本文为【Redis分布式锁八股文合集(2)】初版,后续还会进行优化更新,欢迎大家关注交流~
hello hello~ ,这里是绝命Coding——老白~💖💖 ,欢迎大家点赞🥳🥳关注💥💥收藏🌹🌹🌹
💥个人主页:绝命Coding-CSDN博客
💥 所属专栏:后端技术分享
这里将会不定期更新有关后端、前端的内容,希望大家多多点赞关注收藏💖

往期内容(篇幅过多,不一一列出,感兴趣的小伙伴可以查看专栏):
大厂面试官问我:Redis处理点赞,如果瞬时涌入大量用户点赞(千万级),应当如何进行处理?【后端八股文一:Redis点赞八股文合集】-CSDN博客
大厂面试官问我:布隆过滤器有不能扩容和删除的缺陷,有没有可以替代的数据结构呢?【后端八股文二:布隆过滤器八股文合集】-CSDN博客
大厂面试官问我:Redis持久化RDB有没有可能阻塞?阻塞点在哪里?【后端八股文三:Redis持久化八股文合集】-CSDN博客
Redis缓存
为什么Redis做缓存?
(高并发,高性能——内存)
(1)高并发
承受的请求 大 ( 直接缓存 数据库)
(单台设备的 Redis 的 QPS(每秒处理完请求的次数)是Mysql的10倍,Redis 单机的 QPS 能轻松破 10w,而 MySQL 单机的 QPS 很难破 1w)
(2)高性能
第一次访问,从硬盘;
缓存,直接内存,速度快
redis作为缓存的使用场景?/ 哪些数据适合放入缓存
即时性、数据线要求不高
访问量大且更新频率不高的数据(读多,写少)
比如:电商商品
什么是缓存预热
缓存预热是指系统上线后,提前将相关的缓存数据加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题,用户直接查询事先被预热的缓存数据。
如果不进行预热,那么Redis初始状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库中, 对数据库造成流量的压力。
缓存预热解决方案:
数据量不大的时候,工程启动的时候进行加载缓存动作;
数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
数据量太大的时候,优先保证热点数据进行提前加载到缓存。
假设一种高热的数据它突然之间过期了,怎么预防这样的情况?你就那比如说恰好这一秒钟我过期了,正好这一秒钟有一两万个QPS
- 分布式缓存: 考虑使用分布式缓存方案,如Redis集群,将热数据分散存储在多个节点上,减少单一节点的过期负担。
- 过期时间随机化: 在设置过期时间时,可以引入一些随机化因素,以减少在相同时刻过期的可能性。
- 限制过期数据量: 设置过期数据的限制,确保在同一时刻过期的数据数量有一个上限,从而避免过多的数据一起过期。
- 增加缓存节点: 如果预计在某个时间段内会有大量数据过期,可以临时增加缓存节点数量,以扩展缓存容量和处理能力。
- 过期前刷新: 对于热数据,可以在过期之前进行刷新,延长数据的有效期。这样可以避免数据突然过期造成的负载冲击。
- 流量控制: 在高并发情况下,可以实施流量控制机制,限制同时访问过期数据的请求数量,减轻过期时的压力。
- 淘汰策略: 使用合适的淘汰策略,如LRU(最近最少使用)等,使得热数据能够保持在缓存中,减少过期的影响。
缓存雪崩,缓存穿透,缓存击穿 / 常见问题解决方案
(缓存穿透——不存在、缓存击穿——访问量大、缓存雪崩——过期时间)
缓存雪崩
指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。
解决:
缓存数据的过期时间设置随机(防止同一时间大量数据过期现象发生)
加锁排队:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个 key 只允许一个线程查询数据和写缓存,其他线程等待;
数据预热:可以通过缓存 reload 机制,预先去更新缓存,再即将发生大并发访问前手动触发加载缓存不同的 key,设置不同的过期时间,让缓存失效的时间点尽量均匀;
- 均匀设置过期时间:设置不同的过期时间,让缓存失效的时间点尽量均匀。通常可以为有效期增加随机值
- 互斥锁:同一时间只让一个线程构建缓存,其他线程阻塞排队。
- 双 key 策略:
主缓存:有效期按照经验值设置,设置为主读取的缓存,主缓存失效后从数据库加载最新值。
备份缓存:有效期长,获取锁失败时读取的缓存,主缓存更新时需要同步更新备份缓存。
(限流、提前缓存)
缓存击穿
一份热点数据访问量过大,在缓存失效,请求直达存储层 服务器崩溃
(可以发现缓存击穿跟缓存雪崩很相似,你可以认为缓存击穿是缓存雪崩的一个子集。)
解决:
永不过期,不给热点数据设置过期时间
加互斥锁
缓存穿透
客户端查询不存在的数据 请求直达存储层 负载过大(既不在缓存中,也不在数据库中)
原因:业务层误将缓存和库中数据删除
有人恶意访问库中不存在的
解决:
缓存空对象,并加入短暂过期时间(存储层未命中,仍将空值缓存)
布隆过滤器(数据存入过滤器,访问缓存前拦截,若请求数据不存在则返回空值)
非法请求的限制
缓存击穿的互斥锁怎么实现的?
