故障时能够自动切换到其他可用节点。
3. 垂直拆分
垂直拆分是将数据按照业务功能或者数据特性的不同分散到不同的数据库中,每个数据库负责存储特定类型的数据。垂直拆分的主要优势在于可以将不同访问模式下的数据分开存储,从而提高查询效率和降低数据冗余度。
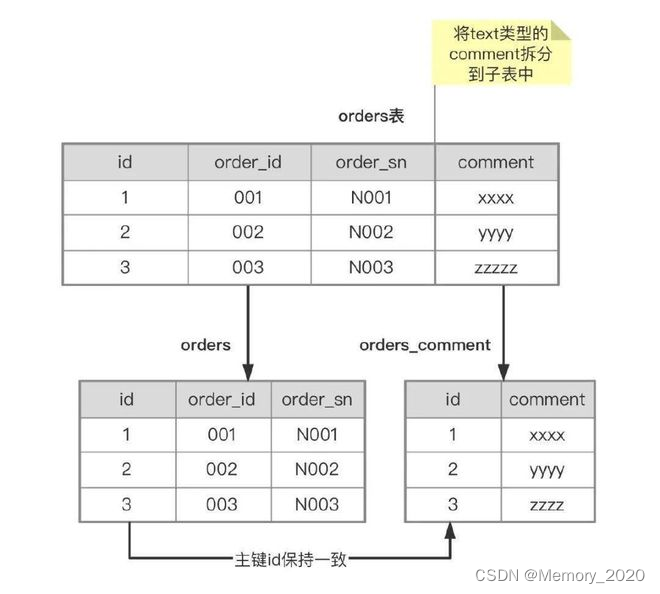
3.1 垂直拆分的策略
- 基于功能:将不同功能模块的数据分开存储,例如将用户信息、商品信息、订单信息等分别存储在不同的数据库中。
- 基于访问模式:将频繁访问和不频繁访问的数据分开存储,例如将热数据和冷数据分别存储在不同的数据库中。
3.2 垂直拆分的实践经验
- 数据关联:需要考虑不同数据之间的关联关系,确保在拆分后能够通过关联查询获取完整的信息。
- 维护成本:垂直拆分会增加系统的维护成本,需要权衡数据隔离和维护成本之间的关系。
- 扩展性:需要设计合适的扩展性方案,确保系统在业务增长时能够方便地进行扩展。
4. 分布式数据库
除了水平拆分和垂直拆分之外,还有一种常见的数据库扩展方式是使用分布式数据库。分布式数据库是将数据存储在多个节点上,并通过分布式协调和数据一致性机制来实现数据的分布式存储和处理。
4.1 分布式数据库的特点
- 数据分布:数据存储在多个节点上,可以实现数据的分布式存储和访问。
- 数据一致性:通过分布式事务和副本机制来保证数据的一致性和可靠性。
- 扩展性:分布式数据库具有良好的扩展性,可以通过增加节点来实现系统的水平扩展。
4.2 分布式数据库的实践经验
- 数据分片:需要设计合适的数据分片策略,确保数据在不同节点上的均衡分布。
- 数据一致性:需要考虑分布式事务和数据一致性机制的实现方式,确保数据的一致性和可靠性。
- 故障恢复:需要设计合适的故障恢复机制,确保系统在节点故障时能够自动切换到其他可用节点。
5. 分库分表 Sharding
一般来说,影响数据库最大的性能问题有两个,一个是对数据库的操作,一个是数据库中数据的大小。对于前者,我们需要从业务上来优化。
一方面,简化业务,不要在数据库上做太多的关联查询,而对于一些更为复杂的用于做报表或是搜索的数据库操作,应该把其移到更适合的地方。比如,用 ElasticSearch 来做查询,用 Hadoop 或别的数据分析软件来做报表分析。
对于后者,如果数据库里的数据越来越多,那么也会影响我们的数据操作。而且,对于我们的分布式系统来说,后端服务都可以做成分布式的,而数据库最好也是可以拆开成分布式的。读写分离也因为数据库里的数据太多而变慢,于是,分库分表就成了我们必须用的手段。
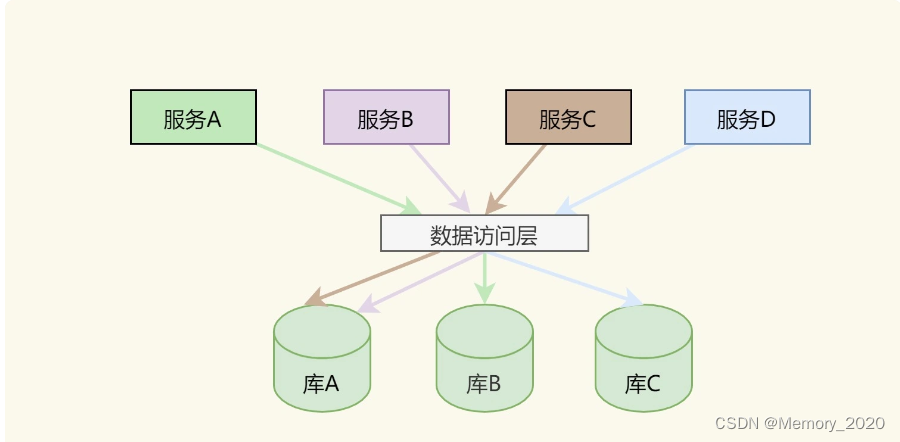
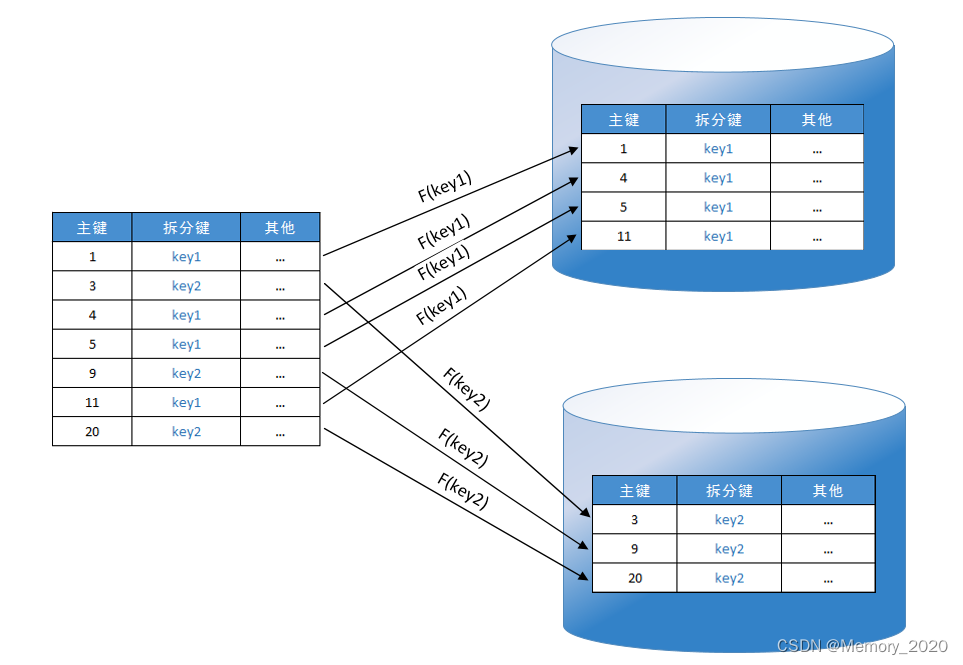
