前言
想必大家编写代码时肯定和我一样,也遇到过汉字乱码的问题。特别是,有时候和上下游对接接口,不能统一编码格式的话,一堆乱码问题,让人头皮发麻。

那么为什么会有这么多的乱码问题?
什么是字符编码?什么是字符集?他们之间有什么区别和联系?
什么是 Unicode ? Unicode 和我们常说的 UTF-8 又有什么关系?
字符编码和解码
要想搞清楚上面的问题,首先我们要知道,在计算机中,不管是一段文字、一张图片还是一段视频,最终都是以二进制的方式来存储。也就是最终都会转化为 0001 1011 0010 0110 这样的格式。
换句话说,计算机只认识 0 和 1 这样的数字,并不能直接存储字符。所以我们需要告诉它什么样的字符对应的是什么数字。
例如,我们的业务中有记录客户端的客户行为日志,然后导出文件来分析,字段间会以 ESC 来分隔。
我在编写代码的时候,就需要定义一下这个ESC 字符应该对应什么数字,这样计算机才能识别并存储。
比如我把它定为 0001 1011,这样计算机就把 ESC 这个字符存了下来。等我下次需要查看的时候,根据对应关系把它解出来就可以了。
上边的两个过程就对应字符的编码和解码过程。
字符编码就是把字符按一定的规则,转换成数字。字符解码是编码的逆过程,即把数字按规则转换成字符。
这样看来,貌似没有什么问题。
但是,这是我自己定义的编码规则,我同桌阿霄就不乐意了。他非要认为 ESC 应该定义为 1101 1000,好家伙正好和我定义的二进制数字顺序相反。
那结果肯定不用说了,我把 0001 1011 这串数字给他之后,按照他的编码规则来解,肯定是 &$#!这样的东西。
所以,乱码问题说到底,就是编码和解码的规则对应不上导致的。
ASCII 码
为了避免我和阿霄因为编码问题打起来,美国国家标准学会(AMERICAN NATIONAL STANDARDS INSTITUTE) ANSI 组织发话了。
停、停、停。不就是个编码问题吗,这种小事犯不着动手,我定义一个统一的规则,大家都按照我的规则来编码和解码不就好了嘛。
于是,ASCII 码出现了,它定义了一个常用字符集,用来表示字符和数字的对应关系,如下表。
ASCII 码全称:美国信息交换标准代码 (American Standard Code for Information Interchange)
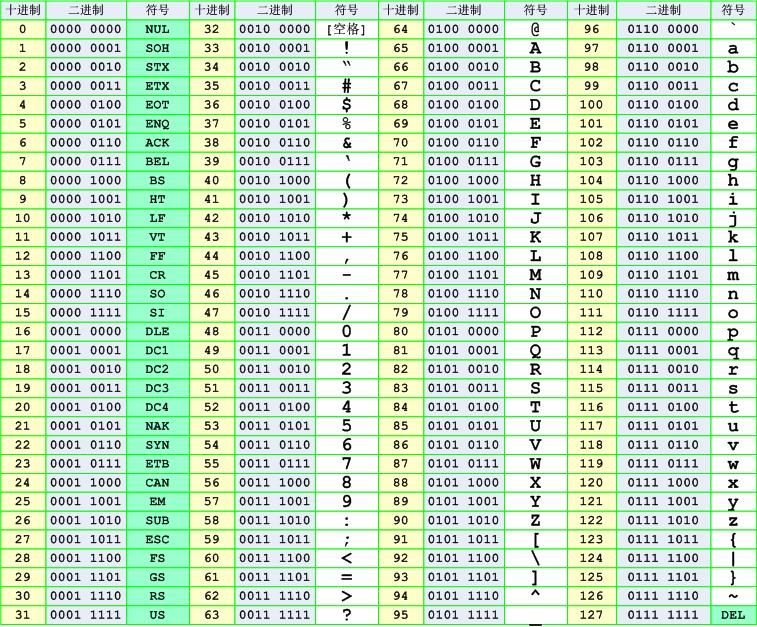
我一查表,ESC 字符不就对应 27 吗,对应的二进制就是 0001 1011 。我去,没想到我定义的规则竟和 ANSI 不谋而合。
同桌阿霄把抡在空中的拳头收了起来,默默地回去敲代码了。
ASCII 码扩展码
在使用英语的国家,ASCII 码就足够用了。但是,在其他欧洲发达国家比如法国,使用的语言是法语,有类似于这样的 á 符号,ASCII 码就不能表示了。那怎么办呢?
我们看上表就会发现,ASCII 码表的表示范围是十进制 0~127,也就是二进制 0000 0000 到 0111 1111 。其实只是用了后边的 7 位,第一位都是 0 。
而计算机二进制中一个字节是 8 个位,现在只用了 7 位。不行啊太浪费了,要充分利用第一个高位,扩展一下,这样多了一位,能表示的字符范围就多了一倍。(2的8次方=256)
这样一些欧洲其他国家,也能在计算机中表示自己的文字了。
后来,随着计算机的普及,中国的用户也多了起来。却发现,一个字节只能表示 256 个字符,远远不能满足我们的要求。
于是,就出现了 GB2312 编码,它使用了两个字节来表示一个汉字。但是,并没有把所有的位都用完,前面一个字节范围 0xA1 ~ 0xF7 (即 10110001 ~ 11110111),后面一个字节范围 0xA1 ~ 0xFE (即 10110001 ~ 11111110) 。 这样