🔥作者:雨晨源码🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python实战项目案例
💕💕文末获取源码
本次文章主要是介绍基于机器学习的股票预测分析系统
系统前言
- 近年来,随着股票市场的发展和机器学习技术的进步,基于机器学习的股票预测系统受到了广泛的关注和研究。本文旨在介绍一种基于机器学习的股票预测系统,该系统利用历史股票数据,结合机器学习算法对未来的股票价格进行预测。该系统主要包括数据获取、数据处理、特征提取和模型训练四个部分。数据获取主要通过网络爬虫获取历史股票数据,数据处理包括数据清洗、数据归一化等操作,特征提取则是将处理后的数据转换为可供机器学习算法处理的特征向量,模型训练则是利用训练数据对机器学习算法进行训练,得到预测模型。实验结果表明,相比于传统的技术分析方法,基于机器学习的股票预测系统能够更准确地预测股票价格的涨跌趋势,具有更好的预测效果和稳定性。未来,我们将进一步改进该系统的算法和数据处理方法,提高预测的精度和实用性,并将其应用于实际的股票市场中。
- 基于机器学习的股票预测系统对于股票市场的参与者具有重要的意义,它可以帮助投资者和交易者更好地把握市场变化,从而获得更好的收益[4]。具体而言,该系统的意义包括以下几个方面:(1)提高投资效率:传统的股票预测方法往往需要投资者花费大量的时间和精力去分析各种市场因素和基本面数据[5],但这些分析结果的准确性和可靠性并不高。而基于机器学习的股票预测系统可以自动分析大量的历史数据和实时数据,并给出更加准确的预测结果,从而提高投资者的效率。(2)降低投资风险:股票市场变化多端,投资者的投资决策往往会受到各种因素的影响[6],从而导致投资风险的增加。而基于机器学习的股票预测系统可以通过分析历史数据和实时数据,识别出市场变化的规律和趋势,帮助投资者降低投资风险,提高投资收益率。(3)优化交易策略:股票市场的变化非常复杂,交易者的交易策略也需要不断地进行优化和调整。基于机器学习的股票预测系统可以通过对历史数据和实时数据的分析,帮助交易者优化交易策略,从而更好地把握市场变化和获得更好的收益。(4)推动科学技术的发展:基于机器学习的股票预测系统是一个典型的人工智能应用案例[8],它将机器学习和数据挖掘等技术应用到股票市场的预测中,推动了人工智能和科学技术的发展,具有重要的科学研究价值和实际应用价值。
