总结于B站鲁班大叔视频:https://www.bilibili.com/video/BV1Tp4y1X7FM?p=13&spm_id_from=pageDriver
概述
JDBC的执行流程可以大致分为:
- 获得连接
- 预编译sql
- 设置参数
- 执行sql
Mybatis执行原理大致分为:
- 动态代理MapperProxy
- sql会话Sqlsession
- 执行器Executor
- JDBC处理器StatementHandler
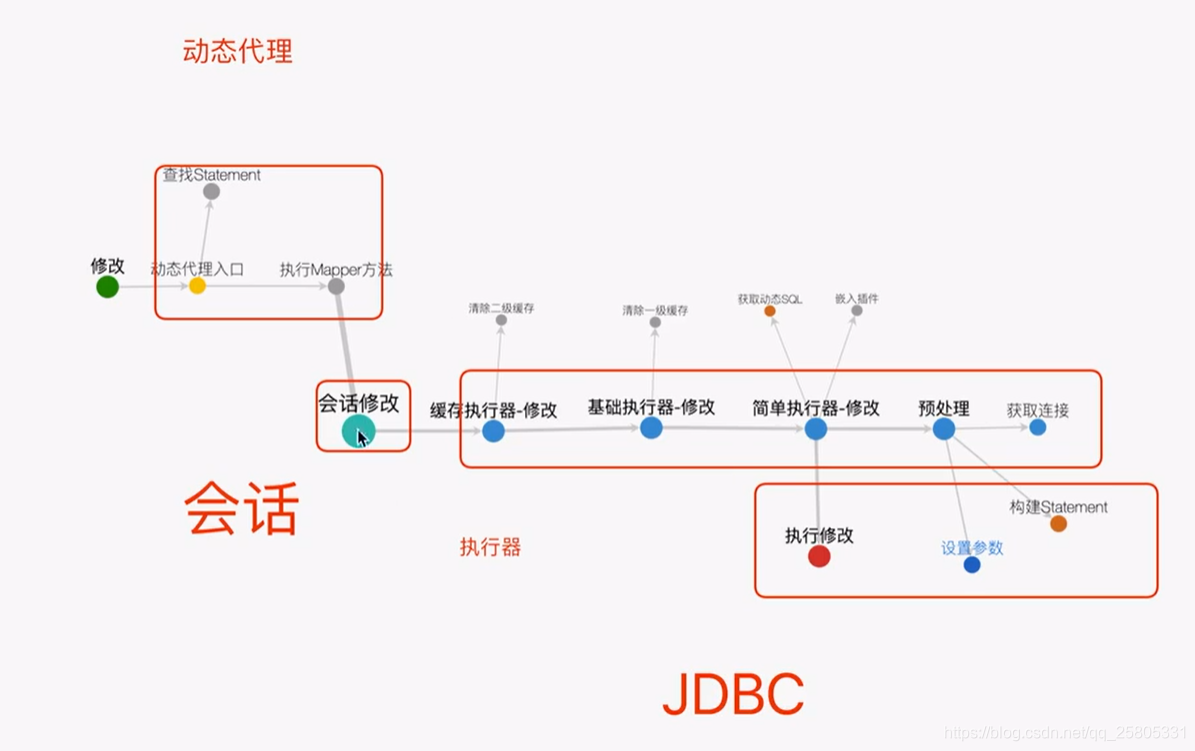
图中JDBC圈起来的部分就对应了sql具体的执行过程,属于Mybatis执行器范围内。本文主要针对sql会话与执行器来展开讨论。
Mybatis的执行过程
Mybatis使用门面模式提供了统一的门面接口API:
- 基本的API:增、删、改、查等
- 辅助的API:提交、关闭会话等
这些统一的API就是Sqlsession提供的,具体的API实现交由执行器来完成。

Executor的实现
- SimpleExecutor(默认实现)
- 其每次执行sql,无论sql是否一样,都会进行sql的预处理。
- ReuseExecutor(可复用MappedStatement,MappedStatement包装的是sql信息)
- 如果多次执行的sql一致,只会进行一次sql预处理。
- sql的重用,之和sql有关,即sql和参数一致,就可以重用,这个很重要。
- BatchExecutor(批处理)
- 只针对增、删、改操作,也就是修改操作。如果是查询语句,则和SimpleExecutor没有区别。
- 在批处理的情况下,对相同的sql,只会预处理一次,多次设置sql的参数值。
- 必须手动调用BatchExecutor.doFlushStatement()方法提交事务。
- BaseExecutor(执行器抽象类)
- 实现SimpleExecutor、BatchExecutor、ReuseExecutor三者的重复操作:一级缓存、获取连接等。
- SimpleExecutor、BatchExecutor、ReuseExecutor继承BaseExecutor,BaseExecutor实现Executor。
- 定义query和doUpdate方法供SimpleExecutor、BatchExecutor、ReuseExecutor使用。

一级缓存
