YOLOv3: An Incremental Improvement
YOLOv3:增量改进
Abstract
我们向YOLO提供一些更新! 我们做了一些小的设计更改以使其更好。 我们还培训了这个相当庞大的新网络。 比上次要大一点,但更准确。 不过速度还是很快的,请放心。 YOLOv3在320×320的条件下以28.2 mAP的速度运行22 ms,与SSD一样精确,但速度快了三倍。 当我们查看旧的.5 IOU mAP检测指标YOLOv3时,它是相当不错的。 在Titan X上,它在51毫秒内可达到57.9 AP 50,而RetinaNet在198毫秒内可达到57.5 AP 50,性能相似,但快3.8倍。 与往常一样,所有代码都位于https://pjreddie.com/yolo/在线。
1 Introduction
有时候,您只是打电话一年,就知道了吗?我今年没有做很多研究。在Twitter上花费了大量时间。和GAN一起玩了些。从去年[12] [1]开始,我还有一点动力。我设法对YOLO进行了一些改进。但是,老实说,没有什么比超级有趣的了,只是一堆使它变得更好的小改动。我也帮助了其他人的研究。
实际上,这就是今天把我们带到这里的原因。我们有一个可以使用相机的截止日期[4],我们需要引用我对YOLO进行的一些随机更新,但我们没有消息来源。因此,准备一份技术报告!
技术报告的优点在于它们不需要介绍,大家都知道我们为什么在这里。因此,本引言的结尾将为本文的其余部分指明路标。首先,我们将告诉您与YOLOv3达成的交易。然后,我们将告诉您我们的做法。我们还将告诉您一些我们尝试过的无效的操作。最后,我们将考虑所有这些。
2 The Deal
因此,这是与YOLOv3达成的交易:我们大多从别人那里汲取了好主意。我们还培训了一个新的分类器网络,该网络要比其他分类器更好。我们将带您从头开始学习整个系统,以便您可以全部了解。
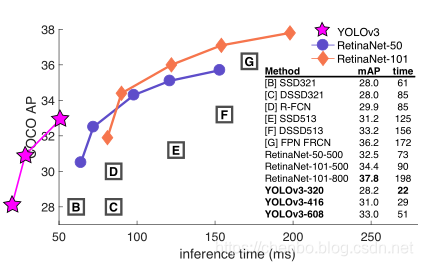
图1.我们根据Focal Loss论文[9]修改了此图。YOLOv3的运行速度明显快于其他具有可比性能的检测方法。 从M40或Titan X来看,它们基本上是相同的GPU。
2.1 边界框预测
遵循YOLO9000,我们的系统使用尺寸簇作为锚定框来预测边界框[15]。网络为每个边界框tx,t y,t w,t h预测4个坐标。如果单元格从图像的左上角偏移了(c x,c y),并且先验边界框的宽度和高度分别为p w,p h,则预测对应于:
b
x
=
σ
(
t
x
)
+
c
x
b
y
=
σ
(
t
y
)
+
c
y
b
w
=
p
w
e
t
w
b
h
=
p
h
e
t
h
\begin{aligned} &b_{x}=\sigma\left(t_{x}\right)+c_{x}\\ &b_{y}=\sigma\left(t_{y}\right)+c_{y}\\ &b_{w}=p_{w} e^{t_{w}}\\ &b_{h}=p_{h} e^{t_{h}} \end{aligned}
bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=pheth
在训练期间,我们使用平方误差损失之和。如果某个坐标预测的地面真实值为ˆ t *,则我们的梯度为地面真实值(从地面真实框计算得出)减去我们的预测:ˆ t * − t *。通过倒转上述公式,可以很容易地计算出地面真实值。
图2.具有尺寸先验和位置预测的边界框。 我们将预测框的宽度和高度,使其偏离群集质心。 我们使用S形函数预测盒子相对于过滤器应用位置的中心坐标。
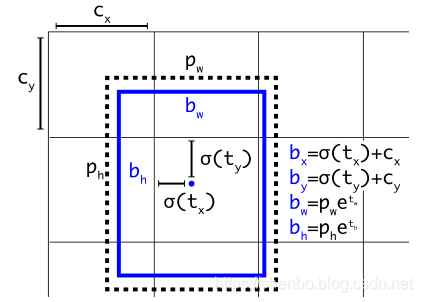
YOLOv3使用逻辑回归预测每个边界框的客观性得分。如果边界先验框与地面真值对象的重叠量大于任何其他边界先验框,则应为1。如果先验边界框不是最好的,但确实与地面真实对象重叠超过某个阈值,我们将忽略预测[17]。我们使用的阈值为.5。与[17]不同,我们的系统仅为每个地面真值对象分配一个边界框。如果没有将边界框先验分配给地面真理对象,则不会对坐标或类别预测造成任何损失,而只会造成客观性的损失。
2.2 类别预测
**每个框使用多标签分类预测边界框可能包含的类。我们不使用softmax,因为我们发现它不需要良好的性能,而是只使用独立的逻辑分类器。**在训练期间,我们使用二元交叉熵损失进行班级预测。
当我们移至更复杂的领域(例如“开放图像”数据集[7])时,这种表述方式会有所帮助。在这个数据集中有很多重叠的标签(即女人和人),使用softmax假设每个盒子只有一个类,通常情况并非如此。多标签方法可以更好地对数据建模。
