将文件的内容按照某种规则进行排列。
排序算法的稳定判定:若在待排序的一个序列中, R i R_i Ri和 R j R_j Rj的关键码相同,即 k i = k j k_i=k_j ki=kj,且在排序前 R i R_i Ri领先于 R j R_j Rj,那么当排序后,如果 R i R_i Ri和 R j R_j Rj的相对次序保持不变, R i R_i Ri仍领先于 R j R_j Rj,则称此类排序方法为稳定的。若可能出现 R j R_j Rj领先于 R i R_i Ri的情况,则称此列排序是不稳定的。
排序可分为内部排序和外部排序,通过是否全部在内存中排序进行判定。
排序完成两个操作:
- 比较两个关键码的大小;
- 将记录从一个位置移动到另一个为止。
1. 简单排序
1.1 直接插入排序
将某个数据插入已经排好的队列中。
void insertSort(int data[], int n)
{
int i, j;
int temp;
for (i = 1; i < n; i++)
{
if (data[i] < data[i - 1]) {
temp = data[i]; data[i] = data[i - 1];
for (j = i - 2; j >= 0 && data[j] > temp; j--) data[j + 1] = data[j];
data[j+1] = temp;
}
}
}
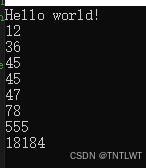
运行结果:
int array[8] = {12, 18184, 45, 78, 45, 555, 47, 36};
insertSort(array, 8);
for (int i = 0; i < 8; i++)
{
printf("%d\n", array[i]);
}
直接插入排序的时间复杂度为
O
(
n
2
)
O(n^2)
O(n2)。排序过程中仅需要一个元素的辅助空间,空间复杂度为
O
(
1
)
O(1)
O(1)。直接插入排序是一种稳定的排序方法。
1.2 冒泡排序
顾名思义,冒泡法就是像气泡上浮一样把数据逐渐传递上去。
void bubbleSort(int data[], int n)
{
int i, j, tag = 1; //tag表示排序过程中是否交换过元素值
int temp;
for (i = 1; tag && i < n; i++)
{
tag = 0;
for (j = 0; j < n - i; j++)
{
if (data[j]>data[j+1])
{
temp = data[j];
data[j] = data[j+1];
data[j + 1] = temp;
tag = 1;
}
}
}
}
int array[8] = {12, 18184, 45, 78, 45, 555, 47, 36};
//insertSort(array, 8);
bubbleSort(array, 8);
for (int i = 0; i < 8; i++)
{
printf("%d\n", array[i]);
}
冒泡排序的时间复杂度为
O
(
n
2
)
O(n^2)
O(n2)。排序过程中仅需要一个元素的辅助空间,空间复杂度为
O
(
1
)
O(1)
O(1)。冒泡排序是一种稳定的排序方法。
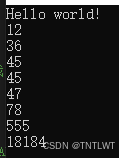
1.3 简单选择排序
逐步找出最小的元素,依次放置。
void selectSort(int data[], int n)
{
int i, j, k;
int temp;
for (i = 0; i < n-1; i++)
{
k = i;
for ( j = i+1; j < n; j++)
{
if (data[j] < data[k]) k = j;
}
if (k!=i)
{
temp = data[i];
data[i] = data[k];
data[k] = temp;
}
}
}
算法结果:
int array[8] = {12, 18184, 45, 78, 45, 555, 47, 36};
//insertSort(array, 8);
//bubbleSort(array, 8);
selectSort(array, 8);
for (int i = 0; i < 8; i++)
{
printf("%d\n", array[i]);
}
简单选择排序的时间复杂度为
O
(
n
2
)
O(n^2)
O(n2)。排序过程中仅需要一个元素的辅助空间,空间复杂度为
O
(
1
)
O(1)
O(1)。简单选择排序是一种不稳定的排序方法。
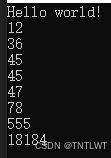
2. 希尔排序
希尔排序又称为“缩小增量排序”,是对直接插入排序方法的改进。
希尔排序的基本思想是:先将整个待排记录序列分割成若干子序列,然后分别进行直接插入排序,待整个序列中的记录基本有序时,再对全体记录进行一次直接插入排序。具体做法是先取一个小于n的整数
d
1
d_1
d1作为第一个增量,将所有相距为
d
1
d_1
d1的记录放在同一个组中,从而把文件的全部记录分成
d
1
d_1
d1组,在各组内进行直接插入排序;然后取第二个增量
d
2
(
d
2
<
d
1
)
d_2(d_2<d_1)
d2(d2<d1),重复上述分组和排序工作,依此类推,直至所取的增量
d
i
=
1
(
d
i
<
d
i
−
1
<
.
.
.
<
d
2
<
d
1
)
d_i=1(d_i<d_{i-1}<...<d_2<d_1)
di=1(di<di−1<...<d2<d1),即所有记录放在同一组进行直接插入排序,将所有记录排列有序为止。

/*************************************************
Function:shellSort,希尔排序方法
Description: 整数序列排序,从小到大
Input: data[] 排序数组
n 数组大小
delta[] 长度为m且递减有序的增量序列最后一个元素为1
m delta[]数组大小
Output:输出转换结果
Return: 0
*************************************************/
void shellSort(int data[], int n, int delta[], int m)
{
int k, i, dk, j; int temp;
for ( i = 0; i < m; i++)
{
dk = delta[i];
for (k = dk; k < n; ++k)
{
if (data[k]<data[k-dk])
{
temp = data[k];
for (j = k - dk; j>0&&temp<data[j]; j-=dk)
{
data[j + dk] = data[j];
}
data[j + dk] = temp;
}
}
}
}
希尔排序的时间复杂度为 O ( N 1.3 ) O(N^{1.3}) O(N1.3).希尔排序是不稳定的排序方法。
3. 快速排序
一趟快速排序的过程称为一次划分,具体做法是:附设两个元素位置指示变量 i i i和 j j j,它们的初值分别指向待排序列的第一个记录和最后一个记录。设枢轴记录(通常是第一个记录)的关键码为 pivot,则首先从j所给位置起向前搜索,找到第一个关键码小于 pivot 的记录时停止,然后从i所给位置起向后搜索,找到第一个关键码大于pivot 的记录时停止,此时交换j所给位置和i所给位置的元素,重复该过程直至i与i相等为止,完成一趟划分。
//用data[low]的值作为枢轴元素pivot进行划分
//不断劈成两半之后排序
int partition(int data[], int low, int high)
{
int i, j;
int pivot;
while (i<j)
{
while (i<j&&data[j]>=pivot)
{
j--;
}
data[i] = data[j];
while (i < j && data[i] <= pivot)
{
i++;
}
data[j] = data[i];
}
data[i] = pivot;
return i;
}
/*************************************************
Function:quickSort,快速排序方法
Description: 整数序列排序,从小到大
Input: data[] 排序数组
low 数组最低位
high 数组最高位
Output:输出转换结果
Return: 0
*************************************************/
void quickSort(int data[], int low, int high)
{
if (low < high)
{
int loc = partition(data, low, high);
quickSort(data,low,loc-1);
quickSort(data, loc + 1, high);
}
}