原生map的“先天不足”
对于已经初始化了的原生map,我们可以尽情地对其进行并发读:
package main
import (
"fmt"
"math/rand"
"sync"
)
func main() {
var wg sync.WaitGroup
var m = make(map[int]int, 100)
for i := 0; i < 100; i++ {
m[i] = i
}
wg.Add(10)
for i := 0; i < 10; i++ {
// 并发读
go func(i int) {
for j := 0; j < 100; j++ {
n := rand.Intn(100)
fmt.Printf("goroutine[%d] read m[%d]: %d\n", i, n, m[n])
}
wg.Done()
}(i)
}
wg.Wait()
}
但原生map一个最大的问题就是不支持多goroutine并发写。Go runtime内置对原生map并发写的检测,一旦检测到就会以panic的形式阻止程序继续运行,比如下面这个例子:
package main
import (
"math/rand"
"sync"
)
func main() {
var wg sync.WaitGroup
var m = make(map[int]int, 100)
for i := 0; i < 100; i++ {
m[i] = i
}
wg.Add(10)
for i := 0; i < 10; i++ {
// 并发写
go func(i int) {
for n := 0; n < 100; n++ {
n := rand.Intn(100)
m[n] = n
}
wg.Done()
}(i)
}
wg.Wait()
}
运行上面这个并发写的例子,我们很大可能会得到下面panic:
$go run concurrent_builtin_map_write.go
fatal error: concurrent map writes
... ...
