什么是响应式编程?
响应式编程是就是对于数据流和传播改变的一种声明式的编程规范。响应式编程是基于异步和事件驱动的非阻塞程序。
在命令式编程的模式下,定义了 a=b+c,那么 a 的值再执行了这条语句后就被分配了 b+c 的结果,不管后续 b、c 怎么发生变化都不会影响到 a 的值。但是在响应式编程中,当b、c发生变化后,a的值会自动进行更新,而不需要重新执行赋值语句。
基于事件驱动(事件模式或者说订阅者模式)。
响应式编程的优点?
- 非阻塞式
使用非阻塞的方式可以利用较小的线程或硬件资源来处理并发进而提高其可伸缩性 - 函数式编程
函数式编程就是java8重要的特点之一
Reactor
Reactor 是一个基于 JVM 之上的异步应用基础库。为 Java 、Groovy 和其他 JVM 语言提供了构建基于事件和数据驱动应用的抽象库。Reactor 性能相当高。
Flux和Mono
Flux 表示的是包含 0 到 N 个元素的异步序列。序列中包含了3种类型的消息通知:正常的包含元素的消息、序列结束的消息、序列出错的消息。当消息通知产生时,订阅者中对应的方法会被调用onNext()、onComplete()、onError()会被调用。
Mono 表示的是包含 0 或者 1 个元素的异步序列。Flux 和 Mono 之间可以进行转换。对一个 Flux 序列进行计数操作,得到的结果是一个 Mono对象。把两个 Mono 序列合并在一起,得到的是一个 Flux 对象。
API
Flux 类中的静态方法。
- just():可以指定序列中包含的全部元素。创建出来的 Flux 序列在发布这些元素之后会自动结束。
- range(int start, int count):创建包含从 start 起始的 count 个数量的 Integer 对象的序列。
Flux.just("Hello", "World").subscribe(System.out::println);
Flux.range(1, 10).subscribe(System.out::println);
Mono 的创建方式与之前介绍的 Flux 比较相似 。
操作符
1.buffer 和 bufferTimeout
作用是把当前流中的元素收集到集合中,并把集合对象作为流中的新元素。
Flux.range(1,100).buffer(20).subscribe(System.out::println);
结果:
2.filter
作用对流中包含的元素进行过滤,只留下满足 Predicate 指定条件的元素。

Flux.range(1, 10).filter(i -> i % 2 == 0).subscribe(System.out::println);
结果:
3.take
作用用来从当前流中提取元素。

Flux.range(1, 1000).take(5).subscribe(System.out::println);//从中取出5个
结果:
4.reduce 和 reduceWith
作用对流中包含的所有元素进行累积操作,得到一个包含计算结果的 Mono 序列。

Flux.range(1, 100).reduce((x, y) -> x + y).subscribe(System.out::println);
结果:
5.flatMap 和 flatMapSequential
作用把流中的每个元素转换成一个流,再把所有流中的元素进行合并。

Flux.just(2, 4)
.flatMap(x -> Flux.interval(Duration.ofMillis(1000)).take(x))
.toStream()
.forEach(System.out::println);
//流中的元素被转换成每隔 1000毫秒产生的数量不同的流,再进行合并。由于第一个流中包含的元素数量较少,所以在结果流中一开始是两个流的元素交织在一起,然后就只有第二个流中的元素。
结果:

消息处理
当需要处理 Flux 或 Mono 中的消息时,可以通过 subscribe 方法来添加相应的订阅逻辑。在调用 subscribe 方法时可以指定需要处理的消息类型。可以只处理其中包含的正常消息,也可以同时处理错误消息和完成消息。
1.使用subscribe处理正常消息和错误消息
Flux.just(1, 2)
.concatWith(Mono.error(new IllegalStateException()))
.subscribe(System.out::println, System.err::println);
结果:

2.出现错误时返回默认值
Flux.just(1, 2)
.concatWith(Mono.error(new IllegalStateException()))
.onErrorReturn(0)
.subscribe(System.out::println);
结果:

- 错误处理
onError、onErrorReturn、onErrorResume
doFinally
调度器
- 单一的可复用的线程,通过 Schedulers.single()方法来创建。
- 使用弹性的线程池,通过 Schedulers.elastic()方法来创建。线程池中的线程是可以复用的。当所需要时,新的线程会被创建。如果一个线程闲置太长时间,则会被销毁。该调度器适用于 I/O 操作相关的流的处理。
- 使用对并行操作优化的线程池,通过 Schedulers.parallel()方法来创建。其中的线程数量取决于 CPU 的核的数量。该调度器适用于计算密集型的流的处理。
- 当前线程,通过 Schedulers.immediate()方法来创建
1.没指定线程池
Flux.range(1, 6)
.doOnRequest(n -> log.info("Request {} number", n)) // 注意顺序造成的区别
.doOnComplete(() -> log.info("Publisher COMPLETE 1"))
.map(i -> {
log.info("Publish {}, {}", Thread.currentThread(), i);
return 10 / (i - 3);
})
.doOnComplete(() -> log.info("Publisher COMPLETE 2"))
.subscribe(i -> log.info("Subscribe {}: {}", Thread.currentThread(), i),
e -> log.error("error {}", e.toString()),
() -> log.info("Subscriber COMPLETE")//,
);
Thread.sleep(2000);
结果:
可以看到,由于报错,导致程序没有执行完,doOnComplete没有打印。
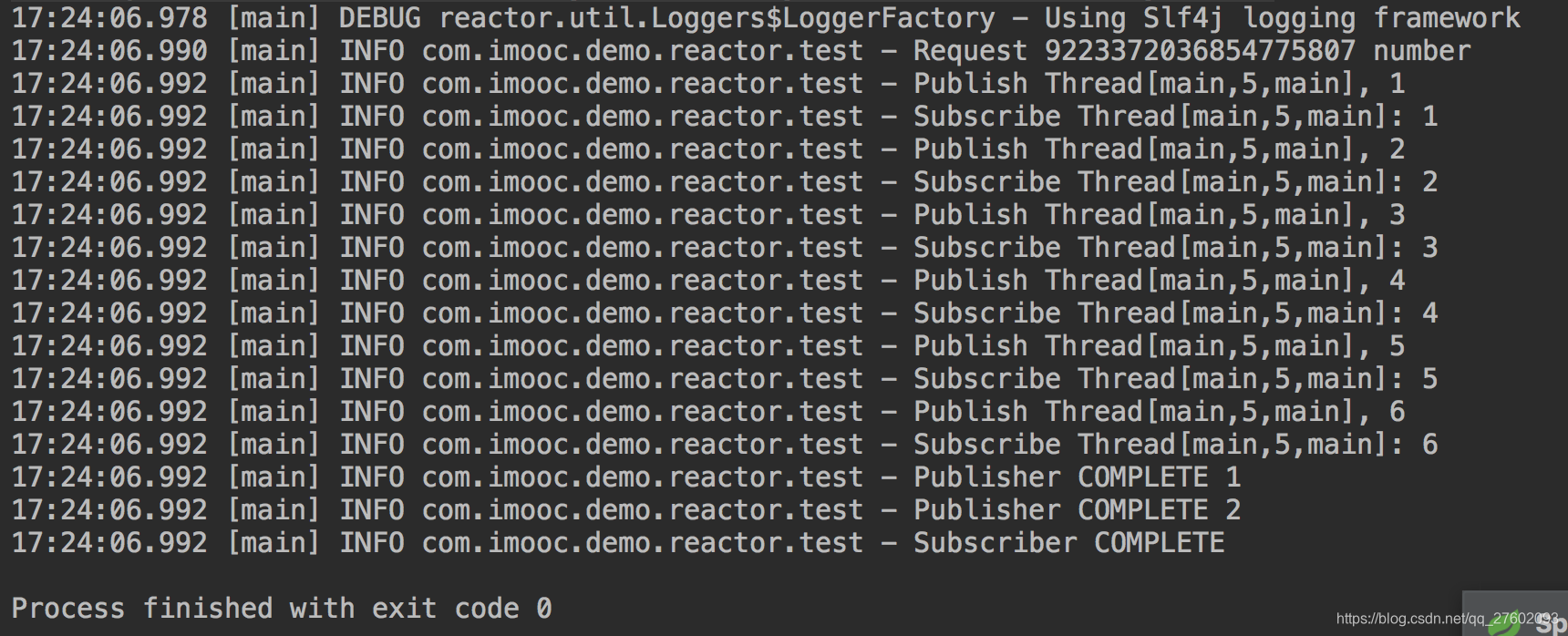
2.没指定线程池,正常情况