2.3 跨尺度的预测
YOLOv3预测3种不同比例的box。我们的系统使用相似的概念从金字塔尺度中提取特征,以金字塔网络为特征[8]。从基本特征提取器中,我们添加了几个卷积层。这些中的最后一个预测3D张量编码边界框,客观性和类预测。*在我们用COCO [10]进行的实验中,我们预测每个尺度上有3个盒子,因此对于4个边界框偏移,1个对象预测和80个类预测,张量为N×N×[3 (4 + 1 + 80)]。
接下来,我们从先前的2层中获取特征图,并将其上采样2倍。我们还从网络的早期获取了一个特征图,并使用级联将其与我们的上采样特征合并。这种方法使我们能够从上采样的特征中获取更有意义的语义信息,并从较早的特征图中获得更细粒度的信息。然后,我们再添加一些卷积层以处理此组合特征图,并最终预测相似的张量,尽管现在的大小是原来的两倍。
我们再执行一次相同的设计,以预测最终比例的盒子。因此,我们对第3层的预测受益于所有先前的计算以及网络早期的细粒度功能。
**我们仍然使用k均值聚类来确定边界框先验。**我们只是随意选择了9个聚类和3个比例,然后将这些聚类在各个比例之间平均分配。在COCO数据集上,9个簇是:(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90) ,(156×198),(373×326)。
2.4 特征提取器
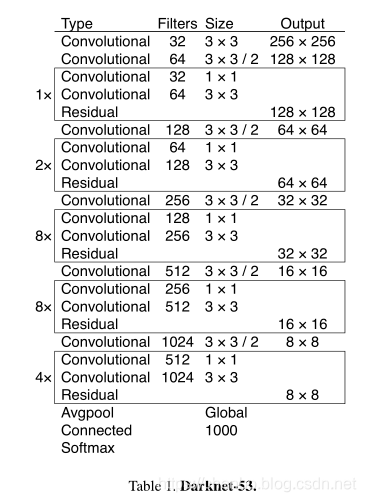
**我们使用一个新的网络来执行特征提取。我们的新网络是YOLOv2,Darknet-19中使用的网络与新的残差网络组件之间的混合方法。**我们的网络使用了连续的3×3和1×1卷积层,但现在也有了一些捷径连接,并且明显更大。它有53个卷积层,所以我们称它为…等待它… Darknet-53!
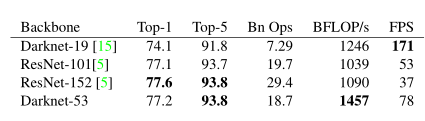
这个新网络比Darknet-19强大得多,但仍比ResNet-101或ResNet-152高效。以下是ImageNet的一些结果:
每个网络都经过相同设置的训练,并以256×256的单作物精度进行测试。运行时间是在Titan X上以256×256进行测量的。因此Darknet-53与最新的分类器性能相当,但浮点运算更少,速度更高。 Darknet-53比ResNet-101更好,速度提高了1.5倍。 Darknet-53具有与ResNet-152相似的性能,并且快2倍。
2.5 训练
我们仍然会训练完整的图像,没有硬的负面挖掘或任何类似的东西。我们使用多尺度训练,大量数据扩充,批处理规范化以及所有标准内容。我们使用Darknet神经网络框架进行训练和测试[14]。
3 我们如何做
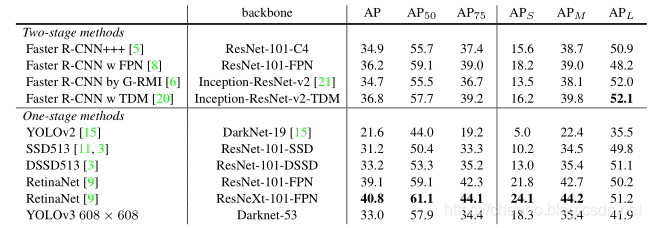
YOLOv3很好!参见表3。就COCO而言,平均平均AP度量标准很奇怪,与SSD变体相当,但速度提高了3倍。但是,在此指标上,它仍然比其他模型(例如RetinaNet)要落后很多。
但是,当我们以IOU = .5(或图表中的AP 50)查看mAP的“旧”检测指标时,YOLOv3非常强大。它几乎与RetinaNet相当,并且远远超过SSD版本。这表明YOLOv3是一个非常强大的检测器,擅长于为物体制造体面的box。但是,随着IOU阈值的增加,性能会显着下降,这表明YOLOv3难以使框与对象完美对齐。
过去,YOLO一直在努力处理小物件。但是,现在我们看到了这种趋势的逆转。通过新的多尺度预测,我们看到YOLOv3具有相对较高的AP S性能。但是,它在中型和大型物体上的性能相对较差。
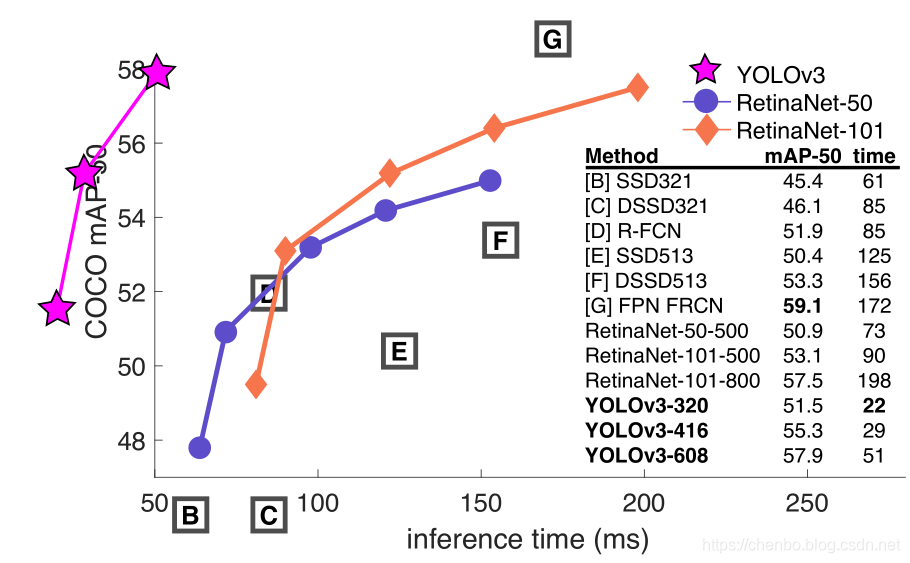
当我们在AP 50度量标准上绘制精度与速度的关系时(参见图5),我们看到YOLOv3比其他检测系统具有明显的优势。即更快,更好。
4 我们尝试过的无效的事情
在开发YOLOv3时,我们尝试了很多东西。很多都行不通。这是我们能记住的东西。
锚框x,y偏移量预测。我们尝试使用普通的锚框预测机制,在该机制中,您可以使用线性激活将x,y偏移量预测为框宽度或高度的倍数。我们发现此公式降低了模型的稳定性,并且无法很好地发挥作用。线性的x,y预测而非逻辑模型。我们尝试使用线性激活而不是逻辑激活直接预测x,y偏移量。这导致mAP下降了两点。
FOCALLOSS 我们尝试使用焦点损失。它降低了我们的mAP大约2点。 YOLOv3可能已经对焦点损失正在尝试解决的问题具有鲁棒性,因为它具有独立的客观性预测和条件类预测。因此,对于大多数示例而言,分类预测不会带来损失吗?或者其他的东西?我们不太确定。
