Centos7搭建Kafka集群
一、集群规划
| 192.168.239.140 | 192.168.239.141 | 192.168.239.142 |
|---|---|---|
| zookeeper | zookeeper | zookeeper |
| kafka | kafka | kafka |
二、环境准备
请自行安装JDK与Zookeeper集群
Zookeeper集群安装参考
三、安装kafka集群
1、下载kafka安装包
kafka_2.13-3.6.1.tgz
2、解压
tar -zxvf kafka_2.13-3.6.1.tgz
3、配置环境变量
vim /etc/profile.d/my_env.sh
在“my_env.sh”文件中添加如下内容:
#KAFKA_HOME(路径按需修改)
export KAFKA_HOME=/wz_program/kafka/kafka_2.13-3.6.1
export PATH=$PATH:$KAFKA_HOME/bin
文件编辑完后执行如下命令:
source /etc/profile
4、编辑配置文件
进入“config”目录下,修改server.properties文件
vim server.properties
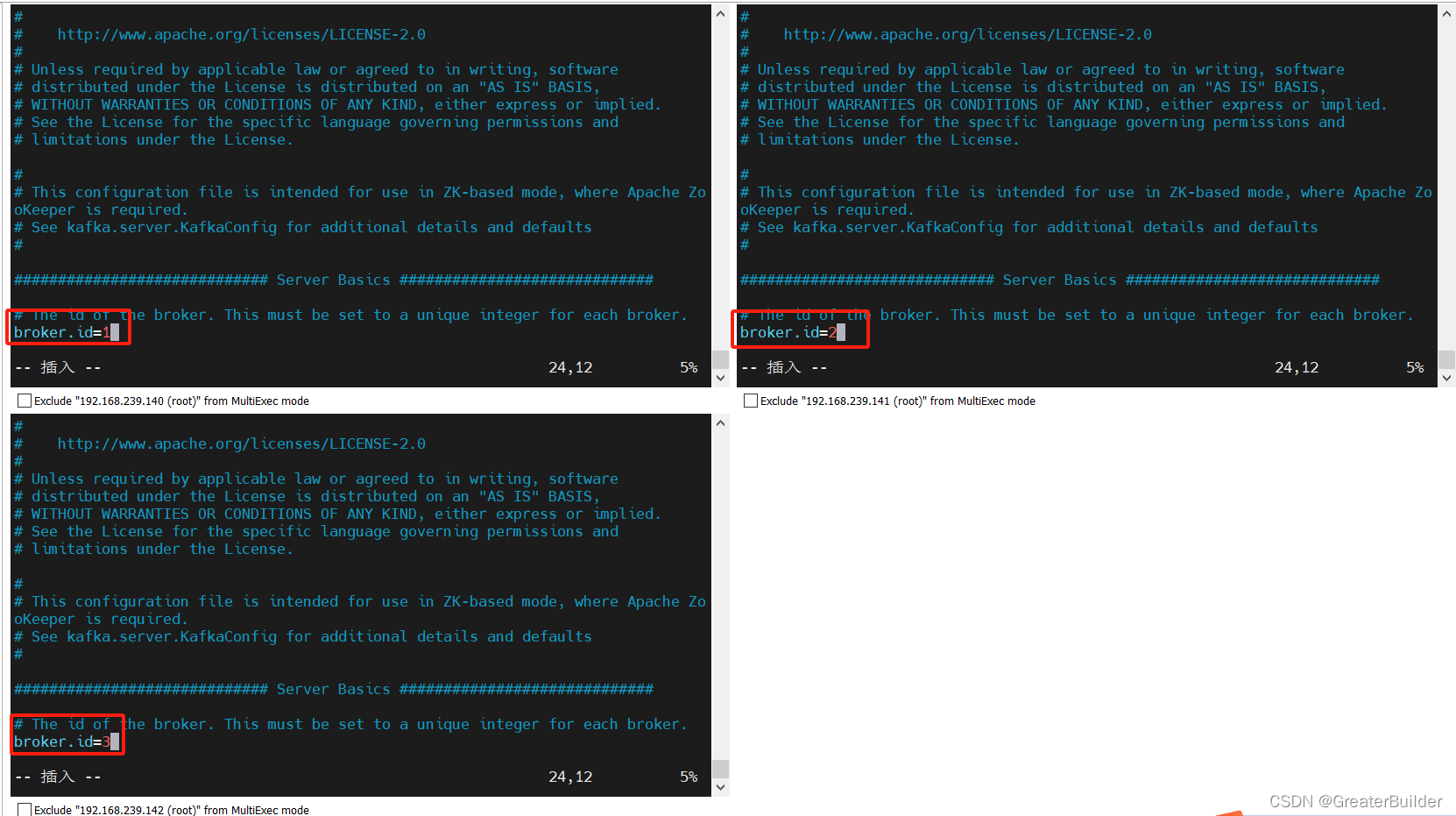
①修改broker.id