原生map的“先天不足”让其无法直接胜任某些场合的要求,于是gopher们便寻求其他路径。一种路径无非是基于原生map包装出一个支持并发读写的自定义map类型,比如,最简单的方式就是用一把互斥锁(sync.Mutex)同步各个goroutine对map内数据的访问;如果读多写少,还可以利用读写锁(sync.RWMutex)来保护map内数据,减少锁竞争,提高并发读的性能。很多第三方map的实现原理也大体如此。
另外一种路径就是使用sync.Map。
sync.Map逻辑
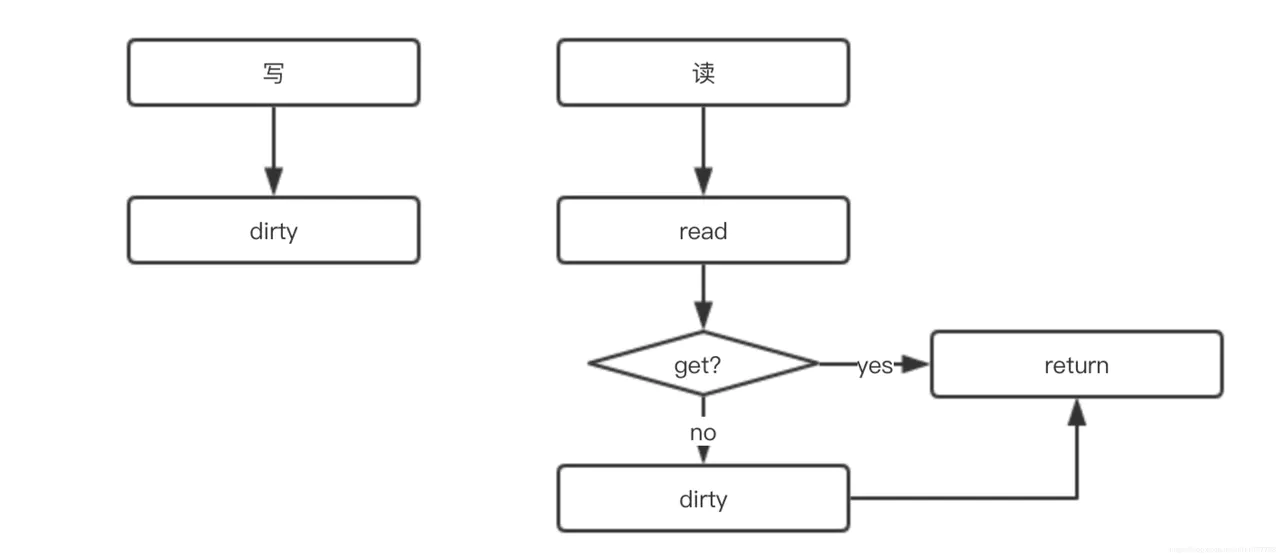
写:直写。
读:先读read,没有再读dirty。
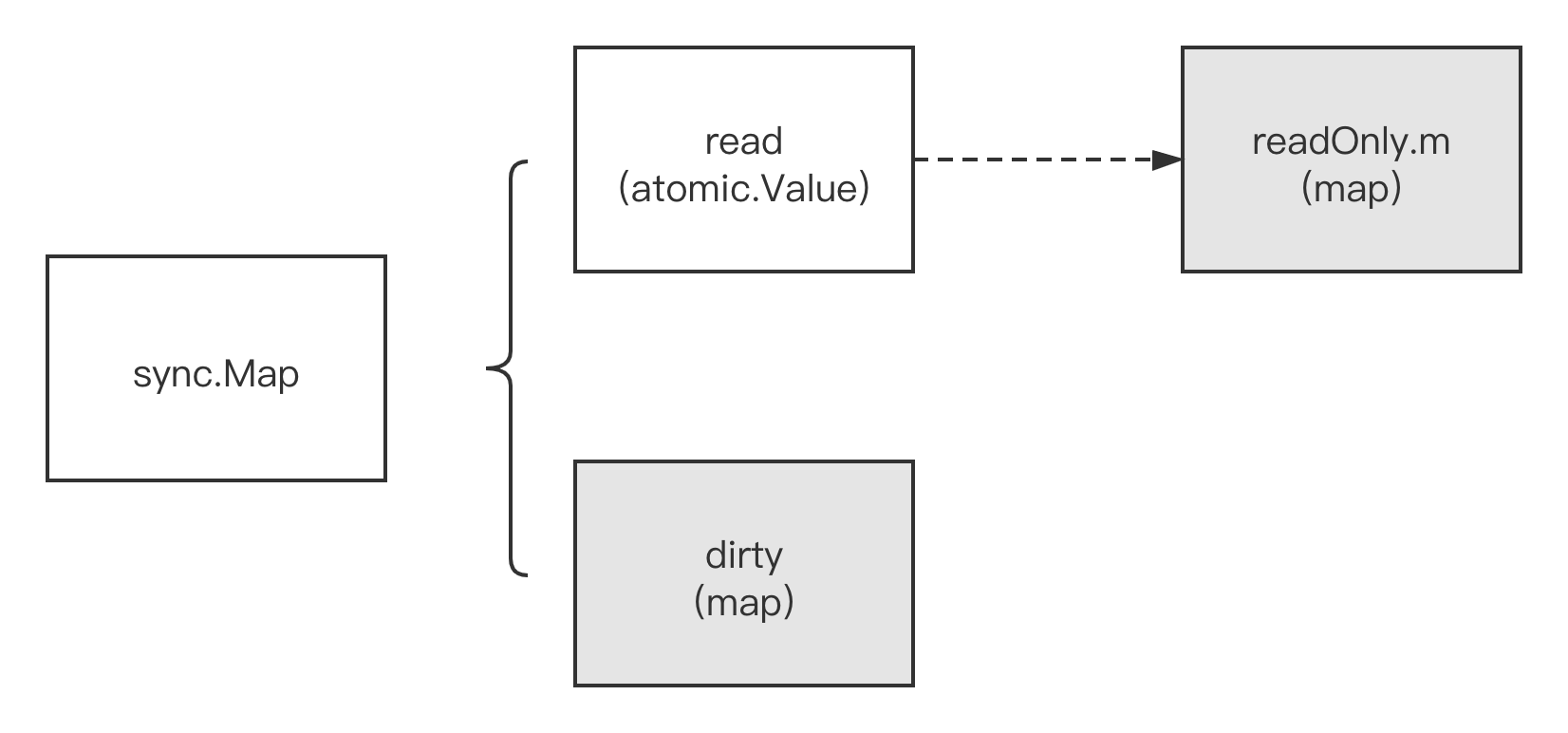
sync.Map底层使用了两个原生map,一个叫read,仅用于读;一个叫dirty,用于在特定情况下存储最新写入的key-value数据:
read(这个map)好比整个sync.Map的一个“高速缓存”,当goroutine从sync.Map中读取数据时,sync.Map会首先查看read这个缓存层是否有用户需要的数据(key是否命中),如果有(命中),则通过原子操作将数据读取并返回,这是sync.Map推荐的快路径(fast path),也是为何上面基准测试结果中读操作性能极高的原因。
基础结构
sync.Map的核心数据结构:
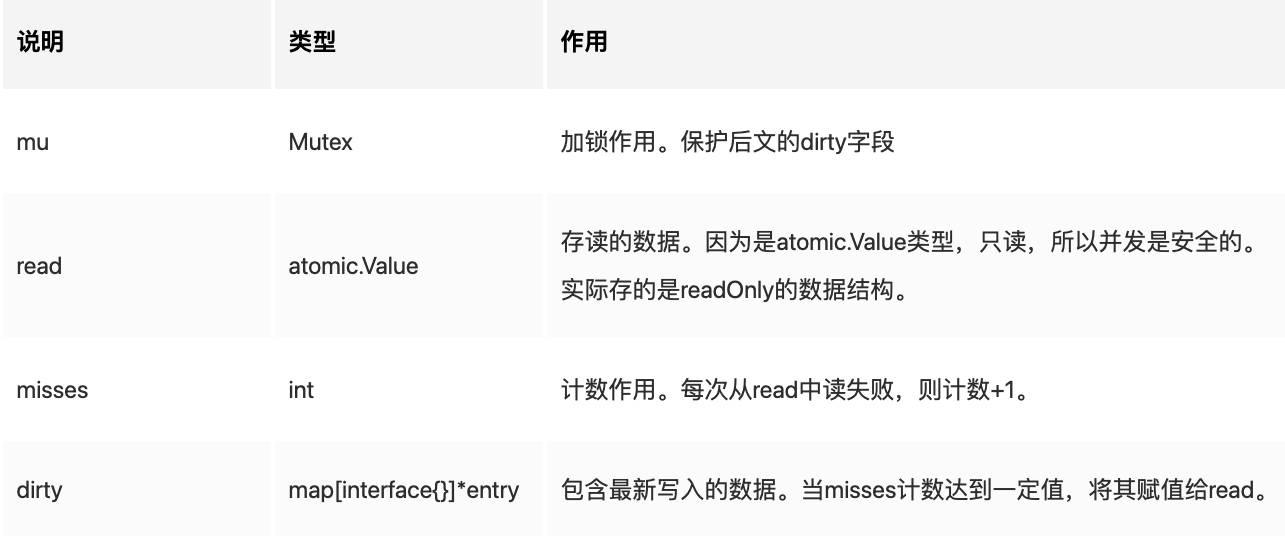
type Map struct {
mu Mutex
read atomic.Value // readOnly
dirty map[interface{}]*entry
misses int
}
这里有必要简单描述一下,大概的逻辑,
readOnly的数据结构:
type readOnly struct {
m map[interface{}]*entry
amended bool
}
entry的数据结构:

type entry struct {
//可见value是个指针类型,虽然read和dirty存在冗余情况(amended=false),但是由于是指针类型,存储的空间应该不是问题
p unsafe.Pointer // *interface{}
}
这个结构体主要是想说明。虽然前文read和dirty存在冗余的情况,但是由于value都是指针类型,其实存储的空间其实没增加多少。
原理
