博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2025年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Django框架、matplotlib可视化、scikit-learn机器学习、Echarts可视化、HTML
全国5A景区数据分析可视化
2、项目界面
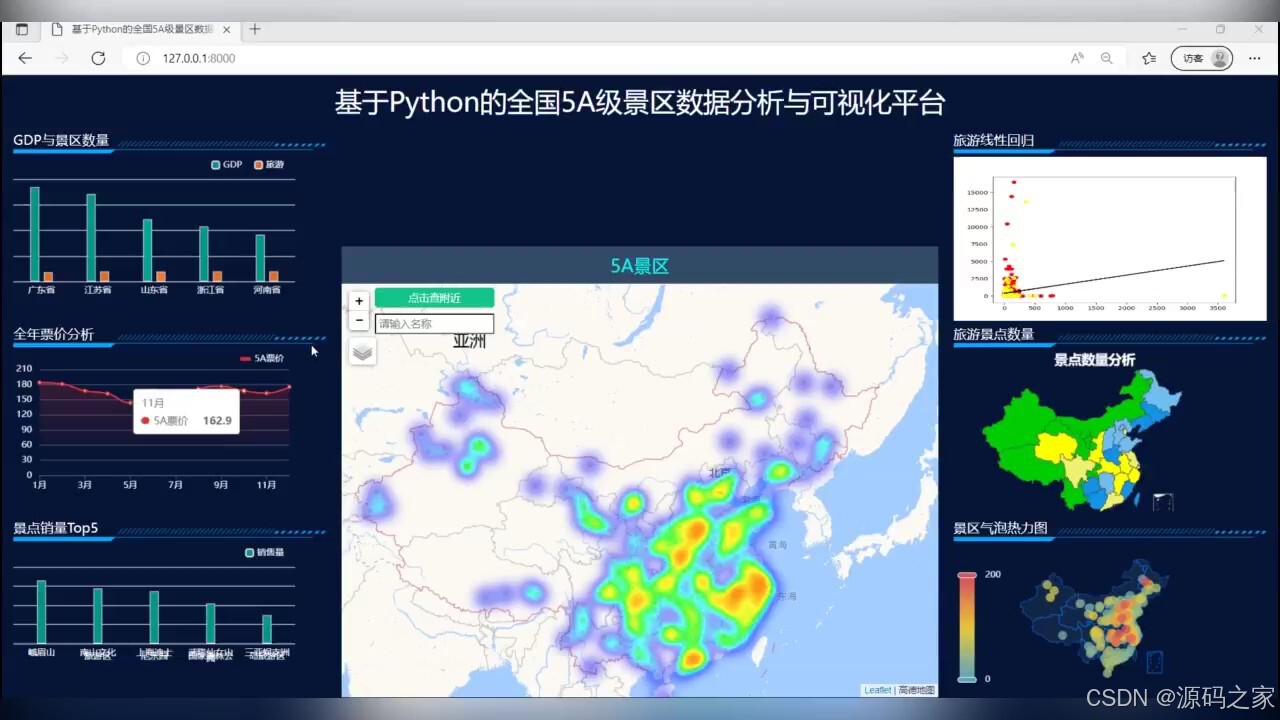
(1)大屏分析----GDP与景区数量、全年票价分析、景点销量排名、旅游线性回归、各省旅游景点数量分布、景区气泡热力图、5A景点查询
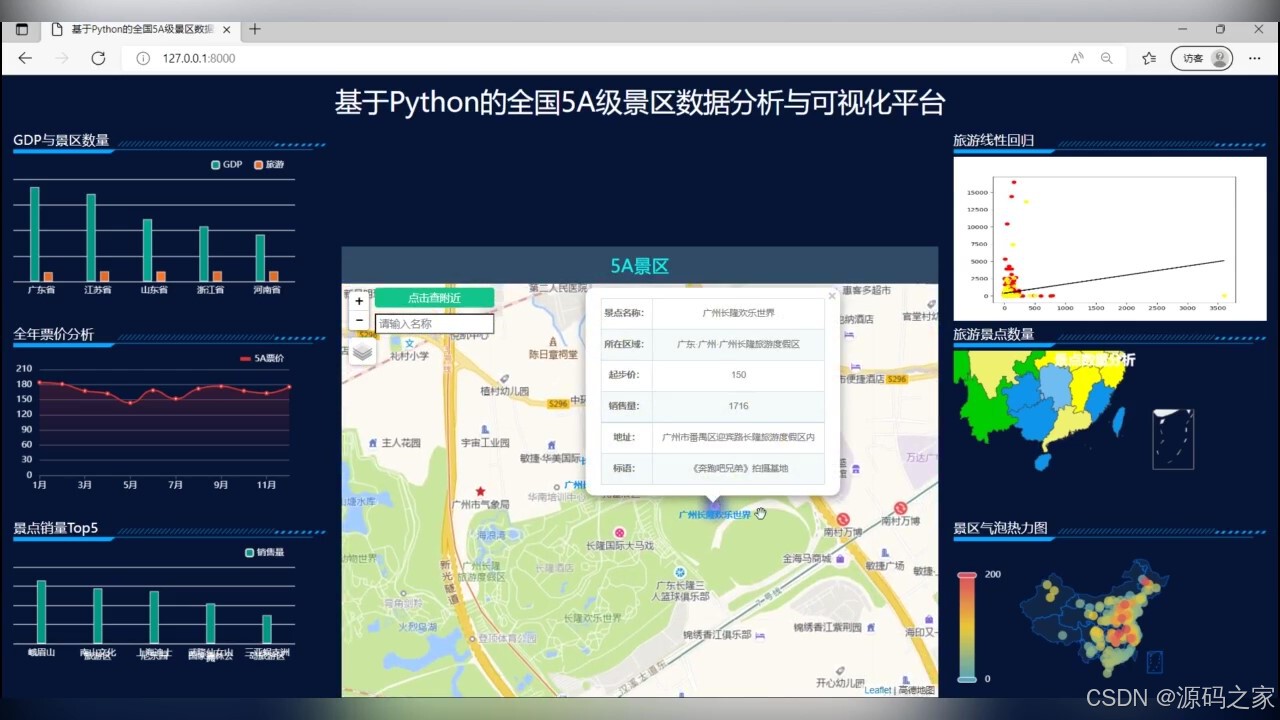
(2)景点查询—展示详细信息(景点名称、所在位置、门票、销量、标语等等)
3、项目说明
全国5A景区数据分析可视化系统:深度洞察与智慧决策
在当今旅游业蓬勃发展的背景下,5A级景区作为旅游业的璀璨明珠,不仅承载着丰富的自然景观和人文历史,更是推动地方经济发展、提升旅游品质的重要力量。为了更全面地了解全国5A景区的现状与发展趋势,我们开发了这款基于Python语言、Django框架、matplotlib与Echarts可视化技术、scikit-learn机器学习算法的全国5A景区数据分析可视化系统。该系统旨在通过数据的力量,为旅游管理者、景区经营者及广大游客提供深度洞察和智慧决策支持。
一、系统概述
本系统集成了数据收集、处理、分析与可视化等多个环节,形成了一套完整的5A景区数据分析体系。我们利用Python语言强大的数据处理能力,结合Django框架的高效开发特性,构建了一个稳定、易用的后端服务。同时,通过matplotlib和Echarts两大可视化工具,将复杂的数据转化为直观的图表和图像,让数据“说话”。此外,我们还引入了scikit-learn机器学习算法,对数据进行深度挖掘,发现潜在的规律和趋势。
二、核心功能
大屏分析:
GDP与景区数量:通过对比各地区GDP与5A景区数量的关系,揭示经济发展与旅游资源开发的内在联系。
全年票价分析:分析各景区全年票价波动情况,为游客选择最佳出游时机提供参考。
景点销量排名:根据景区门票销量进行排名,展示热门景区的受欢迎程度。
旅游线性回归:利用机器学习算法预测未来一段时间内旅游市场的变化趋势。
各省旅游景点数量分布:通过地图可视化展示各省5A景区数量,直观反映旅游资源的地域分布。
景区气泡热力图:结合景区数量、游客量、评分等多个维度,生成气泡热力图,直观展示景区热度。
5A景点查询:提供便捷的查询功能,用户可根据关键词快速找到感兴趣的5A景区。
景点查询:
系统为用户提供了详尽的景点查询功能。用户只需输入景点名称或关键词,即可快速获取该景点的详细信息,包括名称、所在位置、门票价格、销量、标语、开放时间、交通指南等。这些信息不仅有助于游客提前规划行程,还能提升游客的游览体验。
此外,景点查询页面还采用了Echarts可视化技术,将景点图片、评分、评论等关键信息以图表和图像的形式呈现,让游客在浏览信息的同时,也能享受到视觉上的愉悦。
三、系统优势
数据全面性与准确性:系统收集了全国所有5A景区的相关数据,并经过严格的数据清洗和校验,确保数据的全面性和准确性。
可视化效果突出:通过matplotlib和Echarts两大可视化工具,将数据转化为直观、易懂的图表和图像,提高了数据的可读性和可理解性。