上面的图片是一个分库的示例。其中有两个事,这里需要提一下,一个是关于分库的策略,一个是关于数据访问层的中间件。
关于分库的策略。我们把数据库按某种规则分成了三个库。比如,或是按地理位置,或是按日期,或是按某个范围分,或是按一种哈希散列算法。总之,我们把数据分到了三个库中。
关于数据访问层。为了不让我们前面的服务感知到数据库的变化,我们需要引入一个叫 " 数据访问层 " 的中间件,用来做数据路由。但是,老实说,这个数据访问层的中间件很不好写,其中要有解析 SQL 语句的能力,还要根据解析好的 SQL 语句来做路由。但即便是这样,也有很多麻烦事。
比如,我要做一个分页功能,需要读一组顺序的数据,或是需要做 Max/Min/Count 这样的操作。于是,你要到三个库中分别求值,然后在数据访问层这里再合计处理返回。但即使是这样,你也会遇到各种令人烦恼的事,比如一个跨库的事务,你需要走 XA 这样的两阶段提交的操作,这样会把数据库的性能降到最低的。
为了避免数据访问层的麻烦,分片策略一般如下。
- 按多租户的方式。用租户 ID 来分,这样可以把租户隔离开来。比如:一个电商平台的商家中心可以按商家的 ID 来分。
- 按数据的种类来分。比如,一个电商平台的商品库可以按类目来分,或是商家按地域来分。
- 通过范围来分。这样分片,可以保证在同一分片中的数据是连续的,于是我们数据库操作,比如分页查询会更高效一些。一般来说,大多数情况是用时间来分片的,比如,一个电商平台的订单中心是按月份来分表的,这样可以快速检索和统计一段连续的数据。
- 通过哈希散列算法来分(比如:主键 id % 3 之类的算法。)此策略的目的是降低形成热点的可能性(接收不成比例的负载的分片)。但是,这会带来两个问题,一个就是前面所说的跨库跨表的查询和事务问题,另一个就是如果要扩容需要重新哈希部分或全部数据。
上面是最常见的分片模式,但是你还应考虑应用程序的业务要求及其数据使用模式。这里请注意几个非常关键的事宜。
- 数据库分片必须考虑业务,从业务的角度入手,而不是从技术的角度入手,如果你不清楚业务,那么无法做出好的分片策略。
- 请只考虑业务分片。请不要走哈希散列的分片方式,除非有个人拿着刀把你逼到墙角,你马上就有生命危险,你才能走哈希散列的分片方式。
6. 结语
数据库扩展是解决数据库大数据量下性能瓶颈和存储容量不足等问题的重要手段。水平拆分、垂直拆分和分布式数据库是常见的数据库扩展方式,它们各自适用于不同的场景和需求。在实际应用中,需要根据业务特点和数据特性选择合适的数据库扩展方案,以实现数据库的高效扩展和优化。随着技术的不断进步和创新,数据库扩展领域也将迎来更多的发展机遇和挑战。
通过本文的介绍,相信读者对数据库扩展的各种方式和实践经验有了更深入的了解,希望能够为实际的架构设计和数据库优化提供一些参考和启发。