接下来,我们给位于~/go/src/github.com/bigwhite/experiments/inside-syncmap/syncmap/sync下面的map.go中(sync.Map包的副本)添加一个Map类型的新方法Dump:
func (m *Map) Dump() {
fmt.Printf("=====> sync.Map:\n")
// dump read
read, ok := m.read.Load().(readOnly)
fmt.Printf("\t read(amended=%v):\n", read.amended)
if ok {
// dump readOnly's map
for k, v := range read.m {
fmt.Printf("\t\t %#v:%#v\n", k, v)
}
}
// dump dirty
fmt.Printf("\t dirty:\n")
for k, v := range m.dirty {
fmt.Printf("\t\t %#v:%#v\n", k, v)
}
// dump miss
fmt.Printf("\t misses:%d\n", m.misses)
// dump expunged
fmt.Printf("\t expunged:%#v\n", expunged)
fmt.Printf("<===== sync.Map\n")
}
这个方法将打印Map的内部状态以及read、dirty两个原生map中的所有key-value对,这样我们在初始状态、store key-value后、load key以及delete key后通过Dump方法输出sync.Map状态便可以看到不同操作后sync.Map内部的状态变化,从而间接了解sync.Map的工作原理。下面我们就分情况剖析sync.Map的行为特征。
1. 初始状态
sync.Map是零值可用的,我们可以像下面这样定义一个sync.Map类型变量,并无需做显式初始化。
var m sync.Map
我们通过Dump输出初始状态下的sync.Map的内部状态:
func main() {
var m sync.Map
fmt.Println("sync.Map init status:")
m.Dump()
... ...
