概述
定义
ClickHouse官网地址 https://clickhouse.com/ 最新版本22.4.5.9
ClickHouse官网文档地址 https://clickhouse.com/docs/zh
ClickHouseGitHub源码地址 https://github.com/ClickHouse/ClickHouse
ClickHouse是俄罗斯的 Yandex 于 2016 年开源的用于在线分析处理查询(OLAP :Online Analytical Processing)MPP架构的列式存储数据库(DBMS:Database Management System),能够使用 SQL 查询实时生成分析数据报告。ClickHouse的全称是Click Stream,Data WareHouse。ClickHouse可以做用户行为分析,流批一体,其线性扩展和可靠性保障能够原生支持 分片和副本,shard + replication,ClickHouse没有走hadoop生态自己实现分布式存储。
- OLAP场景的关键特征
- 绝大多数是读请求
- 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
- 已添加到数据库的数据不能修改。
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 宽表,即每个表包含着大量的列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每个查询有一个大表。除了他以外,其他的都很小。
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
- 很容易可以看出,OLAP场景与其他通常业务场景(例如,OLTP或K/V)有很大的不同, 因此想要使用OLTP或Key-Value数据库去高效的处理分析查询场景,并不是非常完美的适用方案。例如,使用OLAP数据库去处理分析请求通常要优于使用MongoDB或Redis去处理分析请求。
- 列式数据库更适合OLAP场景的原因
- 针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中你可以只读取你需要的数据。例如,如果只需要读取100列中的5列,这将帮助你最少减少20倍的I/O消耗。
- 由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储这也更容易压缩。这进一步降低了I/O的体积。
- 由于I/O的降低,这将帮助更多的数据被系统缓存。
- CPU
- 向量引擎:所有的操作都是为向量而不是为单个值编写的。这意味着多个操作之间的不再需要频繁的调用,并且调用的成本基本可以忽略不计。操作代码包含一个优化的内部循环。
- 代码生成:生成一段代码,包含查询中的所有操作。
特性
- 真正的列式数据库管理系统:ClickHouse不单单是一个数据库, 它是一个数据库管理系统。因为它允许在运行时创建表和数据库、加载数据和运行查询,而无需重新配置或重启服务.
- 数据压缩:支持通用压缩编解码器之外,ClickHouse还提供针对特定类型数据的专用编解码器。
- 数据的磁盘存储:ClickHouse被设计用于工作在传统磁盘上的系统,它提供每GB更低的存储成本,但如果可以使用SSD和内存,它也会合理的利用这些资源。
- 多核心并行处理
- 多服务器分布式处理
- 支持SQL
- 向量引擎
- 实时的数据更新
- 索引
- 适合在线查询
- 支持近似计算
- 自适应连接算法
- 支持数据复制和数据完整性
- 角色的访问控制
- 限制
- 没有完整的事务支持。
- 缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据,但这符合 GDPR。
- 稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。
性能
- 单个大查询吞吐量:如果数据被放置在page cache中,则一个不太复杂的查询在单个服务器上大约能够以2-10GB/s(未压缩)的速度进行处理。
- 处理短查询的延迟时间:如果一个查询使用主键并且没有太多行(几十万)进行处理,并且没有查询太多的列,那么在数据被page cache缓存的情况下,它的延迟应该小于50毫秒。
- 处理大量短查询的吞吐量:在相同的情况下,ClickHouse可以在单个服务器上每秒处理数百个查询。
- 写入速度大约为50到200MB/s。如果您写入的数据每行为1Kb,那么写入的速度为50,000到200,000行每秒。
为什么ClickHouse这么快?
