海量数据处理相关问题
转载自: doocs/advanced-java
1. 如何从大量URL中找出相同的URL?
-
题目描述:
给定 a、b 两个文件,各存放 50 亿个 URL,每个 URL 各占 64B,内存限制是 4G。请找出 a、b 两个文件共同的 URL。
-
总体思路:
- 分而治之,进行哈希取余。
- 对每个子文件进行HashSet统计。
-
解答思路:
- 由于内存只有4G,因此不可能一次性把所有url加载到内存中进行处理。故先遍历文件a,对遍历的url求
hash(url)%1000,根据计算结果将遍历到的URL存入 a 0 , a 1 , a 2 , . . . , a 999 \ a_0 , a_1, a_2,...,a_{999} a0,a1,a2,...,a999这一千个小文件中,每个大小约为300MB。 - 使用同样的方式遍历b,把文件b中的url分别存储到 b 0 , b 1 , b 2 , . . . , b 999 \ b_0 , b_1, b_2,...,b_{999} b0,b1,b2,...,b999中。这样处理过后,所有可能相同的 URL 都在对应的小文件中,如 a 0 \ a_0 a0 和 b 0 \ b_0 b0是一对,以此类推,共1000对。只需要求出这1000对小文件中相同的url即可。
- 遍历 a i \ a_i ai中的URL,将其存储到一个HashSet集合中,然后遍历 b i \ b_i bi中的每个URL,看该URL是否出现在HashSet集合中,若是,则可以将其存到一个单独的文件中。
- 由于内存只有4G,因此不可能一次性把所有url加载到内存中进行处理。故先遍历文件a,对遍历的url求
如何从大量数据中找出高频词?
-
题目描述:
有一个 1GB 大小的文件,文件里每一行是一个词,每个词的大小不超过 16B,内存大小限制是 1MB,要求返回频数最高的 100 个词(Top 100)。
-
总体思路:
- 分而治之,哈希取余
- 使用hashmap统计频数
- 使用小顶堆求TOP100
-
解答思路:
- 首先遍历大文件,对遍历到的每个词x,执行 h a s h ( x ) % 5000 \ hash(x)\%5000 hash(x)%5000, 将结果为i的词放到文件 a i \ a_i ai中,遍历结束后每个文件大小为200KB左右。
- 接着统计每个小文件中出现频数最高的100个词。使用hashmap统计出每个词的词频。然后使用小根堆,堆大小为100,找出小文件的所有词中出现频数最高的100个词。
- 依次遍历所有小文件,最后得到的小顶堆的词就是出现频数最高的100个词。
如何找出某天访问百度网站最多的IP?
-
题目描述:
现有海量日志数据保存在一个超大文件中,该文件无法直接读入内存,要求从中提取某天访问百度次数最多的那个 IP。
-
总体思路:
- 分而治之,哈希取余
- 使用hashmap统计频数
- 求max
-
解答思路:
- 首先遍历大文件,对每个IP执行 h a s h ( I P ) % 1000 \ hash(IP)\%1000 hash(IP)%1000,分成1000个小文件。若小文件依然无法直接读入内存,则继续划分。
- 遍历每个小文件,使用hashmap统计出每个IP的出现次数。找出最大出现次数的IP和对应的次数。
- 比较这1000个小文件的IP的最大出现次数,找出频数最高的IP.
如何从大量数据中找出不重复的整数?
-
题目描述:
在2.5亿个整数中找出不重复的整数。
-
总体思路:
- 分治法或位图法。
-
解答思路:
- 分治法:先将2.5亿个数划分到多个小文件,用hashSet找出每个小文件中不重复的整数,再合并每个子结果,即为最终结果。
- 位图法:使用int能表示的整数个数为
2
32
\ 2^{32}
232,使用2个bit来表示各个数字的状态:
- 00表示没有出现
- 01表示这个数字出现过1次
- 10表示这个数字出现了多次
- 那么这 2 32 \ 2^{32} 232个整数,总共所需内存为 2 32 ∗ 2 b = 1 G B \ 2^{32}*2b=1GB 232∗2b=1GB ,因此当可用内存超过1GB时,可以采用位图法。假设内存满足位图法要求,那么进行下面的操作:
- 遍历2.5亿个整数,查看位图中对应的位,如果是00就变为01,如果是01就变为10,如果是10就保持不变。遍历结束后,查看位图,将对应位是01的整数输出即可。
如何在大量数据中判断一个数是否存在?