由于一级缓存、获取连接的实现在BaseExecutor中,单独使用SimpleExecutor、BatchExecutor、ReuseExecutor就无法得到BaseExecutor的支持:
- BaseExecutor中query方法会创建缓存的key,并调用其重载的方法query方法,通过localcache(key)去获取一级缓存,如果没有缓存,就会去调用doQuery方法,这个【doQuery】方法就是子类(SimpleExecutor、BatchExecutor、ReuseExecutor)中实现的数据库操作方法。
二级缓存
- CachingExecutor
- 实现Executor接口
- 只专注实现二级缓存的逻辑。
- CachingExecutor二级缓存的逻辑执行完成之后,将会把业务交由下一个执行器处理。下一个执行器(SimpleExecutor或BatchExecutor或ReuseExecutor)由构造方法指定。装饰者模式。
需要注意的是:
- 一级缓存的数据是开始执行的时候就生成了,二级缓存的数据是提交执行过后才会生成。
- 之后的查询会先访问二级缓存,再访问一级缓存。
缓存命中场景
一级缓存
一级缓存是key-value形式的,实质底层就是一个HashMap。作用范围是sqlsession,当数据库会话结束之后,随之消亡。
命中条件:
- sql和参数相同。
- 相同的statementID(需要调用相同mapper中的查询方法相同)
- 同一个sqlsession(这就是为什么一级缓存也叫会话级缓存)
- 如果是分页查询,使用的RowBounds也要相同(也就是查询起始行、查询数据大小都要相同)
影响命中一级缓存的设置:
- 手动清空sqlsession.clearCache()
- Mapper层(DAO层)查询方法使用了@Options(fluashCache = Opions.FlushCachePolicy.TRUE)
- 该参数设置在每次查询后都会清空一级缓存
- 执行了update操作
- rollback也会清空相应的缓存
Spring集成mybatis一级缓存失效问题
spring集成Mybatis之后,不满足同一个sqlsession,导致一级缓存失效。在没有配置事务的情况下,每次执行sql都会构造一个新的会话。是由于srping的动态代理导致的。
解决办法就是将sql执行放在同一个事务中,就会使用同一个sqlsession,同一个sqlsession的情况下,一级缓存就不会失效。
二级缓存
为什么已经有了一级缓存,还需要二级缓存呢?
