推荐系统-内容推荐
用户画像
一个推荐系统大概有三步:认识每一个用户->给他推荐他感兴趣的东西->各种指标上升。
用户画像(User Profile)大体分为给机器看的和给人看的,其中给人看的一般是运营,产品等用的。我们这里只关注给机器看的。我们知道要对用户和物品进行计算,是需要对数据进行计算的,因此我们首先就要将用户和物品都向量化,用户向量化后的结果,就是User Profile,俗称“用户画像”,所以,用户画像不是推荐系统的目的,而是在构建推荐系统过程中产生的一个关键环节的副产品。
用户画像的维度,在制定用户画像维度的时候,需要对每一个维度都是可理解的,而维度的数量是自想的(假如是根据用户的阅读历史挖掘阅读兴趣标签,那么我们无法提前知道用户有哪些标签,也就不能确定用户画像有哪些维度),有哪些维度也是自想的(维度越多越精细,个性化推荐就越强,但带来的计算代价也就越大,这里注意的是用户画像是向量化结果,而不是标签化。标签化知识向量化的一种)。
用户画像的构建,查户口,对数据(积累历史数据,做统计工作,就是历史行为数据中去挖掘出标签,然后在标签维度中做数据统计,用统计结果作为量化结果),黑盒子(embedding)
文本信息来构建画像
首先我们要知道物品这一端也有大量文本信息,可以用来构建物品画像(通常有物品的标题,描述,物品本身的内容,物品的其他基本属性的文本)
对结构化文本采用的方法有关键词提取、实体识别、内容分类、主题模型、embedding、聚类。
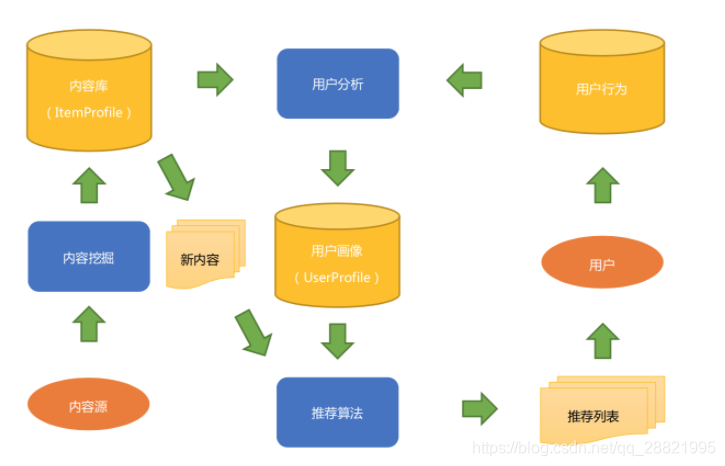
上面是典型基于内容推荐的框架图
内容这一端:内容源经过内容分析,得到结构化的内容库和内容模型,也就是物品画像。用户这一端:用户看过推荐列表后,会产生用户行为数据,结合物品画像,经过用户分析得到用户画像。以后对于那些没有给用户推荐过的新内容,经过相同的内容分析过程后就可以经过推荐算法匹配,计算得到新的推荐列表给用户。如此周而复始,永不停息。
内容源:作者写的,网站爬取的…
内容分析和用户分析:构建物品和用户画像…
内容推荐算法:对于基于内容的推荐系统,最简单的推荐算法当然是计算相似性即可,用户的画像内容就表示为稀疏的向量,同时内容端也有对应的稀疏向量,两者之间计算余弦相似度,根据相似度对推荐物品排序。
量,两者之间计算余弦相似度,根据相似度对推荐物品排序。