特别注意:broker.id在整个集群中全局唯一,不能重复,只能是数字
broker.id
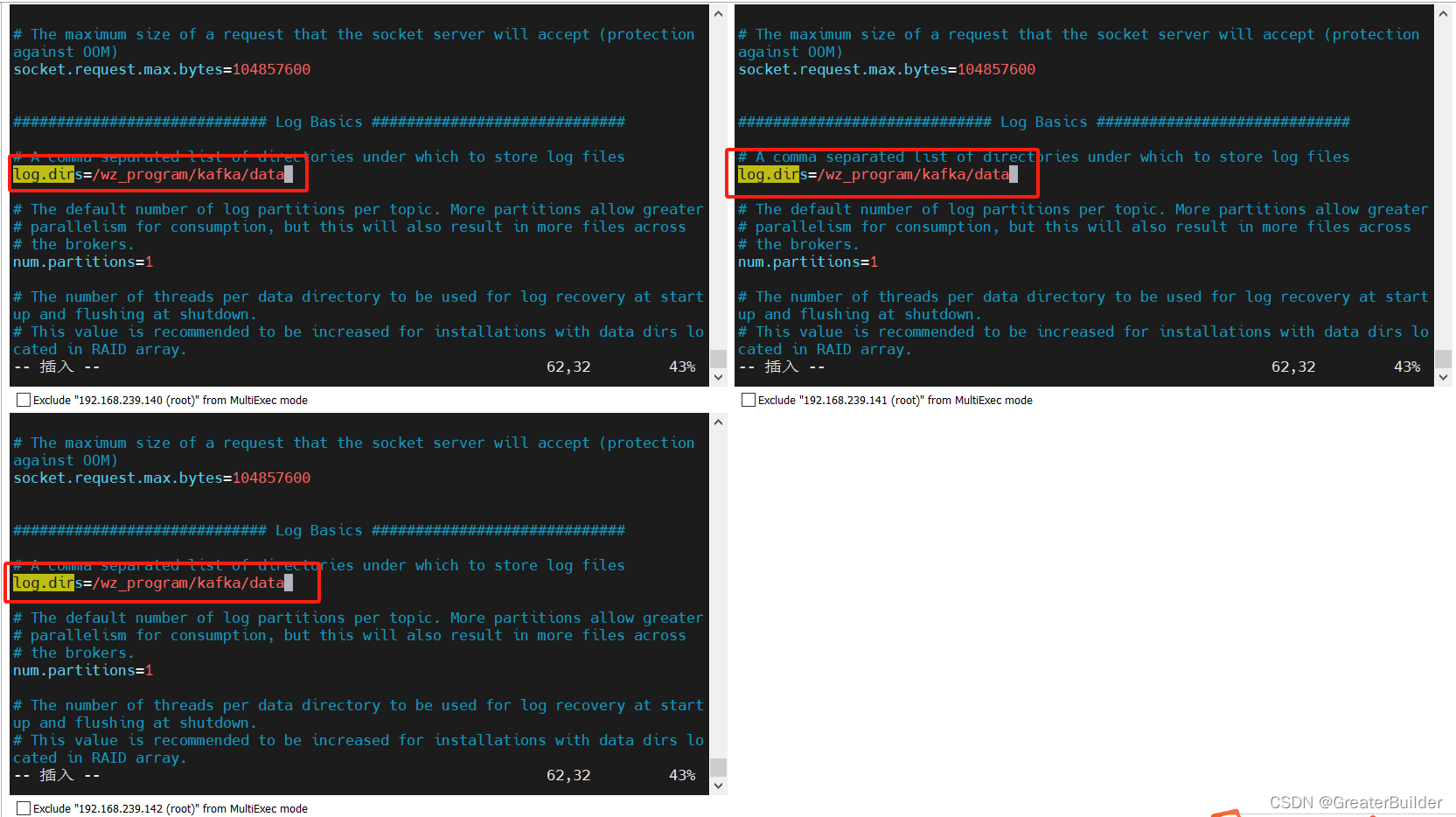
②配置kafka运行日志路径
kafka运行日志(数据)存放的路径,路径不需要手动创建,kafka会自动创建。可以配置多个磁盘路径,路径与路径之间可以用","分隔。
log.dirs
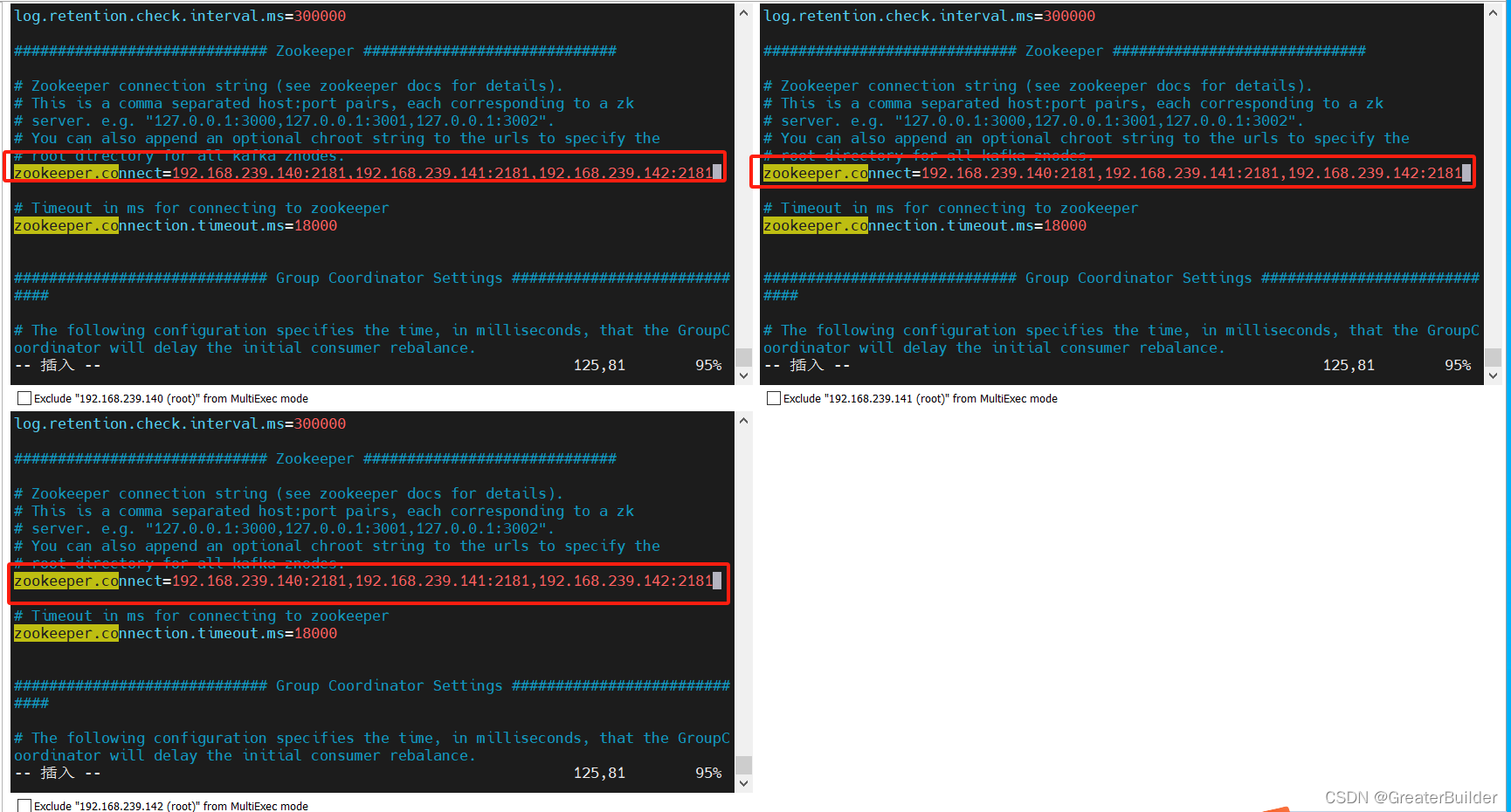
③配置Zookeeper集群地址
zookeeper.connect=
5、启动集群
启动kafka集群前需要保证zookeeper集群已启动!!!