二级缓存也称作是应用级缓存,与一级缓存不同的是它的作用范围是整个应用,而且可以跨线程使用。所以二级缓存有更高的命中率,适合缓存一些修改较少的数据。
- 二级缓存可以使用内存和磁盘进行存储。
- 溢出淘汰:在有限的内存中缓存数据,始终会面临缓存承载满的情况,就会存在缓存淘汰机制
- FIFO,先进先出的淘汰算法。
- LRU,最近最少使用的淘汰机制。
- 缓存设置过期时间,会进行过期清理。
- 线程安全
- 命中率统计
- 序列化
Mybatis二级缓存设计、
接口定义:
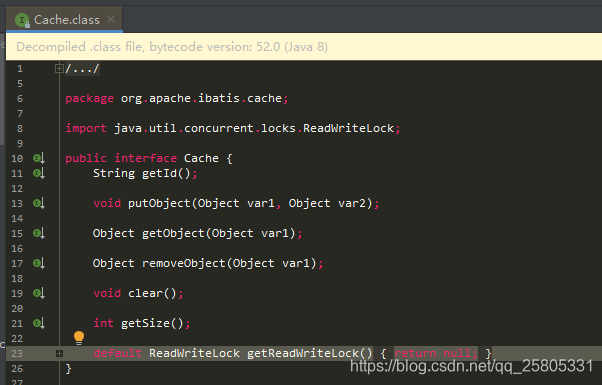
实现类
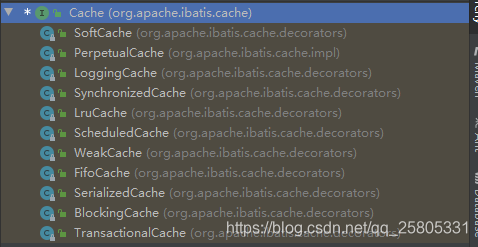
Mybatis使用装饰器+责任链模式构建了完整的二级缓存结构:
- SynchronizedCache:线程同步
- LoggingCache:记录命中率
- LruCache:防止溢出
- ScheduledCache:过期清理
- BlockingCache:防止内存穿透
- PerpetualCache:内存存储
调用Cache实现类的任何方法都会沿着上面的xxxCache完成装饰,并执行。
二级缓存命中条件:
- 必须提交了事务
- 即使是设置了autocommite也不能命中缓存,除非是手动调用了commite方法,或者是关闭当前的事务。
- sql和参数相同。
- 如果是分页查询,使用的RowBounds也要相同(也就是查询起始行、查询数据大小都要相同)
影响二级缓存命中的设置:
- 缓存的开关userCache = true。
- Mapper层(DAO层)查询方法使用了@Options(fluashCache = Opions.FlushCachePolicy.TRUE)
- 该参数设置在每次查询后都会清空一级缓存
- 声明缓存空间
- <cache><cache/>或者@CacheNamespace
- 同时必须引用缓存空间:<cache-ref>或@CacehNamespaceRef
为什么要提交之后才能命中二级缓存?
因为二级缓存是跨线程使用的:
例如sqlsessionA和sqlsessionB去查询同样的数据
- A先修改了数据,再对该数据进行查询
- B去查询该数据将结果填充进入二级缓存
- A去查询该数据的时候,B进行的回滚
- A这时候如果从二级缓存读取数据,就会产生脏读。
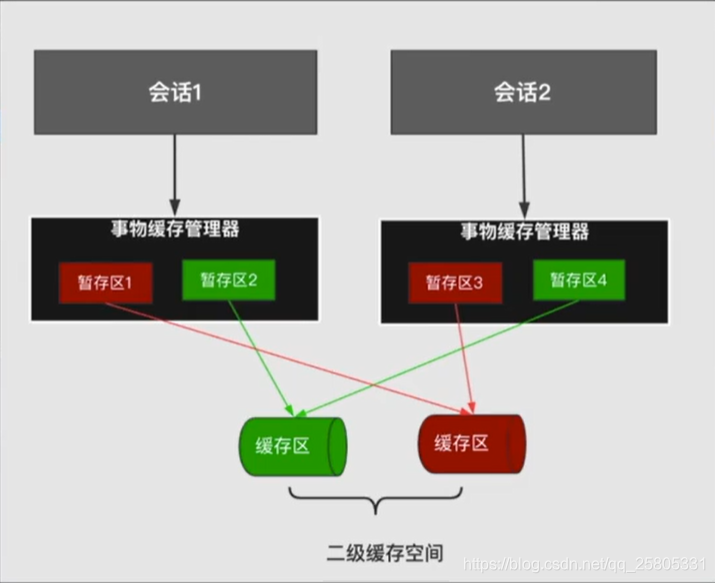
所有执行结果在commit之前,都会放入事务缓存管理器的暂存区,只有被commit之后才会放入缓存区,这里的缓存区指的就是装饰器+责任链模式构建了完整的二级缓存结构。
StatementHandler
