Kotlin基础学习(1)
本文主要讲解kotlin的部分基础知识,并不是全部基础。
提示:纯属个人理解,如有理解错误,欢迎留言指正批评。
一、Null检查机制
kotlin对于声明可为空的参数,使用时是需要进行空判断的
1.如何声明一个可为空的参数
var a: String? = "1"
var b: String? = null
去掉“?”,声明的是一个不为空的参数,给一个不为空的对象赋值为null,会报错

2.如何进行空判断处理
- 字段后面添加
!!,字段为空时抛出空指针异常
var b: String? = null
var age = b!!.toInt()
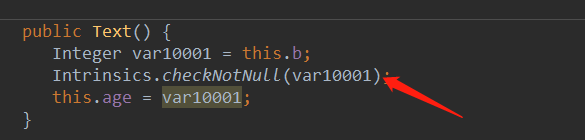
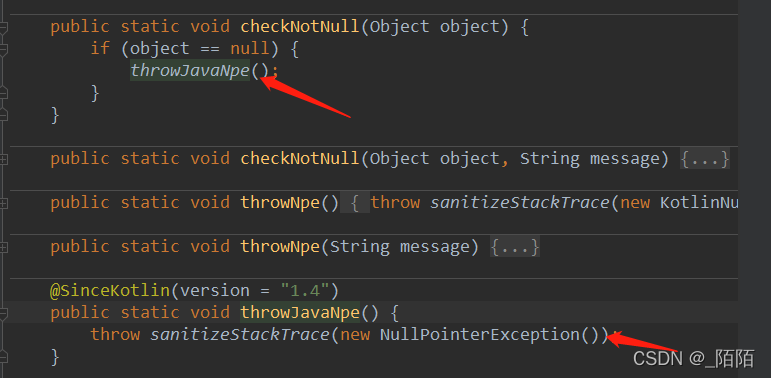
当b字段为null时会抛出空指针异常,可以看下这段kotlin代码编译为java源码时的样子
从java源码中看到,上面这段kotlin代码是会直接抛空指针异常的
- 字段后面添加
?., 字段为空时返回null
var b: String? = null
var age = b?.toInt()
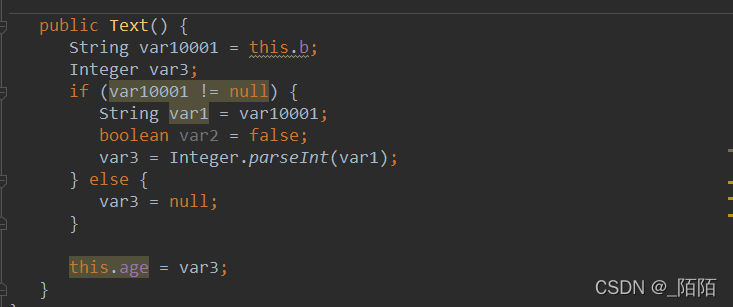
当b为null时,会返回null给age,当b不为null时,则返回结果给age。也来看看这段kotlin代码编译为java源码时的样子
- 符号
?:,A ?: B当A为null时,返回B ,常规用法:?.与?:连用
var b: String? = null
var a: String = "12"
var age = b ?: a
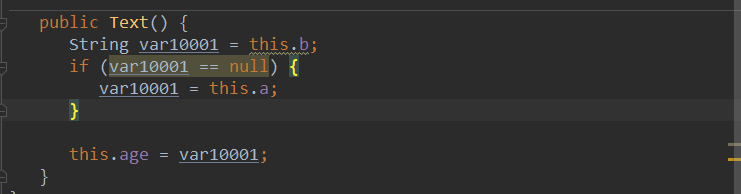
老规矩,看一下java源码:
可以看到当b为null时,会把a的值赋值给age。
看一下,常规用法:
var b: String? = null
var a: String? = "12"
var c: String = "111"
//当b为null时且a为null时,返回null;
//当b为null时且a不为null,则返回a.toInt()的结果
//当b不为null时,返回b
var age = b ?: a?.toInt()
//当b为null时且a为null时,返回null;
//当b为null时且a不为null,则返回a.toInt()的结果
//当b不为null时,返回b.toInt()的结果
var age2 = b?.toInt() ?: a?.toInt()
//当a为null时,返回c;
//a不为null时,返回a.toInt()
var age3 = a?.toInt() ?: c
二、延迟加载
kotlin在类中声明一个变量(属性)的时候时必须初始化的,这在开发的时候时不满足需求的。很多时候我们都需要在使用的时候才进行初始化,于是就有了延迟加载这个功能。
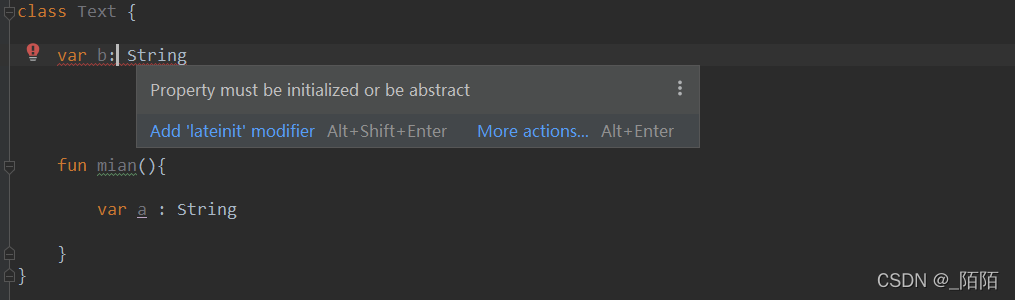
局部变量是可以只声明而不进行初始化的。全局变量是必须初始化的
上图可以看到编译器报错了。以下讨论都是针对全局变量的。
1.lateinit
1、 只能用于var变量的延迟
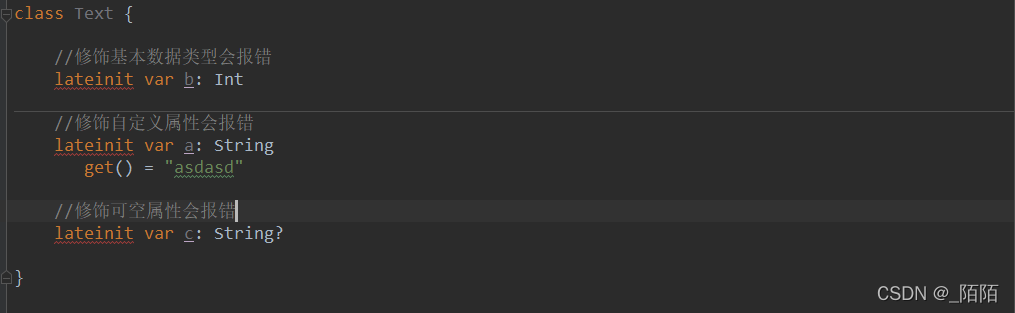
2、被lateinit修饰的变量不能声明为可空对象
3、不能用于基本数据类型
4、自定义属性的getter或setter方法后,就不能用lateinit修饰了
lateinit var b: String
使用时需要初始化该变量,才能使用。初始化语句在哪调用,就在哪开始初始化。
以下是lateinit无法使用的三种情况:
2.by lazy{}
1、仅能用于val变量的延迟
2、自定义属性的getter或setter方法后,就不能用by lazy{}修饰了
lateinit var b : String
//仅能用于val变量的延迟
val a: String by lazy {
b = "dad"
print("你好,我是延迟初始化")
return@lazy "111"
}
//可修饰基本数据类型,也可修饰可空数据类型
val c: Int? by lazy {
print("你好,我是延迟初始化")
null
}
第一次调用get()会执行by lazy{}括号中的所有语句,并且记录被修饰的变量结果内容,后续再调用get()只是返回记录的结果,并不会调用by lazy{}括号中的所有语句了。
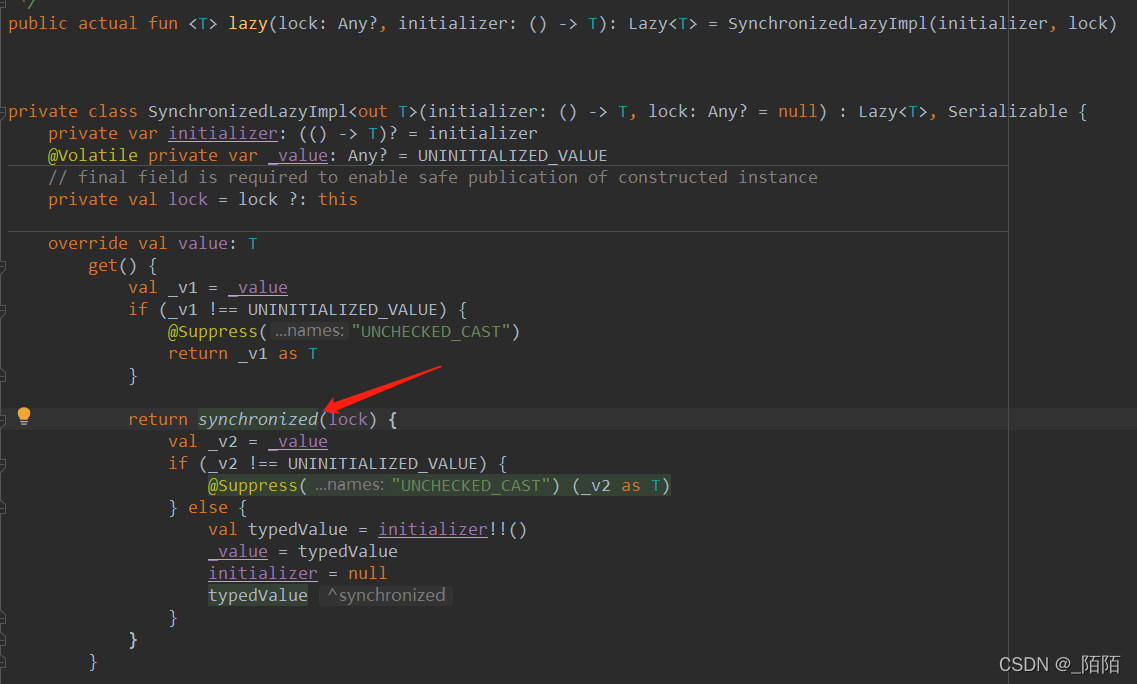
来看看lazy的源码: 默认情况下,调用的是SynchronizedLazyImpl方法
从源码可以看出,当第一次调用get方法时,会执行by lazy {}括号中的所有语句,第二次调用get方法时,就直接获取第一次得到的结果值。这里还应该注意一点,by lazy{}是线性安全的,它使用了同步锁:该值只在一个线程中计算,并且所有线程会看到相同的值。
额外知识点
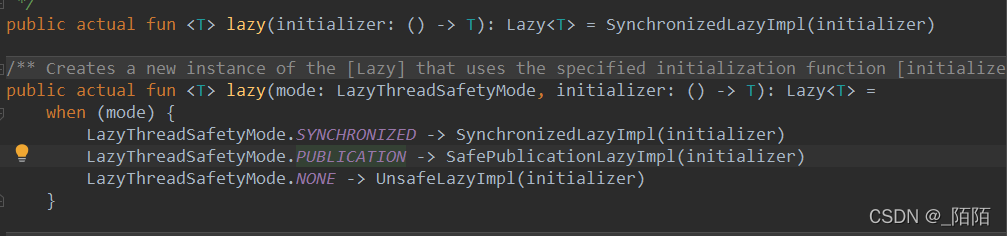
lazy可以传进来一个LazyThreadSafetyMode变量,一共有三种模式。如下使用:
val a: String by lazy(LazyThreadSafetyMode.NONE) {
b = "dad"
print("你好,我是延迟初始化")
return@lazy "111"
}
简单介绍一下这三种模式:
LazyThreadSafetyMode.SYNCHRONIZED
默认模式。延迟属性的值,只允许一个线程中修改,其他线程只能使用该线程修改的值,并且代码块只有该线程走过一遍,其余线程只能获取最终结果。
LazyThreadSafetyMode.PUBLICATION
公共模式。延迟属性的值,只有一个线程能修改,这个使用的不是同步锁控制的,这个是通过CAS操作,在赋值时进行了CAS原子操作,所以值还是唯一的,不会因为多线程的原因导致值有问题。但是首次执行时,代码块是有可能被多个线程(首次同时进入多个线程时)走过多遍的。第二次则会直接获取第一次得到的结果。
LazyThreadSafetyMode.NONE
None模式。这个模式是线性不安全的,多个线程在同一时刻可进入初始化块,也可修改成功多次。
3.两个延迟加载的区别
区别:
1、lateinit只能修饰var ;by lazy只能修饰val
2、lateinit不能修饰可空属性且不能修饰基本数据类型 ;by lazy可以修饰可空属性也可以修饰基本数据类型
3、lateinit初始化是依据初始化代码在哪调用即在哪进行初始化赋值的 ;by lazy是在第一次调用该变量获取值时就开始初始化赋值。
相同点:
自定义属性都不能使用lateinit和by lazy进行修饰
三、顶层声明
在java中有很多工具类,类中会定义很多静态方法以及静态属性。kotlin认为根本不需要创建这些无意义的类。可以直接将代码放入文件的顶层,不用附属于任何一个类。
在kotlin中有class与file文件的区别。顶层声明就是写在一个file文件里。
1.顶层函数
在Kotlin中,顶层函数属于包内成员,包内可以直接使用,包外只需要import该顶层函数,即可使用。
kotlin中使用:
java中使用:
在java中,系统编译后会生成一个文件名+kt的类,用该类进行调用,方法会变成该类的静态方法。看下反编译后的java源码:




额外知识点
@file:JvmName("xxxx")
@file:JvmName("xxxx") 的使用:系统编译后,文件名为xxxx。可用xxxx.方法名()调用
@file:JvmName("Text")
package com.demo.kotlindemo
fun moxiaoting(){
}
java中调用:
public class Day2 {
public void mian(){
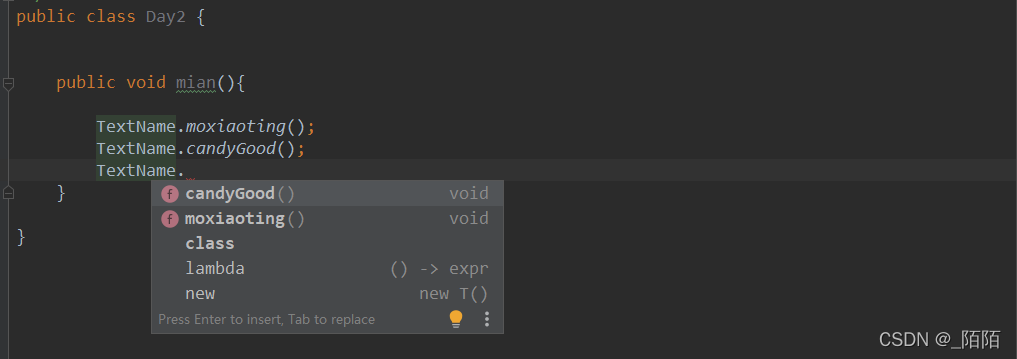
//Text 为@file:JvmName("Text")中的名字
Text.moxiaoting();
}
}
kotlin调用还是一样的,不影响kotlin中的使用方式。只是改变了java中的调用方式
@file:JvmMultifileClass
@file:JvmMultifileClass的使用:系统编译后,会把多个自定义名字相同的文件强制合并在一起
Text文件:
@file:JvmName("TextName")
@file:JvmMultifileClass
package com.demo.kotlindemo
fun moxiaoting(){
}
TextOther文件:
@file:JvmName("TextName")
@file:JvmMultifileClass
package com.demo.kotlindemo
fun candyGood(){
}
java中调用:
可以看到在编译后,java已经把两个文件Text和TextOther进行了合并。统一使用TextName可调用这两个文件的所有方法。
在kotlin中使用不受影响,直接调用方法名即可。
@JvmName("xxxx")相同时如果不使用JvmMultifileClass注解,编译会报错。
2.顶层属性
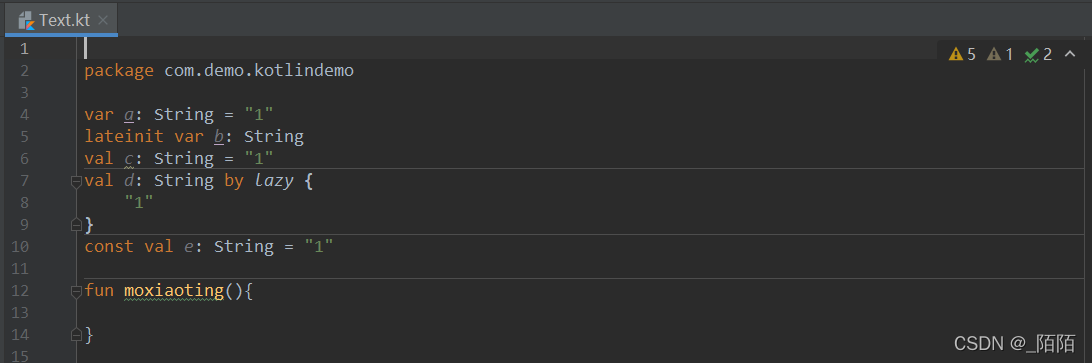
和顶层函数一样,属性也可以放在文件的顶层,不附属与任何一个类。这种属性叫顶层属性。
kotlin中使用:
java中使用:
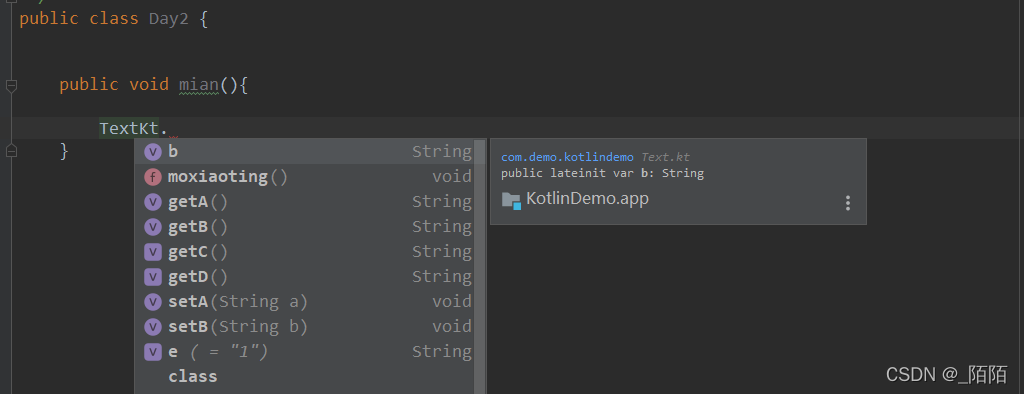
和顶层函数调用是一样的,也是编译后生成一个文件名+kt的一个类,里面有属性的getter与setter方法,直接调用就可以了。细心的同学可以看到,有些属性是可以直接通过属性名调出来的,如例子中的b和e属性。有些属性却只能通过其getter与setter方法调用。具体我们可以看下编译后的java源码:
可以看到被lateinit修饰的延迟属性编译后是public的,const修饰的属性编译后也是public的。我们从这里还可以知道,顶层属性被编译后是java中的静态属性,顶层方法被编译后是java中的静态方法。


- 谜之操作(我也不太清楚原因):
在添加@file:JvmMultifileClass之后编译,被lateinit修饰的延迟属性依然是public。但是java中调用时,只能通过其getter与setter方法调用。const修饰的属性依然是public,在java中调用时可以直接通过属性名调用出来。
来看下编译后的java代码:
final class TextName__TextKt {
@NotNull
private static String a = "1";
public static String b;
@NotNull
private static final String c = "1";
@NotNull
private static final Lazy d$delegate;
....//省略其他属性的getter与setter方法
public static final void moxiaoting() {
}
static {
d$delegate = LazyKt.lazy((Function0)null.INSTANCE);
}
}
// TextName.java
public final class TextName {
@NotNull
public static final String e = "1";
....//省略其他属性的getter与setter方法
@NotNull
public static final String getB() {
return TextName__TextKt.getB();
}
public static final void setB(@NotNull String var0) {
TextName__TextKt.setB(var0);
}
public static final void moxiaoting() {
TextName__TextKt.moxiaoting();
}
}
从编译后的java源码可以看出,合并后的类TextName里只有const修饰的属性,因此可以直接通过属性名调用。其他属性都需要通过其getter与setter方法调用。至于为什么合并后要这么操作,我也不太清楚,如果有明白的大神或者同学可以在评论区留言告知一下,万分感谢~
四、类
1.数据类
在kotlin中一个数据类对应于java中的一个实例类bean。使用data修饰符。
data class Bean(){}
例如:
Java中有这样一个实例类
public class Bean {
private String name;
private String age;
private DataBean bean;
public DataBean getBean() {
return bean;
}
public void setBean(DataBean bean) {
this.bean = bean;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
private class DataBean{
private String sex;
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
}
}
在kotlin中就可以写成如下这样
data class Bean(var name: String , var age: String, var bean: DataBean) : Serializable {
data class DataBean( var sex: String ) : Serializable {}
}
数据类会自动为该类生成一些自带的函数,其中最重要的就是componentN()函数以及copy()函数。现在来讲一下这自动生成的两类函数:
解构声明
只要某个类有componentN()函数,就可以对该类进行解构声明。解构声明简单来说就是把一个对象变成多个变量的形式
解构声明的表现形式: var (变量名 , 变量名,…) = 类对象
data类都会有componentN()函数,函数个数就是主构函数中属性的个数,顺序与属性声明一样。有多少个componentN()函数解构声明中的变量名就可以写多少个。
看个栗子:
data class Person(val name: String , var sex : String) {
var age: Int = 0
}
该数据类,会有两个组件函数:component1()、component2(),因为主构函数中有两个属性name和属性sex。不会为age属性生成一个组件函数,因为其声明不在主构函数中。
data class Person(val name: String , var sex : String) {
var age: Int = 0
}
fun main(){
val person1 = Person("John" , "女")
//解构声明
var (name , sex) = person1
//等价于
val name2 = person1.name
var sex2 = person1.sex
}
现在应该可以理解这句话的意思了吧:解构声明简单来说就是把一个对象变成多个变量的形式,解构声明之后,我们就可以直接使用name和sex这两个变量了。
可能这块有点疑问,这个解构声明和component1()、component2()函数有什么关系呢?
