独立模式(Standalone)是部署 Flink 最基本也是最简单的方式: 所需要的所有 Flink 组件, 都只是操作系统上运行的一个 JVM 进程。
独立模式是独立运行的, 不依赖任何外部的资源管理平台; 当然独立也是有代价的: 如果资源不足, 或者出现故障, 没有自动扩展或重分配资源的保证, 必须手动处理。所以独立模式 一般只用在开发测试或作业非常少的场景下。
另外, 我们也可以将独立模式的集群放在容器中运行。 Flink 提供了独立模式的容器化部署方式,可以在 Docker 或者 Kubernetes 上进行部署。
1.会话模式部署
Flink 是一个分布式的流处理框架,所以实际应用一般都需要搭建集群环境。我们在进行 Flink 安装部署的学习时, 需要准备 3 台 Linux 机器。具体要求如下:
- 系统环境为 CentOS 7.5 版本。
- 安装 Java 8。
- 安装 Hadoop 集群, Hadoop 建议选择 Hadoop 2.7.5 以上版本。
- 配置集群节点服务器间时间同步以及免密登录,关闭防火墙。
具体安装步骤:
Flink 是典型的 Master-Slave 架构的分布式数据处理框架, 其中 Master 角色对应着 JobManager,Slave 角色则对应 TaskManager。我们对三台节点服务器的角色分配如下所示。
| 节点服务器 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
| 角色 | JobManager | TaskManager | TaskManager |
-
下载安装包
进入 Flink 官网, 下载 1.13.0 版本安装包 flink- 1.13.0-bin-scala_2.12.tgz,注意此处选用对应 scala 版本为 scala 2.12 的安装包。 -
解压
在hadoop102节点服务器上创建安装目录/opt/module,将 flink 安装包放在该目录下,并执行解压命令, 解压至当前目录。tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/ -
修改集群配置
(1)进入 conf 目录下, 修改 flink-conf.yaml 文件,修改 jobmanager.rpc.address 参数为 hadoop102,如下所示:$ cd conf/ $ vim flink-conf.yaml # JobManager 节点地址 . jobmanager.rpc.address: hadoop102这就指定了 hadoop102 节点服务器为 JobManager 节点。
(2)修改 workers 文件, 将另外两台节点服务器添加为本 Flink 集群的 TaskManager 节点, 具体修改如下:$ vim workers hadoop103 hadoop104这样就指定了 hadoop103 和 hadoop104 为 TaskManager 节点。
(3)另外, 在 flink-conf.yaml 文件中还可以对集群中的 JobManager 和 TaskManager 组件 进行优化配置, 主要配置项如下:jobmanager.memory.process.size:对 JobManager 进程可使用到的全部内存进行配置, 包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。taskmanager.memory.process.size:对 TaskManager 进程可使用到的全部内存进行配置, 包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。taskmanager.numberOfTaskSlots:对每个 TaskManager 能够分配的 Slot 数量进行配置, 默认为 1,可根据 TaskManager 所在的机器能够提供给 Flink 的 CPU 数量决定。所谓 Slot 就是TaskManager 中具体运行一个任务所分配的计算资源。parallelism.default:Flink 任务执行的默认并行度, 优先级低于代码中进行的并行度配 置和任务提交时使用参数指定的并行度数量。
-
分发安装目录
配置修改完毕后, 将 Flink 安装目录发给另外两个节点服务器。scp -r ./flink-1.13.0 root@hadoop103:/opt/module scp -r ./flink-1.13.0 root@hadoop104:/opt/module -
启动集群
(1)在 hadoop102 节点服务器上执行 start-cluster.sh 启动 Flink 集群:bin/start-cluster.sh Starting cluster. Starting standalonesession daemon on host hadoop102. Starting taskexecutor daemon on host hadoop103. Starting taskexecutor daemon on host hadoop104.(2)查看进程情况:
[root@hadoop102 flink-1.13.0]$ jps 13859 Jps 13782 StandaloneSessionClusterEntrypoint [root@hadoop103 flink-1.13.0]$ jps 12215 Jps 12124 TaskManagerRunner [root@hadoop104 flink-1.13.0]$ jps 11602 TaskManagerRunner 11694 Jps -
访问 Web UI
启动成功后, 同样可以访问http://hadoop102:8081对 flink 集群和任务进行监控管理, 如图所示。

这里可以明显看到, 当前集群的 TaskManager 数量为 2;由于默认每个 TaskManager 的 Slot 数量为 1,所以总 Slot 数和可用 Slot 数都为 2。
2.单作业模式部署
Flink 本身无法直接以单作业方式启动集群, 一般需要借助一些资源管理平台。所以 Flink 的独立(Standalone)集群并不支持单作业模式部署。
3.应用模式部署
应用模式下不会提前创建集群, 所以不能调用 start-cluster.sh 脚本。我们可以使用同样在 bin 目录下的 standalone-job.sh 来创建一个 JobManager。
具体步骤如下:
(1)进入到 Flink 的安装路径下, 将应用程序的jar 包放到lib/目录下。
cp ./FlinkTutorial-1.0-SNAPSHOT.jar lib/
(2)执行以下命令, 启动 JobManager。
./bin/standalone-job.sh start --job-classname com.cw.wc.StreamWordCount
这里我们直接指定作业入口类, 脚本会到 lib 目录扫描所有的jar 包。
(3)同样是使用 bin 目录下的脚本, 启动 TaskManager。
./bin/taskmanager.sh start
(4)如果希望停掉集群,同样可以使用脚本,命令如下。
./bin/standalone-job.sh stop
./bin/taskmanager.sh stop
4.高可用(High Availability)
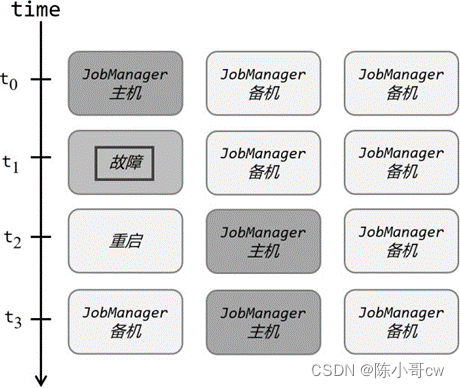
分布式除了提供高吞吐,另一大好处就是有更好的容错性。对于 Flink 而言,因为一般会有多个 TaskManager,即使运行时出现故障,也不需要将全部节点重启,只要尝试重启故障节点就可以了。但是我们发现,针对一个作业而言,管理它的 JobManager 却只有一个,这同样有可能出现单点故障。为了实现更好的可用性,我们需要 JobManager 做一些主备冗余,这就是所谓的高可用(High Availability,简称 HA)。
我们可以通过配置,让集群在任何时候都有一个主 JobManager 和多个备用 JobManagers, 如图所示,这样主节点故障时就由备用节点来接管集群,接管后作业就可以继续正常运行。主备 JobManager 实例之间没有明显的区别,每个 JobManager 都可以充当主节点或者备节点。
具体配置如下:
(1) 进入 Flink 的安装路径下的 conf 目录下,修改配置文件: flink-conf.yaml,增加如下配置。
high-availability: zookeeper
high-availability.storageDir: hdfs://hadoop102:9820/flink/standalone/ha
high-availability.zookeeper.quorum: hadoop102:2181,hadoop103:2181,hadoop104:2181
high-availability.zookeeper.path.root: /flink-standalone
high-availability.cluster-id: /cluster
(2)修改配置文件: masters,配置备用 JobManager 列表
hadoop102:8081
hadoop103:8081
(3) 分发修改后的配置文件到其他节点服务器。
(4) 在/etc/profile.d/my_env.sh 中配置环境变量
export HADOOP_CLASSPATH=`hadoop classpath`
注意:
- 需要提前保证HAOOP_HOME 环境变量配置成功
- 分发到其他节点
具体部署方法如下:
-
首先启动HDFS 集群和 Zookeeper 集群。
-
执行以下命令,启动 standalone HA 集群。
bin/start-cluster.sh -
可以分别访问两个备用 JobManager 的 Web UI 页面
http://hadoop102:8081 http://hadoop103:8081 -
在 zkCli.sh 中查看谁是 leader。
[zk:localhost:2181(CONNECTED) 1] get /flink-standalone/cluster/leader/rest_server_lock杀死 hadoop102 上的 Jobmanager, 再看 leader。
注意: 不管是不是leader,从 WEB UI 上是看不到区别的, 都可以提交应用。