机器学习算法加持:引入scikit-learn机器学习算法,对数据进行深度挖掘和分析,发现潜在的规律和趋势,为智慧决策提供有力支持。
用户体验友好:系统界面简洁明了,操作便捷,为用户提供了良好的使用体验。
四、应用场景
旅游管理者:通过系统提供的数据分析和可视化功能,旅游管理者可以全面了解全国5A景区的现状与发展趋势,为制定旅游政策、优化旅游资源配置提供科学依据。
景区经营者:系统提供的景点查询和销量排名等功能,有助于景区经营者了解市场需求和竞争态势,制定针对性的营销策略和提升服务质量。
广大游客:游客可以通过系统快速获取感兴趣的5A景区信息,规划行程,提升游览体验。
综上所述,这款全国5A景区数据分析可视化系统凭借其全面的数据收集、高效的数据处理、直观的数据可视化以及强大的机器学习算法支持,在旅游业中展现出了巨大的应用潜力和价值。未来,我们将继续优化系统功能、提升用户体验,为旅游业的发展贡献更多智慧和力量。
4、核心代码
from django.shortcuts import render
from api.models import *
from django.forms.models import model_to_dict
from django.http import JsonResponse
from django.db.models import Q
# Create your views here.
import pandas as pd
import os
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
def index(request):
return render(request, 'indexold.html')
def rl(request):
return render(request, 'indexrl.html')
def index3(request): # index页面加载
context = {}
return render(request, 'index.html', context)
def points(request):
keyword = request.GET.get('keyword','')
keyword2 = request.GET.get('keyword2','')
keyword3 = request.GET.get('keyword3','')
results = Quna.objects.filter(Q(area__icontains=keyword) & Q(level__icontains=keyword2) & Q(name__icontains=keyword3))
list_all = []
for result in results:
di = model_to_dict(result)
di['lng'] = di['latlng'].split(',')[0]
di['lat'] = di['latlng'].split(',')[1]
list_all.append(di)
return JsonResponse({'status':200,'data':list_all})
def top5(reuqest):
data = pd.read_excel(os.path.join(BASE_DIR,"api","total.xlsx"))