//解构声明实际上调用的就是component1()和component2()函数
var (name , sex) = person1
//等价于
val name2 = person1.component1() //这个函数的返回值就是name属性
var sex2 = person1.component2() //这个函数的返回值就是sex属性
//等价于
val name2 = person1.name
var sex2 = person1.sex
我们看一下这个data类的反编译java源码:
public final class Person {
private int age;
@NotNull
private final String name;
@NotNull
private String sex;
....
@NotNull
public final String component1() {
return this.name;
}
@NotNull
public final String component2() {
return this.sex;
}
....
}
可以看到系统为Person类生成了两个componentX()函数,分别对应name属性和sex属性。这就是我前面说的:data类都会有componentN()函数,函数个数就是主构函数中属性的个数,顺序与属性声明一样。 可以看到这个顺序component1对应name,component2对应sex,有兴趣的可以试下把sex和name在主构函数中换个位置,component1就对应sex,component2就对应name了。
copy()函数
现在来看下数据类自动生成的第二个函数copy()。和
componentN()函数一样,也只是复制主构函数中的属性,不在主构函数中的属性不进行复制。
copy()函数的实现会类似下面这样:
data class Person(val name: String , var sex : String) {
var age: Int = 0
}
fun copy(name: String = this.name, sex : String= this.sex ) = Person(name, sex)
会类似一个带有默认值的函数。默认值就是其调用者对应的属性的值。
data class Person(val name: String , var sex : String) {
var age: Int = 0
}
fun main(){
val person1 = Person("John" , "女")
var person = person1.copy("ni")
person1.age = 20
}
person 的age值还是0,name值为"ni" ,sex值是person1的sex值;person1的age值是20,上面这个栗子实际上只复制了sex属性。
额外知识点
1、自定义带有解构声明的类
前面讲的组件函数是data类自动生成的,那么可不可以自定义一个可解构声明的类呢?当然是可以的。
使用 operator 修饰组件函数
class Point(var x: Int , var y: Int){
operator fun component1() = x;
operator fun component2() = y;
}
这样就为一个自定义的Point类声明了两个组件函数,对该类就可以使用解构声明了。
需要注意一点,data类是自动按照主构函数中的属性,对每个属性生成一个属于它自己的组件函数,所以data类会自动生成很多方法,而我们安卓是有方法数限制的。这块是需要注意的一点。
2、工具JsonToKotlinClass插件
这个插件可以帮助我们把一个json串自动转成data类。不过生成的data类是一个kt文件,需要手动把二级data类移动为内部类即可。使用方式和我们经常使用的GsonFormatPlus插件是一样的,这里就不讲述使用方式了,不会的同学可以百度一下。
3、标准数据类(元组)
在kotlin中,只有二元元组(Pair)和三元元组(Tripe)。这两个类也是data类。是kotlin自定义的且继承Serializable,这意味这可以进行页面传递。
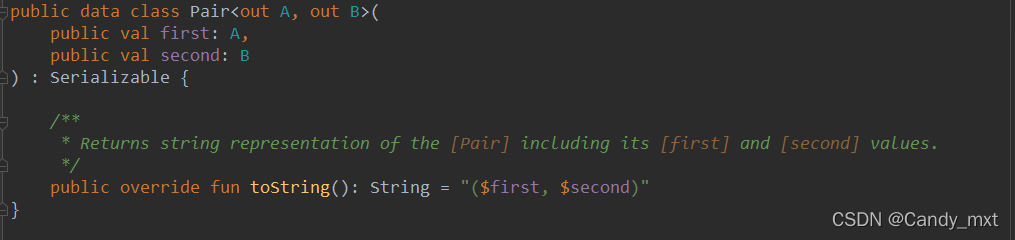
来看下这两个类的源码:Pair
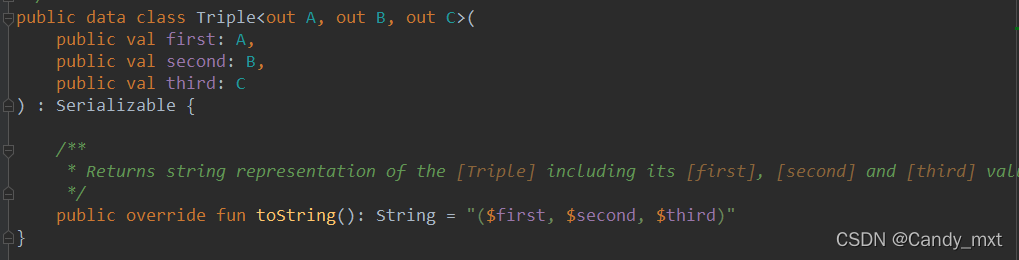
Tripe类
可以看到这两个类也是data类,且继承Serializable,很简单不做过多的解释,直接看例子就明白了。
fun main() {
val student1 = Triple<String, String, Int>("Alfred", "男", 29)
val student2 = Pair<String,Int>("Thomas",21)
println(student1.first)
println(student1.second)
println(student1.third)
println(student2.first)
println(student2.second)
}
结果:
Alfred
男
29
Thomas
21
这个是kotlin中自定义的data类,如果不在乎命名的话,可以直接使用比较方便。使用元组还是建议和解构声明一起使用,否则不建议单独获取其属性值,毕竟这个命名有点雷人。
2.密封类
使用sealed修饰的类为密封类
sealed class SealedDemo{}
看下这行代码的Java源码:
public abstract class sealedDemo {
private sealedDemo() {}
}
可以看出,密封类实际是一个抽象类,它是无法被实例化的(构造方法是private),自身是没有对象的。但是它是类而且是抽象类,所以可以被继承。
密封类在kotlin1.5以上,允许子类定义在不同的文件中,只要保证子类和父类在同一个
Gradle module且同一个包下即可。密封类是不允许外部(别的library)有其子类的,这个性质在开发工具类,如jar包或第三方框架时你会特别喜欢。由于java的单继承性,所以kotlin1.5以上新出来了一个密封接口,在一定程度上弥补了密封类的不足。密封接口和密封类是一样的性质,只是一个是接口一个是类而已。
使用
密封类是不能够被实例化的,它的取值范围是其子类。废话不多说,来看个例子
sealed class SealedDemo{}
//密封类的子类
class Test2Activity : SealedDemo() {}
//密封类的子类
class Test3Activity : SealedDemo() {}
//密封类的子类
open class Test4Activity : SealedDemo() {}
//间接子类,不算密封类的取值范围
class Test5Activity : Test4Activity() {}
var sealed1 : SealedDemo = Test2Activity()
fun eval(e: SealedDemo): String =
//需要书写出全部子类的情况,建议写成这样,可以避免新增加一个子类忘记补全when表达式的情况
when (e) {
is Test2Activity -> "111"
is Test3Activity -> "2222"
is Test4Activity -> "2222"
}
//或者
fun eval(e: SealedDemo): String =
when (e) { //不需要写出全部子类的情况,缺少的子类进入else语句
is Test2Activity -> "111"
is Test3Activity -> "2222"
else -> "2222"
}
sealed1是SealedDemo 的对象,可以看到其实例化是通过子类进行的。所以,我们说密封类的取值范围是其子类,就是这个意思。间接子类不算密封类的取值范围
密封类最常用的用法就是与when语句搭配使用。当when作为表达式的时候是需要填写完整逻辑的,即必须包含else语句。
可以看到当when作为表达式的时候必须要有else,否则会报错。但是与密封类一起使用就可以不用写else,但是需要书写全部子类的各个情况,如果缺少一种子类的情况,编译器会报错。利用这个特性,可以帮我们避免在项目中,新增加一个子类后忘记补全when表达式的结果情况。

与枚举类的区别
相同点:
密封类与枚举类的取值范围都是固定的。密封类取值是其子类,枚举类的取值是其对象
区别:
枚举类的值都是其对象,每个对象都只能被实例化一次。而密封类的取值是其子类,每个子类可以有多个实例,并且每个子类可以有不同的状态参数以及行为方法来记录更多的实现信息以完成更多的功能。这是枚举不具备的,枚举的方法和参数都是其值共同拥有的,不具备独立性。
密封接口
所有的枚举都继承自java.lang.Enum类,所以枚举类是不能再继承其他类了,但是却可以实现接口。所以kotlin1.5以上新出了一个特性,密封接口。专门用来弥补不能继承密封类的缺憾。
sealed interface Language {
}
enum class HighLevelLang : Language {
Java, Kotlin, CPP, C
}
enum class MachineLang : Language {
ARM, X86
}
//使用:双层嵌套when语句。枚举中的每个实例都是密封接口的对象
fun eval(lang : Language): String = when (lang) {
is MachineLang ->
when (lang) {
MachineLang.ARM -> "111"
MachineLang.X86 -> "111"
}
is HighLevelLang ->
when (lang) {
HighLevelLang.CPP -> "111"
HighLevelLang.Java -> "111"
HighLevelLang.Kotlin -> "111"
HighLevelLang.C -> "111"
}
}
3.内联类
温馨提示:建议先看本篇文中的内联函数,弄懂 inline 关键词后再返过来看这节。本节默认您已经知道了 inline 关键词
Kotlin 引入了一种特殊的类,叫做内联类,它是通过在类名前放置一个 Inline 修饰符来声明
inline class Bean(val name: String) {
val str
get() = "asda"
val length