}
运行后,输出如下:
sync.Map init status:
=====> sync.Map:
read(amended=false):
dirty:
misses:0
expunged:(unsafe.Pointer)(0xc0001101e0)
<===== sync.Map
在初始状态下,dirty和read两个内置map内都无数据。expunged是一个哨兵变量(也是一个包内的非导出变量),它在sync.Map包初始化时就有了一个固定的值。该变量在后续用于元素删除场景(删除的key并不立即从map中删除,而是将其value置为expunged)以及load场景。如果哪个key值对应的value值与explunged一致,说明该key已经被map删除了(即便该key所占用的内存资源尚未释放)。
var expunged = unsafe.Pointer(new(interface{}))
2. 写入数据(store)
下面,我们向Map写入一条数据:
type val struct {
s string
}
func main() {
... ...
val1 := &val{"val1"}
m.Store("key1", val1)
fmt.Println("\nafter store key1:")
m.Dump()
... ...
}
我们看一下存入新数据后,Map内部的状态:
after store key1:
=====> sync.Map:
read(amended=true):
dirty:
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000108080)}
misses:0
expunged:(unsafe.Pointer)(0xc000108040)
<===== sync.Map
我们看到写入(key1,value1)后,Map中有两处变化,一处是dirty map,新写入的数据存储在dirty map中;第二处是read中的amended值由false变为了true,表示dirty map中存在某些read map还没有的key。
3. dirty提升(promoted)为read
此时,如果我们调用一次sync.Map的Load方法,无论传给Load的key值是否为”key1″还是其他,sync.Map内部都会发生较大变化,我们来看一下:
m.Load("key2") //这里我们尝试load key="key2"
fmt.Println("\nafter load key2:")
m.Dump()
下面是Load方法调用后Dump方法输出的内容:
after load key2:
=====> sync.Map:
read(amended=false):
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000010240)}
dirty:
misses:0
expunged:(unsafe.Pointer)(0xc000010200)
<===== sync.Map
我们看到:原dirty map中的数据被提升(promoted)到read map中了,提升后amended值重新变回false。
结合sync.Map中Load方法的源码,我们得出如下sync.Map的工作原理:当Load方法在read map中没有命中(miss)传入的key时,该方法会再次尝试在dirty中继续匹配key;无论是否匹配到,Load方法都会在锁保护下调用missLocked方法增加misses的计数(+1);如果增加完计数的misses值大于等于dirty map中的元素个数,则会将dirty中的元素整体提升到read:
func (m *Map) missLocked() {
m.misses++ //计数+1
if m.misses < len(m.dirty) {
return
}
m.read.Store(readOnly{m: m.dirty}) // dirty提升到read
m.dirty = nil // dirty置为nil
m.misses = 0 // misses计数器清零
}
为了验证上述promoted的条件,我们再来做一组实验:
val2 := &val{"val2"}
m.Store("key2", val2)
fmt.Println("\nafter store key2:")
m.Dump()
val3 := &val{"val3"}
m.Store("key3", val3)
fmt.Println("\nafter store key3:")
m.Dump()
m.Load("key1")
fmt.Println("\nafter load key1:")
m.Dump()
m.Load("key2")
fmt.Println("\nafter load key2:")
m.Dump()
m.Load("key2")
fmt.Println("\nafter load key2 2nd:")
m.Dump()
m.Load("key2")
fmt.Println("\nafter load key2 3rd:")
m.Dump()
在完成一次promoted动作之后,我们又向sync.Map中写入两个key:key2和key3,并在后续Load一次key1并连续三次Load key2,下面是Dump方法的输出结果:
after store key2:
=====> sync.Map:
read(amended=true):
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000010240)}
dirty:
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000010240)}
"key2":&smap.entry{p:(unsafe.Pointer)(0xc000010290)}
misses:0
expunged:(unsafe.Pointer)(0xc000010200)
<===== sync.Map
after store key3:
=====> sync.Map:
read(amended=true):
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000010240)}
dirty:
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000010240)}
