HunyuanDiT
论文
Hunyuan-DiT : A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
模型结构
模型基于transformer decoder结构,在DiT基础上重新设计了Time Embedding以及positional Embedding的添加方式,Text Prompt通过两个text encoder进行编码,其余与DiT一致。
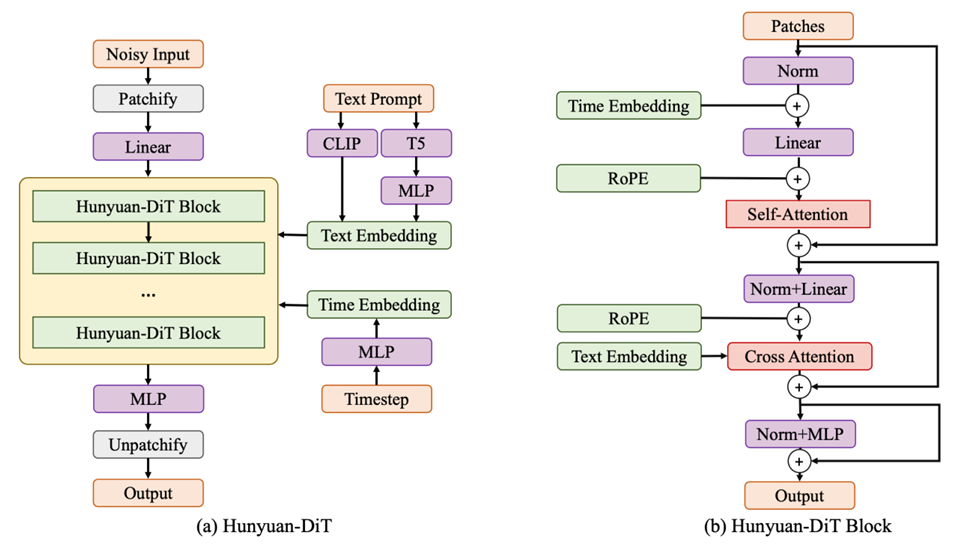
算法原理
使用self-attention捕获图像内部的结构信息,使用cross attention对齐文本与图像。
环境配置
Docker(方法一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-centos7.6-dtk24.04-py310
docker run --shm-size 10g --network=host --name=hunyuan --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it <your IMAGE ID> bash
pip install -r requirements.txt
pip install timm --no-deps
pip install flash_attn-2.0.4+das1.0+82379d7.abi0.dtk2404.torch2.1-cp310-cp310-manylinux2014_x86_64.whl (开发者社区)
pip install bitsandbytes-0.42.0-py3-none-any.whl (whl文件夹中)
Dockerfile(方法二)
docker build -t <IMAGE_NAME>:<TAG> .
docker run --shm-size 10g --network=host --name=hunyuan --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it <your IMAGE ID> bash
pip install -r requirements.txt
pip install timm --no-deps
pip install flash_attn-2.0.4+das1.0+82379d7.abi0.dtk2404.torch2.1-cp310-cp310-manylinux2014_x86_64.whl (开发者社区)
pip install bitsandbytes-0.42.0-py3-none-any.whl (whl文件夹中)
Anaconda (方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
DTK驱动:dtk24.04
python:python3.10
torch: 2.1.0
torchvision: 0.16.0
onnx: 1.15.0
flash-attn: 2.0.4
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应
2、其它非特殊库参照requirements.txt安装
pip install -r requirements.txt
pip install timm --no-deps
pip install bitsandbytes-0.42.0-py3-none-any.whl (whl文件夹中)
数据集
无
推理
命令行
# Prompt Enhancement + Text-to-Image. Torch mode
python sample_t2i.py --prompt "千里冰封万里雪飘"
