垃圾回收&运行机制
垃圾回收
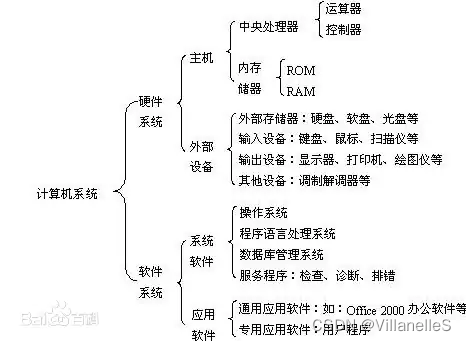
计算机组成
我们编写的软件首先读取到内存,用于提供给 CPU 进行运算处理。
内存的读取和释放,决定了程序性能。
Windows电脑启动程序是在rom的。
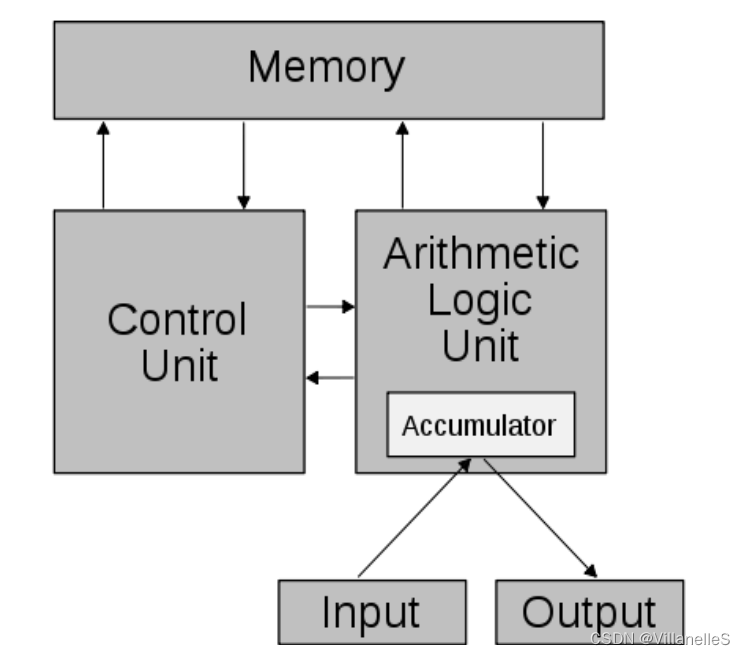
冯诺依曼模型
解释与编译
编译相当于做好了一桌子菜,可以直接开吃了。而解释就相当于吃火锅,需要一边煮一边吃。
JavaScript 属于解释型语言,它需要在代码执行时,将代码编译为机器语言。
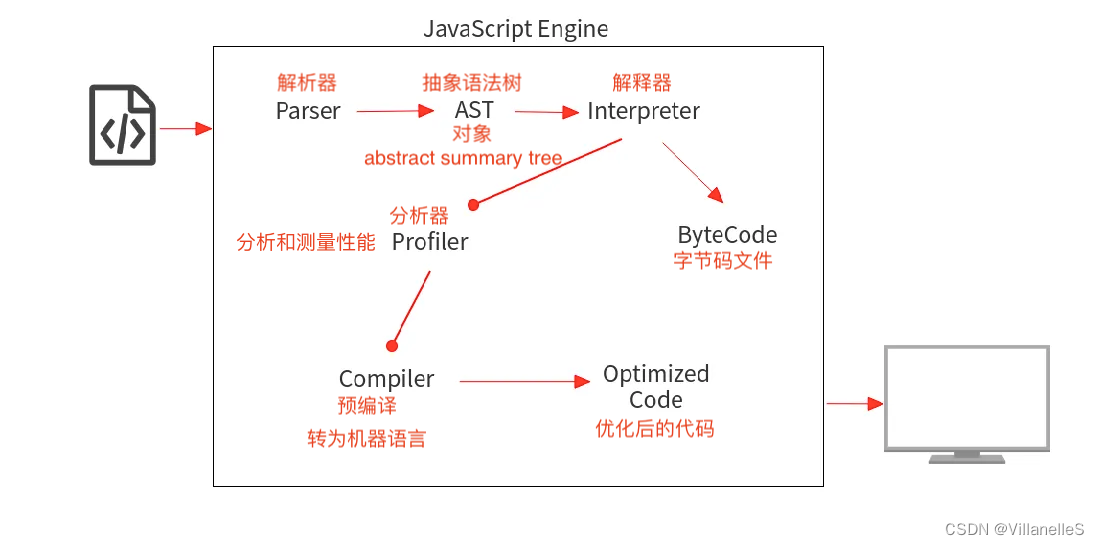
- Interpreter 逐行读取代码并立即执行。
- Compiler 读取您的整个代码,进行一些优化,然后生成优化后的代码。