- 面向列的存储:源数据通常包含数百甚至数千列,而报表可以只使用其中的少数列。系统需要避免读取不必要的列,否则最昂贵的磁盘读取操作将被浪费。
- 索引:ClickHouse将数据结构保存在内存中,不仅允许读取已使用的列,还允许读取这些列的必要行范围。
- 数据压缩:将同一列的不同值存储在一起通常会带来更好的压缩比(与面向行的系统相比),因为在实际数据中,列的相邻行通常具有相同或不那么多的不同值。除了通用压缩,ClickHouse还支持专门的编解码器,可以使数据更加紧凑。
- 向量化查询执行:ClickHouse不仅在列中存储数据,还在列中处理数据。它可以提高CPU缓存利用率,并允许使用SIMD CPU指令。
- 可伸缩性:ClickHouse可以利用所有可用的CPU核和磁盘执行单个查询。不仅在单个服务器上,而且在集群的所有CPU核和磁盘上也是如此。
安装部署
系统要求
ClickHouse可以在任何具有x86_64,AArch64或PowerPC64LE CPU架构的Linux,FreeBSD或Mac OS X上运行。
官方预构建的二进制文件通常针对x86_64进行编译,并利用SSE 4.2指令集,因此,除非另有说明,支持它的CPU使用将成为额外的系统需求。下面是检查当前CPU是否支持SSE 4.2的命令:
$ grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
要在不支持SSE 4.2或AArch64,PowerPC64LE架构的处理器上运行ClickHouse,您应该通过适当的配置调整从源代码构建ClickHouse。
可用安装包
- DEB安装包
- RPM安装包
- Tgz安装包
- Docker安装包
- 其他环境安装包
- 使用源码安装
安装包列表:
clickhouse-common-static— ClickHouse编译的二进制文件。clickhouse-server— 创建clickhouse-server软连接,并安装默认配置服务clickhouse-client— 创建clickhouse-client客户端工具软连接,并安装客户端配置文件。clickhouse-common-static-dbg— 带有调试信息的ClickHouse二进制文件。
单机RPM包安装
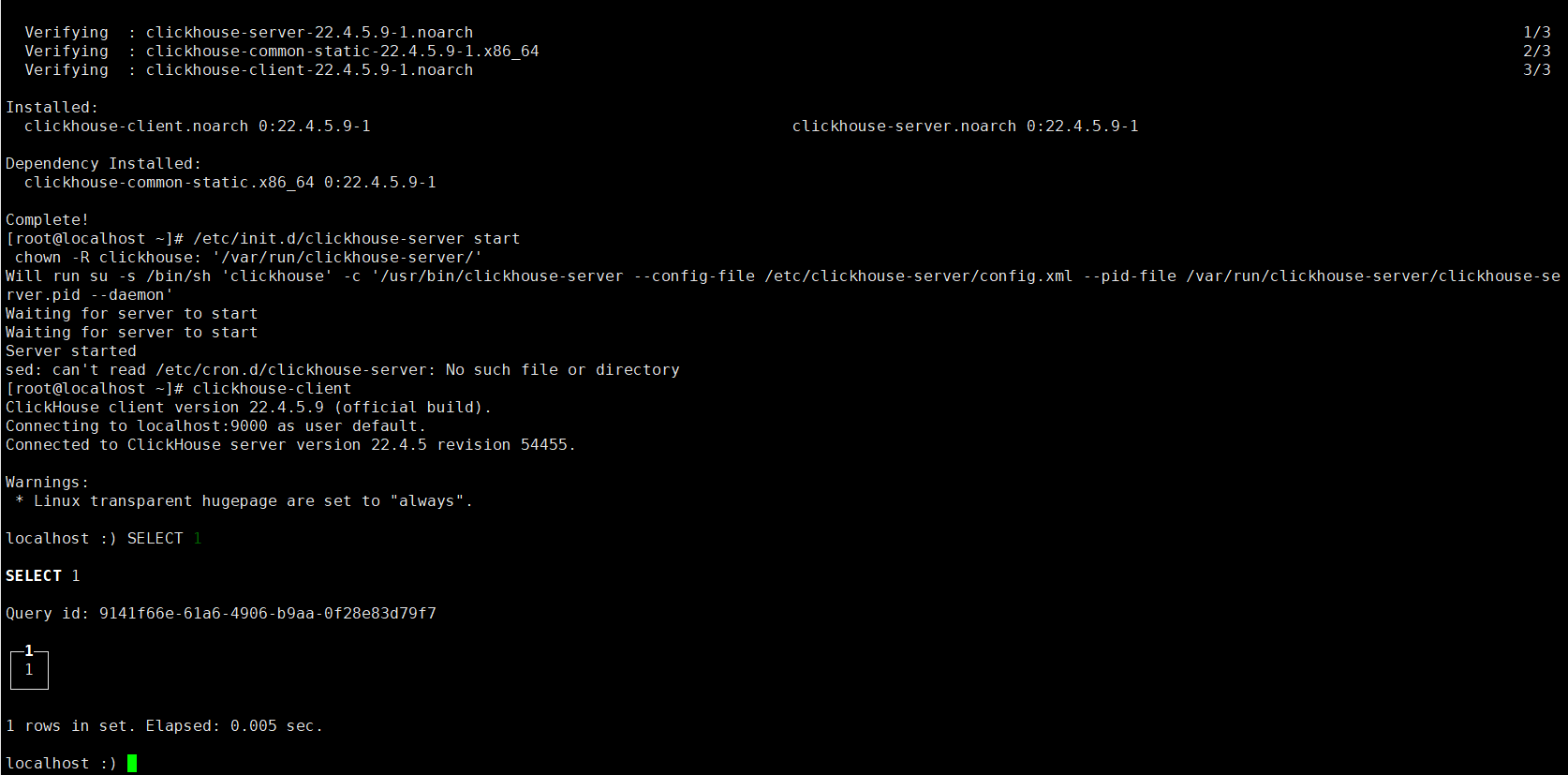
单机部署比较简单,执行完下面四条命令就可以通过clickhouse-client来操作了
yum install -y yum-utils
yum-config-manager --add-repo https://packages.clickhouse.com/rpm/clickhouse.repo