使用setnx作为Redis中的锁。
Redis中查询缓存
- 存在且不为空值,直接返回
- 为空值(比如“”、0等特殊值),返回失败结果
- 不存在,获取锁
获取锁失败,等待重试
获取成功,查找MySQL
- 不存在,Redis存入空值
- 存在,写入Redis
释放锁,返回结果
public Result queryShopById(Long id) {
// 用String形式存储JSON
String shopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
// 如果查询结果不为null,直接返回
if (StrUtil.isNotBlank(shopJson)) {
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
// 否则Redis中查询结果为空,判断是否为“”
if (shopJson != null) {
return Result.fail("店铺不存在,请确认id是否正确");
}
// 尝试获取锁,
// 如果没有得到锁,Sleep一段时间
if (!tryLock(LOCK_SHOP_KEY + id)) {
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 从开始重试
return queryShopById(id);
}
// 获得了锁,从MySQl中查找
Shop shop = this.getById(id);
// 模拟重建的延时
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 不在MySQL中
if (shop == null) {
// 将空值写入Redis
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
// 释放锁
unLock(LOCK_SHOP_KEY + id);
return Result.fail("店铺不存在,请确认id是否正确");
}
else {
// 在MySQL中,存入redis
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 释放锁
unLock(LOCK_SHOP_KEY + id);
return Result.ok(shop);
}
}
public boolean tryLock(String key) {
// 尝试获取锁,set成功返回true,否则返回false
Boolean getLock = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
// 避免getLock为null,使用工具类
return BooleanUtil.isTrue(getLock);
}
public void unLock(String key) {
stringRedisTemplate.delete(key);
}一般我们在更新数据库数据时,需要同步redis中缓存的数据,所以存在两种方法:
第一种方案:先执行update操作,再执行缓存清除。
第二种方案:先执行缓存清除,再执行update操作。
这两种方案的弊端是当存在并发请求时,很容易出现以下问题:
第一种方案:当请求1执行update操作后,还未来得及进行缓存清除,此时请求2查询到并使用了redis中的旧数据。
第二种方案:当请求1执行清除缓存后,还未进行update操作,此时请求2进行查询到了旧数据并写入了redis。
所以此时我们需要使用第三种方案:先进行缓存清除,再执行update,最后(延迟N秒)再执行缓存清除。
上述中(延迟N秒)的时间要大于一次写操作的时间,一般为3-5秒。
原因:如果延迟时间小于写入redis的时间,会导致请求1清除了缓存,但是请求2缓存还未写入的尴尬。。。
ps:一般写入的时间会远小于5秒
先更新db再删缓存,如果删失败了怎么办?
事务,回退数据库
延迟删除
如果Redis缓存扛不住怎么办?
使用本地缓存(在面对大部分并发场景或者一些中小型公司流量没有那么高的情况,使用redis基本都能解决了。但是在流量较高的情况下可能得使用到本地缓存了)
比如guava的LoadingCache和快手开源的ReloadableCache。
如果单节点qps达到了千级别就要解决单点问题了(即使redis号称能抗住十万级别的qps)
本地缓存
在一些场景下可能单纯使用Redis类的远程缓存已经不够了,还需要进一步配合本地缓存使用,例如Guava cache或Caffeine,从而再次提升程序的响应速度与服务性能。于是,就产生了使用本地缓存作为一级缓存,再加上远程缓存作为二级缓存的两级缓存架构。
为什么要使用本地缓存
- 本地缓存基于本地环境的内存,访问速度非常快,对于一些变更频率低、实时性要求低的数据,可以放在本地缓存中,提升访问速度
- 使用本地缓存能够减少和Redis类的远程缓存间的数据交互,减少网络I/O开销,降低这一过程中在网络通信上的耗时
本地缓存问题及解决
1. 缓存一致性
两级缓存与数据库的数据要保持一致,一旦数据发生了修改,在修改数据库的同时,本地缓存、远程缓存应该同步更新。
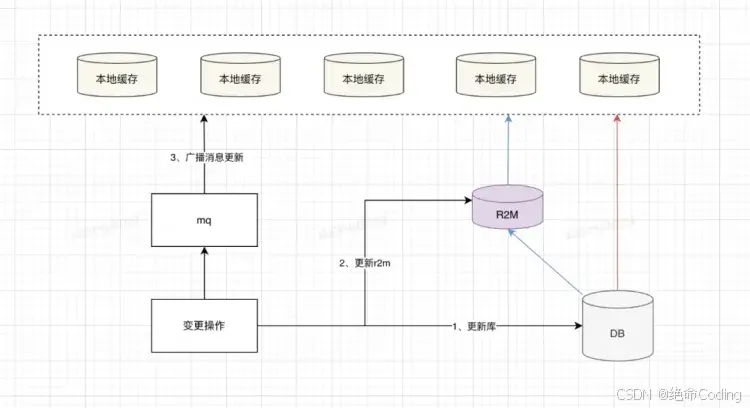
解决方案1: MQ
一般现在部署都是集群部署,有多个不同节点的本地缓存; 可以使用MQ的广播模式,当数据修改时向MQ发送消息,节点监听并消费消息,删除本地缓存,达到最终一致性;
解决方案2:Canal + MQ
如果你不想在你的业务代码发送MQ消息,还可以适用近几年比较流行的方法:订阅数据库变更日志,再操作缓存。Canal 订阅Mysql的 Binlog日志,当发生变化时向MQ发送消息,进而也实现数据一致性。
redis优化缓存结构
(1)使用Redis和Cache 多级缓存;
(2)Caffine+Redis+ES 做三级缓存;
(3)使用 Redis 实现分布式缓存,另外配合 Nginx 缓存 + 本地 Caffeine 缓存 + CDN 缓存 + 浏览器缓存共同实现多级缓存来保证系统的性能。
(4)使用mq转发(来自京东技术:营销权益平台春晚技术探究):
本地缓存的构建的两种方式:
- 一级缓存:本地+mysql+推模式更新。
- 两级缓存:本地+r2m+mysql+推模式更新。
后期新的八股文合集文章会继续分享,感兴趣的小伙伴可以点个关注~
更多精彩内容以及免费资料请关注公众号:绝命Coding