JDBC处理器,基于JDBC构建的Statement并设置参数,然后执行sql,没调用会话当中的一次sql,就有与之相对应的且唯一的Statement实例。
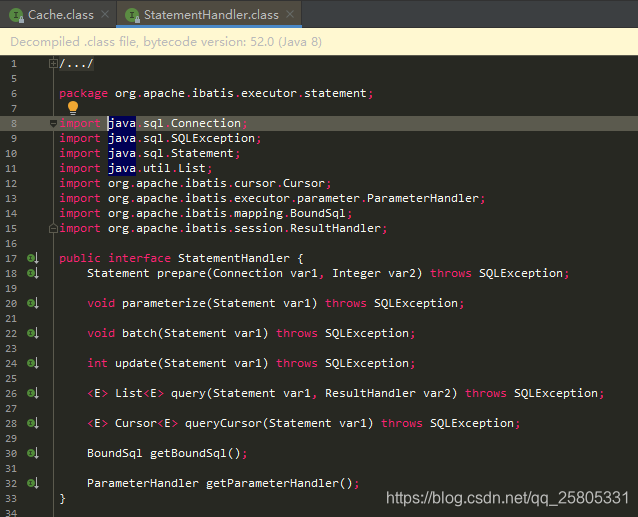
主要功能
- 声明(创建)Statement
- prepare方法基于Connection创建Statement。
- 设置参数
- 查询
- 修改
主要是实现:

- BaseStatementHandler(从子类处理器中抽象出公共的处理逻辑)
- SimpleStatementHandler(简单处理器)
- PreparedStatementHandler(预处理器)
- 大多数情况下都是使用该处理器,预处理性能更高,会进行参数转义,防止sql注入。
- CallableStatementHandler(存储过程处理器)
PreparedStatementHandler执行流程
这个过程包括从 执行器 -> StatementHandler -> 参数处理 -> 结果集处理
- 执行器
- StatementHandler
- 预编译
- 设置参数
- 执行sql
- 结果集映射成Java bean
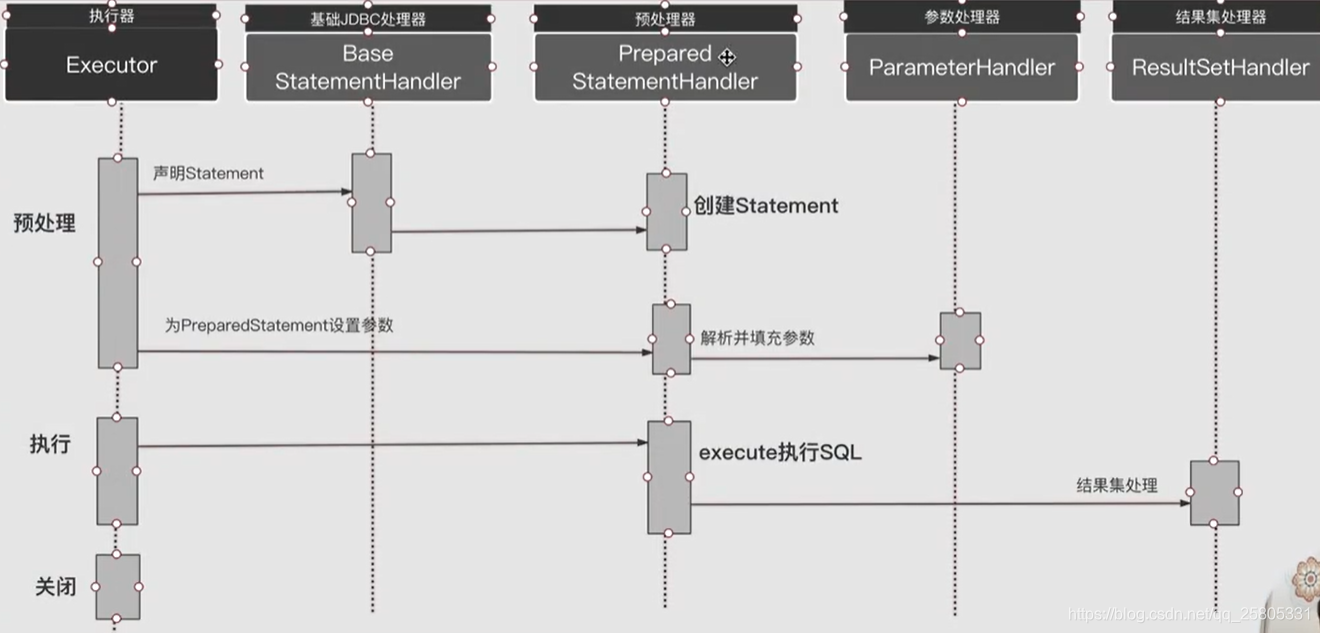
声明或者是创建Statement
执行查询的开始代码,是在具体Executor的实现类中的doQuery方法:
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
//创建Statement
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
//创建Statement实例
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
//RoutingStatementHandler构造方法根据Statement类型创建具体的Statement
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}创建完Statement之后,回到doQuery方法,调用prepareStatement()方法
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
//创建Statement
stmt = handler.prepare(connection, transaction.getTimeout());
//设置参数
handler.parameterize(stmt);
return stmt;
}
@Override
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {
ErrorContext.instance().sql(boundSql.getSql());
Statement statement = null;
try {
//instantiateStatement抽象方法由具体的子类实现(PreparedStatementHandler、SimpleStatementHandler、CallableStatementHandler)
statement = instantiateStatement(connection);
//设置超时时间
setStatementTimeout(statement, transactionTimeout);
//设置返回行数
setFetchSize(statement);
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("Error preparing statement. Cause: " + e, e);
}
}回到prepareStatement方法,handler.parameterize(stmt);设置参数。parameterize方法是各个StatementHandler实现类的具体实现。最后回到doQuery方法通过具体的handler的query方法执行真正的sql操作。
Mybatis的运行原理
获取SqlSessionFactory对象
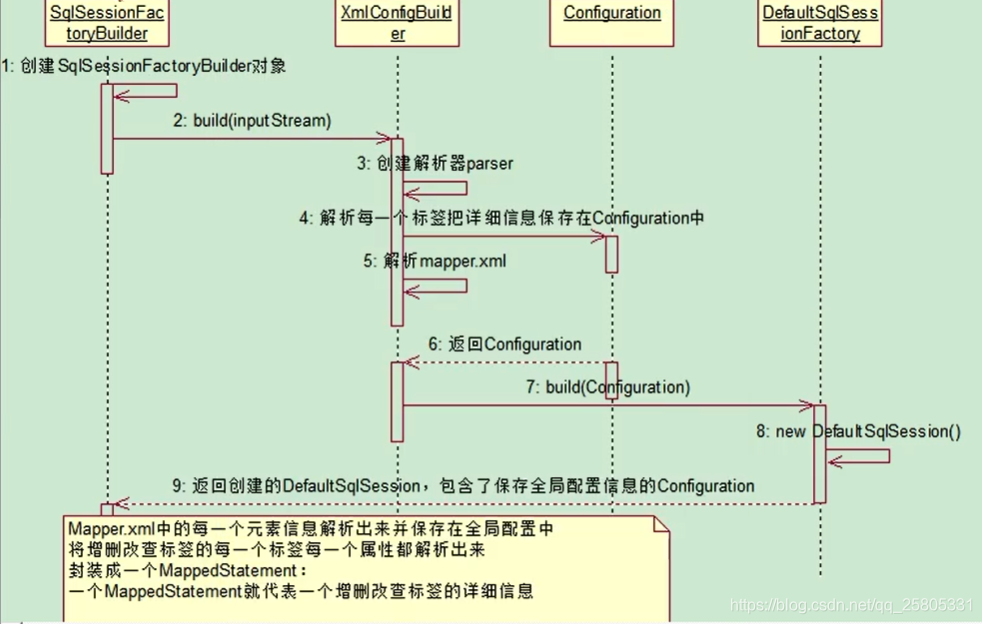
- 创建SqlSessionFactory实际上就是加载配置信息,包括Mybatis的配置文件以及加载Mapper文件。
- 将Mapper文件中的sql解析为MappedStatement(一个MappedStatement对应一个mapper文件中的sql) 以及 配置信息封装为Configuration。
- Configuration注入DefaultSqlSessionFactory返回。
OpenSession

DefaultSqlSessionFactory的openSession
@Override
public SqlSession openSession() {
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
//获取配置信息
final Environment environment = configuration.getEnvironment();
//创建事务
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
//根据执行器类型创建执行器
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}获取查询的代理对象
