- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊|接辅导、项目定制
一、课题背景和开发环境
📌第N5周:seq2seq详解📌
- Python 3.8.12
- numpy==1.21.5 -> 1.24.3
- pytorch==1.8.1+cu111
📌本周任务:📌
-
- 了解seq2seq是什么?
-
- 基于RNN的seq2seq模型如何处理文本/长文本序列?
-
- seq2seq模型处理长文本序列有哪些难点?
-
- 基于RNN的seq2seq模型如何结合attention来改善模型效果?
-
- 可以先尝试着自己编写代码
二、seq2seq是什么
seq2seq(sequence to sequence)是一种常见的NLP模型结构,翻译为“序列到序列”,即:从一个文本序列得到一个新的文本序列。典型的任务有:机器翻译任务,文本摘要任务。谷歌翻译在2016年末开始使用seq2seq模型,并发表了2篇开创性的论文,感兴趣的同学可以阅读原文进行学习。
- Sequence to Sequence Learning with Neural Networks
- Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
无论是否读过上述两篇谷歌的文章,NLP初学者想要充分理解并实现seq2seq模型很不容易。因为,我们需要拆解一系列相关的NLP概念,而这些NLP概念又是是层层递进的,所以想要清晰的对seq2seq模型有一个清晰的认识并不容易。但是,如果能够把这些复杂生涩的NLP概念可视化,理解起来其实就更简单了。因此,本文希望通过一系列图片、动态图帮助NLP初学者学习seq2seq以及attention相关的概念和知识。
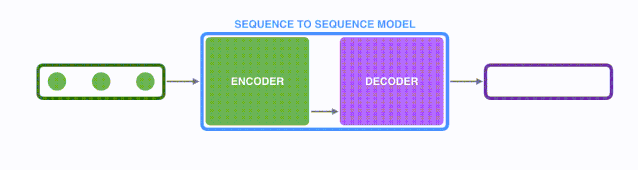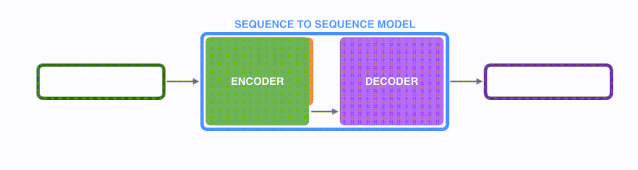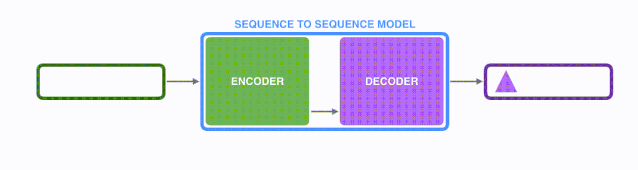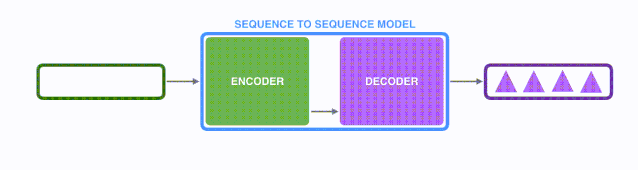
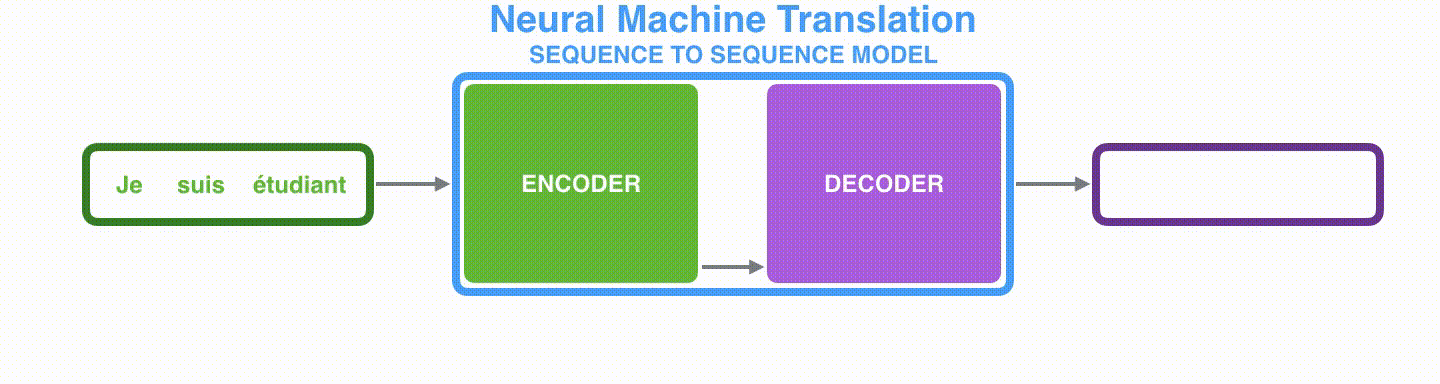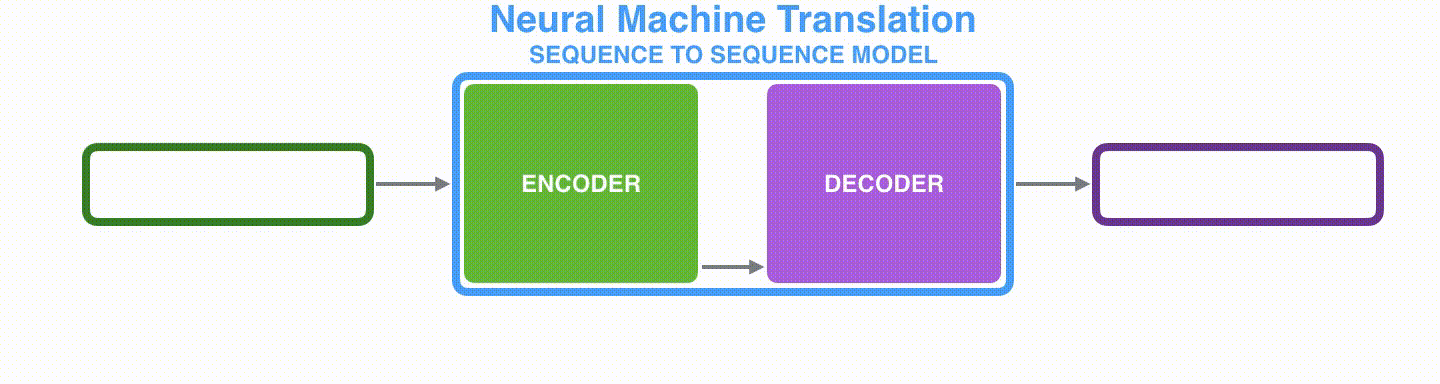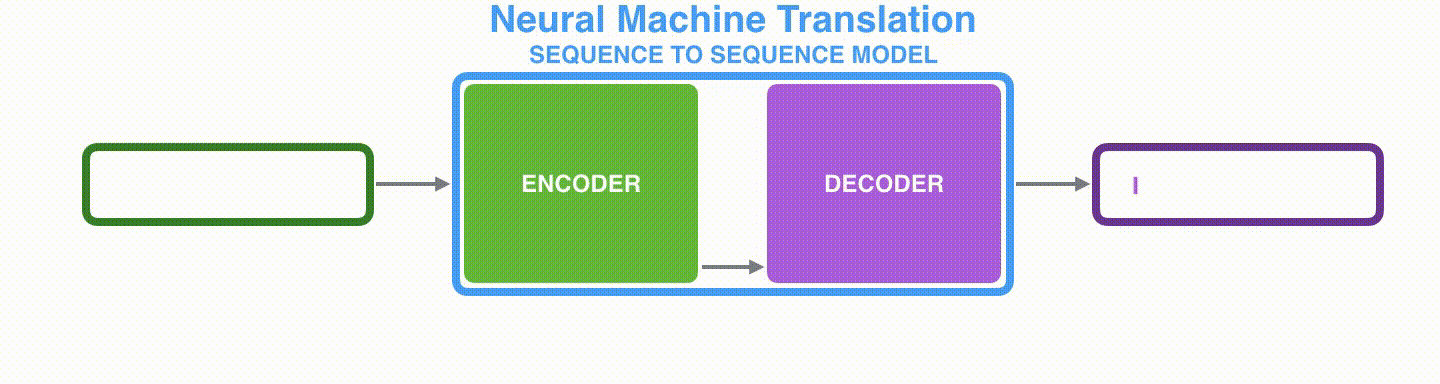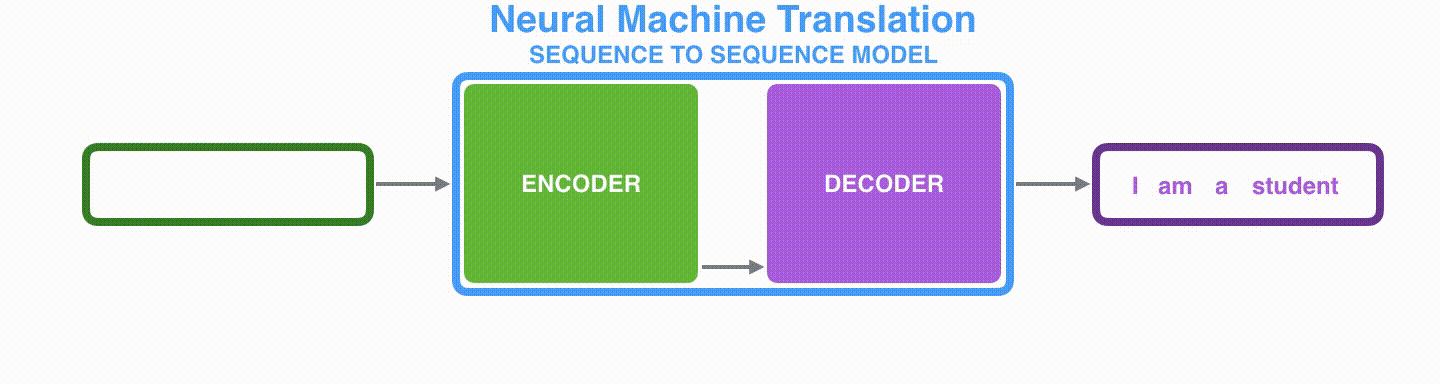
首先看seq2seq干了什么事情?seq2seq模型的输入可以是一个(单词、字母或者图像特征)序列,输出是另外一个(单词、字母或者图像特征)序列。一个训练好的seq2seq模型如下图所示:

如下图所示,以NLP中的机器翻译任务为例,序列指的是一连串的单词,输出也是一连串单词。

三、seq2seq原理
将上图中蓝色的seq2seq模型进行拆解,如下图所示:seq2seq模型由编码器(Encoder)和解码器(Decoder)组成。绿色的编码器会处理输入序列中的每个元素并获得输入信息,这些信息会被转换成为一个黄色的向量(称为context向量)。当我们处理完整个输入序列后,编码器把 context向量 发送给紫色的解码器,解码器通过context向量中的信息,逐个元素输出新的序列。
在机器翻译任务中,seq2seq模型实现翻译的过程如下图所示。seq2seq模型中的编码器和解码器一般采用的是循环神经网络RNN,编码器将输入的法语单词序列编码成context向量(在绿色encoder和紫色decoder中间出现),然后解码器根据context向量解码出英语单词序列。关于循环神经网络,建议阅读 Luis Serrano写的循环神经网络精彩介绍.(youtube网址)
黄色的context向量本质上是一组浮点数。而这个context的数组长度是基于编码器RNN的隐藏层神经元数量的。下图展示了长度为4的context向量,但在实际应用中,context向量的长度是自定义的,比如可能是256,512或者1024。在下文中,我们会可视化这些数字向量,使用更明亮的色彩来表示更高的值,如下图右边所示
那么RNN是如何具体地处理输入序列的呢?

