Mybatis源码分析02-Mapper与BestPractice
前言
Mapper文件解读
- namespace
关联到接口方法,区分类似 package 的作用 - resultMap/resultType
| Pros | Cons | |
|---|---|---|
| resultType | 多表关联字段是清楚知道的,性能调优直观 | 创建很多实体类 |
| resultMap | 不需要写 join 语句 | N+1 问题 |
- sql
- CRUD
自增:<insert id="insert" parameterType="com.gupao.dal.dao.Test" useGeneratedKeys="true" keyProperty="id">
5.动态sql
mybatis-3动态sql官方文档
6.缓存
这里只是简单介绍一下,后续文章我们手写源码时会详细讲原理。
-
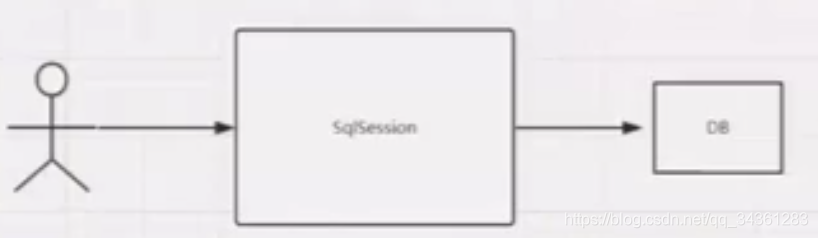
一级缓存
一级缓存指的是Sqlsession级别缓存//mybatis一级缓存伪代码 public void query(){ Sqlsession sqlsession ; sqlsession.selectOne(); //被update 下面的语句就是脏数据 sqlsession.selectOne();//命中缓存 内存 }从上例可以看出,当我们设置mybatis缓存级别是一级缓存后,使用Sqlsession 再次查询的数据,实际上不请求数据库,而是从内存中查询
优势:从缓存中将之前查到的结果取出,减少与数据库的交互
可能存在的问题:当一级缓存执行过程中,同一份数据在数据库层面被更新,那么此时从一级缓存读取到的数据是不准确的! -
二级缓存(默认是关闭的,也不建议使用,一般用redis来替代)
一级缓存指的是Mapper级别缓存
二级缓存的弊端:
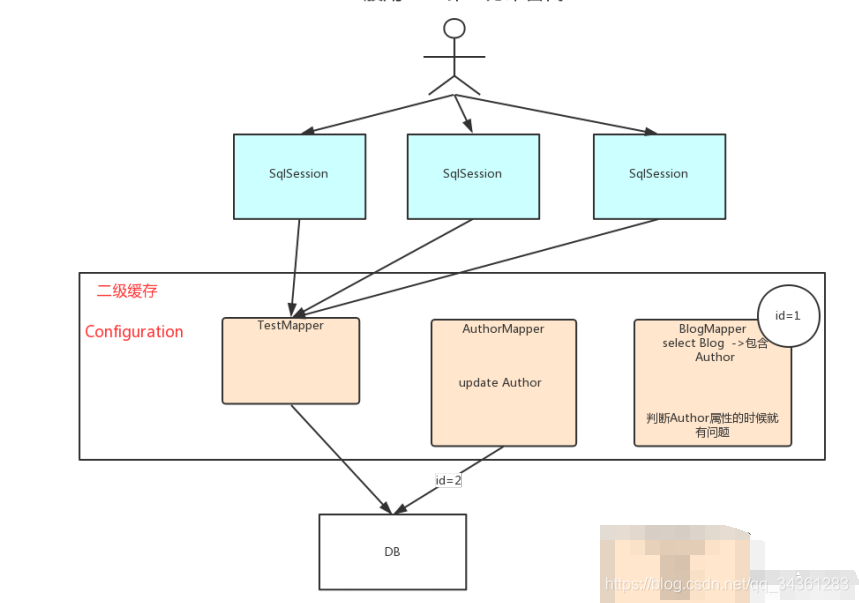
在关联查询时,会容易查询脏数据问题,另外更新缓存数据,缓存更新策略会使数据全部失效,重新获取数据,虽然可以达到效果,但是缓存中有些数据是我们想要的,不一定都要删除,所以不符合实际应用场景。
BestPractice
- 分页
- 逻辑分页
org.apache.ibatis.executor.resultset.DefaultResultSetHandler #handleRowValuesForSimpleResultMap
mybatis通过内置的的这个方法,将ResultSet结果集获取到之后,进行分页,即内存分页 - 物理分页
在查询数据库时,将分页数据
a) limit
b) 分页插件
- 批量操作Batch
| 性能 | ||
|---|---|---|
| for循环一个一个插入 | 低 | 每次都要IO |
| foreach拼SQL(性能最高、推荐使用) | 高 | 有SQL长度限制,定好List大小show variables like ‘%packet%’;show variables like ‘%net_buffer%’; |
| ExeutorType.BATCH | 一般 | 使用见代码com.xxx.test.dal.TestMapperTe st#insertBatchExType |
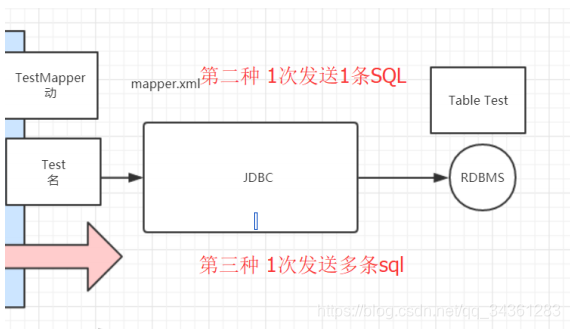
评价这三种方式:
第一种:每循环一次,便查询一次数据库,发送一条SQL
3. 联合查询
- 嵌套结果
- 嵌套查询
a) Lazy loading
b) com.gupao.dal.config.MybatisConfig#localSessio
nFactoryBean

总结
代码在我的gitlab上,地址和之前我的源码分析文章上有发。