# Prompt Enhancement + Text-to-Image. Torch mode(在最新硬件上可用)
python sample_t2i.py --prompt "千里冰封万里雪飘" --infer-mode fa
# Only Text-to-Image. Torch mode
python sample_t2i.py --prompt "飞流直下三千尺疑是银河落九天" --no-enhance
# Generate an image with other image sizes.
python sample_t2i.py --prompt "飞流直下三千尺疑是银河落九天" --image-size 1280 768
# Prompt Enhancement + Text-to-Image. DialogGen loads with 4-bit quantization, but it may loss performance.
python sample_t2i.py --prompt "飞流直下三千尺疑是银河落九天" --load-4bit
参数列表
| Argument | Default | Description |
|---|---|---|
--prompt | None | The text prompt for image generation |
--image-size | 1024 1024 | The size of the generated image |
--seed | 42 | The random seed for generating images |
--infer-steps | 100 | The number of steps for sampling |
--negative | - | The negative prompt for image generation |
--infer-mode | torch | The inference mode (torch, fa) |
--sampler | ddpm | The diffusion sampler (ddpm, ddim, or dpmms) |
--no-enhance | False | Disable the prompt enhancement model |
--model-root | ckpts | The root directory of the model checkpoints |
--load-key | ema | Load the student model or EMA model (ema or module) |
--load-4bit | Fasle | Load DialogGen model with 4bit quantization |
webui(推荐)
# By default, we start a Chinese UI.
python app/hydit_app.py
# Using Flash Attention for acceleration. (在最新硬件上可用)
python app/hydit_app.py --infer-mode fa
# You can disable the enhancement model if the GPU memory is insufficient.
# The enhancement will be unavailable until you restart the app without the `--no-enhance` flag.
python app/hydit_app.py --no-enhance
# Start with English UI
python app/hydit_app.py --lang en
# Start a multi-turn(对话形式) T2I generation UI.
# If your DCU memory is less than 32GB, use '--load-4bit' to enable 4-bit quantization, which requires at least 22GB of memory.
python app/multiTurnT2I_app.py
result
| 结果 |  | | |
| prompt | 千里冰封万里雪飘 | 飞流直下三千尺疑是银河落九天 | 一只金毛犬叼着一个RTX4090显卡 |


精度
无
应用场景
算法类别
AIGC
热点应用行业
零售,广媒,电商
预训练权重
预训练权重快速下载中心:SCNet AlModels ,项目中的预训练权重可从快速下载通道下载:HunyuanDiT。
下载链接中的所有模型文件,并放入ckpts文件中。
ckpts/
├── dialoggen
│ ├── config.json
│ ├── generation_config.json
│ ├── model-00001-of-00004.safetensors
│ ├── model-00002-of-00004.safetensors
│ ├── model-00003-of-00004.safetensors
│ ├── model-00004-of-00004.safetensors
│ ├── model.safetensors.index.json
│ ├── openai
│ │ └── clip-vit-large-patch14-336
│ │ ├── config.json
│ │ ├── merges.txt
│ │ ├── preprocessor_config.json
│ │ ├── pytorch_model.bin
│ │ ├── README.md
│ │ ├── special_tokens_map.json
│ │ ├── tokenizer_config.json
│ │ ├── tokenizer.json
│ │ └── vocab.json
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── tokenizer.model
└── t2i
├── clip_text_encoder
│ ├── config.json
│ └── pytorch_model.bin
├── model
│ ├── pytorch_model_ema.pt
│ └── pytorch_model_module.pt
├── mt5
│ ├── config.json
│ ├── download.sh
│ ├── generation_config.json
│ ├── nohup.out
│ ├── pytorch_model.bin
│ ├── README.md
│ ├── special_tokens_map.json
│ ├── spiece.model
│ └── tokenizer_config.json
├── sdxl-vae-fp16-fix
│ ├── config.json
│ ├── diffusion_pytorch_model.bin
│ └── diffusion_pytorch_model.safetensors
└── tokenizer
├── special_tokens_map.json
├── tokenizer_config.json
├── vocab_org.txt
└── vocab.txt