get() = name.length
init {
println(str)
}
fun toMinutes() = str.length * 60
}
使用时和普通类是一样,只是在编译的时候,并不会给这个类创建它的实例,而是直接使用里面的属性进行赋值(和编译时常量一样的概念)。除非你打印了该类的实例时,就会进行创建一个实例,只是调用属性和方法是不会创建该类的实例。
//调用
fun main(){
val hous = Bean("24")
println(hous.length)
}
//编译后
public static final void main() {
String hous = Bean.constructor-impl(); //这里是调用了内联类的静态方法,为了打印init块中的语句
int var1 = Bean.getLength-impl(hous); //这里是调用了内联类的静态方法,为了打印后面的语句
System.out.println(var1);
}
//编译后的bean类
public final class Bean {
@NotNull
public static String constructor_impl(@NotNull String name) {
Intrinsics.checkNotNullParameter(name, "name");
String var1 = getStr-impl(name);
System.out.println(var1);
return name;
}
@NotNull
public static final String getStr_impl(String $this) {
return "asda";
}
public static final int getLength_impl(String $this) {
return $this.length();
}
public static final int toMinutes_impl(String $this) {
return getStr-impl($this).length() * 60;
}
}
从上面可以看到,并未给内联类Bean进行初始化实例,都是直接调用静态方法直接获取值。
当我们实例化一个对象时,该对象就存储在 JVM 堆上。我们在存储和使用对象实例时会有性能损失。堆分配和内存提取的性能代价很高,虽然看起来每个对象的内存开销都微不足道,但是积累起来,它对代码运行速度就会产生一定的影响。内联类就可以解决这样的问题
创建一个内联类的限制
1、内联类主构造器必须有且仅有一个只读val属性
2、不能继承父类,也不能被继承,但可以实现接口
3、内联类的内部是允许成员属性的,但成员属性只能是自定义的val属性且值必须是常量或者基于构造器中那个基础值计算
4、内联类必须在顶层声明,嵌套、内部类不能内联的。
5、目前,也不支持内联类枚举。
4.对象表达式(个人理解:匿名类)
语法格式
object[:若干个父类型,中间用逗号隔开]{
}
要创建一个继承自某个(或某些)类型的匿名类的对象,我们就会使用对象表达式。我个人理解为匿名类。
open class A(x: Int) {
public open val y: Int = x
}
interface B { …… }
val ab: A = object : A(1), B {
override val y = 15
}
这是一个继承A类,实现B接口的一个匿名类,ab是该类的实例。如果我们只需要“一个对象而已”,并不需要特殊超类型,那么我们可以简单地写:
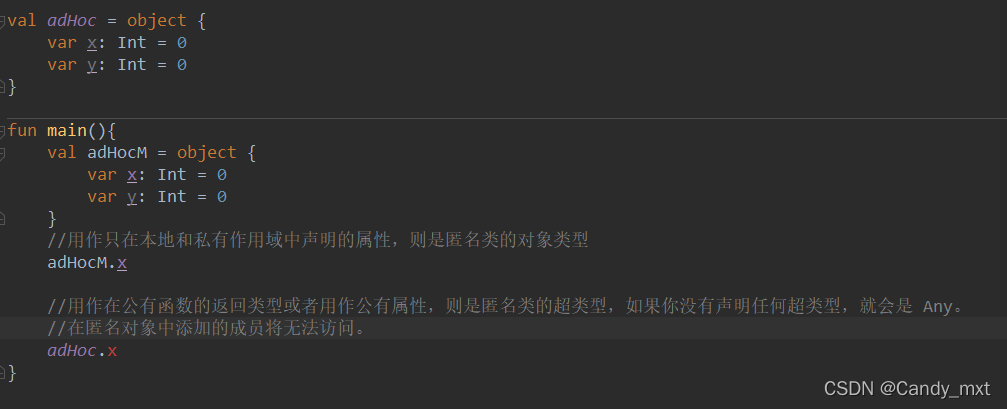
val adHoc = object {
var x: Int = 0
var y: Int = 0
}
这是一个不继承任何父类的匿名类,adHoc是它的一个实例。
来看下,java中的匿名内部类:
使用kotlin的对象表达式为:
这是继承View.OnClickListener类的一个匿名类,其实例传入了setOnClickListener()方法中。所以我叫对象表达式为匿名类。但它和java中的匿名类还有点区别。
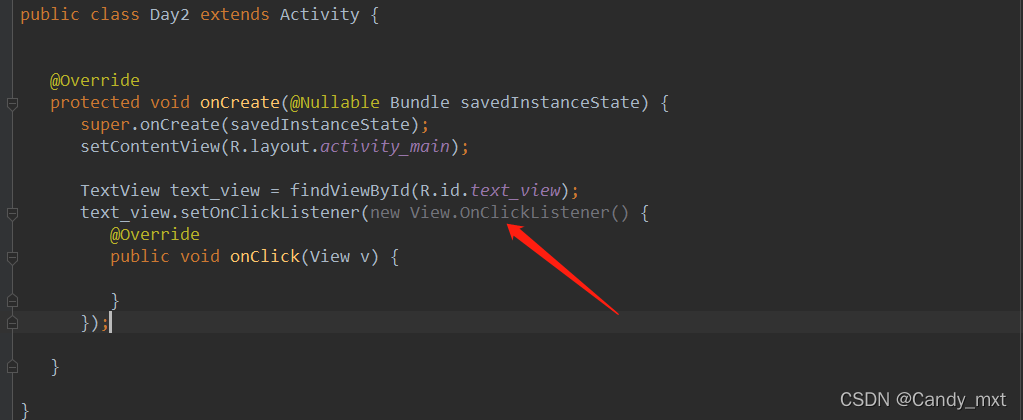

与java中的匿名内部类有点区别,在java中匿名内部类修改外部类的变量时,需要该变量为final修饰。但是在kotlin中对象表达式里并没有这个限制。
另外请注意,匿名对象可以用作只在本地和私有作用域中声明的类型。如果你使用匿名对象作为公有函数的返回类型或者用作公有属性的类型,那么该函数或属性的实际类型会是匿名对象声明的超类型,如果你没有声明任何超类型,就会是 Any。在匿名对象中添加的成员将无法访问。
五、函数
1.高阶函数
在 Kotlin 里面,函数的参数也可以是函数类型的
fun candy_new(funParam: (Int) -> String): String {
return funParam(1)
}
在上述代码中,参数 funParam 具有函数类型
(Int) -> String,因此 candy_new 接受一个函数作为参数,该函数接受类型为Int的参数并返回一个 String 类型的值。
函数类型不只可以作为函数的参数类型,还可以作为函数的返回值类型。
fun candy(param: Int): (Int) -> Unit {
return ::candy_new
}
这种「参数或者返回值为函数类型的函数」,在 Kotlin 中就被称为「高阶函数」
引用
除了作为函数的参数和返回值类型,你把它赋值给一个变量也是可以的。但是需要加双冒号,这个双冒号的写法叫做函数引用。
1、函数引用
1、成员函数:
类名::函数名
2、扩展函数:扩展类名::函数名
3、顶层函数:::函数名
4、成员扩展函数:没有引用
fun b(param: Int): Unit {}
var d = ::b
变量d是函数b的引用。
Kotlin 里「函数可以作为参数」这件事的本质,是函数在 Kotlin 里可以作为对象存在——因为只有对象才能被作为参数传递啊。赋值也是一样道理,只有对象才能被赋值给变量啊。但 Kotlin 的函数本身的性质又决定了它没办法被当做一个对象。那怎么办呢?Kotlin 的选择是,那就创建一个和函数具有相同功能的对象。怎么创建?使用双冒号。
在 Kotlin 里,一个函数名的左边加上双冒号,它就不表示这个函数本身了,而表示一个对象,或者说一个指向对象的引用,但,这个对象可不是函数本身,而是一个和这个函数具有相同功能的对象。
b(1) // 调用函数
d(1) // 用对象 d 后面加上括号来实现 b() 的等价操作;实际上会调用 d.invoke(1)
(::b)(1) // 用对象 :b 后面加上括号来实现 b() 的等价操作;实际上会调用 (::b).invoke(1)
a(::b) //传递一个b函数对象
每个函数类型的对象都有一个自带的invoke() 函数,你对一个函数类型的对象加括号、加参数,这种写法是 Kotlin 的语法糖,实际上它真正调用的是这个对象的 invoke() 函数。
2、属性引用
属性引用的用法与函数(方法)引用的用法是完全一致,都是通过::形式来引用的。
顶层属性引用
package com.demo.kotlindemo
const val pase = 3
fun main() {
println(::pase) // 打印属性类型: val pase: kotlin.Int
println(::pase.get()) // 打印属性值: 3
println(::pase.name) // 打印属性名:pase
}
这里,
::pase表示一个 KProperty 对象。通过这个 KProperty 访问指定属性的具体信息,相当于 java 的Field。
KProperty 是一个接口,代表一个属性(val 或 var)。
对于 var 属性,则使用 KMutableProperty。这个接口继承自 KProperty 但具有 set 方法。
类的公共属性引用
class Person(val name: String){}
fun main(){
val prop = Person::name
println(prop.get(Person("Android")))
}
其实这个属性引用就类似于在Java反射属性的方式差不多,目的都是通过反射来操作属性的一些东东, 其中
Person::name其实表示的是类型KProperty的属性对象,那们我们可以通过get()来获取其值,也可以通过name属性来获取其名字。
如果属性属于具体类,那么所对应的属性引用必须依赖于具体的实例存在,因此 get 方法必须传递该类的一个实例。如:prop.get(Person("Android"))
通过实例获得属性引用
fun main() {
var str = "abcde"
var getMethod = str::get //通过实例获取其方法的引用
println(getMethod(1))
var getField = "str"::length //通过实例获取其属性的引用
println(getField.get())
}
注意,上述代码实际上等效于:
fun main() {
var str = "abcde"
var getMethod = String::get //通过类名获取方法的引用,这种形式不知道调用者是谁,所以需要传递调用者
println(getMethod(str , 1))
var getField = String::length //通过类名获取属性的引用,这种形式不知道调用者是谁,所以需要传递调用者
println(getField.get("str"))
}
属性引用在函数的应用
其实属性引用也是可以用在函数上的
fun main() {
val strings = arrayListOf("View", "TextView", "AppCompatAutoCompleteTextView")
var a : (String) -> Int = String::length
println(strings.map(a))
println(strings.map(String::length))
}
其实map方法接收的是一个函数
transform: (T) -> R,其中T参数就代表集合中的每一个String的元素,而R则为整个函数返回的值,在这里我们应该将一个函数引用传递给它,但这里我们实际上传递了一个属性引用,这充分说明了属性引用和函数引用本质上是相同的。那咱们传的是一个属性引用其执行的机制是咋样的呢?