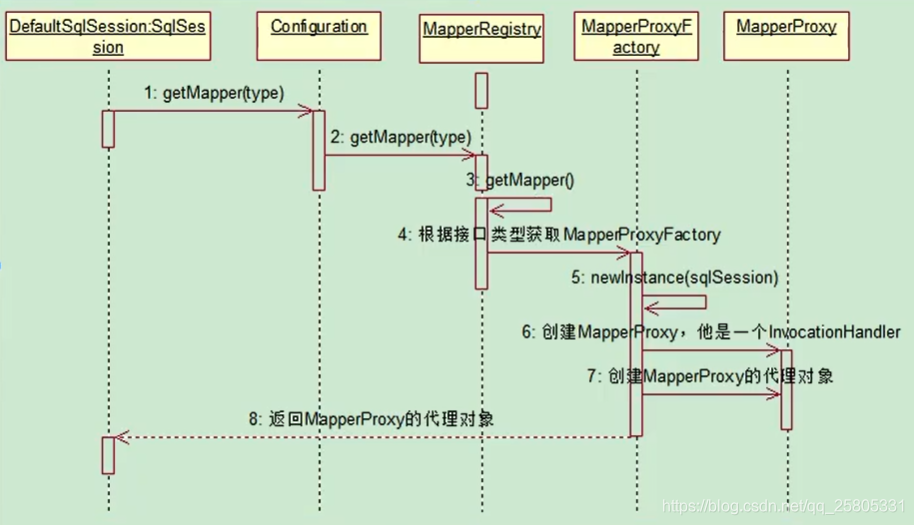
openSession执行之后返回了DefaultSqlSession,DefaultSqlSession用来获取查询的代理对象。其实DefaultSqlSession已经可以根据之前加载的配置信息以及MappeStatement进行查询了。
DefaultSqlSession的getMapper
@Override
public <T> T getMapper(Class<T> type) {
return configuration.getMapper(type, this);
}Configuration
protected final MapperRegistry mapperRegistry = new MapperRegistry(this);
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}MapperRegistry
private final Configuration config;
private final Map<Class<?>, MapperProxyFactory<?>> knownMappers = new HashMap<>();
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
//根据Mapper的代理工厂构建Mapper的代理对象
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}MapperProxyFactory
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
protected T newInstance(MapperProxy<T> mapperProxy) {
//JDK动态代理
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}最终返回的Mapper
执行sql
执行流程就是执行器Executor的原理的,中间穿插了一级缓存和二级缓存的逻辑。
- 代理对象包含了DefaultSqlSession,实际执行查询也是通过DefaultSqlSession
- DefaultSqlSession的创建中也包含了具体的执行器,通过执行器的doQuery进行实际查询
- 具体的Executor创建其对应的StatementHandler,进行参数的设置,预编译(ParameterHandler),执行查询(StatementHandler),返回结果处理(ResultSetHandler)