yum install -y clickhouse-server clickhouse-client
/etc/init.d/clickhouse-server start
集群部署
修改默认数据目录
clickhouse默认数据目录在 /var/lib/clickhouse, 一般分区空间有限,需要修改,修改到专用数据盘位置,且权限授权目录。
sudo vim /etc/clickhouse-server/config.xml
# 修改以下配置为自己的目录
<!-- 数据存储目录 -->
<path>/home/warehouse/clickhouse/data</path>
<!-- 查询时的产生的临时数据存储目录 -->
<tmp_path>/home/warehouse/clickhouse/tmp</tmp_path>
<!-- 用户数据文件目录,用于ClickHouse文件表引擎 -->
<user_files_path>/home/warehouse/clickhouse/user_files</user_files_path>
clickhouse程序是由clickhouse用户启动的,所以/home/warehouse/clickhouse目录最好把用户改成clickhouse:
sudo chown -R clickhouse:clickhouse /home/warehouse/clickhouse
#启动
sudo /etc/init.d/clickhouse-server start
部署
ClickHouse集群是一个同质集群,操作步骤如下
- 分别在ckserver1(192.168.5.52)、ckserver2(192.168.5.53)、ckserver3(192.168.12.27)这三台上按照上面的单机部署前面3行命令安装ClickHouse服务端。需提前准备Zookeeper,这样使用的是提前建好的3台Zookeeper集群(Zookeeper部署可以查看之前的文章)。
拷贝metrika.xml到/etc/clickhouse-server/config.d/,修改/etc/clickhouse-server/config.d/metrika.xml,目前主要配置zookeeper、remote_servers和macros节点数据,而macros数据在每个节点分别配置,分片副本可以以ckserver1配置为01,ckserver2配置02形式作为标识配置。在下面示例为配置一个1个分片和2个副本的集群:由于ClickHouse默认的9000端口和本地已监听端口服务有冲突,所以我这里修改端口为9110