其实是这样的:这里如果是函数引用,map 会将数组中的元素传递给函数引用,但如果是属性引用,map 会将元素传递给属性引用的接收者,即变成了it.length,这会调用数组元素的 length 方法。
3、构造函数引用
构造方法其实也是一个方法嘛,也存在引用,所以下面来看一下它如何来用
class Bean{
constructor(any: String){}
constructor( age : Int , sex: String){}
}
fun main(){
//调用的是构造函数
call(::Bean)
call_new(::Bean)
var param : (String) -> Bean = ::Bean
var param1 : (Int , String) -> Bean = ::Bean
param("qweqwe")
param1(0,"qweqwe")
}
fun call(param: (String) -> Bean){}
fun call_new(param: (Int , String) -> Bean){}
1、函数对象的参数要与构造方法的参数保持一致(体现在参数个数与参数类型上)。
2、函数对象的返回结果与构造方法所在类的类型保持一致。
在多构造函数的类中,直接使用(::Bean)去调用构造方法会报错,因为不知道该引用的函数类型,所以需要先定义一个变量去接收,而且需要明确写出函数类型,然后再用改变量去调用方法,就可以了


4、类引用
1、通过类引用 KClass
fun main() {
val c : KClass<String> = String::class // 获取 KClass
println(c) // 打印:class kotlin.String
val c2 : Class<String> = String::class.java // 获取 Java Class
println(c2) // 打印:class java.lang.String
}
KClass 引用了 kotlin 类(具有内省能力)。类似于 Java 的 class 。要获取一个类的 KClass,通过类型名
::class获得,而对应的 Java class 则通过类型名::class.java获得
2、通过实例引用 KClass
open class Parent
class Son:Parent()
class Daughter: Parent()
fun main(){
val son:Parent = Son()
val daughter: Parent = Daughter()
var str : String = "asdasd"
println(son::class) // 打印:com.demo.kotlindemo.Son
println(son::class.java) // 打印:com.demo.kotlindemo.Son
println(daughter::class) //打印:class com.demo.kotlindemo.Daughter
println(daughter::class.java) //打印:class com.demo.kotlindemo.Daughter
println(str::class) //打印:class class kotlin.String
println(str::class.java) //打印:class class java.lang.String
}
可以看到虽然 对象声明时使用的是父类型,但它的 KClass 仍然是具体的子类型。此外,对于自定义的类(java中没有的类),KClass 和 java class 的输出是一样的。java与kotlin都有的共同类,KClass 和 java class 的输出是不一样的。
匿名函数
要传一个函数类型的参数,或者把一个函数类型的对象赋值给变量,除了用双冒号来拿现成的函数使用,你还可以直接把这个函数挪过来写:
fun param(funParam: (Int) -> String): String {
return funParam(1)
}
fun main(){
param(fun (param: Int): String {
return param.toString()
})
//aaaa 是一个函数引用
val aaaa = fun(param: Int): String {
return param.toString()
}
}
这种写法叫做匿名函数。匿名函数还能更简化一点,写成 Lambda 表达式的形式
Lambda 表达式
如果 Lambda 是函数的最后一个参数,你可以把 Lambda 写在括号的外面
fun param(funParam: (String , Int) -> String): String {
return funParam("11", 1)
}
fun main(){
param(fun (param: String , intger : Int): String {
return param.toString()
})
// => 如果 Lambda 是函数的最后一个参数,你可以把 Lambda 写在括号的外面
param(){ param : String , intger : Int -> String
param.toString()
}
// => 而如果 Lambda 是函数唯一的参数,你还可以直接把括号去了:
param{ param : String , intger : Int -> String
param.toString()
}
// => 另外,如果这个 Lambda 是多参数,但有些参数未使用,使用“_”下划线代替
param{ param : String , _ -> String
param.toString()
}
// => 还可以省略参数的类型声明以及返回值的类型
param{ param , _ ->
param.toString()
}
}
另外,如果这个 Lambda 是单参数的,它的这个参数也省略掉不写, Kotlin 的 Lambda 对于省略的唯一参数有默认的名字:it
//这里有明确的函数声明
fun param(funParam: (String) -> String): String {
return funParam("11")
}
fun main(){
param{ param ->
param.toString()
}
// => 如果这个 Lambda 是单参数的,可以把参数省略,Lambda 对于省略的唯一参数有默认的名字:it
param{
it.toString()
}
}
需要注意一点,就是允许这么写的前提是,函数a的声明有明确函数类型的参数信息
//这里有明确的函数声明
fun param(funParam: (String) -> String): String {
return funParam("11")
}
所以 Lambda 才不用写的。当你要把一个匿名函数赋值给变量而不是作为函数参数传递的时候:
val b = fun(param: Int): String {
return param.toString()
}
//=>写成 Lambda出错
val b = {
it.toString() //it报错
}
这里不能省略掉 Lambda 的参数类型,因为它无法从上下文中推断出这个参数的类型
可以这么写:
val b = { param: Int ->
param.toString()
}
// =>或
val b: (Int) -> String = {
it.toString() // it 可以被推断出是 Int 类型
}
因为 Lambda 是个代码块,它总能根据最后一行代码来推断出返回值类型,所以它的返回值类型确实可以不写。 另外 Lambda的返回值不是用 return 来返回,而是直接取最后一行代码的值。这个一定注意,Lambda 的返回值别写 return,如果你写了,它会把这个作为它外层的函数的返回值来直接结束外层函数。当然如果你就是想这么做那没问题啊,但如果你是只是想返回 Lambda,这么写就出错了。
Kotlin 的匿名函数和 Lambda 表达式的本质,它们都是函数类型的对象。在 Kotlin 里「函数并不能传递,传递的是对象」且「匿名函数和 Lambda 表达式其实都是对象」
六个常用的高阶函数
作用域函数是Kotlin比较重要的一个特性。简单来说,就是在此作用域中,可以访问该对象而无需其名称。这些函数称为作用域函数。
我们在写java中adapter类的时候,经常有这样的写法:
holder.mBinding.itemTitle.setText("xxxx");
holder.mBinding.itemContent.setText(mQuestionsDTO.getChecklistName());
holder.mBinding.itemLine.setVisibility(View.GONE);
面对这样的书写方式,我们可以使用kotlin中的作用域函数,等价于下面这个:
holder.mBinding.let{ //这块就是holder.mBinding对象的作用域,在这个作用域中,可以使用it来对mBinding对象做任何操作
it.itemTitle.setText("xxxx");
it.itemContent.setText(mQuestionsDTO.getChecklistName());
it.itemLine.setVisibility(View.GONE);
}
简单来说,作用域函数是为了方便对一个对象进行访问和操作,你可以对它进行空检查或者修改它的属性或者直接返回它的值等操作。
1、T.let{}
public inline fun <T, R> T.let(block: (T) -> R): R {
return block(this)
}
let函数是参数化类型 T 的扩展函数。在let块内可以通过 it 指代该对象。返回值为let块的最后一行或指定return表达式。在Kotlin中,如果let块中的最后一条语句是非赋值语句,则默认情况下它是返回语句。
- let块中的最后一条语句如果是非赋值语句,则默认情况下它是返回语句,反之,则返回的是一个 Unit类型
class Book() {
var name = "《数据结构》"
var price = 60
fun displayInfo() = print("Book name : $name and price : $price")
}
fun main(){
val book = Book().let {
it.name = "《计算机网络》"
"This book is ${it.name}"
}
println(book) //输出This book is 《计算机网络》
val book1 = Book().let {
///在函数体内使用it代替对象去访问其公有方法和属性
it.name = "《计算机网络》"
}
println(book1) //输出kotlin.Unit
}
- let可用于空安全检查。
fun main(){
var name: String? = null
//当name不为null时,进入let函数体。否则复制“name为空时的值”这个字符串
val nameLength = name?.let {
it.length
} ?: "name为空时的值"
print(nameLength) //输出 "name为空时的值"
}
- let可进行链式调用。
由于最后一句表达式为let函数的返回值,可以利用这点进行链式调用。
//这是一个切换Fragment的功能
private fun switchFragment(position: Int) {
val transaction = supportFragmentManager.beginTransaction()
hideFragments(transaction) //这个方法是隐藏所有fragment,方法体就不看了,不是重点
when (position) {
0 //第一个fragment
-> mHomeFragment?.let {
transaction.show(it)
} ?: HomeFragment.getInstance(mTitles[position]).let {
mHomeFragment = it
transaction.add(R.id.fl_container, it, "home")