-
题目描述:
给定 40 亿个不重复的没排过序的 unsigned int 型整数,然后再给定一个数,如何快速判断这个数是否在这 40 亿个整数当中?
-
总体思路:
- 分治法或位图法
-
解答思路:
-
分治法:先将大量数据划分到多个小文件,用hashSet找出每个小文件中不重复的整数。对给定的数据,依次判断它是否出现在每个hashSet中,如果出现过,则在,如果都没有出现,那么就不在。
-
位图法:40亿个不重复整数,用40亿个位来表示,初始位均为0,那么共需要内存 4 , 000 , 000 , 000 b ≈ 512 M 。 \ 4, 000, 000, 000b≈512M。 4,000,000,000b≈512M。我们读取这40亿个整数,将对应的bit设置为1,接着读取要查询的数,判断相应位是否为1,如果为1表示存在,否则表示不存在。
-
如何查询最热门的查询串?
-
题目描述:
搜索引擎会通过日志文件把用户每次检索使用的所有查询串都记录下来,每个查询串的长度不超过 255 字节。
假设目前有 1000w 个记录(这些查询串的重复度比较高,虽然总数是 1000w,但如果除去重复后,则不超过 300w 个)。请统计最热门的 10 个查询串,要求使用的内存不能超过 1G。(一个查询串的重复度越高,说明查询它的用户越多,也就越热门。)
-
总体思路:
- 分治法或HashMap法或前缀树法。
-
解答思路:
- 每个查询串最长为 255B,1000w 个串需要占用 约 2.55G 内存,因此,我们无法将所有字符串全部读入到内存中处理。
- 分治法: 划分为多个小文件,保证单个小文件中的字符串能被直接加载到内存中处理,然后求出每个文件中出现次数最多的 10 个字符串;最后通过一个小顶堆统计出所有文件中出现最多的 10 个字符串。
- HashMap法: 虽然字符串总数比较多,但去重后不超过300w,因此可以考虑把所有字符串以及出现次数保存在一个hashmap中。所占用的空间为 300w*(255+4)≈777M(其中,4 表示value为整数占用的 4 个字节)。由此可见,1G 的内存空间完全够用。然后用小顶堆统计出hashmap中出现次数最多的10个字符串。
- 前缀树法:这些字符串含有大量相同的前缀时,可以考虑使用前缀树来统计字符串出现次数,树的结点保存字符串出次数,0表示没有出现。
- 具体步骤: 在遍历字符串时,在前缀树中查找,如果找到,则把结点中保存的字符串次数+1,否则为这个字符串构建新节点。构建完后把叶子结点中字符串的出现次数置为1.最后依然使用小顶堆来对字符串的出现次数进行排序。
如何统计不同电话号码的个数?
-
题目描述:
已知某个文件内包含一些电话号码,每个号码为 8 位数字,统计不同号码的个数。
-
总体思路:
- 位图法
-
解答思路:
- 对于本地,8位电话号码可以表示的号码个数为 1 0 8 \ 10^8 108个,即1亿个。对每个号码用一个bit来表示,则内存占用为100M bit.
- 申请一个位图数组,长度为 1 亿,初始化为 0。然后遍历所有电话号码,把号码对应的位图中的位置置为 1。遍历完成后,如果 bit 为 1,则表示这个电话号码在文件中存在,否则不存在。bit 值为 1 的数量即为 不同电话号码的个数。
如何从5亿个数中找出中位数?