双IOU阈值和真值分配。更快的RCNN在训练期间使用两个IOU阈值。如果预测与基本事实的重叠为0.7,则为正例;由[.3-.7]进行的预测将被忽略;对于所有基本真实对象,小于0.3则为负例。我们尝试了类似的策略,但未取得良好的效果。
我们非常喜欢我们目前的表述,似乎至少是局部最优。这些技术中的某些可能最终会产生良好的结果,也许它们只需要进行一些调整就可以稳定训练。
5 这一切意味着什么
YOLOv3是一个很好的检测器。快速,准确。在.5至.95 IOU度量标准之间的COCO平均AP效果不佳。但是,对于.5 IOU的旧检测指标而言,这非常好。
为什么我们仍要转换指标?原始的COCO论文只是这样一个含糊的句子:“评估服务器完成后,将添加对评估指标的完整讨论”。 Russakovsky等人报告说,人类很难区分.3和.5的IOU!“训练人员视觉检查IOU为0.3的边界框并将其与IOU 0.5的边界框区分开是非常困难的。” [ 18]如果人类很难分辨出差异,那么这有多重要?
但是也许更好的问题是:“既然有了探测器,我们将如何处理这些探测器?”许多从事这项研究的人都在谷歌和Facebook。我想至少我们知道这项技术掌握得很好。并且绝对不会被用来收集您的个人信息并将其出售给…。等等,您是在说这正是它的用途??哦。
好吧其他为视觉研究投入大量资金的人是军队,他们从未做过任何可怕的事情,例如用新技术杀死许多人,等等… 1我非常希望大多数使用计算机视觉的人能够只是用它来做快乐的好东西,例如计算国家公园中斑马的数量[13],或跟踪猫在房子周围徘徊的猫[19]。但是计算机视觉已经开始被质疑使用,作为研究人员,我们有责任至少考虑我们的工作可能造成的危害并想办法减轻它。我们欠世界那么多。
包括在内,请不要。 (因为我终于退出了Twitter)。
反驳
我们要感谢Reddit的评论者,同事,电子邮件发送者,以及走廊上传来的喊叫声,感谢他们的可爱,由衷的话。如果您像我一样,正在审查ICCV,那么我们知道您可能还会阅读其他37篇论文,您将不可避免地推迟到最后一周,然后在该领域中有一些传奇人物通过电子邮件向您发送有关您应该如何完成的论文这些评论只是不清楚他们说的是什么,也许它们来自未来?无论如何,如果没有您过去自己过去所做的所有工作,这篇论文将不会变成及时的事情,但是只有一点点前进,直到现在为止都没有。而且,如果您发了推文,我不会知道。只是在说。
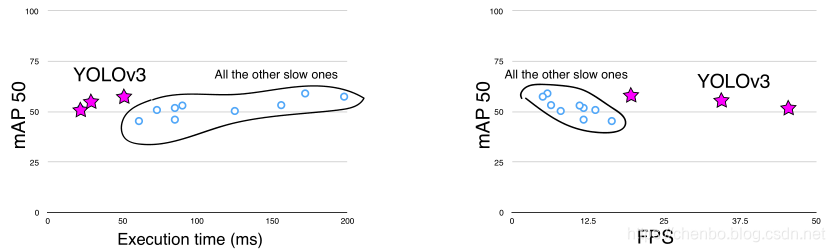
审稿人#2 AKA丹·格罗斯曼(笑的是谁呢)坚持认为,我在这里指出我们的图不是一个而是两个非零的原点。丹,您绝对正确,这是因为看起来比承认我们所有人都在战胜2-3%的行动计划更好。但是这里是要求的图形,我也用FPS绘制了一个图形,因为当我们在FPS上绘图时,我们看起来就像超级棒。
评论者4在Reddit上的AKA JudasAdventus写道:“有趣的阅读,但反对MSCOCO指标的论点似乎有些虚弱”。好吧,我一直都知道你会成为打开我犹大的人。您知道在进行项目时是如何进行的,而且只能顺利进行,因此您必须找出某种方法来证明您所做的工作确实很酷吗?我基本上是想这样做,并且对COCO指标大加抨击。但是,既然我已经放完了这座山丘,我不妨死在它上面。
看到问题了,mAP已经有些破损,因此对其进行更新应该可以解决一些问题,或者至少说明为什么更新版本在某种程度上更好。这就是我遇到的最大问题是缺乏合理性。对于PASCAL VOC,将IOU阈值“故意设置得较低,以解决地面真实数据中边界框中的不准确性” [2]。 COCO的标签是否比VOC更好?绝对有可能,因为COCO带有分割蒙版,也许标签更值得信赖,因此我们不必担心准确性。但同样,我的问题是缺乏合理性.COCO度量标准强调更好的边界框,但强调必须意味着它不再强调其他内容,在这种情况下为分类准确性。是否有充分的理由认为更精确的边界框比更好的分类更重要?未分类的示例比稍微移动的边界框更明显。
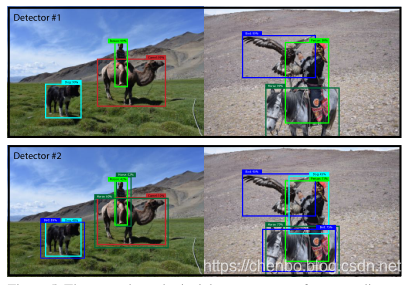
mAP已经搞砸了,因为重要的是按班级排序。例如,如果您的测试集仅具有这两个图像,则根据mAP,产生这些结果的两个检测器就如常:
现在,这显然是对mAP问题的过分夸大,但是我想我最近重新定义的一点是,“现实世界”中的人们所关心的与我们当前的度量标准之间存在如此明显的差异。要提出新的指标,我们应该关注这些差异。同样,它已经是平均精度了,我们什至称之为COCO指标,平均平均精度?