从上图中可以看出,ByteCode 只是中间码,计算机仍需要对其进行翻译才能执行。 但是 Interpreter 和 Compiler 都将源代码转换为机器语言,它们唯一的区别在于转换的过程不尽相同。 - Interpreter 逐行将源代码转换为等效的机器代码。
- Compiler 在一开始就将所有源代码转换为机器代码

JavaScript引擎
JavaScript 其实有众多引擎,只不过 v8 是我们最为熟知的。
- V8 (Google),用 C++编写,开放源代码,由 Google 丹麦开发,是 Google Chrome 的一部分,也用于 Node.js。
- JavaScriptCore (Apple),开放源代码,用于 webkit 型浏览器,如 Safari ,2008 年实现了编译器和字节码解释器,升级为了 SquirrelFish。苹果内部代号为“Nitro”的 JavaScript 引擎也是基于 JavaScriptCore 引擎的。
- Rhino,由 Mozilla 基金会管理,开放源代码,完全以 Java 编写,用于 HTMLUnit
- SpiderMonkey (Mozilla),第一款 JavaScript 引擎,早期用于 Netscape Navigator,现时用于 Mozilla Firefox。
V8引擎
在node.js整个架构中:
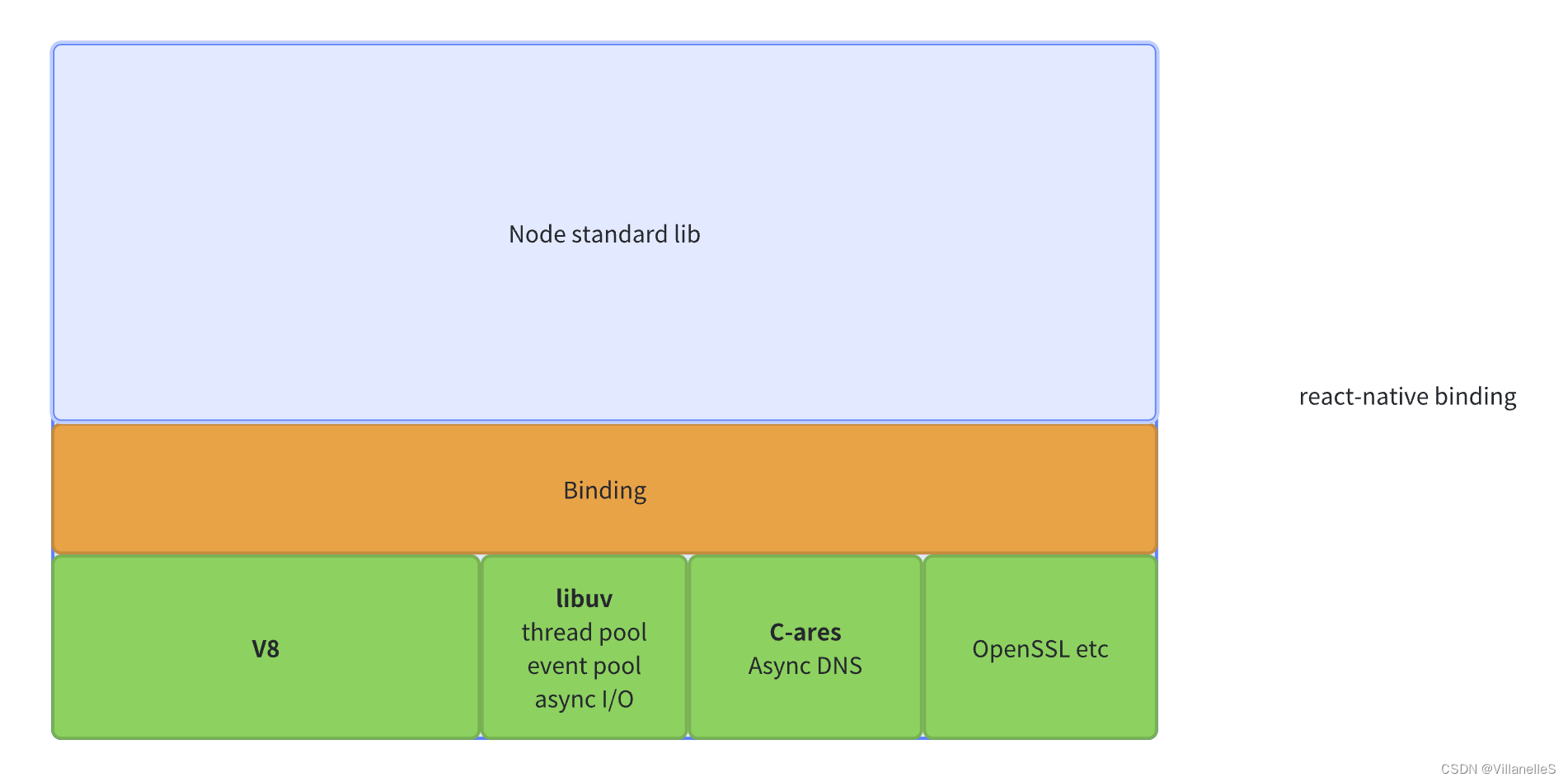
谷歌的 Chrome 使用 V8,Safari 使用 JavaScriptCore,Firefox 使用 SpiderMonkey
V8处理过程
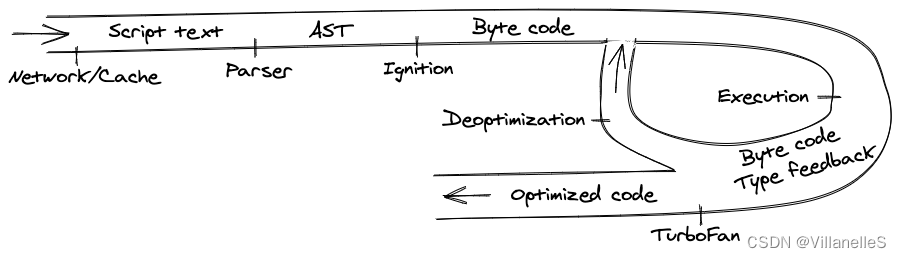
- 始于从网络中获取 JavaScript 代码。
- V8 解析源代码并将其转化为抽象语法树(AST)。