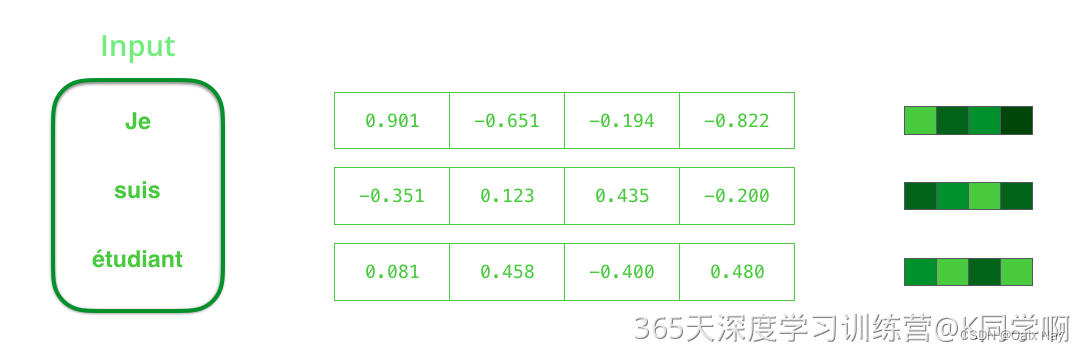
- 假设序列输入是一个句子,这个句子可以由 n n n 个词表示: s e n t e n c e = { w 1 , w 2 , . . . , w n } sentence = \{w_1,w_2,...,w_n\} sentence={ w1,w2,...,wn} 。
- RNN首先将句子中的每一个词映射成为一个向量得到一个向量序列: X = { x 1 , x 2 , . . . , x n } X = \{x_1,x_2,...,x_n\} X={ x1,x2,...,xn} ,每个单词映射得到的向量通常又叫做:word embedding。
- 然后在处理第 t ∈ [ 1 , n ] t\in[1,n] t∈[1,n] 个时间步的序列输入 x t x_t xt 时,RNN网络的输入和输出可以表示为: h t = R N N ( x t , h t − 1 ) h_t = RNN(x_t, h_{t-1}) ht=RNN(xt,ht−1)