"key2":&smap.entry{p:(unsafe.Pointer)(0xc000010290)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc0000102c0)}
misses:0
expunged:(unsafe.Pointer)(0xc000010200)
<===== sync.Map
after load key1:
=====> sync.Map:
read(amended=true):
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000010240)}
dirty:
"key3":&smap.entry{p:(unsafe.Pointer)(0xc0000102c0)}
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000010240)}
"key2":&smap.entry{p:(unsafe.Pointer)(0xc000010290)}
misses:0
expunged:(unsafe.Pointer)(0xc000010200)
<===== sync.Map
after load key2:
=====> sync.Map:
read(amended=true):
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000010240)}
dirty:
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000010240)}
"key2":&smap.entry{p:(unsafe.Pointer)(0xc000010290)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc0000102c0)}
misses:1
expunged:(unsafe.Pointer)(0xc000010200)
<===== sync.Map
after load key2 2nd:
=====> sync.Map:
read(amended=true):
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000010240)}
dirty:
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000010240)}
"key2":&smap.entry{p:(unsafe.Pointer)(0xc000010290)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc0000102c0)}
misses:2
expunged:(unsafe.Pointer)(0xc000010200)
<===== sync.Map
after load key2 3rd:
=====> sync.Map:
read(amended=false):
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000010240)}
"key2":&smap.entry{p:(unsafe.Pointer)(0xc000010290)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc0000102c0)}
dirty:
misses:0
expunged:(unsafe.Pointer)(0xc000010200)
<===== sync.Map
我们看到在写入key2这条数据后,dirty中不仅存储了key2这条数据,原read中的key1数据也被复制了一份存入到dirty中。这个操作是由sync.Map的dirtyLocked方法完成的:
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[interface{}]*entry, len(read.m))
for k, e := range read.m {
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
前面我们提到过,promoted(dirty -> read)是一个整体的指针交换操作,promoted时,sync.Map直接将原dirty指针store给read并将自身置为nil,因此sync.Map要保证amended=true时,dirty中拥有整个Map的全量数据,这样在下一次promoted(dirty -> read)时才不会丢失数据。不过dirtyLocked是通过一个迭代实现的元素从read到dirty的复制,如果Map中元素规模很大,这个过程付出的损耗将很大,并且这个过程是在锁保护下的。
在存入key3后,我们调用Load方法先load了key1,由于key1在read中有记录,因此此次load命中了,走的是快路径,对Map状态没有任何影响。
之后,我们又Load了key2,key2不在read中,因此产生了一次miss。misses增加计数后的值为1,而此时dirty中的元素数量为3,不满足promote的条件,于是没有执行promote操作。后续我们又连续进行了两次key2的Load操作,产生了两次miss事件后,misses的计数值等于了dirty中的元素数量,于是promote操作被执行,dirty map整体被置换给read,自己则变成了nil。
4. 更新已存在的key
我们再来看一下更新已存在的key的值的情况。首先是该key仅存在于read中(刚刚promote完毕),而不在dirty中。我们更新这时仅在read中存在的key2的值:
val2_1 := &val{"val2_1"}
m.Store("key2", val2_1)
fmt.Println("\nafter update key2(in read, not in dirty):")
m.Dump()
下面是Dump输出的结果:
after update key2(in read, not in dirty):
=====> sync.Map:
read(amended=false):
"key1":&smap.entry{p:(unsafe.Pointer)(0xc00008e220)}
