一、分布式计算框架MapReduce
1、MapReduce是什么
面向大数据并行处理的计算模型、框架和平台。
2、特点
分布可靠,对数据集的操作分发给集群的多个节点实现可靠性,每个节点周期性返回它完成的任务和最新的状态
封装了实现细节,基于框架API编程,面向讹误展开分布式编码
提供跨语言编程的能力
3、企业应用
各大运营商、中大型互联网公司、金融银行保险类公司等
二、MapReduce运行流程
1、MapReduce的主要功能
数据划分和计算任务调度
系统优化
出错检测和恢复
2、MapReduce的运行流程
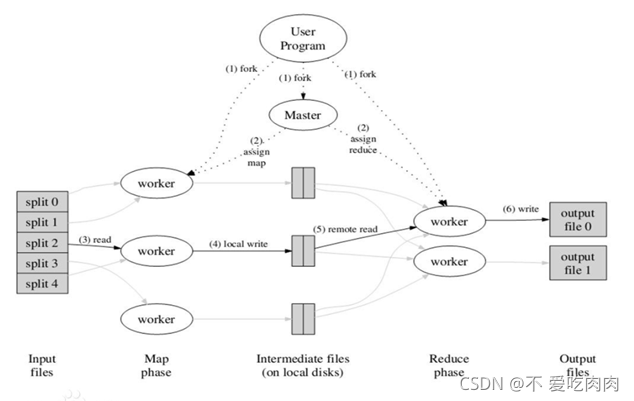
2.1运行流程
步骤:
1)正式提交作业代码,对输入的数据源进行切片
2)master调度worker执行map任务
3)worker读取输入源切片
4)worker执行map任务,将任务输出保存在本地
5)master调度worker执行reduce任务,reduce worker读取map任务的输出文件
6)执行reduce任务,将任务输出保存到HDFS
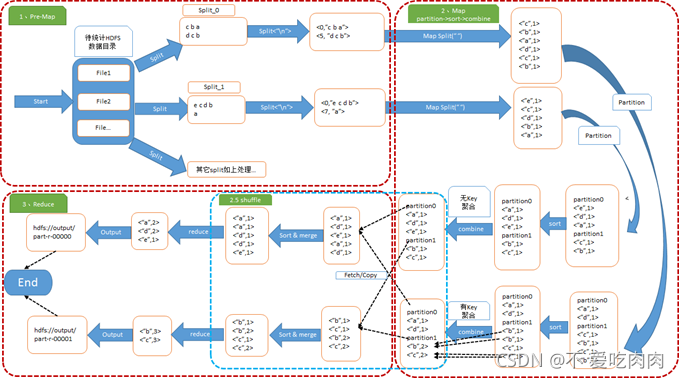
2.2运行流程详解
以WordCount为例
给定任意的HDFS的输入目录,其内部数据为“f a c d e……”等用空格字符分隔的字符串,通过使用MapReduce计算框架来统计以空格分隔的每个单词出现的频率,输出结果如<a,10>,<b,20>,<c,2>形式的结果到HDFS目录中。
WordCount运行图解
三、代码实现
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//启动mr的driver类
public class WordCountDriver {
//map类,实现map函数
public static class MyTokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
//暂存每个传过来的词频计数,均为1,省掉重复申请空间
private final static IntWritable one = new IntWritable(1);
//暂存每个传过来的词的值,省掉重复申请空间
private Text word = new Text();
//核心map方法的具体实现,逐个<key,value>对去处理
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
//用每行的字符串值初始化StringTokenizer
StringTokenizer itr = new StringTokenizer(value.toString());
//循环取得每个空白符分隔出来的每个元素
while (itr.hasMoreTokens()) {
//将取得出的每个元素放到word Text对象中
word.set(itr.nextToken());
//通过context对象,将map的输出逐个输出
context.write(word, one);
}
}
}
//reduce类,实现reduce函数
public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
//核心reduce方法的具体实现,逐个<key,List(v1,v2)>去处理
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
//暂存每个key组中计算总和
int sum = 0;
//加强型for,依次获取迭代器中的每个元素值,即为一个一个的词频数值
for (IntWritable val : values) {
//将key组中的每个词频数值sum到一起
sum += val.get();
}
//将该key组sum完成的值放到result IntWritable中,使可以序列化输出
result.set(sum);
//将计算结果逐条输出
context.write(key, result);
}
}
//启动mr的driver方法
public static void main(String[] args) throws Exception {
//得到集群配置参数
Configuration conf = new Configuration();
//设置到本次的job实例中
Job job = Job.getInstance(conf, "WordCount");
//通过指定相关字节码对象,找到所属的主jar包
job.setJarByClass(WordCountDriver.class);
//指定map类
job.setMapperClass(MyTokenizerMapper.class);
//指定combiner类,要么不指定,如果指定,一般与reducer类相同
job.setCombinerClass(IntSumReducer.class);
//指定reducer类
job.setReducerClass(IntSumReducer.class);
//指定job输出的key和value的类型,如果map和reduce输出类型不完全相同,需要重新设置map的output的key和value的class类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定输入数据的路径
FileInputFormat.addInputPath(job, new Path(args[0]));
//指定输出路径,并要求该输出路径一定是不存在的
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//指定job执行模式,等待任务执行完成后,提交任务的客户端才会退出!
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}