导读
ConvNeXt基于RestNet50,灵感来自于Sw-Transformer,对ResNet50进行改进,仍保证是卷积网路,是篇调参发挥极致的论文
传统卷积与现代VIT性能区别可能来自于训练技巧:
SwT和VIT使用的训练策略,AdamW优化器,带有权重正则化的优化器
数据增强技巧,Mixup,Cutmix,RandAugment,Random Erasing,构造更多的训练集
RestNet50结构 3:4:6:4
每个block有三层卷积,64、128、256等数字是通道数,每个block重复3/4/6/4遍
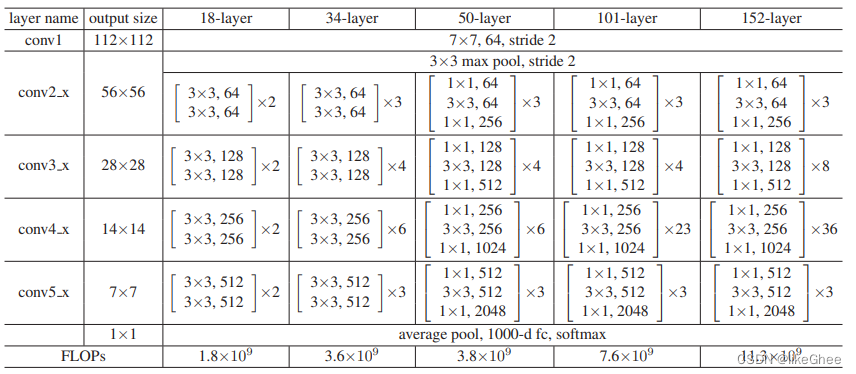
ConvNeXt改成了3:3:9:3,借鉴启发自Sw-T
并将底层卷积替换成4×4 stride=4的卷积,类似patch
使用depth-wise卷积(群卷积),深度可分离卷积,减少计算量的,只是对空间维度进行混合
提升通道数从64提升到96
引入信息瓶颈,transformer中block第一部分是mhsa,第二部分是两层MLP,第一层MLP映射到4倍空间大小上,第二层MLP又将信息还原回一倍空间上,这个是transformer重要的设计,ConvNeXt对block进行一样的设计
激活函数RELU替换成GELU,BN替换成LN
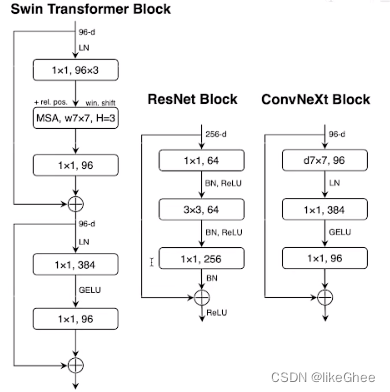
引入更少的激活函数和归一化层
采用2×2,stride=2卷积进行下采样,类似patch merging
底层和下采样之前和最后的平均池化之后之后加入LN层
论文地址
https://openaccess.thecvf.com/content/CVPR2022/papers/Liu_A_
ConvNet_for_the_2020s_CVPR_2022_paper.pdf
代码地址
https://github.com/facebookresearch/ConvNeXt
核心代码 - Block类
核心代码在models文件夹下的convnext.py,这个文件就实现了整个convnext-T模型结构
整个模型有三个部分,第一个部分是stem,对原始图像进行预处理,采用4×4,96,stride=4的卷积
第二部分有4个stage,每一个stage里面都会重复很多个block,重复的次数叫做depth
最后一部分,对特征进行下采样,也就是进行池化,映射到我们要做分类的类别上
一开始定义了block类,尽管每个block的特征维度有一些区别,但是都能把它抽象成一个高层block,因此首先定义一个block
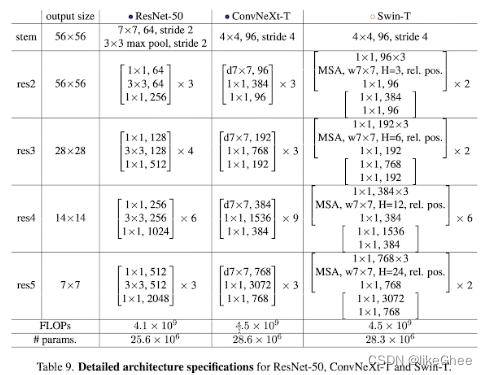
res2 block第一层是一个7×7的群卷积,depth-wise(所以写作d7×7)深度可分离卷积,即group等于in_channel的群卷积,输出通道数是96
block第二层是一个1×1的卷积,没有考虑空间的局部关联性,只做通道融合, 可以看作是2维的MLP,把dim=96映射到了384
第三层也是1×1的卷积,又将第二层的384维度映射回96维度
所以一个block可以看作是一个群卷积加两个MLP构成
一层和二层之间有一个LN,第二层到第三层经过一个GELU
最后输入和输出相加,实现残差结构
class Block(nn.Module):
r""" ConvNeXt Block. There are two equivalent implementations:
(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
We use (2) as we find it slightly faster in PyTorch
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
# depth-wise conv
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim)
self.norm = LayerNorm(dim, eps=1e-6)
# point-wise/1x1 conv, implemented with linear layers
self.pwconv1 = nn.Linear(dim, 4 * dim)
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
init函数实例化了层,有depth-wise conv,LayerNorm,两个MLP(point-wise),GELU激活函数
forward函数,输入送入dwconv,dwconv的输出转置一下维度成(N, C, H,W) -> (N, H, W, C),转置的目的是送入MLP,dim维度做映射
直接送入LN,送入pwconv1,激活函数act,pwconv2
最后把输出还原成标准的卷积格式(N,C,H,W)
完整模型
有了block之后就可以完整定义模型了,模型分为三步,一层是stem层,stem层很简单,就是4×4的卷积stride=4,out_channel=96
stem之后有一个LN
第二层是block数量比例为3:3:9:3的4个stage,两两stage之间进行下采样,一共有4个stage,所以有3个downsample_layer,下采样用的是2×2 stride=2的conv,下采样之前会有一个LN,特征之间是下采样,但是通道数目之间进行上采样,这个想法类似于Swin