<?xml version="1.0"?>
<yandex>
<zookeeper-server>
<node index="1">
<host>zk1</host>
<port>2181</port>
</node>
<node index="2">
<host>zk2</host>
<port>2181</port>
</node>
<node index="3">
<host>zk3</host>
<port>2181</port>
</node>
</zookeeper-server>
<macros>
<shard>01</shard>
<replica>01</replica>
</macros>
<remote_servers>
<ck_cluster_1shards_2replicas>
<shard>
<replica>
<host>ckserver1</host>
<port>9110</port>
<priority>1</priority>
</replica>
<replica>
<host>ckserver2</host>
<port>9110</port>
<priority>1</priority>
</replica>
<replica>
<host>huawei27</host>
<port>9110</port>
<priority>1</priority>
</replica>
</shard>
</ck_cluster_1shards_2replicas>
</remote_servers>
</yandex>
上述安装完配置文件的路径,*/etc/clickhouse-server/config.xml*
主要配置listen_host为本机IP或者0.0.0.0,按需修改端口默认为9000<tcp_port>9000</tcp_port>,
并删除整个remote_servers节点,增加如下配置,将remote_servers和zk等放在包含文件/etc/clickhouse-server/config.d/metrika.xml里配置
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
<zookeeper incl="zookeeper-server" optional="false" />
<macros incl="macros" optional="true" />
<remote_servers incl="ck_cluster_1shards_2replicas" />
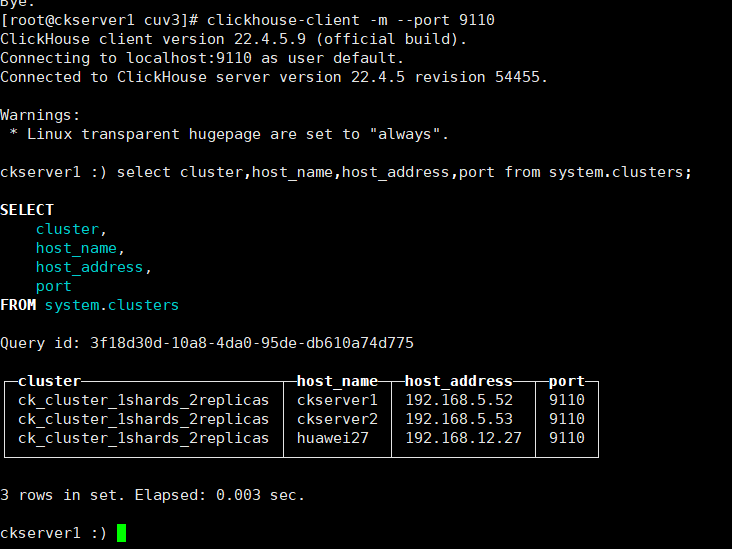
