目录
一:什么是redis sentinel
哨兵又名redis sentinel,在生产环境中,不免会有意外原因导致redis服务器挂掉,如果此时挂掉的是一个master节点,主节点宕机,主从复制将不能继续进行,写数据将会阻塞,而哨兵的存在主要是为了切换掉宕机的master,然后从master下面的slave节点中选举一个作为新的master,并且把旧的master的slave全部转移到新的master上面,继续原有的主从复制,保证了redis主从复制的HA。
哨兵本身是一个独立的进程,本身也是有单点问题的,所以哨兵也有自身的集群,用来保证哨兵本身的容错机制。
图解:
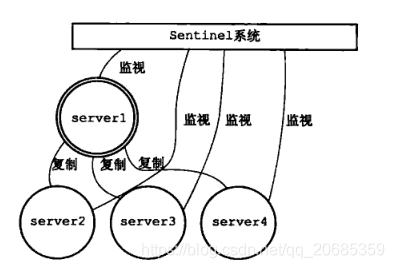
图1:正常运行
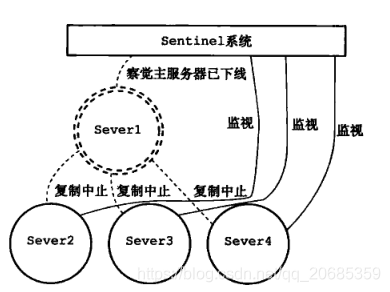
图2:master宕机
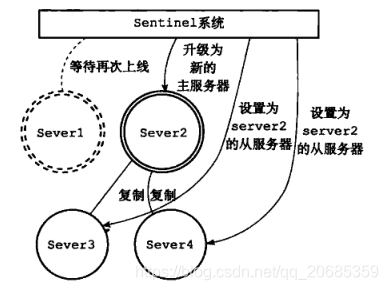
图3:哨兵选举新的master
哨兵的工作流程
1):每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令。
2):如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel 标记为主观下线。
3):如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
4):当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线 。
5):在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令 。
6):当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次 。
7):若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会被移除。
若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。
二:哨兵机制下的数据丢失
Q:哨兵机制可否让redis避免数据丢失?
A:哨兵本身作用于集群状态的高可用,作用于master节点挂掉后的主备切换,不能解决redis本身丢失数据的相关问题。
场景1:master挂掉
因为redis的数据同步是异步的,所以,当写完master后,master还没有来得及同步slave节点的时候自身就挂掉了,此时写到master的这部分数据就会丢失。
场景2:脑裂情况
脑裂情况一般出现于网络分区,此时的master并没有挂掉,而是“正常的”提供服务中,但是哨兵不认为该master是正常的,哨兵会重新选举出来master,此时出现新的master,由于哨兵在选举master是有一定的时间延迟的,导致通知client新的master服务地址延迟,所以可能还会有client去写旧的的master,等网络分区结束后, 旧的master会同步新的master的数据,丢弃掉自己未同步的数据,此时,数据丢失。
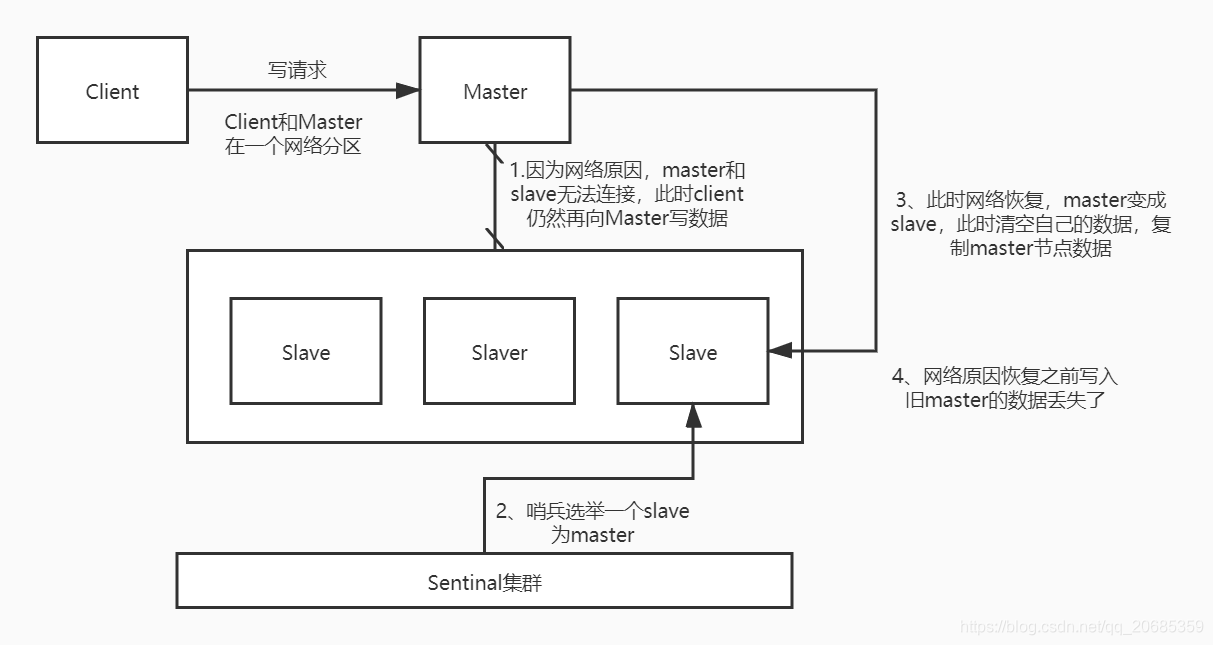
三:哨兵机制下数据丢失解决方案
数据丢失带来的问题就是一致性的下降(CAP),然而当业务不能容忍一致性下降到一定程度的时候就要适当去降低服务的可用性来保证数据的一致性。
redis数据丢失解决方案