这是一个建议,给人们真正关心的是图像和检测器,检测器对图像中的对象进行查找和分类的程度如何。摆脱每个类别的AP而仅执行全球平均精度又如何呢?还是对每个图像进行AP计算并求平均值?
总结
一个需要注意的地方,yolov3-tiny 有max pooling,而yolov3使用stride=2的卷积代替pooling操作
yolov3-tiny:
yolov3:
图片引用地址:https://blog.csdn.net/qq_14845119/article/details/80335225
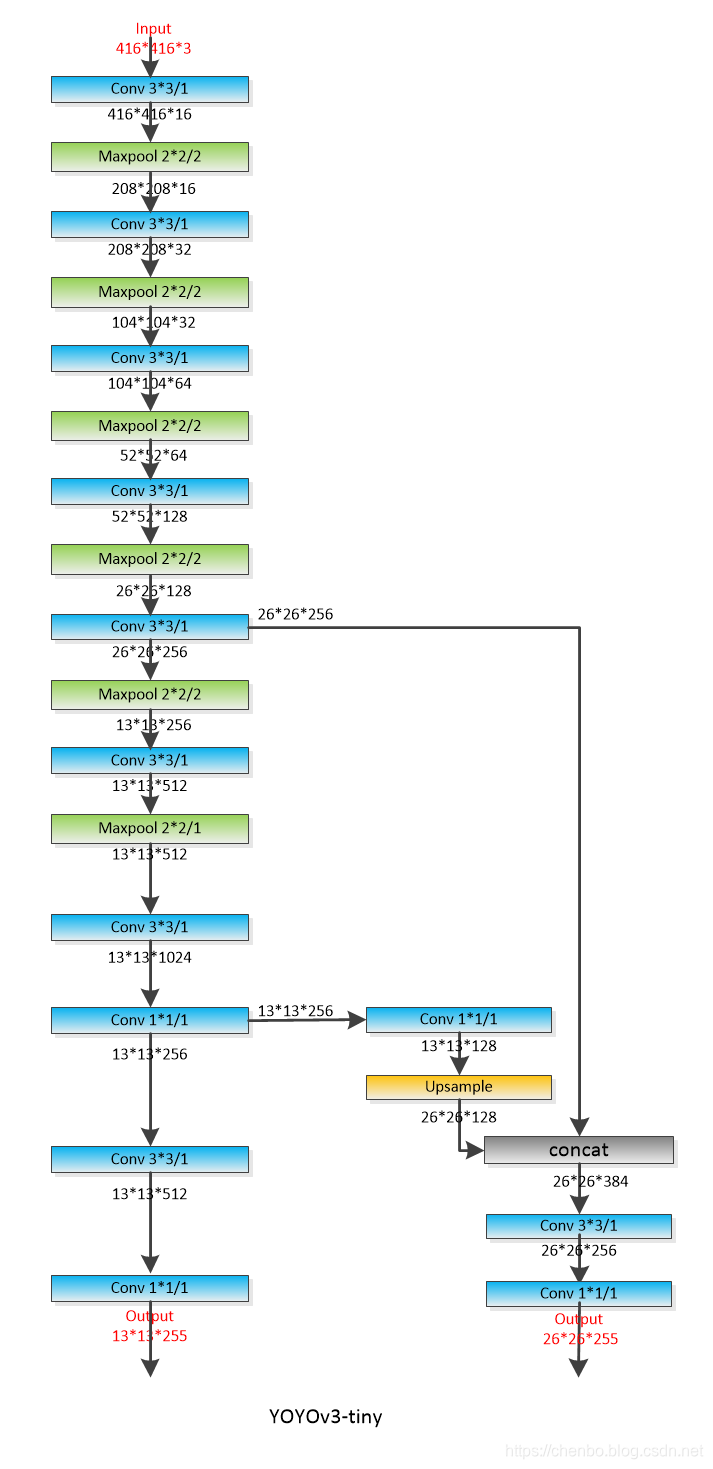

YOLOv3没有太多的创新,主要是借鉴一些好的方案融合到YOLO里面。不过效果还是不错的,在保持速度优势的前提下,提升了预测精度,尤其是加强了对小物体的识别能力。
YOLO3主要的改进有:调整了网络结构;利用多尺度特征进行对象检测;对象分类用Logistic取代了softmax。
新的网络结构Darknet-53
在基本的图像特征提取方面,YOLO3采用了称之为Darknet-53的网络结构(含有53个卷积层),它借鉴了残差网络residual network的做法,在一些层之间设置了快捷链路(shortcut connections)。
Darknet-53网络采用2562563作为输入,最左侧那一列的1、2、8等数字表示多少个重复的残差组件。每个残差组件有两个卷积层和一个快捷链路
利用多尺度特征进行对象检测
YOLO2曾采用passthrough结构来检测细粒度特征,在YOLO3更进一步采用了3个不同尺度的特征图来进行对象检测。
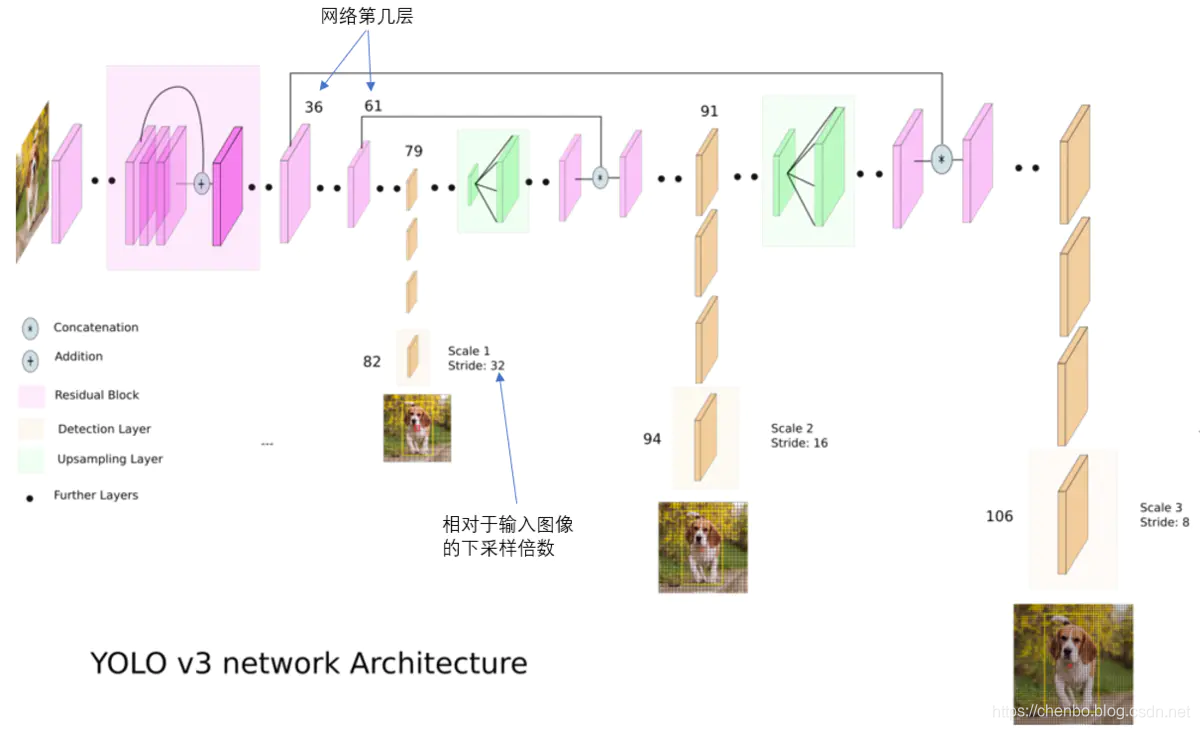
结合上图看,卷积网络在79层后,经过下方几个黄色的卷积层得到一种尺度的检测结果。相比输入图像,这里用于检测的特征图有32倍的下采样。比如输入是416416的话,这里的特征图就是1313了。由于下采样倍数高,这里特征图的感受野比较大,因此适合检测图像中尺寸比较大的对象。
为了实现细粒度的检测,第79层的特征图又开始作上采样(从79层往右开始上采样卷积),然后与第61层特征图融合(Concatenation),这样得到第91层较细粒度的特征图,同样经过几个卷积层后得到相对输入图像16倍下采样的特征图。它具有中等尺度的感受野,适合检测中等尺度的对象。
最后,第91层特征图再次上采样,并与第36层特征图融合(Concatenation),最后得到相对输入图像8倍下采样的特征图。它的感受野最小,适合检测小尺寸的对象。
9种尺度的先验框
随着输出的特征图的数量和尺度的变化,先验框的尺寸也需要相应的调整。YOLO2已经开始采用K-means聚类得到先验框的尺寸,YOLO3延续了这种方法,为每种下采样尺度设定3种先验框,总共聚类出9种尺寸的先验框。在COCO数据集这9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。
分配上,在最小的13*13特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。中等的2626特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。较大的5252特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。
感受一下9种先验框的尺寸,下图中蓝色框为聚类得到的先验框。黄色框式ground truth,红框是对象中心点所在的网格。

对象分类softmax改成logistic
预测对象类别时不使用softmax,改成使用logistic的输出进行预测。这样能够支持多标签对象(比如一个人有Woman 和 Person两个标签)。

输入映射到输出
不考虑神经网络结构细节的话,总的来说,对于一个输入图像,YOLO3将其映射到3个尺度的输出张量,代表图像各个位置存在各种对象的概率。
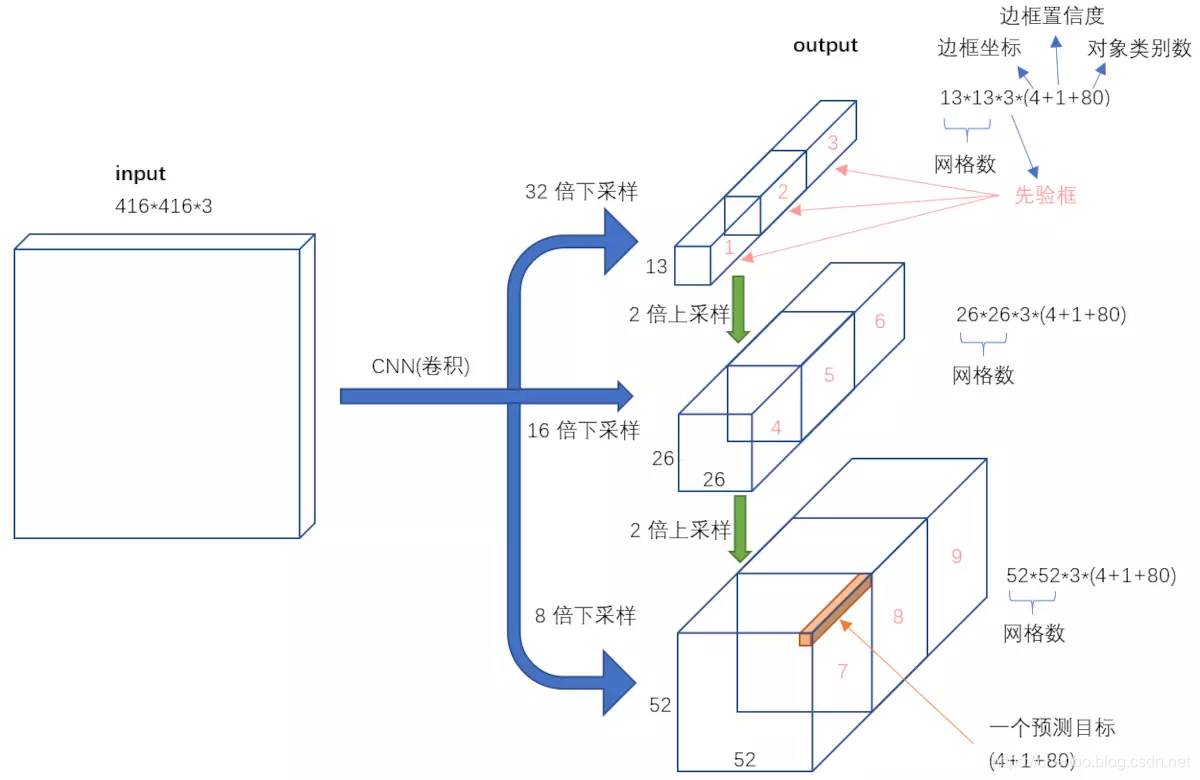
我们看一下YOLO3共进行了多少个预测。对于一个416416的输入图像,在每个尺度的特征图的每个网格设置3个先验框,总共有 **13133 + 26263 + 5252*3 = 10647 个预测**。每一个预测是一个(4+1+80)=85维向量,这个85维向量包含边框坐标(4个数值),边框置信度(1个数值),对象类别的概率(对于COCO数据集,有80种对象)。
对比一下,YOLO2采用13135 = 845个预测,YOLO3的尝试预测边框数量增加了10多倍,而且是在不同分辨率上进行,所以mAP以及对小物体的检测效果有一定的提升。
参考链接:https://www.jianshu.com/p/d13ae1055302
darknet.py代码的超详细注释
(参考https://blog.csdn.net/qq_34199326/article/details/84072505)
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import numpy as np
from util import *
def get_test_input():
img = cv2.imread("dog-cycle-car.png")
img = cv2.resize(img, (416,416)) #Resize to the input dimension
img_ = img[:,:,::-1].transpose((2,0,1)) #img是【h,w,channel】,这里的img[:,:,::-1]是将第三个维度channel从opencv的BGR转化为pytorch的RGB,然后transpose((2,0,1))的意思是将[height,width,channel]->[channel,height,width]