定义stage有两层循环,第一层循环是对4个stage遍历,第二层循环是对每一个stage的depth进行遍历,深度依次为3、3、9、3
定义block有一个细节就是dp_rates,随着深度的增大,drop-out比例是越来越大的,最开始的stagedrop out比例比较小
最后是分类模块,比较简单了,首先进行池化,全局平均池化之后有一个LN,卷积过后是一个4维张量,我们池化成2维的张量输入进head,head层,即一个MLP映射到分类维度
对于大型模型,一般head层和特征抽取层分离,特征抽取层写一个forward_features函数,head层在forward函数里面用
完整模型代码:
class ConvNeXt(nn.Module):
r""" ConvNeXt
A PyTorch impl of : `A ConvNet for the 2020s` -
https://arxiv.org/pdf/2201.03545.pdf
Args:
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]
dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]
drop_path_rate (float): Stochastic depth rate. Default: 0.
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1.
"""
def __init__(self, in_chans=3, num_classes=1000,
depths=[3, 3, 9, 3], dims: list = [96, 192, 384, 768], drop_path_rate=0.,
layer_scale_init_value=1e-6, head_init_scale=1.,
):
super().__init__()
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
# 下采样
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
# 4 feature resolution stages, each consisting of multiple residual blocks
self.stages = nn.ModuleList()
dp_rates = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur + j],
layer_scale_init_value=layer_scale_init_value)
for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
self.apply(self._init_weights)
self.head.weight.data.mul_(head_init_scale)
self.head.bias.data.mul_(head_init_scale)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward_features(self, x):
for i in range(4):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
ConvNext Isotropic
各向同性的convnext,所谓各向同性就是每经过一个stage后,不需要对输入特征进行空间上的降维,一直保持embedding dim不变,sequence length也不变,实现isotropic convnext是为了对比VIT模型,进行的消融实验
在官方开源的文件models文件夹下的convnext_isotropic.py实现了各向同性的convnext结构
在isotropic中我们不在需要下采样层了,就只有stem,block层,head层
stem层,16×16卷积,stride=16,out_channel=384
block层,没有4个stage的概念了,不同stage之间也没有下采样了,3+3+9+3一共18个block,block都是dim=384,每个block里面都是3层,第一层是dim=384的depth-wise二维卷积,第二层1×1的dim=384×4的point-wise卷积,第三层是1×1的dim=384的point-wise卷积,输入和最后一层输出进行残差连接,一共进行18次
head层,首先进行平均池化,送入head分类
执行main.py
查看main.py可以发现,使用了argparse库,在get_args_parser()发现有很多可选参数可以去指定,一般argparse库都是在linux系统使用的多,写一个bash调用main.py,但像我们windows系统一般在脚本文件里直接调试会比较方便
我们主要是需要指定一下data_path数据路径(下载的数据放到这里)和data_set指定数据集
那么如何解析的时候把参数传进去呢?