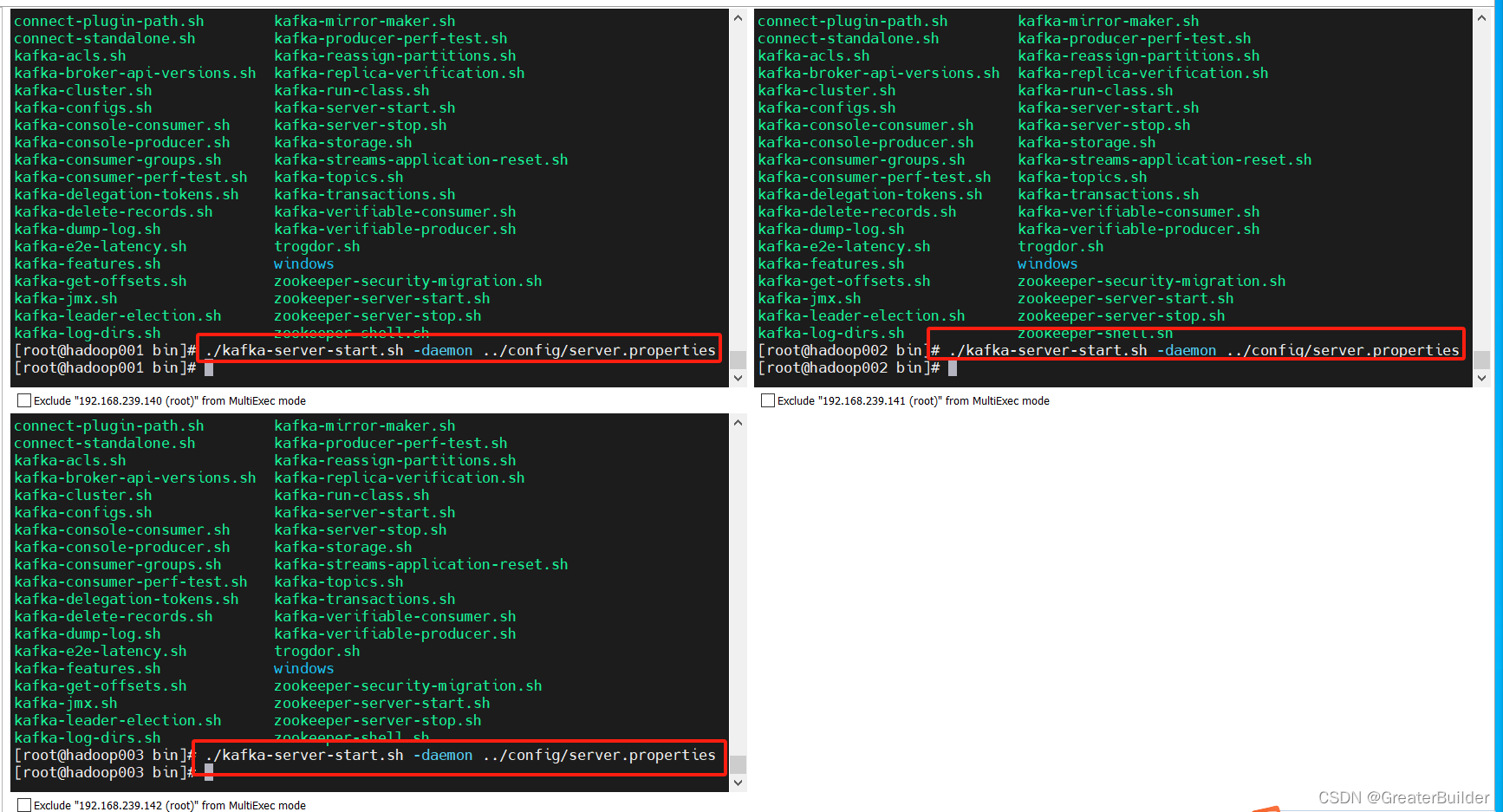
进入kafka的bin目录下执行如下命令:
./kafka-server-start.sh -daemon ../config/server.properties
关闭集群可使用如下命令:
./kafka-server-stop.sh
特别注意:停止Kafka集群时,一定要等Kafka所有节点进程全部停止后再停止Zookeeper集群。因为Zookeeper集群当中记录着Kafka集群相关信息,Zookeeper集群一旦先停止,Kafka集群就没有办法再获取停止进程的信息,只能手动杀死Kafka进程了。
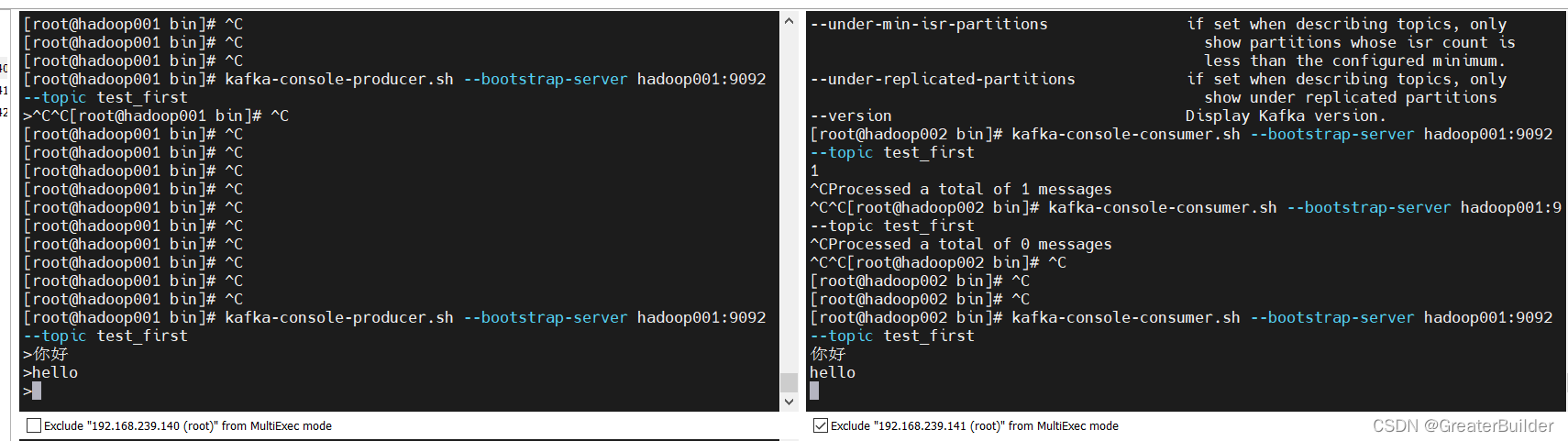
6、测试kafka
①、创建topic
kafka-topics.sh --bootstrap-server hadoop001:9092 --create --partitions 1 --replication-factor 3 --topic test_first

②、查看当前服务器中的所有topic
kafka-topics.sh --bootstrap-server hadoop001:9092 --list

③、生产者与消费者
生产者:
kafka-console-producer.sh --bootstrap-server hadoop001:9092 --topic test_first
消费者:
kafka-console-consumer.sh --bootstrap-server hadoop001:9092 --topic test_first