"key2":&smap.entry{p:(unsafe.Pointer)(0xc00008e2d0)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc00008e2a0)}
dirty:
misses:0
expunged:(unsafe.Pointer)(0xc00008e1e0)
<===== sync.Map
我们看到sync.Map直接更新了位于read中的key2的值(entry.storeLocked方法实现的),dirty和其他字段没有受到影响。
第二种情况是该key刚store到dirty中,尚未promote,不在read中。我们新增一个key4,并更新其值:
val4 := &val{"val4"}
m.Store("key4", val4)
fmt.Println("\nafter store key4:")
m.Dump()
val4_1 := &val{"val4_1"}
m.Store("key4", val4_1)
fmt.Println("\nafter update key4(not in read, in dirty):")
m.Dump()
dump方法的输出结果如下:
after store key4:
=====> sync.Map:
read(amended=true):
"key1":&smap.entry{p:(unsafe.Pointer)(0xc00008e220)}
"key2":&smap.entry{p:(unsafe.Pointer)(0xc00008e2d0)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc00008e2a0)}
dirty:
"key1":&smap.entry{p:(unsafe.Pointer)(0xc00008e220)}
"key2":&smap.entry{p:(unsafe.Pointer)(0xc00008e2d0)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc00008e2a0)}
"key4":&smap.entry{p:(unsafe.Pointer)(0xc00008e310)}
misses:0
expunged:(unsafe.Pointer)(0xc00008e1e0)
<===== sync.Map
after update key4(not in read, in dirty):
=====> sync.Map:
read(amended=true):
"key1":&smap.entry{p:(unsafe.Pointer)(0xc00008e220)}
"key2":&smap.entry{p:(unsafe.Pointer)(0xc00008e2d0)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc00008e2a0)}
dirty:
"key1":&smap.entry{p:(unsafe.Pointer)(0xc00008e220)}
"key2":&smap.entry{p:(unsafe.Pointer)(0xc00008e2d0)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc00008e2a0)}
"key4":&smap.entry{p:(unsafe.Pointer)(0xc00008e330)}
misses:0
expunged:(unsafe.Pointer)(0xc00008e1e0)
<===== sync.Map
我们看到,sync.Map同样是直接将key4对应的value重新设置为新值(val4_1)。
5. 删除key
为了方便查看,我们将上述Map状态回滚到刚刚promote(dirty -> read)完的时刻,即:
after load key2 3rd:
=====> sync.Map:
read(amended=false):
"key1":&smap.entry{p:(unsafe.Pointer)(0xc00008e220)}
"key2":&smap.entry{p:(unsafe.Pointer)(0xc00008e270)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc00008e2a0)}
dirty:
misses:0
expunged:(unsafe.Pointer)(0xc00008e1e0)
<===== sync.Map
删除key也有几种情况,我们分别来看一下:
删除的key仅存在于read中
我们删除上面Map中仅存在于read中的key2:
m.Delete("key2")
fmt.Println("\nafter delete key2:")
m.Dump()
删除后的Dump结果如下:
after delete key2:
=====> sync.Map:
read(amended=false):
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000010240)}
"key2":&smap.entry{p:(unsafe.Pointer)(nil)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc0000102c0)}
dirty:
misses:0
expunged:(unsafe.Pointer)(0xc000010200)
<===== sync.Map
我们看到sync.Map并没有删除key2,而是将其value置为nil。
删除的key仅存在于dirty中
为了构造初仅存在于dirty中的key,我们向sync.Map写入新数据key4,然后再立刻删除它
val4 := &val{"val4"}
m.Store("key4", val4)
fmt.Println("\nafter store key4:")
m.Dump()
m.Delete("key4")
fmt.Println("\nafter delete key4:")
m.Dump()
上述代码的Dump结果如下:
after store key4:
=====> sync.Map:
read(amended=true):