- 基于该 AST,Ignition 解释器可以开始做它的事情,并产生字节码。
- 在这一点上,引擎开始运行代码并收集类型反馈。
- 为了使它运行得更快,字节码可以和反馈数据一起被发送到优化编译器。优化编译器在此基础上做出某些假设,然后产生高度优化的机器代码。
- 如果在某些时候,其中一个假设被证明是不正确的,优化编译器就会取消优化,并回到解释器中。
垃圾回收
垃圾回收,又称为:GC(garbage collection)。
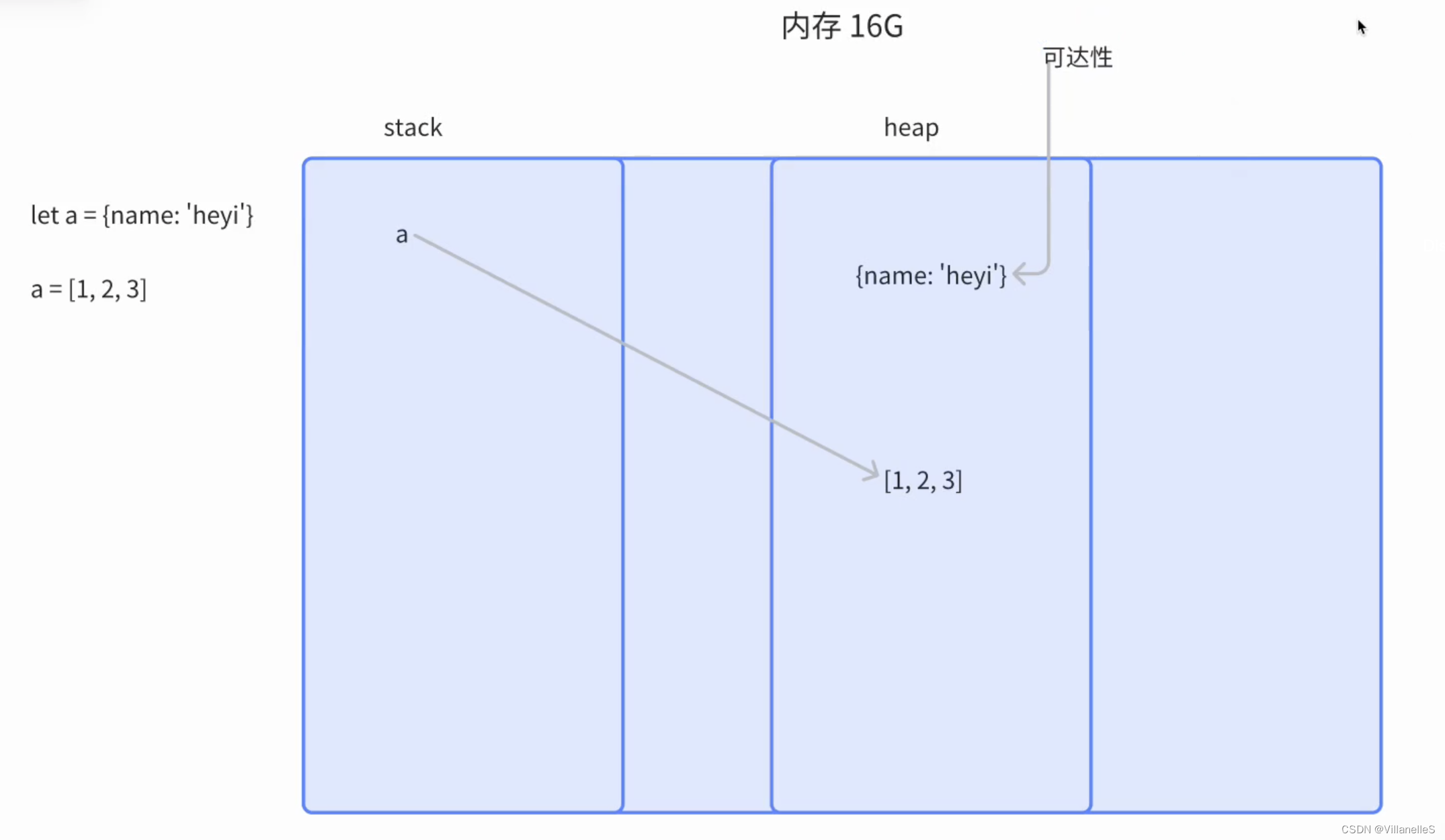
let a = {
name: 'heyi'};
a = [1, 2, 3, 4, 5];
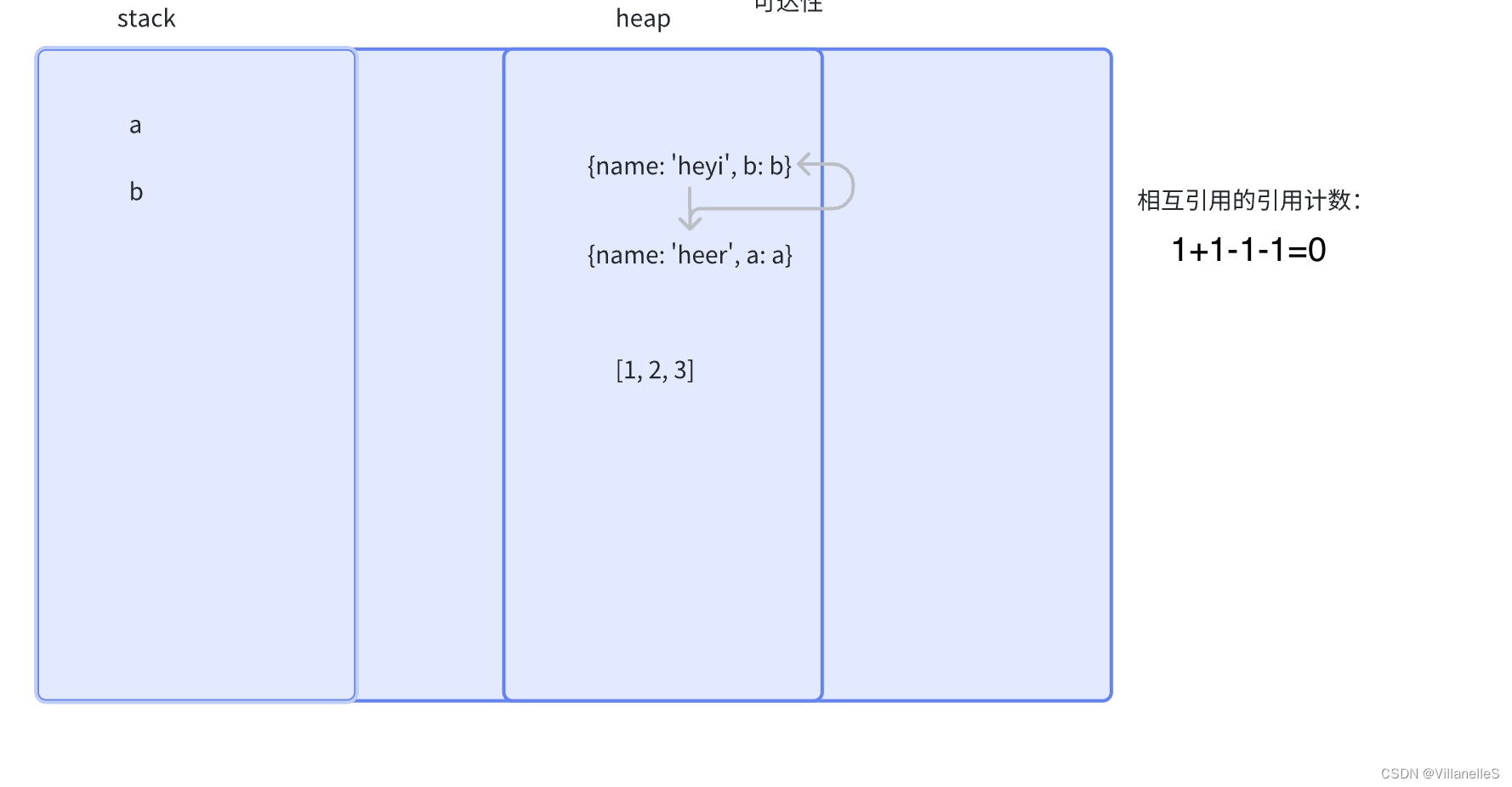
引用计数法
- 当声明了一个变量并且将一个引用类型赋值给该变量的时候这个值的引用次数就为 1
- 如果同一个值又被赋给另一个变量,那么引用数加 1
- 如果该变量的值被其他的值覆盖了,则引用次数减 1
- 当这个值的引用次数变为 0 的时候,说明没有变量在使用,这个值没法被访问了,回收空间,垃圾回收器会在运行的时候清理掉引用次数为 0 的值占用的内存
let a={
name:"heyi",b:b}
let b={
name:"heer",a:a}
a=null
b=null
优点
引用计数算法的优点我们对比标记清除来看就会清晰很多,首先引用计数在引用值为 0 时,也就是在变成垃圾的那一刻就会被回收,所以它可以立即回收垃圾
而标记清除算法需要每隔一段时间进行一次,那在应用程序(JS脚本)运行过程中线程就必须要暂停去执行一段时间的 GC,另外,标记清除算法需要遍历堆里的活动以及非活动对象来清除,而引用计数则只需要在引用时计数就可以了
缺点
引用计数的缺点想必大家也都很明朗了,首先它需要一个计数器ÿ