CAP中的C和A无法同时兼容,目前的数据一致性C在逐渐地降低,已经不能容忍业务的需要,此时就需要降低A可用性来保证C,如果slave复制请求在得到ack超时达到min-slaves-max-lag配置时候,并且有一定的slave数量,此时master对外终止响应。(分布式系统在实现CAP都是C和A的一个动态抉择,如:KAFKA的ISR列表为空用户可以选择使用OSR【降低一致性】)列表或者终暂停服务(降低可用性))
四:哨兵本身的机制和原理
sdown & odown
sdown代表主观宕机,odown代表客观宕机
主观宕机是哨兵的一个节点发送心跳在规定时间(该时间可配置)内没有收到回复,哨兵则认为该master宕机,那么该master就是主观宕机,这是一个哨兵节点的主观臆断,很明显主观宕机不"准确",此时需要客观去判断是否真正的宕机了,此时该哨兵节点会通知其他哨兵节点去探测该master的状况,如果超过quorum的都认为该master节点宕机,那么就客观的认为master真正宕机。注:quorum一般配置为过半。
哨兵本身通讯机制
哨兵本身通过pub/sub来通信,哨兵会往__sentinel__:hello的chanel发送消息,其他哨兵可以得到消息
哨兵和redis集群的通信机制
redis哨兵通过gossip protocols协议和集群中节点通信,可以用来发现集群中节点的状态,gossip又成流言协议,一传十,十传百,最终集群节点可以互相知道彼此之间的存在,在此不细说gossip(gossip讲述比较清晰的一篇文章)。
哨兵集群本身的master选举机制(raft协议)
当sentinel节点完成了对master主观宕机下线后,sentinel集群会选举出来一个leader用来主持新的master选举工作,以及后续故障转移,在此使用到了大名鼎鼎的raft协议去选举,在此和zookeeper的zab协议较为类似,大致流程如下:
1 发现redis master挂掉的哨兵节点X会向其他节点会发起选举;
2 如果其他节点没有进行过投票,则会向X投票表示赞同;
3 当有过半的节点同意X的选举,此时X很高兴的成为master。
4 有一种情况就是有多个节点同时发现redis master挂掉,可能会同时发起投票,针对同时发起投票,有可能出现没有任何节点当选,此时每个参选节点等待一个随机时间failover_start_time+1s内随机数,然后进行下一轮选举,这点和raft协议雷同,在raft中随机时间为election timeout。
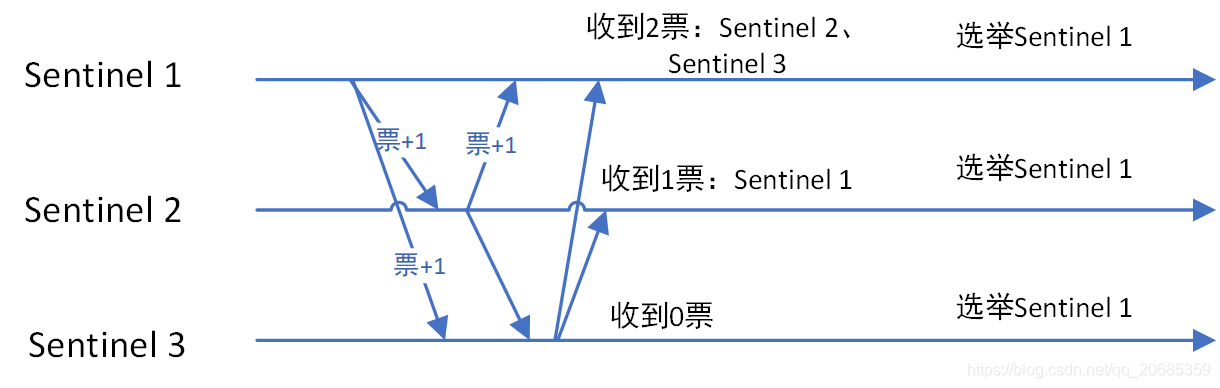
redis集群的master选举机制
首先会从哨兵集群中选举出来一个master作用于集群中的主备切换,哨兵自身选举算法为raft算法。
当redis集群中的master因为某些原因挂掉的时候,此时如果该master下有多个slave,怎么确定哪一个可以晋为master,在此master的选举是有条件的
1.和master断开的时间,如果副本与主服务器断开连接的时间超过已配置主服务器超时的十倍,该slave不会成为master
2.每个slave都是有优先级的,会优先选举优先级比较高的,redis.conf中配置的replica-priority
3.其次当优先级一致的情况下,会选举数据同步最多的。
4.当上述两个条件均满足的时候,哪一个节点最先启动,优先成为master(slaves中runid最小的)
思考:
redis丢失数据会带来什么问题
Q:使用redis实现的分布式锁还可靠吗?
A:引入Quorum NWR(NWR),效仿ZK & DynamoDB