-
题目描述:
从 5 亿个数中找出中位数。数据排序后,位置在最中间的数就是中位数。当样本数为奇数时,中位数为 第
(N+1)/2个数;当样本数为偶数时,中位数为 第N/2个数与第1+N/2个数的均值。 -
总体思路
- 双堆法或分治法。
-
解答思路:
-
双堆法:维护两个堆,一个大顶堆,一个小顶堆。大顶堆中的最大数小于等于小顶堆中最小的数。保证这两个堆中的元素个数差不超过1。具体见
leetcode 295。若数据总数为偶数,当这两个堆建好之后,中位数就是这两个堆顶元素的平均值。当数据总数为奇数时,根据两个堆的大小,中位数一定在数据多的堆的堆顶。 -
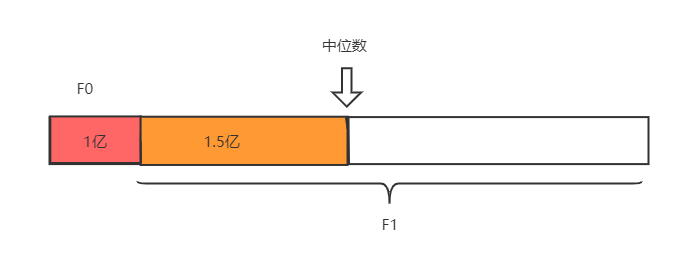
分治法:顺序读取这5亿个数字,对于读取到的数字num,如果它对应的二进制中最高位为1,则把这个数字写到f1中,否则写到f0中。在最高位是符号位的情况下,f0的数全部大于f1。划分后,可以非常容易的知道中位数是在f0还是f1中。假设f1中有1亿个数,那么中位数一定在f0中,且是在f0中,从小到大排列的1.5亿个数与它后面一个数的平均值。
-
对于f0可以用次高位的二进制继续将文件一分为二,如此划分下去,直到划分后的文件可以被加载到内存中,把数据加载到内存中后可以直接排序,找出中位数。
-
如何按照query的频度排序?
-
题目描述:
有 10 个文件,每个文件大小为 1G,每个文件的每一行存放的都是用户的 query,每个文件的 query 都可能重复。要求按照 query 的频度排序。
-
总体思路:
- 内存若够,直接读入进行排序;
- 内存不够,先划分为小文件,小文件排好序后,整理使用外排序进行归并。
-
解答思路:
- 如果 query 的重复度比较大,可以考虑一次性把所有 query 读入内存中处理;如果 query 的重复率不高,那么可用内存不足以容纳所有的 query,这时候就需要采用分治法或其他的方法来解决。
- HashMap法:如果 query 重复率高,说明不同 query 总数比较小,可以考虑把所有的 query 都加载到内存中的 HashMap 中。接着就可以按照 query 出现的次数进行排序。
- 分治法:分治法需要根据数据量大小以及可用内存的大小来确定问题划分的规模。对于这道题,可以顺序遍历 10 个文件中的 query,通过 Hash 函数
hash(query) % 10把这些 query 划分到 10 个小文件中。之后对每个小文件使用 HashMap 统计 query 出现次数,根据次数排序并写入到零外一个单独文件中。接着对所有文件按照 query 的次数进行排序,这里可以使用归并排序(由于无法把所有 query 都读入内存,因此需要使用外排序)。
如何找出排名前500的数?
-
题目描述:
有 20 个数组,每个数组有 500 个元素,并且有序排列。如何在这 20*500 个数中找出前 500 的数?
-
解答思路:
- 假设数组降序排列。首先建立大顶堆,堆的大小为数组的个数,即为20.把每个数组最大的值存到堆中。
- 接着删除堆顶元素,保存到另外一个大小为500的数组中,然后向大顶堆插入删除的元素所在数组的下一个元素。
- 重复上面的步骤,直到删除完第500个元素,也找出了最大的前500个数。
海量数据的排序
-
题目描述:
一个文件中有9亿条不重复的9位整数,对这个文件中数字进行排序;
-
解答思路:
- 分治法:过Hash法将9亿条数据分为20个小文件,每个文件存5000万条,大约需要占用5000万*4B = 200MB空间。遍历这20个小文件,每次取500万条数据,进行排序,将排序结果放入一个大文件中。 一共要进行5000/500=10次排序。
- 位图法:考虑到最大的9位整数为999999999,由于9亿条数据是不重复的,可以声明一个可以包含9位整数的bit数组,一共需要10亿/8,大约120MB内存。把内存中的数组全部初始化为0,读取文件中的数据,并将数据放入内存,遍历所有数据,将这9亿条数据放入bit数组中,对应bit置一。最后遍历整个bit数组,将bit为1的数组下标存入文件,最终得到排序的内容.