开发技术与环境
- 开发技术:LSTM预测模型、Python+爬虫+Django框架+HTML++Echarts+Mysql
- 项目简介:本项目爬虫端和网站后台采用Python语言开发,其中爬虫利用的是Scrapy框架可以轻松实现网站数据的抓取,抓取到的兼职信息直接保存到mysql数据库中,前端采用Vue开发,实现了前后端分离的模式,前端请求Django后端接受到数据然后利用echarts画各种统计图。
需求分析-功能介绍
通过研究目前行业内的软件功能,基于机器学习的股票预测系统为了能保证合理的完成股票预测,应该具备如下功能:用户管理模块、自选股份模块、数据收集及预处理模块、股票预测模块。如图所示:
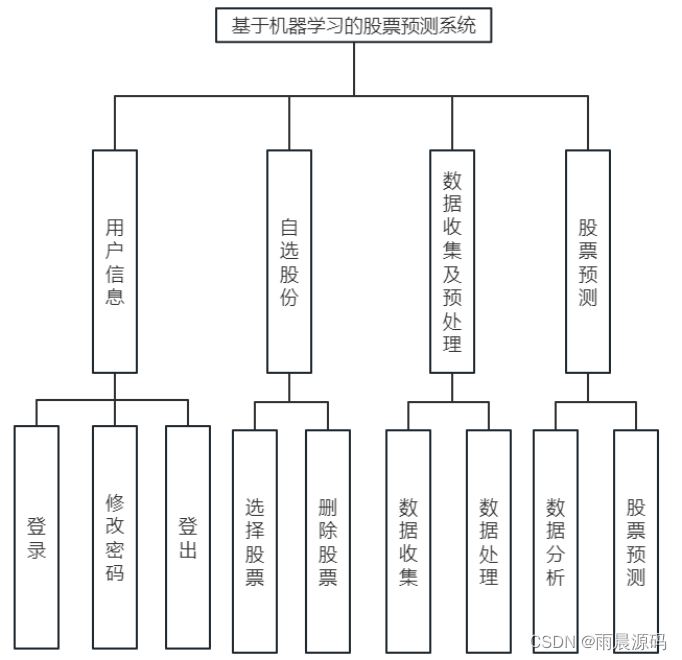
用户信息模块:用户可以登录、浏览个人信息、修改密码等。
自选股票模块:用户可以自主选择股票名称、股票代码进行预测。
数据收集及预处理模块:将所以符合算法模型的股票数据进行收集,包括舆论数据、每日股市闭市时的基本数据。
股票预测模块:通过收集数据为基础,使用LSTM模型进行股票预测。
演示图片
1.页面:
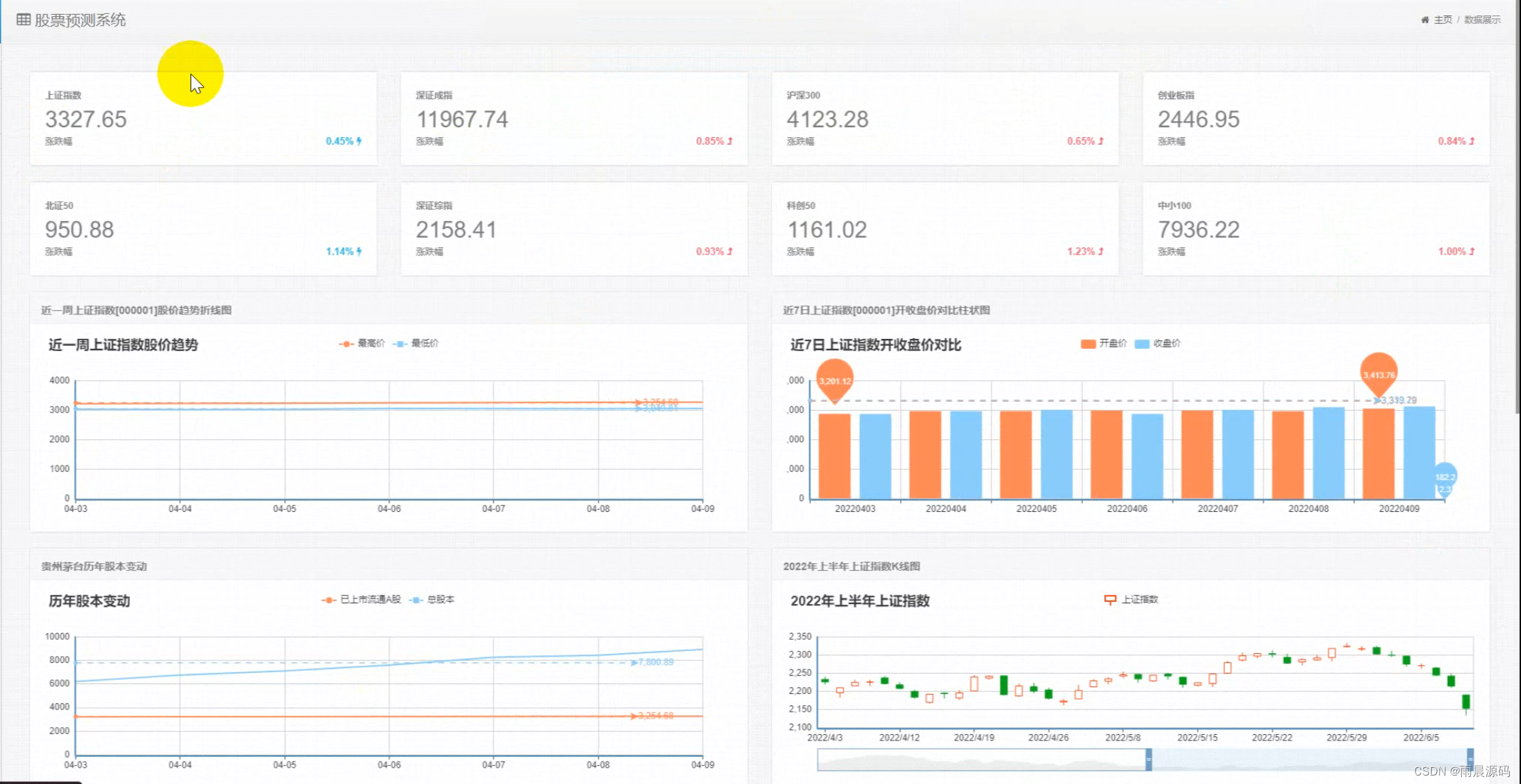
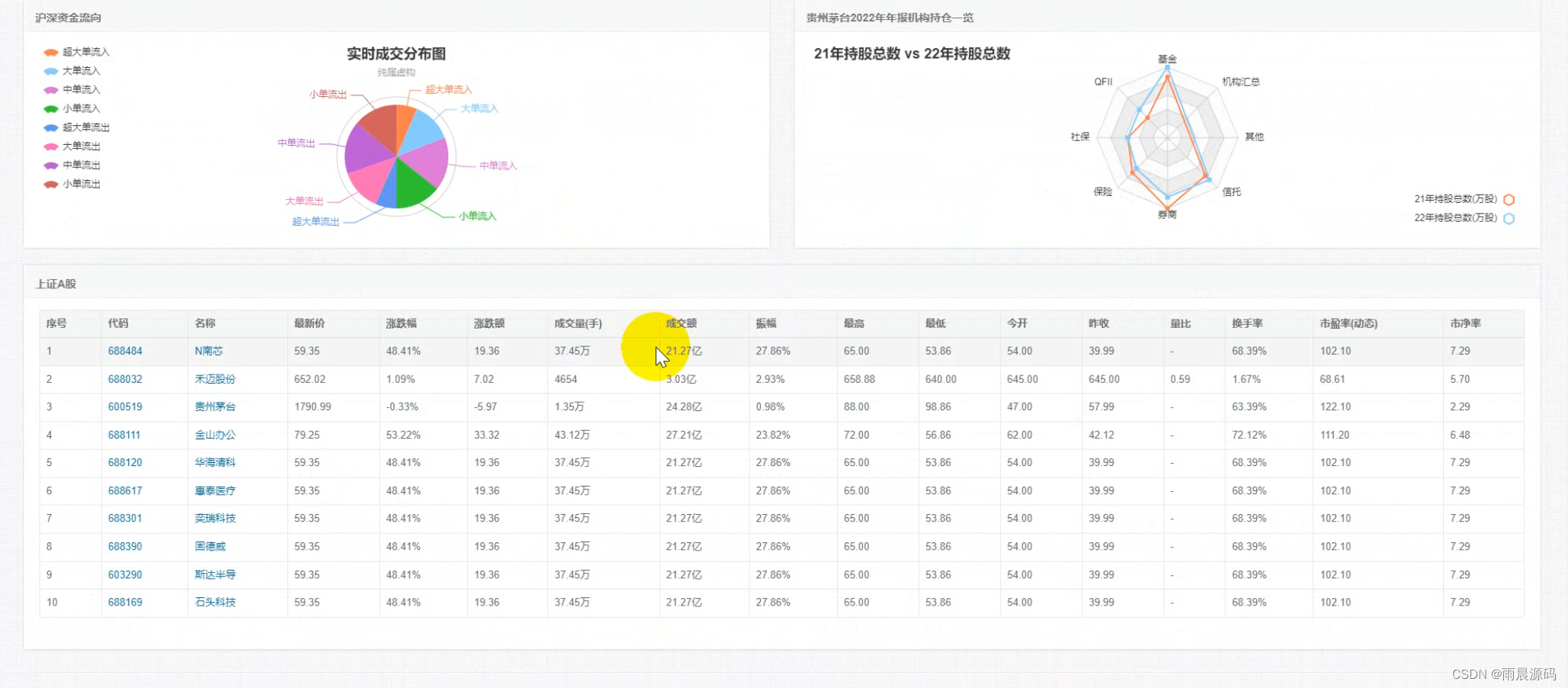
☀️数据可视化分析模块(股价趋势、收盘价对比、股本变动、实时成交)☀️
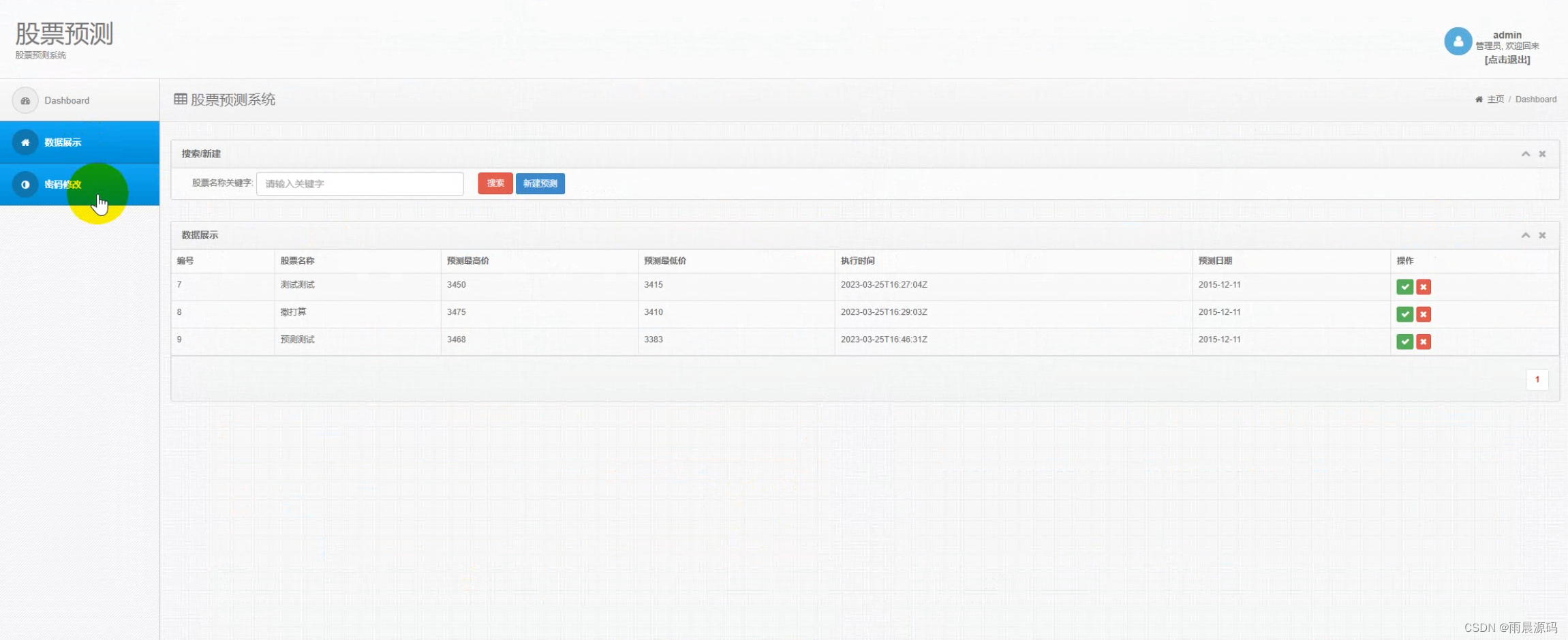
☀️LSTM模型预测-股票预测-股票自选☀️
☀️密码修改☀️
☀️登录:sunny
☀️文档截图:sunny

代码展示
1.代码如下(示例):
class Config:
# 数据参数
feature_columns = list(range(2, 9)) # 要作为feature的列,按原数据从0开始计算,也可以用list 如 [2,4,6,8] 设置
label_columns = [4, 5] # 要预测的列,按原数据从0开始计算, 如同时预测第四,五列 最低价和最高价
# label_in_feature_index = [feature_columns.index(i) for i in label_columns] # 这样写不行
label_in_feature_index = (lambda x, y: [x.index(i) for i in y])(feature_columns, label_columns) # 因为feature不一定从0开始