img_ = img_[np.newaxis,:,:,:]/255.0 #Add a channel at 0 (for batch) | Normalise
img_ = torch.from_numpy(img_).float() #Convert to float
img_ = Variable(img_) # Convert to Variable
return img_
def parse_cfg(cfgfile):
"""
输入: 配置文件路径
返回值: 列表对象,其中每一个元素为一个字典类型对应于一个要建立的神经网络模块(层)
"""
# 加载文件并过滤掉文本中多余内容
file = open(cfgfile, 'r')
lines = file.read().split('\n') # store the lines in a list等价于readlines
lines = [x for x in lines if len(x) > 0] # 去掉空行
lines = [x for x in lines if x[0] != '#'] # 去掉以#开头的注释行
lines = [x.rstrip().lstrip() for x in lines] # 去掉左右两边的空格(rstricp是去掉右边的空格,lstrip是去掉左边的空格)
# cfg文件中的每个块用[]括起来最后组成一个列表,一个block存储一个块的内容,即每个层用一个字典block存储。
block = {}
blocks = []
for line in lines:
if line[0] == "[": # 这是cfg文件中一个层(块)的开始
if len(block) != 0: # 如果块内已经存了信息, 说明是上一个块的信息还没有保存
blocks.append(block) # 那么这个块(字典)加入到blocks列表中去
block = {} # 覆盖掉已存储的block,新建一个空白块存储描述下一个块的信息(block是字典)
block["type"] = line[1:-1].rstrip() # 把cfg的[]中的块名作为键type的值
else:
key,value = line.split("=") #按等号分割
block[key.rstrip()] = value.lstrip()#左边是key(去掉右空格),右边是value(去掉左空格),形成一个block字典的键值对
blocks.append(block) # 退出循环,将最后一个未加入的block加进去
# print('\n\n'.join([repr(x) for x in blocks]))
return blocks
# 配置文件定义了6种不同type
# 'net': 相当于超参数,网络全局配置的相关参数
# {'convolutional', 'net', 'route', 'shortcut', 'upsample', 'yolo'}
# cfg = parse_cfg("cfg/yolov3.cfg")
# print(cfg)
class EmptyLayer(nn.Module):
"""
为shortcut layer / route layer 准备, 具体功能不在此实现,在Darknet类的forward函数中有体现
"""
def __init__(self):
super(EmptyLayer, self).__init__()
class DetectionLayer(nn.Module):
'''yolo 检测层的具体实现, 在特征图上使用锚点预测目标区域和类别, 功能函数在predict_transform中'''
def __init__(self, anchors):
super(DetectionLayer, self).__init__()
self.anchors = anchors
def create_modules(blocks):
net_info = blocks[0] # blocks[0]存储了cfg中[net]的信息,它是一个字典,获取网络输入和预处理相关信息
module_list = nn.ModuleList() # module_list用于存储每个block,每个block对应cfg文件中一个块,类似[convolutional]里面就对应一个卷积块
prev_filters = 3 #初始值对应于输入数据3通道,用来存储我们需要持续追踪被应用卷积层的卷积核数量(上一层的卷积核数量(或特征图深度))
output_filters = [] #我们不仅需要追踪前一层的卷积核数量,还需要追踪之前每个层。随着不断地迭代,我们将每个模块的输出卷积核数量添加到 output_filters 列表上。
for index, x in enumerate(blocks[1:]): #这里,我们迭代block[1:] 而不是blocks,因为blocks的第一个元素是一个net块,它不属于前向传播。
module = nn.Sequential()# 这里每个块用nn.sequential()创建为了一个module,一个module有多个层
#check the type of block
#create a new module for the block
#append to module_list
if (x["type"] == "convolutional"):
''' 1. 卷积层 '''
# 获取激活函数/批归一化/卷积层参数(通过字典的键获取值)
activation = x["activation"]
try:
batch_normalize = int(x["batch_normalize"])
bias = False#卷积层后接BN就不需要bias
except:
batch_normalize = 0
bias = True #卷积层后无BN层就需要bias