像这样,如果是必选参数:
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('echo')
args = parser.parse_args(['hello world!'])
print(args.echo)
如果是可选参数
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--echo')
args = parser.parse_args(['--echo', 'hello world!'])
print(args.echo)
回到main.py,我们在根目录下创建dataset/cifar文件夹存放dataset数据集
然后修改args一行代码,替换成如下代码
args = parser.parse_args(['--data_path', 'dataset/cifar',
'--data_set', 'CIFAR',
'--device', 'cpu'])
配置一下args参数,因为我是CPU没有装cuda,device需要配一下,如果有cuda就不用配device了
这里有个巨坑,如果cpu跑起来的话,需要改两个地方
第一处是timm库里的Mixup类,手动给Mixup类添加个self.device属性,然后在main.py大约277行,Mixup实例化多传一个device参数,然后修改timm\data\mixup.py,大概是217行,target = mixup_target(target, self.num_classes, lam, self.label_smoothing)多传一个self.device参数进去,如果嫌太麻烦就或者直接写死target = mixup_target(target, self.num_classes, lam, self.label_smoothing, ‘cpu’)
然后engine.py里的大约84行修改成
if torch.cuda.is_available():
torch.cuda.synchronize()
学习其main.py写法
它导入了timm这个库,这个库在计算机视觉领域是非常好的一个库,基本上把很多CV的模型都实现好了
在datasets导入了build_dataset,写了一个datasets.py如何去导入数据集,定义了一个build_transform()对原始图片进行一些列的变换,根据args中的data_set参数下载相应的数据集,有CIFAR,IMNET,image_folder
我们可以学习一下他们argparse的写法,通过parent参数,用parents=[get_args_parser()]专门传入Argument超参数
main函数定义训练函数, utils.init_distributed_mode(args)支持多机多卡训练,utils是他们自己写的代码,init_distributed_mode初始化多级多卡训练的配置, 主节点IP和端口等等都是在这里设置的,如果想要多机多卡训练可以认真看一下这一部分的代码
num_tasks = utils.get_world_size(),定义一共有多少个节点
global_rank = utils.get_rank()表示当前这个节点在第几个节点上跑的
获得一个sampler,获取在每个节点上我们拿到的数据索引是什么
sampler_train = torch.utils.data.DistributedSampler(
dataset_train, num_replicas=num_tasks, rank=global_rank, shuffle=True, seed=args.seed,
)
种子seed设置,固定种子用于复现,fix the seed for reproducibility
开启了benchmark, cudnn.benchmark = True,找到最优卷积算法
if global_rank == 0 and args.log_dir is not None:
表示我们设置了日志目录,那么只在主节点上记录日志
torch.utils.data.DataLoader定义DataLoader
create_model从timm库导入,timm实现了很多计算机视觉的模型,我们只需要把模型名称传入到create_model函数就能获得这个模型的实例,像这里就传入了convnext_tiny,但这个模型直接是从@register_model配置过来的,在models文件夹下的convnext.py中有使用到@register_model注解
如果是分布式训练就传入torch.nn.parallel.DistributedDataParallel获得model
create_optimizer是作者自己写的优化器
作者自己写的utils.auto_load_model自动导入模型,获取所有的checkpoint-*.pth,取数字最大的checkpoint视为最新的文件
也可以传入args.resume来导入checkpoint
checkpoint = torch.load(args.resume, map_location=‘cpu’)
save_model保存模型,output_dir指定保存路径,保存内容:
'model': model_without_ddp.state_dict(),
'optimizer': optimizer.state_dict(),
'epoch': epoch,
'scaler': loss_scaler.state_dict(),
'args': args,
save_on_master在主节点才保存