}
1 //第二个fragment
-> mDiscoveryFragment?.let {
transaction.show(it)
} ?: DiscoveryFragment.getInstance(mTitles[position]).let {
mDiscoveryFragment = it
transaction.add(R.id.fl_container, it, "discovery") }
2 //第三个fragment
-> mHotFragment?.let {
transaction.show(it)
} ?: HotFragment.getInstance(mTitles[position]).let {
mHotFragment = it
transaction.add(R.id.fl_container, it, "hot") }
3 //第四个fragment
-> mMineFragment?.let {
transaction.show(it)
} ?: MineFragment.getInstance(mTitles[position]).let {
mMineFragment = it
transaction.add(R.id.fl_container, it, "mine") }
}
}
- let可以将“It”重命名为一个可读的lambda参数。
class Book() {
var name = "《数据结构》"
var price = 60
fun displayInfo() = print("Book name : $name and price : $price")
}
fun main(){
//对自带的it进行了重命名为book
val book = Book().let {book ->
book.name = "《计算机网络》"
}
}
2、T.run{}
public inline fun <T, R> T.run(block: T.() -> R): R {
return block()
}
run函数是参数化类型 T 的扩展函数。在run块内可以通过 this 指代该对象,且它的调用方式与let一致。返回值为run块的最后一行或指定return表达式。
class Book() {
var name = "《数据结构》"
var price = 60
fun displayInfo() = print("Book name : $name and price : $price")
}
fun main(){
Book().run {
//在run块内可以通过 this 指代该对象,可以省略this
name = "《计算机网络》"
price = 30
displayInfo()
}
//与let的区别。
Book().let {
it.name = "《计算机网络》"
it.price = 30
it.displayInfo()
}
}
3、run{}
public inline fun <R> run(block: () -> R): R {
return block()
}
run不是扩展函数,是一个普通的高阶函数。其返回值是函数块里的最后一句话或者指定return表达式。
fun main(){
var animal = "cat"
run {
var animal = "dog"
println(animal) // dog
}
println(animal) //cat
}
在这个简单的main函数当中我们拥有一个单独的作用域,在run函数中能够重新定义一个animal变量,并且它的作用域只存在于run函数当中。目前对于这个run函数看起来貌似没有什么用处,但是在run函数当中它不仅仅只是一个作用域,他还有一个返回值。他会返回在这个作用域当中的最后一个对象。
利用返回值的这个特点,我们可以有一下操作
run {
var animal: String? = "dog"
animal ?: "cat"
}.length
获得字符串的长度。当animal不为空时返回animal的长度,为空则返回"cat"的长度。这样比if和else看起来优雅很多。在我们项目业务中经常遇见:如果用户没有登录进入登录页面,如果已经登录进入其他页面。这样的场景就可以使用。
4、with(object){}
public inline fun <T, R> with(receiver: T, block: T.() -> R): R {
return receiver.block()
}
with不是扩展函数,只是一个普通的高阶函数。但是它传入的高阶函数是一个扩展函数。在with块内可以通过 this 指代该对象,且它的调用方式与run一致。返回值为with块的最后一行或指定return表达式。
class Book() {
var name = "《数据结构》"
var price = 60
fun displayInfo() = print("Book name : and price : ")
}
fun main(){
with(Book()) {
name = "《计算机网络》"
price = 30
displayInfo()
}
}
with和T.run其实做的是同一种事情,对上下文对象都称之为“this”,但是他们又存在着不同。
fun main(){
val book: Book? = null
with(book){
this?.name = "《计算机网络》"
this?.price = 40
}
book?.run{
name = "《计算机网络》"
price = 40
}
}
相比较with来说,run函数更加简便,空安全检查也没有with那么频繁。
5、T.also{}
public inline fun <T> T.also(block: (T) -> Unit): T {
block(this)
return this
}
also是 T 的扩展函数,also函数的用法类似于let函数,将对象的上下文引用为“it”而不是“this”以及提供空安全检查方面。但是它和let的区别是返回值,它返回的是本身的调用者,let的返回值是函数块最后一条语句。
val book : Book = Book().also {
it.name = "《计算机网络》"
it.price = 40
}
print(book.name)
also的返回值就是其调用者本身,因此可以利用这个特点进行链式结构
Book().also {
it.name = "《计算机网络》"
it.price = 40
}.let {
//这里it是 Book() 对象
println(it.name)
}
6、T.apply{}
public inline fun <T> T.apply(block: T.() -> Unit): T {
block()
return this
}
apply是 T 的扩展函数,与run函数有些相似,它将对象的上下文引用为“this”而不是“it”,并且提供空安全检查,不同的是,apply不接受函数块中的返回值,返回的是自己的T类型对象。
Book().apply {
name = "《计算机网络》"
price = 40
}.let {
println(it.name)
}
apply返回的是自己的T类型对象。因此它也可以利用这个特点进行链式结构。
总结
| 函数名 | 对象的上下文引用 | 返回值 | 空安全检查 |
|---|---|---|---|
T.let{} | it | 函数块中的最后一句代码或指定的return语句 | T?.let{} |
T.run{} | this | 函数块中的最后一句代码或指定的return语句 | T?.run{} |
run{} | 无 | 函数块中的最后一句代码或指定的return语句 | 函数块中自检 |
with(object){} | this | 函数块中的最后一句代码或指定的return语句 | 函数块中自检 |
T.also{} | it | T(调用者本身) | T?.also{} |
T.apply{} | this | T(调用者本身) | T?.apply{} |
2.扩展函数
扩展函数与成员函数的区别:确切地说,不是任何一个类的成员函数——但我要限制只有通过某个 类的对象才能调用你。这就是扩展函数的本质。
扩展函数
在声明一个函数的时候在函数名的左边写个类名再加个点,你就能对这个类的对象调用这个函数了。
这种函数就叫扩展函数。
fun MutableList<Int>.swap(a:Int , b:Int){
val tmp = this[a]
this[a] = this[b]
this[b] = tmp
}
fun main(){
val list = mutableListOf(1,2,3)
//调用
list.swap(0,2)
}
例子中是给 MutableList<Int> 类型的变量添加了一个内部方法,方法中用this即可表示扩展目标的对象
注意:扩展并不是真正的修改他们所扩展的类,通过定义一个扩展,你并没有在一个类中插入新成员,仅仅只是可以通过该类型的变量用点表达式去调用这个新函数而已。
- 扩展函数的调用,取决于所在的表达式的类型来决定的,并不是运行时类型决定的
open class Father
class Son:Father()
fun Father.foo() = "C"
fun Son.foo() = "D"
fun printFoo(a : Father){
//该表达式类型(a : Father)决定调用的是Father的扩展函数
println("结果:" + a.foo())
}
fun main(){
printFoo(Son())
//该表达式类型(d : Father)决定调用的是Father的扩展函数
var d : Father = Son()
println(d.foo())
//该表达式类型(e : Son)决定调用的是Son的扩展函数
var e : Son = Son()
println(e.foo())
}
——打印——
结果:C
C
- 如果一个类定义有一个成员函数和一个扩展函数,他们完全相同(函数名和参数个数都相同)时,那么调用时总是取成员函数
open class Father{
fun foo(){
println("member")
}
}
fun Father.foo(){
println("extension")
}
fun main(){
var c = Father()
c.foo()
}
——打印——
member
- 扩展函数里的this语法
class Son {
var age = 2
}
open class Father{
var age = 30
fun Son.foo(){
//这里使用的是扩展类的成员age,即son类中的成员age
println("$age")
//使用this@Father可以得到本类(Father)中的成员age,这个this指定了是Father类
println("${[email protected]}")
}
fun getFoo(){
var girl = Son()
girl.foo()
}
}
fun main(){
var c = Father()
c.getFoo()
}
——打印——
2
30
- open的扩展函数调用情况:子类调用子类继承的扩展函数。
class D1{}
open class Father{
open fun D1.foo(){
println("Father -> D1")
}
fun caller(d: D1){
d.foo()
}
}
class Son :Father() {
override fun D1.foo() {
println("Son -> D1")
}
}
fun main(){
Son().caller(D1())
}
1、顶层扩展函数
package com.demo.kotlindemo
fun String.method1(i: Int) {
}
fun main(){
"rengwuxian".method1(1)
}
顶层扩展函数不属于某个类,但是仅有指定类的对象可以调用它。顶层扩展函数写在kt文件里的。
2、成员扩展函数
扩展函数也可以写在某个类里:
open class Father{
open fun D1.foo(){
println("Father -> D1")
}
fun caller(d: D1){
