前言
朴素贝叶斯(Naive Bayes,NB),这名字听起来既熟悉又点奇怪,不过它确实是应用广泛的分类算法之一。朴素贝叶斯的基层逻辑就是基于贝叶斯公式,跟SVM一样纯数学,因此分类效率相对稳定,参数也比较少,所以很“朴素”。
具体的数学逻辑运算就不说了,直接上代码实战SUV:
一、导入库与数据
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.metrics import confusion_matrix
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
# 导入数据集
dataset = pd.read_csv('Day 4 Social_Network_Ads.csv')
X = dataset.iloc[:, [1, 2, 3]].values
Y = dataset.iloc[:, 4].values
# 性别转化为数字
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0])
二、数据集切分与特征缩放
# 将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, Y, test_size=0.25, random_state=0)
# 特征缩放
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
三、数据训练与预测(有三种贝叶斯哈)
直接上代码了:
from sklearn.naive_bayes import GaussianNB
classifier = GaussianNB(var_smoothing=1e-8)
classifier.fit(X_train, y_train)
四、预测测试集结果
y_pred = classifier.predict(X_test)
随便解说
NB的参数少得惨不忍睹:
这个叫高斯朴素贝叶斯:
class sklearn.naive_bayes.GaussianNB(*, priors=None, var_smoothing=1e-09)
① priors:先验概率大小,如果没有给定,模型则根据样本数据自己计算(利用极大似然法)。
② var_smoothing:所有特征的最大方差部分,添加到方差中用于提高计算稳定性,默认1e-9。
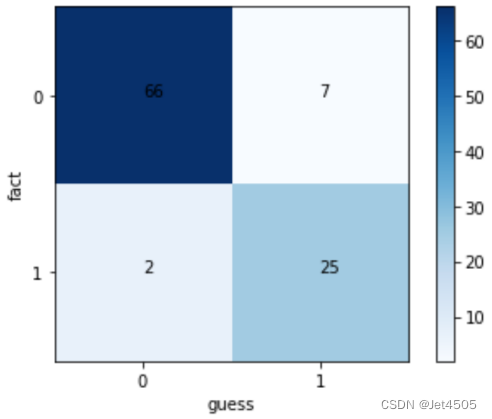
五、模型评估
模型预测,使用混淆矩阵评估:
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)
输出的结果:
混淆矩阵可视化:

总结
这一步比较简单,可以早早洗洗睡了。