Flux.range(1, 6)
.doOnRequest(n -> log.info("Request {} number", n)) // 注意顺序造成的区别
.doOnComplete(() -> log.info("Publisher COMPLETE 1"))
.map(i -> {
log.info("Publish {}, {}", Thread.currentThread(), i);
return i;
})
.doOnComplete(() -> log.info("Publisher COMPLETE 2"))
.subscribe(i -> log.info("Subscribe {}: {}", Thread.currentThread(), i),
e -> log.error("error {}", e.toString()),
() -> log.info("Subscriber COMPLETE")//,
);
Thread.sleep(2000);
结果:
3.指定publish,subscribe的线程池
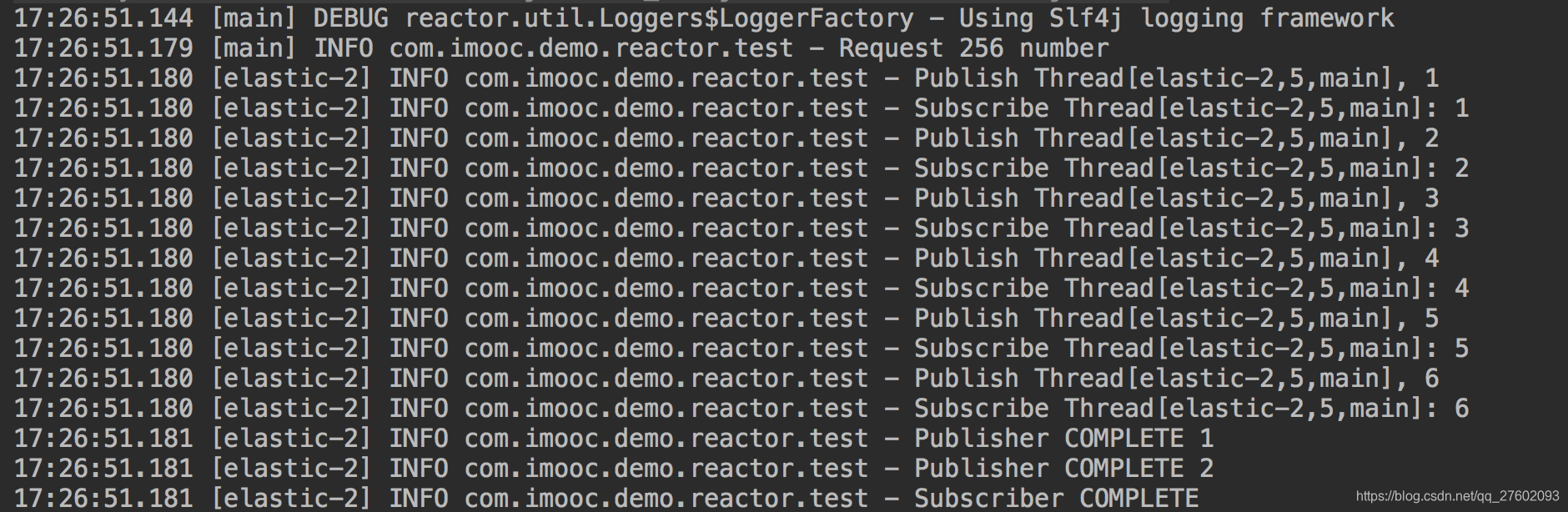
Flux.range(1, 6)
.doOnRequest(n -> log.info("Request {} number", n)) // 注意顺序造成的区别
.publishOn(Schedulers.elastic())
.doOnComplete(() -> log.info("Publisher COMPLETE 1"))
.map(i -> {
log.info("Publish {}, {}", Thread.currentThread(), i);
return i;
})
.doOnComplete(() -> log.info("Publisher COMPLETE 2"))
.subscribe(i -> log.info("Subscribe {}: {}", Thread.currentThread(), i),
e -> log.error("error {}", e.toString()),
() -> log.info("Subscriber COMPLETE")//,
);
Thread.sleep(2000);
结果:
可以看到publish和subscribe都是在elastic线程上面的。据观察,publishOn指定的线程池之后的代码都是在该线程池里的线程中执行,无论是生成过程的操作还是最后消费的操作。