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000104220)}
"key2":&smap.entry{p:(unsafe.Pointer)(0xc0001041e0)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc0001042a0)}
dirty:
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000104220)}
"key4":&smap.entry{p:(unsafe.Pointer)(0xc0001042f0)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc0001042a0)}
misses:0
expunged:(unsafe.Pointer)(0xc0001041e0)
<===== sync.Map
after delete key4:
=====> sync.Map:
read(amended=true):
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000104220)}
"key2":&smap.entry{p:(unsafe.Pointer)(0xc0001041e0)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc0001042a0)}
dirty:
"key3":&smap.entry{p:(unsafe.Pointer)(0xc0001042a0)}
"key1":&smap.entry{p:(unsafe.Pointer)(0xc000104220)}
misses:0
expunged:(unsafe.Pointer)(0xc0001041e0)
<===== sync.Map
我们看到:和仅在read中的情况不同(仅将value设置为nil),仅存在于dirty中的key被删除后,该key就不再存在了。这里还有一点值得注意的是:当向dirty写入key4时,dirty会复制read中的未被删除的元素,由于key2已经被删除,因此顺带将read中的key2对应的value设置为哨兵(expunged),并且该key不会被加入到dirty中。直到下一次promote,该key才会被回收(因为read被交换指向新的dirty,原read指向的内存将被GC)。
删除的key既存在于read,也存在于dirty中
目前上述sync.Map实例中既存在于read,也存在于dirty中的key有key1和key3(key2已经被删除),我们这里以删除key1为例:
after delete key1:
=====> sync.Map:
read(amended=true):
"key2":&smap.entry{p:(unsafe.Pointer)(0xc0001041e0)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc0001042a0)}
"key1":&smap.entry{p:(unsafe.Pointer)(nil)}
dirty:
"key3":&smap.entry{p:(unsafe.Pointer)(0xc0001042a0)}
"key1":&smap.entry{p:(unsafe.Pointer)(nil)}
misses:0
expunged:(unsafe.Pointer)(0xc0001041e0)
<===== sync.Map
我们看到删除key1后,read和dirty两个map中的key1均没有真正删除,而是将其value设置为nil。
我们再触发一次promote:连续调用两次导致read miss的LOAD:
m.Load("key5")
fmt.Println("\nafter load key5:")
m.Dump()
m.Load("key5")
fmt.Println("\nafter load key5 2nd:")
m.Dump()
调用后的Dump输出如下:
after load key5:
=====> sync.Map:
read(amended=true):
"key1":&smap.entry{p:(unsafe.Pointer)(nil)}
"key2":&smap.entry{p:(unsafe.Pointer)(0xc000010200)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc0000102c0)}
dirty:
"key3":&smap.entry{p:(unsafe.Pointer)(0xc0000102c0)}
"key1":&smap.entry{p:(unsafe.Pointer)(nil)}
misses:1
expunged:(unsafe.Pointer)(0xc000010200)
<===== sync.Map
after load key5 2nd:
=====> sync.Map:
read(amended=false):
"key1":&smap.entry{p:(unsafe.Pointer)(nil)}
"key3":&smap.entry{p:(unsafe.Pointer)(0xc0000102c0)}
dirty:
misses:0
expunged:(unsafe.Pointer)(0xc000010200)
<===== sync.Map
我们看到虽然dirty中的key1已经处于被删除状态,但它仍算作dirty元素的个数,因此第二次miss才会触发promote。promote后,dirty被赋值给read,因此原dirty中的key1元素就顺带进入到read中,只能等下次写入一个不存在的新key时才能被置为哨兵值,并在下一次promote时才能被真正删除释放。
总结
优点:是官方出的,是亲儿子;通过读写分离,降低锁时间来提高效率;
缺点:不适用于大量写的场景,这样会导致read map读不到数据而进一步加锁读取,同时dirty map也会一直晋升为read map,整体性能较差。 适用场景:大量读,少量写
原文链接:
https://tonybai.com/2020/11/10/understand-sync-map-inside-through-examples/
https://juejin.cn/post/6844903895227957262