//只能在该类里调用这个扩展函数,在这里类外就无法调用
d.foo()
}
}
就可以在这个类里调用这个函数,但必须使用那个前缀类的对象来调用它。类外就无法调用这个扩展函数,该扩展函数是Father类的成员函数,也是D1类的扩展函数。
这种扩展函数不存在函数引用。Kotlin 不许我们引用既是成员函数又是扩展函数的函数。
3、伴生对象扩展函数
class Bean {
companion object{}
}
fun Bean.companion.foo( a : Int){
print("伴生对象的扩展函数")
}
fun main(){
Bean.foo(1)
}
伴生对象的扩展函数使用:用类名调用该扩展函数。
4、从java代码看扩展函数
class Bean {}
fun Bean.foo(a : Int){
}
反编译后,可以看下java中的样子
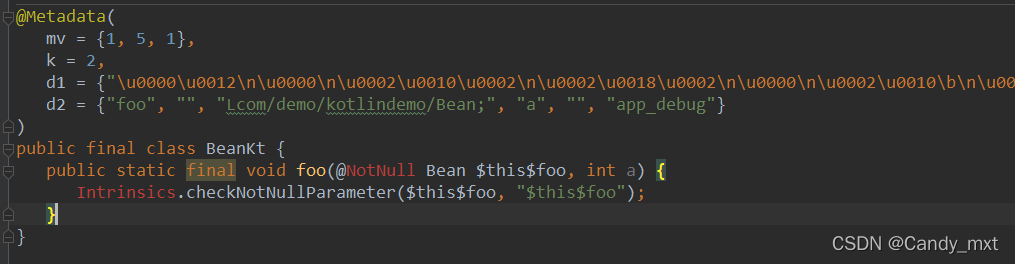
可以看出这是一个顶层扩展函数,在java中顶层声明会自动生成一个类名+kt的类。可以看到扩展函数foo在Beankt类中属于成员函数,第一个参数是Bean的对象(前缀类的对象),第二个参数是扩展函数正常需要传参的变量a
所以主要看扩展函数写在哪个位置,写在某个类里,则为那个类的成员函数,写在顶层里,则为文件名+kt该类的成员函数。
扩展函数的引用
扩展函数引用: 扩展类名::函数名
1、通过引用调用扩展函数
fun String.method1(i: Int) {}
(String::method1)("rengwuxian",1) // 扩展函数: 等价于 "rengwuxian".method1(1)
//相当于
String::method1.invoke("rengwuxian", 1)
//等价于
"rengwuxian".method1(1)
当拿着一个函数的引用去调用的时候,不管是一个普通的成员函数还是扩展函数,你都需要把 Receiver 也就是接收者或者调用者作为第一个参数填进去。从前面讲的《从java代码看扩展函数》可以看到扩展函数其实就是某个类的成员函数,第一个参数就是其接收者或者调用者。
(String::method1)("rengwuxian", 1) // 扩展函数: 等价于 "rengwuxian".method1(1)
(Int::toFloat)(1) //成员函数 : 等价于 1.toFloat()
2、把扩展函数的引用赋值给变量
val a: String.(Int) -> Unit = String::method1
然后再拿着这个变量去调用,或者再次传递给别的变量,都是可以的
"rengwuxian".a(1) //实际调用的是a.invoke()
a("rengwuxian", 1) //实际调用的是a.invoke()
a.invoke("rengwuxian", 1) //实际调用的是a.invoke()
val b = a
b("aa",1) //实际上调用的是a.invoke("aa", 1);
b是等于a的,a是指向扩展函数method1的引用,因此b也是这个扩展函数的引用
3、有无 Receiver 的变量的互换
我们叫扩展函数就是一个有 Receiver的函数;普通的函数就是一个无 Receiver的函数。同理,接收扩展函数引用的变量为有Receiver的变量,接收普通函数引用的变量为无Receiver的变量。
//有Receiver的变量
val a: String.(Int) -> Unit = String::method1
//无Receiver的变量
val b: (String, Int) -> Unit = String::method1
成员函数和扩展函数,它的引用都可以赋值给两种不同的函数类型变量:一种是有 Receiver 的,一种是没有 Receiver 的。
个人理解:这里只是定义了一个普通函数引用的变量,把它的函数引用指向了扩展函数的引用,因此b变量引用的函数的函数体就是这个扩展函数的函数体。b不是扩展函数的引用,是
(String, Int) -> Unit函数的引用。
(String::method1)("rengwuxian", 1) //可以调用
b("rengwuxian", 1) //可以调用 这就是普通函数调用而已
"rengwuxian".b(1) //不允许调用,报错,b不是扩展函数的引用
"rengwuxian".a(1) //可以调用 ,a是扩展函数的引用
这两种类型的变量也可以互相赋值来进行转换
val a: String.(Int) -> Unit = String::method1
val b: (String, Int) -> Unit = String::method1
val c: String.(Int) -> Unit = b
val d: (String, Int) -> Unit = a
b("rengwuxian", 1) //可以调用 这就是普通函数调用而已 等价b.invoke("rengwuxian", 1)
c("rengwuxian", 1) //可以调用 这是扩展函数的引用调用
"rengwuxian".c(1) // 可以调用
但是他们的含义不一样。b和d是普通函数,a和c是扩展函数。
注意,扩展函数的引用是:扩展类::方法名 , 所以如果该扩展函数即是成员函数又是扩展函数,则这种扩展函数不存在函数引用,Kotlin 不许我们引用既是成员函数又是扩展函数的函数。
扩展属性
除了扩展函数,Kotlin 的扩展还包括扩展属性。它跟扩展函数是一个逻辑,就是在声明的属性左边写上类名加点,这就是一个扩展属性了。
val Float.dp
get() = TypedValue.applyDimension(
TypedValue.COMPLEX_UNIT_DIP,
this,
Resources.getSystem().displayMetrics
)
//使用
val RADIUS = 200f.dp
它的用法和扩展函数一样。它没有默认的getter和setter方法,需要自己实现。由于扩展没有实际的将成员插入类中,因此对于扩展属性来说幕后字段是无效的。所以扩展属性不能有初始化器。它们的行为只能由显示提供的getter和setter方法定义
3.内联函数
Java 里有个概念叫编译时常量。这种编译时常量,会被编译器以内联的形式进行编译,也就是直接把你的值拿过去替换掉调用处的变量名来编译。
const val ACTION = "学习kotlin"
//调用处
fun main(){
var any = ACTION
}
//实际编译的代码
public static final void main() {
String any = "学习kotlin";
}
让变量内联用的是 const;而除了变量,Kotlin 还增加了对函数进行内联的支持。
个人理解:因为函数体通常比常量复杂多了,而函数内联会导致函数体被拷贝到每个调用处,如果函数体比较大而被调用处又比较多,就会导致编译出的字节码变大很多。我们都知道编译结果的压缩是应用优化的一大指标,而函数内联对于这项指标是明显不利的。所以靠inline 来做性能优化是不存在的,也不能无脑的使用 inline
inline的使用
在 Kotlin 里,你给一个函数加上 inline 关键字,这个函数就会被以内联的方式进行编译。上面提到,如果使用不当,反而会变成负优化。那这个 inline 的意思在哪?
事实上,inline 关键字不止可以内联自己的内部代码,还可以内联自己内部的内部的代码。什么叫「内部的内部」?就是自己的函数类型的参数。
Java 里并没有对函数类型的变量的原生支持,Kotlin 需要想办法来让这种自己新引入的概念在 JVM 中落地。那就是用一个 JVM 对象来作为函数类型的变量的实际载体,让这个对象去执行实际的代码。
fun hello(postAction: () -> Unit){
println("asdad")
postAction()
}
//调用处
fun main(){
hello{
println("asdasdasd")
}
}
程序在每次调用 hello() 的时候都会创建一个对象来执行 Lambda表达式里的代码,虽然这个对象是用一下之后马上就被抛弃,但它确实被创建了。如果这种函数被放在循环里执行或者界面刷新之类的高频场景里,这一类函数就全都有了性能隐患,内存一下就彪起来了。
这就是 inline 关键字出场的时候了。
//加上内联关键字
inline fun hello(postAction: () -> Unit){
println("asdad")
postAction()
}
//调用处
fun main(){
hello{
println("asdasdasd")
}
}
//实际编译的代码
public static final void main() {
String var1 = "asdad";
System.out.println(var1);
String var3 = "asdasdasd";
System.out.println(var3);
}
经过这种优化,就避免了函数类型的参数所造成的临时对象的创建了,就不怕在循环或者界面刷新这样的高频场景里调用它们了
inline可以让你用内联——也就是函数内容直插到调用处——的方式来优化代码结构,从而减少函数类型的对象的创建;
什么时候使用它?如果你写的是高阶函数,会有函数类型的参数,加上inline就对了;如果不怕麻烦,也可以只在会被频繁调用的高阶函数才使用inline
noinline的使用
noinline 的意思很直白:inline 是内联,而 noinline 就是不内联。不过它不是作用于函数的,而是作用于函数的参数。
对于一个标记了
inline的内联函数,你可以对它的任何一个或多个函数类型的参数添加noinline关键字
添加了之后,这个参数就不会参与内联了
//返回一个函数对象
inline fun hello(postAction: () -> Unit) : () -> Unit{
println("asdad")
postAction()
return postAction
}
//调用处
fun main(){
hello{
println("asdasdasd")
}
}
//实际调用情况
fun main(){
println("asdad")
println("asdasdasd")
postAction //这个是返回函数对象,但是由于已经被内联了,这个对象是不存在的,所以这块是错误
}
所以当你要把一个这样的参数当做对象使用的时候,Android Studio 会报错,告诉你这没法编译
加上noinline以后就可以了,这个参数就不会参与内联了

//实际调用情况
fun main(){
println("asdad")
val postAction = ({ println("asdasdasd") }).invoke()
postAction
}
那么,我们应该怎么判断什么时候用
noinline呢?很简单,比inline还要简单:你不用判断,Android Studio 会告诉你的。当你在内联函数里对函数类型的参数使用了风骚操作,Android Studio 拒绝编译的时候,你再加上noinline就可以了。
crossinline的使用
crossinline 也是一个用在参数上的关键字。
Kotlin 制定了一条规则:
Lambda表达式里不允许使用return,除非——这个Lambda是内联函数的参数。
但是如果为内联函数,就可以使用return,但是返回的最外层函数
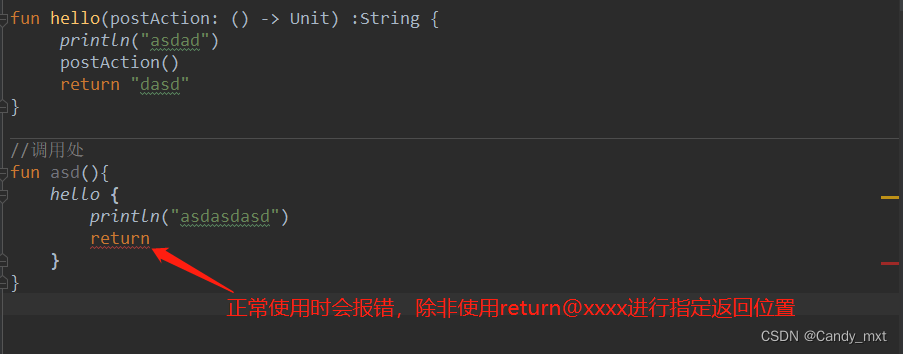
inline fun hello(postAction: () -> Unit){
println("asdad")
postAction()
}
//调用处
fun asd(){
hello {
println("asdasdasd")
return
}
}
//实际调用情况
fun asd(){
println("asdad")
println("asdasdasd")
return
}
那这样的话规则就简单了:
1、Lambda里的return,正常是不可以使用的,除非使用return@xxxx指定返回地方就可以使用
2、只有内联函数的Lambda参数可以使用return,但结束的不是直接的外层函数,而是外层再外层的函数
有一个疑问:如果内联函数里是间接调用的函数参数,还能不能用return呢?