filters= int(x["filters"])
padding = int(x["pad"])
kernel_size = int(x["size"])
stride = int(x["stride"])
if padding:
pad = (kernel_size - 1) // 2
else:
pad = 0
# 开始创建并添加相应层
# Add the convolutional layer
# nn.Conv2d(self, in_channels, out_channels, kernel_size, stride=1, padding=0, bias=True)
conv = nn.Conv2d(prev_filters, filters, kernel_size, stride, pad, bias = bias)
module.add_module("conv_{0}".format(index), conv)
#Add the Batch Norm Layer
if batch_normalize:
bn = nn.BatchNorm2d(filters)
module.add_module("batch_norm_{0}".format(index), bn)
#Check the activation.
#It is either Linear or a Leaky ReLU for YOLO
# 给定参数负轴系数0.1
if activation == "leaky":
activn = nn.LeakyReLU(0.1, inplace = True)
module.add_module("leaky_{0}".format(index), activn)
elif (x["type"] == "upsample"):
'''
2. upsampling layer
没有使用 Bilinear2dUpsampling
实际使用的为最近邻插值
'''
stride = int(x["stride"])#这个stride在cfg中就是2,所以下面的scale_factor写2或者stride是等价的
upsample = nn.Upsample(scale_factor = 2, mode = "nearest")
module.add_module("upsample_{}".format(index), upsample)
# route layer -> Empty layer
# route层的作用:当layer取值为正时,输出这个正数对应的层的特征,如果layer取值为负数,输出route层向后退layer层对应层的特征
elif (x["type"] == "route"):
x["layers"] = x["layers"].split(',')
#Start of a route
start = int(x["layers"][0])
#end, if there exists one.
try:
end = int(x["layers"][1])
except:
end = 0
#Positive anotation: 正值
if start > 0:
start = start - index
if end > 0:# 若end>0,由于end= end - index,再执行index + end输出的还是第end层的特征
end = end - index
route = EmptyLayer()
module.add_module("route_{0}".format(index), route)
if end < 0: #若end<0,则end还是end,输出index+end(而end<0)故index向后退end层的特征。
filters = output_filters[index + start] + output_filters[index + end]
else: #如果没有第二个参数,end=0,则对应下面的公式,此时若start>0,由于start = start - index,再执行index + start输出的还是第start层的特征;若start<0,则start还是start,输出index+start(而start<0)故index向后退start层的特征。
filters= output_filters[index + start]
#shortcut corresponds to skip connection
elif x["type"] == "shortcut":
shortcut = EmptyLayer() #使用空的层,因为它还要执行一个非常简单的操作(加)。没必要更新 filters 变量,因为它只是将前一层的特征图添加到后面的层上而已。
module.add_module("shortcut_{}".format(index), shortcut)
#Yolo is the detection layer
elif x["type"] == "yolo":
mask = x["mask"].split(",")
mask = [int(x) for x in mask]
anchors = x["anchors"].split(",")
anchors = [int(a) for a in anchors]
anchors = [(anchors[i], anchors[i+1]) for i in range(0, len(anchors),2)]
anchors = [anchors[i] for i in mask]
detection = DetectionLayer(anchors)# 锚点,检测,位置回归,分类,这个类见predict_transform中
module.add_module("Detection_{}".format(index), detection)
module_list.append(module)