修改完配置后分别在三台上执行/etc/init.d/clickhouse-server start,使用客户端查询集群信息select * from system.clusters;,查询集群信息如下
clickhouse-client -m --port 9110
select cluster,host_name,host_address,port from system.clusters;
接口
- ClickHouse提供了一个原生命令行客户端
clickhouse-client客户端支持命令行--host, -h-– 服务端的host名称, 默认是localhost。您可以选择使用host名称或者IPv4或IPv6地址。--port– 连接的端口,默认值:9000。注意HTTP接口以及TCP原生接口使用的是不同端口。--user, -u– 用户名。 默认值:default。--password– 密码。 默认值:空字符串。--query, -q– 使用非交互模式查询。--database, -d– 默认当前操作的数据库. 默认值:服务端默认的配置(默认是default)。--multiline, -m– 如果指定,允许多行语句查询(Enter仅代表换行,不代表查询语句完结)。--multiquery, -n– 如果指定, 允许处理用;号分隔的多个查询,只在非交互模式下生效。--format, -f– 使用指定的默认格式输出结果。--vertical, -E– 如果指定,默认情况下使用垂直格式输出结果。这与–format=Vertical相同。在这种格式中,每个值都在单独的行上打印,这种方式对显示宽表很有帮助。--time, -t– 如果指定,非交互模式下会打印查询执行的时间到stderr中。--stacktrace– 如果指定,如果出现异常,会打印堆栈跟踪信息。--config-file– 配置文件的名称。--secure– 如果指定,将通过安全连接连接到服务器。--history_file— 存放命令历史的文件的路径。--param_<name>— 查询参数配置。
- HTTP客户端:HTTP接口允许您在任何编程语言的任何平台上使用ClickHouse,HTTP接口比原生接口受到更多的限制,但它具有更好的兼容性。默认情况下,
clickhouse-server会在8123端口上监控HTTP请求(这可以在配置中修改)。如果你发送了一个未携带任何参数的GET /请求,它会返回一个字符串 «Ok.» - MySQL接口:ClickHouse支持MySQL wire通讯协议。
- JDBC驱动
- 官网驱动
- 第三方驱动:
- ClickHouse-Native-JDBC
- clickhouse4j
- ODBC驱动