可以看到,间接调用会报错。kotlin中内联函数里的函数类型的参数是不允许这种间接调用。
如果我真的需要间接调用,就使用 crossinline。需要注意——Kotlin 增加了一条额外规定:内联函数里被 crossinline 修饰的函数类型的参数,将不再享有「Lambda 表达式可以使用 return」的福利。
什么时候需要
crossinline?只要在看到 Android Studio 给你报错的时候把它加上就行了。
六、泛型
1、书写规范
规范
在java中使用泛型,我们常常是这么写的:
//在类方面
class Nick<T , Z >{}
//在函数方面
public <Y , Z , U> Y fun(List<? super T> a , U b ){}
在kotlin中我们书写泛型的形式与java是一样的
//在类方面
class Nick<T , Z >{}
//在函数方面
public <Y , Z , U> fun( a : List<? super T>, b : U ) : Y {}
类型擦除
我们知道,一个子类型是可以赋值给父类型的,比如:
Object obj = "nanchen2251"; // 这是多态
Object 作为 String 的父类,自然可以接受 String 对象的赋值,这样的代码我们早已司空见惯,并没有什么问题。
但当我们写下这串代码:
List<String> list = new ArrayList<String>();
List<Object> objects = list;
上面发生了赋值错误,Java 里面认为 List< String > 和 List< Object > 类型并不一致,也就是说,子类的泛型 List< String > 不属于泛型 List< Object > 的子类。
Java 的泛型本身是一种 「伪泛型」,Java 为了兼容 1.5 以前的版本,不得以在泛型底层实现上使用 Object 引用,所以我们声明的泛型在编译时会发生「类型擦除」,泛型类型会被 Object 类型取代。只是说等同于object,类型并没有真正擦除
class Demo<T> {
void func(T t){}
}
//会被编译成:
class Demo {
void func(Object t){}
}
编译器会根据我们声明的泛型类型进行提前的类型检查,然后再进行类型擦除,擦除为 Object,但在字节码中其实还存储了我们的泛型的类型信息(类型并没有真正被擦除),在使用到泛型类型的时候会把擦除后的 Object 自动做类型强转操作。
List<String> list = new ArrayList<>();
list.add("nanchen2251");
String str = list.get(0);//虽然我们没有进行类型转换,但是实际上本身就是一个经过强转的 String 对象了。
2、通配符
如果想要这样的代码不报错,我们可以使用通配符
List<String> list = new ArrayList<String>();
List<Object> objects = list;
java中的上界通配符,可以使 Java 泛型具有「协变性 」。
<? extends T>: 能够接受指定类及其子类类型的数据
kotlin中的上界通配符:< out T>
< out T>:「只能读取不能修改」,这里的修改仅指对泛型集合添加元素,如果是remove(int index)以及 clear 当然是可以的。
open class Animal
interface Middle
open class Cat : Animal() , Middle
var one: MutableList<Int> = ArrayList()
//在具体类中使用
var list: MutableList< out Number> = one
MutableList< out Number> 能够接受Number类以及它子类类型的数据,所以把MutableList< Int >类型数数据赋值给它是完全没有问题的。等价于java中的<? extends T>
out自己的特点
修饰泛型时,只能定义为返回值,不能定义为参数,否则编译器会报错。
被out修饰的泛型,只能作为方法的返回值类型,不能作为参数的类型。因为它「只能读取不能修改」,kotlin会进行检测,认为传入的参数可能会被修改。@UnsafeVariance的使用
如果你确定被out修饰的泛型,你不会进行修改,可以使用@UnsafeVariance进行修饰,这样编译器就不会报错,但需要自己保证不会去写入数据,否则会导致类型转换异常
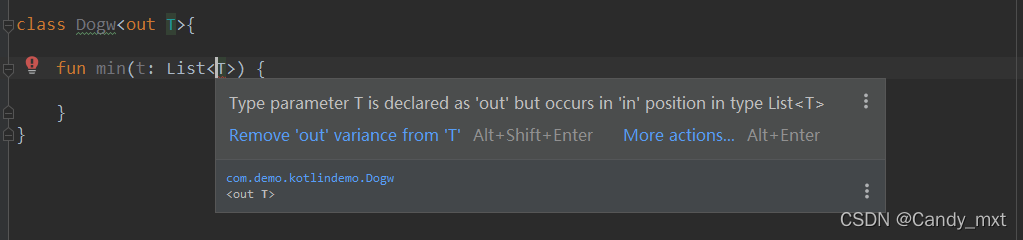
open class Animal
interface Middle
open class Cat : Animal() , Middle
class Dod : Cat()
class Dogw<out T>{
//报错,需要自己保证不会进行写数据
fun min(t: List<@UnsafeVariance T>) {}
//这是可以的,作为输出
fun max() : T {}
}
fun callmy(){
var dd : Dogw<Dod> = Dogw<Dod>()
//这是可以的,因为T被out修饰,可以接受其类和其子类的类型赋值
var ee : Dogw<Cat> = dd
var dwmo : Dogw<Animal> = ee
}
java中的下界通配符,可以使 Java 泛型具有「逆变性 」。
<? super T>: 能够接受指定类及其父类类型的数据
kotlin中的下界通配符:< in T>
< in T>:「只能修改不能读取」,这里说的不能读取是指不能按照泛型类型读取,你如果按照 Object 读出来再强转当然也是可以的。
open class Animal
interface Middle
open class Cat : Animal() , Middle
class Dod : Cat()
fun callmy(){
var dwmo : MutableList<Animal> = mutableListOf()
//用在具体的类上
var ee : MutableList<in Cat> = dwmo
//如果按照 Object 读出来再强转当然也是可以的。
var frist : Animal = ee[0] as Animal
//会报错,因为不能读取,这里说的不能读取是指不能按照具体类型读取,但可以按照Any类型读取
var frist : Animal = ee[0]
var frist : Any? = ee[0] //可以
}
MutableList<in Cat> 能够接受Cat类以及它父类类型的数据,所以把MutableList<Animal>类型数数据赋值给它是完全没有问题的。等价于java中的<? super T>
in自己的特点
修饰泛型时,只能定义为参数,不能定义为返回值,否则编译器会报错。
这里也是可以使用
@UnsafeVariance的,逆变中也可以使用@UnsafeVariance注解来强行让泛型T作为输出位置,编译是完全正常的没有报错,但是需要自己保证不会按照具体类型读取,否则会报类转换异常。
class Dogw<in T>{
fun min(t: List<T>) {}
fun max() : @UnsafeVariance T {}
}
Java中单个
<?>也能作为泛型通配符使用,这是一个无边界通配符,能接受未知类型的数据,相当于<? extends object>
kotlin中的等效写法:<*>相当于<out Any?>
3、泛型上界约束
单个上界约束
java中的单个上界约束
public class Day{}
class Nick<T extends Day >{}
kotlin中的单个上界约束
open class Animal{}
class Dogw< T : Animal>{}
Dogw类支持的泛型类型必须是Animal的子类;Nick支持的泛型类型必须是Day的子类。
多个上界约束
java中的多个上界约束
public class Day{}
interface Middle{}
class Nick<T extends Day & Middle > {}
kotlin中的多个上界约束
open class Animal
interface Middle
class PetShop<T> where T : Animal , T : Middle {}
PetShop类支持的泛型类型必须是Animal 和 Middle的子类;Nick支持的泛型类型必须是Day和 Middle的子类
4、多个泛型参数声明
多个泛型,可以通过 , 进行分割多个声明
class Dogw< T : Animal , Z, Y>{}
多个泛型参数声明,java与kotlin是一样的方式。
结语
提示:纯属个人理解,欢迎各位大神或同学进行指教批评
以上是我对kotlin语言的个人理解,如果理解错误的地方,欢迎各位大神或同学进行指教批评。本人比较懒,如果有时间会继续出kotlin最基础的知识点总汇,本篇文章不太适合刚接触kotlin的小白学习。