prev_filters = filters
output_filters.append(filters)
return (net_info, module_list)
class Darknet(nn.Module):
def __init__(self, cfgfile):
super(Darknet, self).__init__()
self.blocks = parse_cfg(cfgfile) #调用parse_cfg函数
self.net_info, self.module_list = create_modules(self.blocks)#调用create_modules函数
def forward(self, x, CUDA):
modules = self.blocks[1:] # 除了net块之外的所有,forward这里用的是blocks列表中的各个block块字典
outputs = {} #We cache the outputs for the route layer
write = 0#write表示我们是否遇到第一个检测。write=0,则收集器尚未初始化,write=1,则收集器已经初始化,我们只需要将检测图与收集器级联起来即可。
for i, module in enumerate(modules):
module_type = (module["type"])
if module_type == "convolutional" or module_type == "upsample":
x = self.module_list[i](x)
elif module_type == "route":
layers = module["layers"]
layers = [int(a) for a in layers]
if (layers[0]) > 0:
layers[0] = layers[0] - i
# 如果只有一层时。从前面的if (layers[0]) > 0:语句中可知,如果layer[0]>0,则输出的就是当前layer[0]这一层的特征,如果layer[0]<0,输出就是从route层(第i层)向后退layer[0]层那一层得到的特征
if len(layers) == 1:
x = outputs[i + (layers[0])]
#第二个元素同理
else:
if (layers[1]) > 0:
layers[1] = layers[1] - i
map1 = outputs[i + layers[0]]
map2 = outputs[i + layers[1]]
x = torch.cat((map1, map2), 1)#第二个参数设为 1,这是因为我们希望将特征图沿anchor数量的维度级联起来。
elif module_type == "shortcut":
from_ = int(module["from"])
x = outputs[i-1] + outputs[i+from_] # 求和运算,它只是将前一层的特征图添加到后面的层上而已
elif module_type == 'yolo':
anchors = self.module_list[i][0].anchors
#从net_info(实际就是blocks[0],即[net])中get the input dimensions
inp_dim = int (self.net_info["height"])
#Get the number of classes
num_classes = int (module["classes"])
#Transform
x = x.data # 这里得到的是预测的yolo层feature map
# 在util.py中的predict_transform()函数利用x(是传入yolo层的feature map),得到每个格子所对应的anchor最终得到的目标
# 坐标与宽高,以及出现目标的得分与每种类别的得分。经过predict_transform变换后的x的维度是(batch_size, grid_size*grid_size*num_anchors, 5+类别数量)
x = predict_transform(x, inp_dim, anchors, num_classes, CUDA)
if not write: #if no collector has been intialised. 因为一个空的tensor无法与一个有数据的tensor进行concatenate操作,
detections = x #所以detections的初始化在有预测值出来时才进行,
write = 1 #用write = 1标记,当后面的分数出来后,直接concatenate操作即可。
else:
'''
变换后x的维度是(batch_size, grid_size*grid_size*num_anchors, 5+类别数量),这里是在维度1上进行concatenate,即按照
anchor数量的维度进行连接,对应教程part3中的Bounding Box attributes图的行进行连接。yolov3中有3个yolo层,所以
对于每个yolo层的输出先用predict_transform()变成每行为一个anchor对应的预测值的形式(不看batch_size这个维度,x剩下的
维度可以看成一个二维tensor),这样3个yolo层的预测值按照每个方框对应的行的维度进行连接。得到了这张图处所有anchor的预测值,后面的NMS等操作可以一次完成
'''
detections = torch.cat((detections, x), 1)# 将在3个不同level的feature map上检测结果存储在 detections 里
outputs[i] = x
return detections