- C++客户端库
- 第三方工具
- 客户端开发库,支持多种语言如Python、Java、Go、Php、NodeJs、Swift、Ruby、R、Scala、C#、Kotlin等等
- 第三方集成库
- 关系数据库:MySQL、MSSQL、PostgreSQL
- 消息队列:Kafka
- 流处理:Flink
- 对象存储:S3
- 容器编排:Kubernetes
- 监控:Grafana、Prometheus、Zabbix
- 第三方代理
- chproxy
- KittenHouse
- ClickHouse-Bulk
- 第三方开发的可视化界面
- 开源
- Tabix
- HouseOps
- 灯塔
- DBeaver
- clickhouse-cli
- clickhouse-flamegraph
- DBM
- 商业
- Holistics
- DataGrip
- 开源
创建数据库
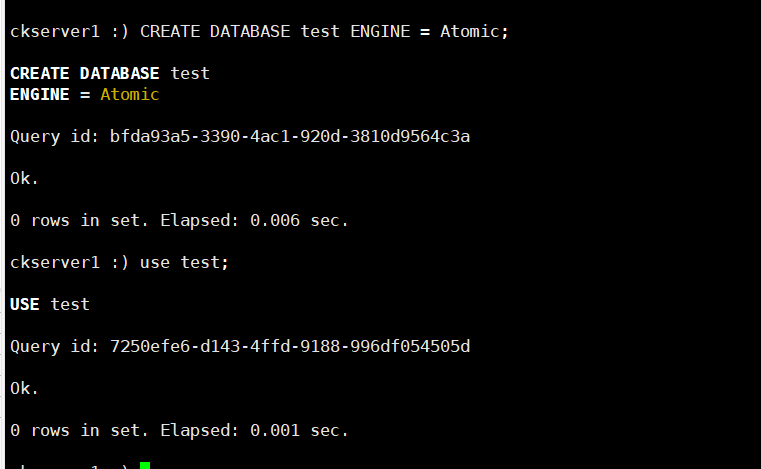
默认情况下,ClickHouse使用Atomic数据库引擎。它提供了可配置的table engines和SQL dialect。创建一个测试数据库
CREATE DATABASE test ENGINE = Atomic;
use test;
创建数据表
# -m支持多行输入
clickhouse-client -m
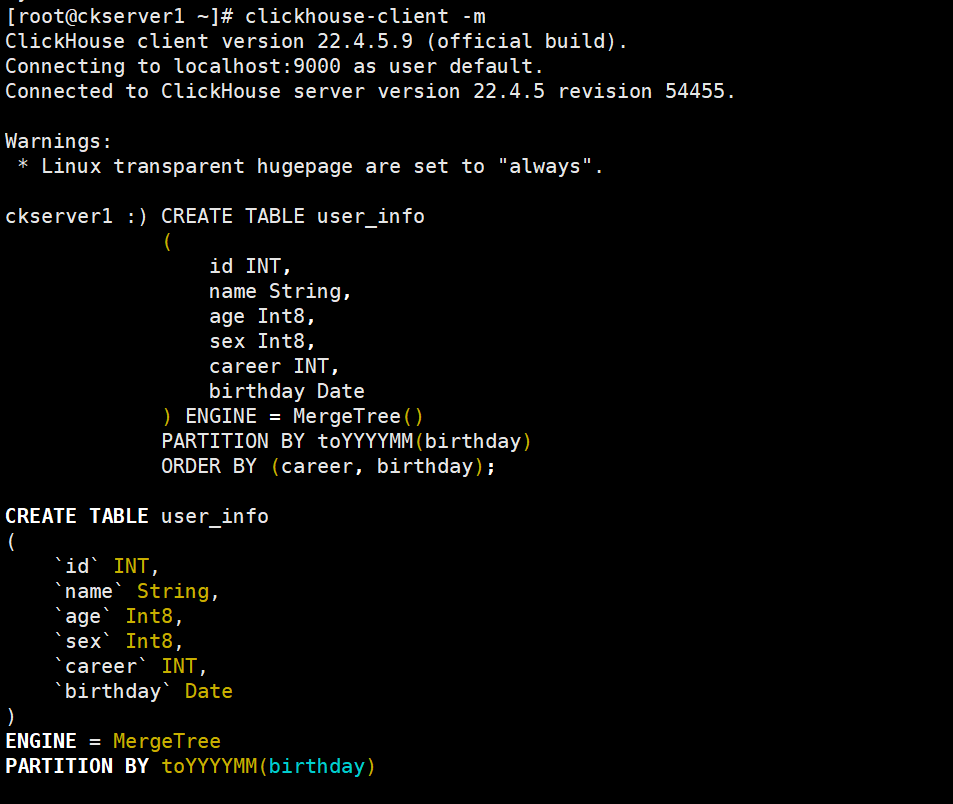
使用最常见的MergeTree表引擎创建一张用户信息表user_info
CREATE TABLE user_info
(
id INT,
name String,
age Int8,
sex Int8,
career INT,
birthday Date
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(birthday)
ORDER BY (career, birthday);
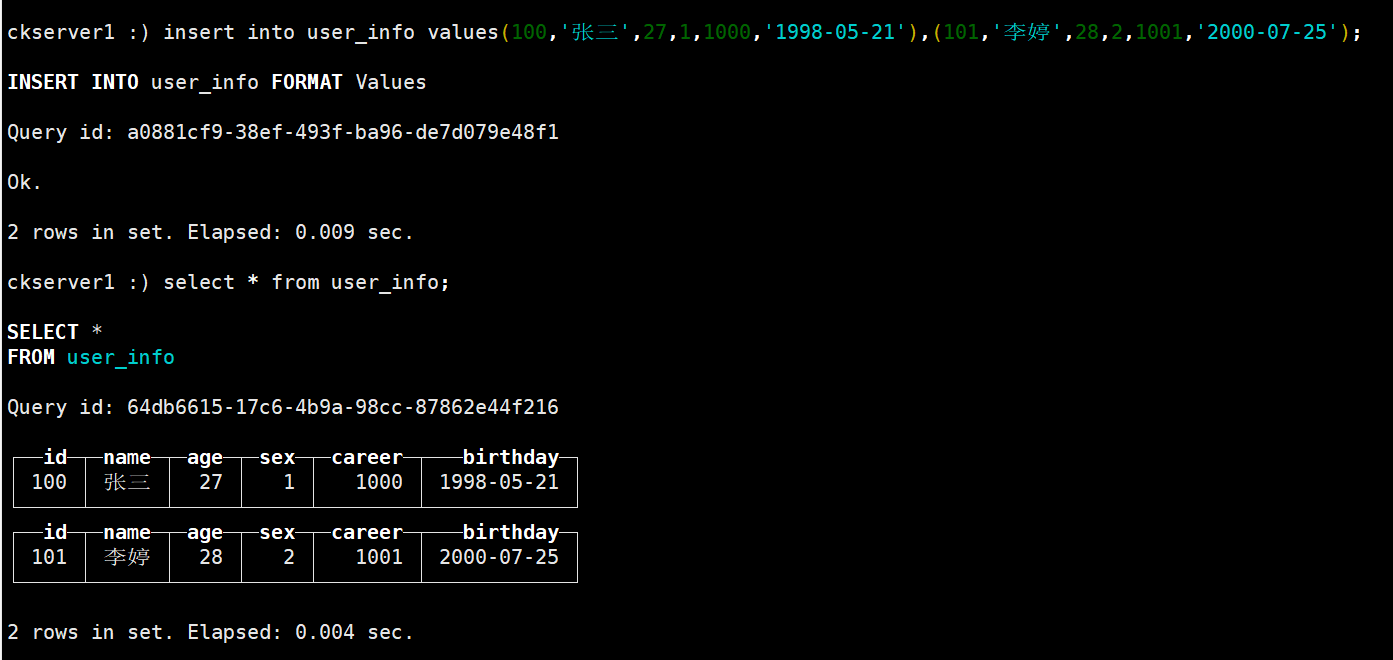
# user_info插入两行数据
insert into user_info values(100,'张三',27,1,1000,'1998-05-21'),(101,'李婷',28,2,1001,'2000-07-25');
# 查询user_info数据
select * from user_info;
至此,ClickHouse的环境已经完全准备就绪,下一篇我们先通过一个案例需求学习ClickHouse使用,然后再层层深入。
**本人博客网站 **IT小神 www.itxiaoshen.com