- 输入:RNN在时间步 t t t 的输入之一为单词 w t w_t wt 经过映射得到的向量 x t x_t xt 。
- 输入:RNN另一个输入为上一个时间步 t − 1 t-1 t−1 得到的hidden state向量 h t − 1 h_{t-1} ht−1 ,同样是一个向量。
- 输出:RNN在时间步 t t t 的输出为 h t h_t ht hidden state向量。
我们在处理单词之前,需要将单词映射成为向量,通常使用 word embedding 算法来完成。一般来说,我们可以使用提前训练好的 word embeddings,或者在自有的数据集上训练word embedding。为了简单起见,上图展示的word embedding维度是4。上图左边每个单词经过word embedding算法之后得到中间一个对应的4维的向量。
进一步可视化一下基于RNN的seq2seq模型中的编码器在第1个时间步是如何工作:
RNN在第2个时间步,采用第1个时间步得到hidden state#10(隐藏层状态)和第2个时间步的输入向量input#1,来得到新的输出hidden state#1。
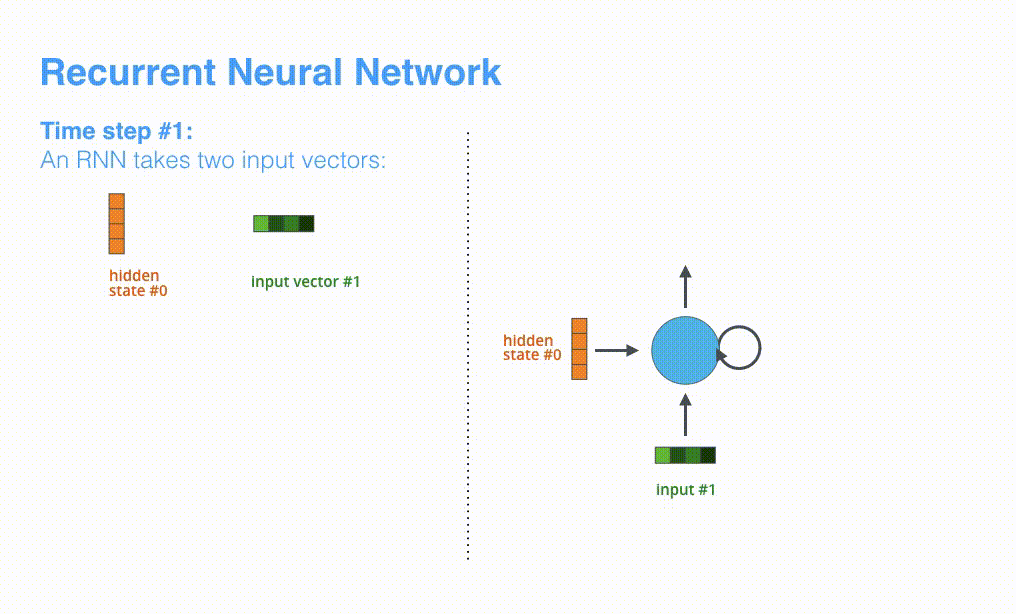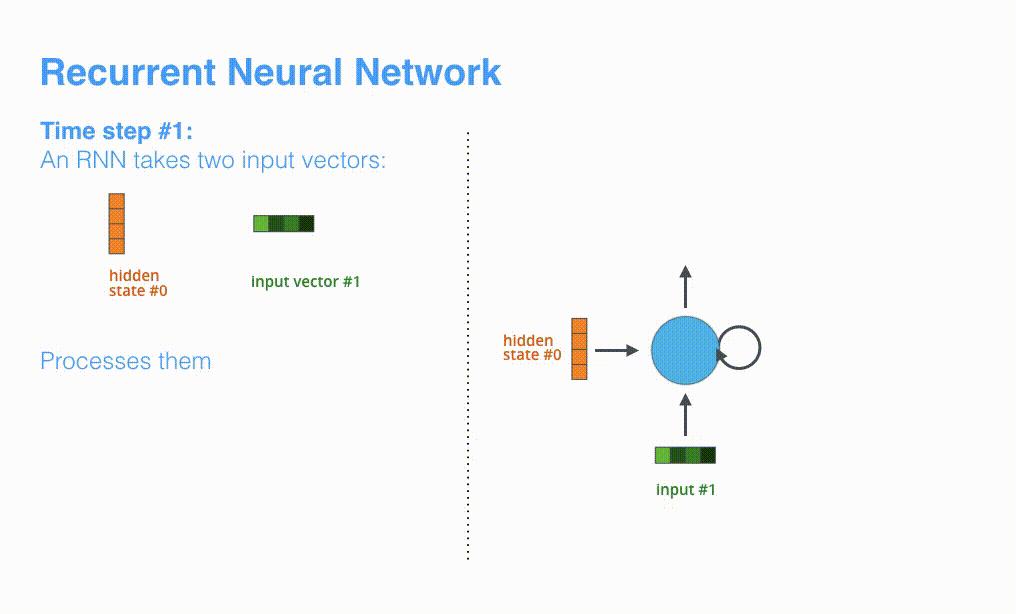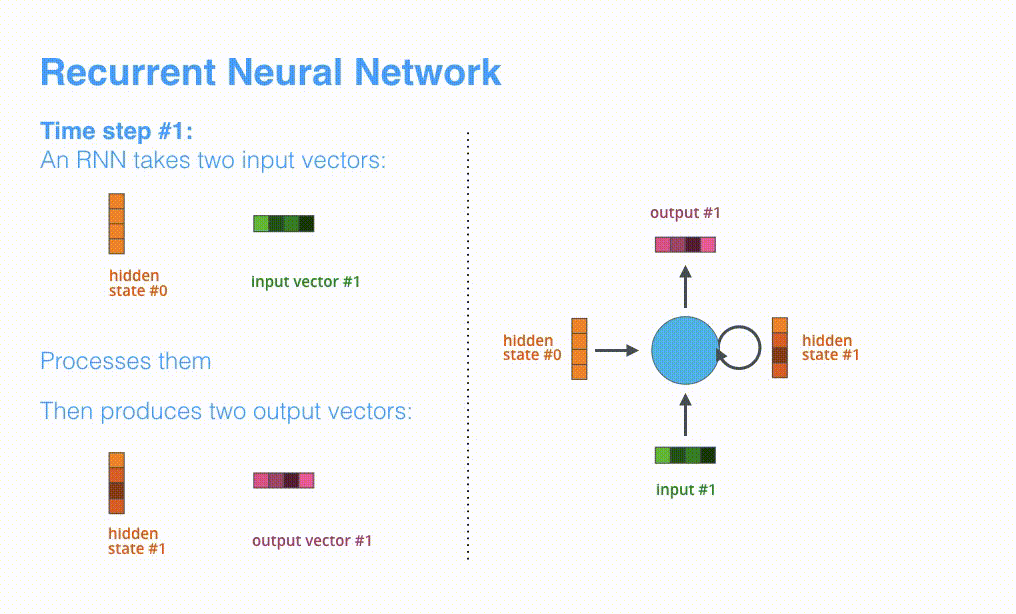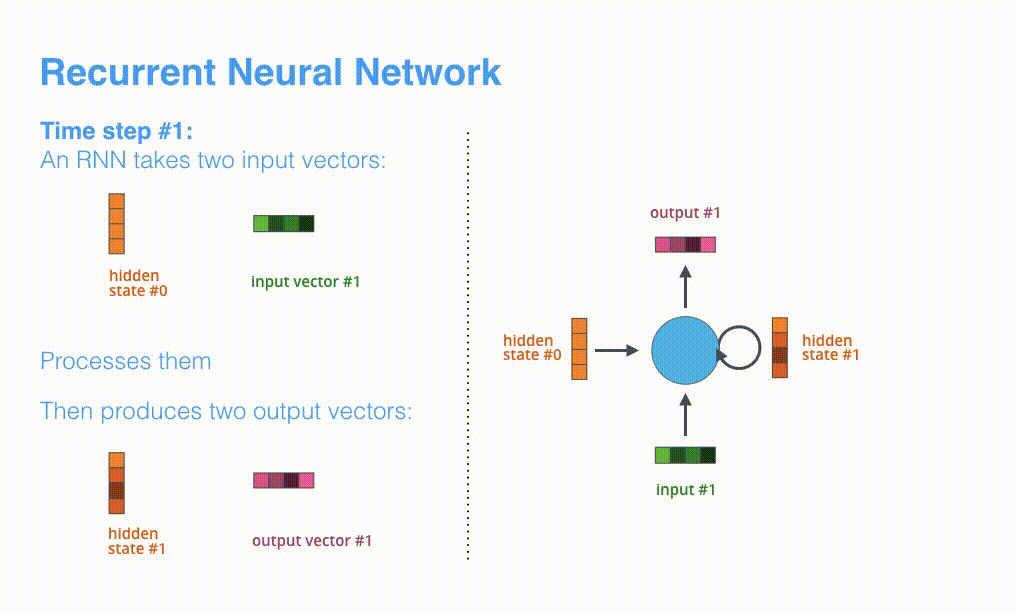
看下面的动态图,详细观察一下编码器如何在每个时间步得到hidden sate,并将最终的hidden state传输给解码器,解码器根据编码器所给予的最后一个hidden state信息解码处输出序列。注意,最后一个 hidden state实际上是我们上文提到的context向量。编码器逐步得到hidden stat