# blocks = parse_cfg('cfg/yolov3.cfg')
# x,y = create_modules(blocks)
# print(y)
def load_weights(self, weightfile):
#Open the weights file
fp = open(weightfile, "rb")
#The first 5 values are header information
# 1. Major version number
# 2. Minor Version Number
# 3. Subversion number
# 4,5. Images seen by the network (during training)
header = np.fromfile(fp, dtype = np.int32, count = 5)# 这里读取first 5 values权重
self.header = torch.from_numpy(header)
self.seen = self.header[3]
weights = np.fromfile(fp, dtype = np.float32)#加载 np.ndarray 中的剩余权重,权重是以float32类型存储的
ptr = 0
for i in range(len(self.module_list)):
module_type = self.blocks[i + 1]["type"] # blocks中的第一个元素是网络参数和图像的描述,所以从blocks[1]开始读入
#If module_type is convolutional load weights
#Otherwise ignore.
if module_type == "convolutional":
model = self.module_list[i]
try:
batch_normalize = int(self.blocks[i+1]["batch_normalize"]) # 当有bn层时,"batch_normalize"对应值为1
except:
batch_normalize = 0
conv = model[0]
if (batch_normalize):
bn = model[1]
#Get the number of weights of Batch Norm Layer
num_bn_biases = bn.bias.numel()
#Load the weights
bn_biases = torch.from_numpy(weights[ptr:ptr + num_bn_biases])
ptr += num_bn_biases
bn_weights = torch.from_numpy(weights[ptr: ptr + num_bn_biases])
ptr += num_bn_biases
bn_running_mean = torch.from_numpy(weights[ptr: ptr + num_bn_biases])
ptr += num_bn_biases
bn_running_var = torch.from_numpy(weights[ptr: ptr + num_bn_biases])
ptr += num_bn_biases
#Cast the loaded weights into dims of model weights.
bn_biases = bn_biases.view_as(bn.bias.data)
bn_weights = bn_weights.view_as(bn.weight.data)
bn_running_mean = bn_running_mean.view_as(bn.running_mean)
bn_running_var = bn_running_var.view_as(bn.running_var)
#Copy the data to model 将从weights文件中得到的权重bn_biases复制到model中(bn.bias.data)
bn.bias.data.copy_(bn_biases)
bn.weight.data.copy_(bn_weights)
bn.running_mean.copy_(bn_running_mean)
bn.running_var.copy_(bn_running_var)
else:#如果 batch_normalize 的检查结果不是 True,只需要加载卷积层的偏置项
#Number of biases
num_biases = conv.bias.numel()
#Load the weights
conv_biases = torch.from_numpy(weights[ptr: ptr + num_biases])
ptr = ptr + num_biases
#reshape the loaded weights according to the dims of the model weights
conv_biases = conv_biases.view_as(conv.bias.data)
#Finally copy the data
conv.bias.data.copy_(conv_biases)
#Let us load the weights for the Convolutional layers
num_weights = conv.weight.numel()
#Do the same as above for weights
conv_weights = torch.from_numpy(weights[ptr:ptr+num_weights])
ptr = ptr + num_weights
conv_weights = conv_weights.view_as(conv.weight.data)
conv.weight.data.copy_(conv_weights)