定义
Robots协议也称作爬虫协议、机器人协议,全名为网络爬虫排除标准,用来告诉爬虫和搜索引擎哪些页面可以爬取、哪些不可以。它通常是一个叫做robots.txt的文本文件,一般放在网站的根目录下。
robots.txt文件的样例
- 对有所爬虫均生效,只能爬取public目录
User-agent:*
Disallow:/
Allow:/public/
- 禁止所有爬虫访问所有目录
User-agent:*
Disallow:/
- 允许所有爬虫访问所有目录
User-agent:*
Disallow:
- 禁止所有爬虫访问网站某些目录也可以写做
User-agent:*
Disallow:/private/
Disallow:/tmp/
- 只允许某一个爬虫访问所有目录
User-agent:WebCrawler
Disallow:
User-agent:*
Disallow:/
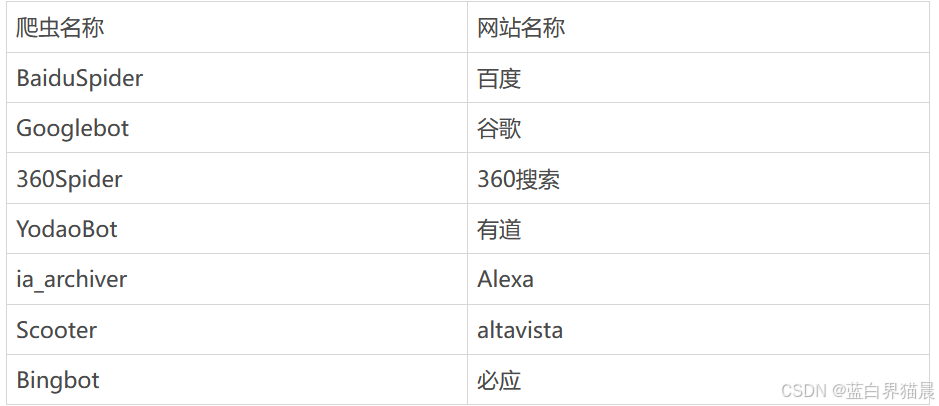
一些常见的爬虫名称
robotparser使用
该模块提供了一个类:RobotFileParser,它可以根据某网站的robots.txt文件判断一个爬虫是否有权限爬取这个网页。
RobotFileParser类的常用方法
- set_url:用来设置robots.txt文件的链接。
- read:读取robots.txt文件进行分析。
- parse:用来解析robots.txt文件
- can_fetch:该方法有两个参数,第一个是User-Agent,第二个是要抓取的URL。返回结果是True或者False,表示User-Agent指示的搜索引擎是否可以抓取这个URL。
- mtime:返回上次抓取和分析robots.txt文件的时间。
- modified:它对长时间分析和抓取的搜索爬虫很有帮助,可以将当前时间设置为上次抓取和分析robots.txt文件的时间
代码示例
from urllib.robotparser import RobotFileParser
rp = RobotFileParser()
rp.set_url("http://www.baidu.com/robots.txt")
rp.read()
print(rp.can_fetch("Baiduspider", "http://www.baidu.com"))
print(rp.can_fetch("Baiduspider", "http://www.baidu.com/homepage/"))
print(rp.can_fetch("Googlebot", "http://www.baidu.com/homepage/"))

- 这里能看到,Googlebot是被严格禁止了的,所以为false

注
以上,便是robots协议的学习笔记整理,来源于当前正在看的一本书–《Python3网络爬虫开发实战》。后面会持续学习并整理的。
感谢阅读~