df = pd.DataFrame(data=data,columns=['地区',"2020年"])
result = df.sort_values(by=['2020年'],ascending=False).head(5).to_dict(orient='record')
x=[i['地区'] for i in result]
y = [i['2020年'] for i in result]
result2 = [2,13,7,9,6]
return JsonResponse({'status': 200, 'data': x,"y":y,"s":result2})
def top10(reuqest):
data = pd.read_csv(os.path.join(BASE_DIR,"api","jd.xlsx"))
df = pd.DataFrame(data=data,columns=['name',"sell"])
print(df)
result = df.sort_values(by=['sell'],ascending=False).head(5).to_dict(orient='records')
x = [i['name'] for i in result]
y = [i['sell'] for i in result]
return JsonResponse({'status': 200, 'data': x,"y":y})
import pandas as pd
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
def yiyuan(request):
# 读取到data frame
df = pd.read_csv('jd.csv')
X = df.iloc[:, : 1].values # 第一列的所有行
Y = df.iloc[:, 1].values # 第二列的所有行
# 拆分训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=1 / 4, random_state=0)
# 用简单线性回归模型拟合训练集
regression = LinearRegression()
regression = regression.fit(X_train, Y_train)
# 预测结果
Y_pred = regression.predict(X_test)
# 可视化训练集预测结果
plt.scatter(X_train, Y_train, color='red') # 散点图
plt.plot(X_train, regression.predict(X_train), color='blue')
# 可视化测试集预测结果
plt.scatter(X_test, Y_test, color='yellow')
plt.plot(X_test, Y_pred, color='black')
plt.show()
return JsonResponse({'status': 200})
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看【用户名】、【专栏名称】、就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,查看下方👇🏻👇🏻