predict_day = 1 # 预测未来几天
# 网络参数
input_size = len(feature_columns)
output_size = len(label_columns)
hidden_size = 128 # LSTM的隐藏层大小,也是输出大小
lstm_layers = 2 # LSTM的堆叠层数
dropout_rate = 0.2 # dropout概率
time_step = 20 # 这个参数很重要,是设置用前多少天的数据来预测,也是LSTM的time step数,请保证训练数据量大于它
# 训练参数
do_train = True
do_predict = True
add_train = False # 是否载入已有模型参数进行增量训练
shuffle_train_data = True # 是否对训练数据做shuffle
use_cuda = True # 是否使用GPU训练
train_data_rate = 0.95 # 训练数据占总体数据比例,测试数据就是 1-train_data_rate
valid_data_rate = 0.15 # 验证数据占训练数据比例,验证集在训练过程使用,为了做模型和参数选择
batch_size = 64
learning_rate = 0.001
epoch = 20 # 整个训练集被训练多少遍,不考虑早停的前提下
patience = 5 # 训练多少epoch,验证集没提升就停掉
random_seed = 42 # 随机种子,保证可复现
do_continue_train = False # 每次训练把上一次的final_state作为下一次的init_state,仅用于RNN类型模型,目前仅支持pytorch
continue_flag = "" # 但实际效果不佳,可能原因:仅能以 batch_size = 1 训练
if do_continue_train:
shuffle_train_data = False
batch_size = 1
continue_flag = "continue_"
# 训练模式
debug_mode = False # 调试模式下,是为了跑通代码,追求快
debug_num = 500 # 仅用debug_num条数据来调试
# 框架参数
used_frame = frame # 选择的深度学习框架,不同的框架模型保存后缀不一样
model_postfix = {"pytorch": ".pth", "keras": ".h5", "tensorflow": ".ckpt"}
model_name = "model_" + continue_flag + used_frame + model_postfix[used_frame]
if not self.config.do_continue_train:
# 在非连续训练模式下,每time_step行数据会作为一个样本,两个样本错开一行,比如:1-20行,2-21行。。。。
train_x = [feature_data[i:i + self.config.time_step] for i in range(self.train_num - self.config.time_step)]
train_y = [label_data[i:i + self.config.time_step] for i in range(self.train_num - self.config.time_step)]
# for i in range(label_column_num):
# plt.figure(i + 1) # 预测数据绘制
# plt.plot(label_X, label_data[:, i], label='label')
# plt.plot(predict_X, predict_data[:, i], label='predict')
# plt.title("Predict stock {} price with {}".format(label_name[i], config.used_frame))
# logger.info("预测股票 {} 天后的 {} 为: ".format(config.predict_day, "高价" if label_name[i] == "high" else "低价") +
# str(np.squeeze(predict_data[-config.predict_day:, i])))
# if config.do_figure_save:
# plt.savefig(
# config.figure_save_path + "{}predict_{}_with_{}.png".format(config.continue_flag, label_name[i],
# config.used_frame))
#
# plt.show()
con = Config()
con.train_data_path = file_name
for key in dir(args): # dir(args) 函数获得args所有的属性
if not key.startswith("_"): # 去掉 args 自带属性,比如__name__等
setattr(con, key, getattr(args, key)) # 将属性值赋给Config
logger = load_logger(con)
try:
np.random.seed(con.random_seed) # 设置随机种子,保证可复现
data_gainer = Data(con)
if con.do_train:
train_X, valid_X, train_Y, valid_Y = data_gainer.get_train_and_valid_data()
train(con, logger, [train_X, train_Y, valid_X, valid_Y])
if con.do_predict:
test_X, test_Y = data_gainer.get_test_data(return_label_data=True)
pred_result = predict(con, test_X) # 这里输出的是未还原的归一化预测数据
predict_data, label_data, data_len, _ = draw(con, data_gainer, logger, pred_result)
return predict_data, label_data, data_len
except Exception:
logger.error("Run Error", exc_info=True)
里插入代码片
结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python实战项目集
💟💟如果大家有任何疑虑,欢迎在下方位置详细交流。