目录导航
前言
前面的章节,关于分布式缓存技术,我们分析了《分布式缓存技术之Redis的使用以及原理》、从这一节开始,我们继续来说说MongoDB。
关于MongoDB,一共五小节内容,分别是:
安装 MongoDB 数据库(Windows 和 Linux 环境)
Windows 环境
打开官网:MongoDB 官网下载地址 选择 Community Server 4.0.1 的版本。
安装与启动
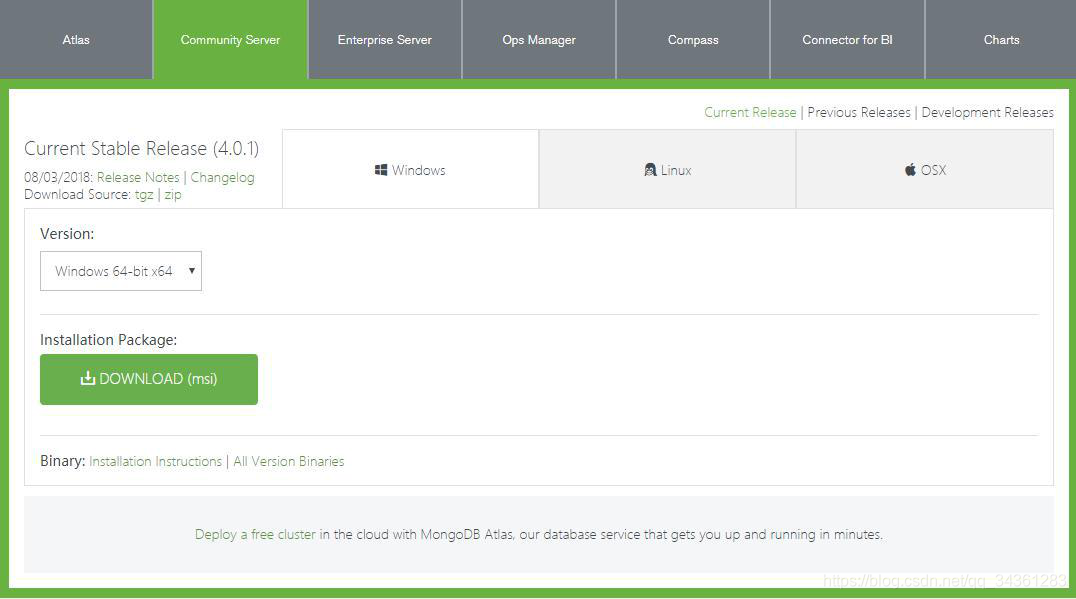
在D 盘创建安装目录,D:\MongoDB,将解压后的文件拷入新建的文件。
在D 盘创建一个目录,D:\MongoDB\Server\4.0\Data,用于存放 MongoDB 的数据。
执行安装,使用命令行,进入 MongDB 的安装目录,执行安装命令,并指明存放 MongoDB 的路径。
安装完成后配置环境变量
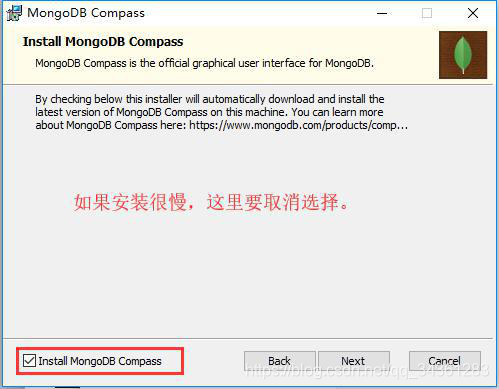
启动数据库
注意,如果这是你的目录中有空格,会报 Invalid command 错误,将 dbpath 后面的值加上双引号即
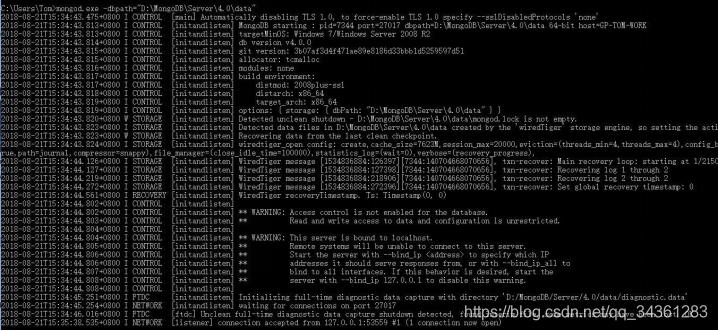
可mongod.exe -dbpath=”D:\MongoDB\Server\4.0\data”。
最后一行显示我们的 MongoDB 已经连接到 27017,它是默认的数据库的端口;它建立完数据库之后,会在我们的 MongoDbData 文件夹下,生成一些文件夹和文件:在 journal 文件夹中会存储相应的数据文件,NoSQL 的 MongoDB,它以文件的形式,也就是说被二进制码转换过的 json 形式来存储所有的数据模型。
启动 MongoDB 数据库,也可以根据自己配置 mongodb.bat 文件,在 D:\MongoDB\Server\4.0\bin 中创建一个 mongodb.bat 文件,然后我们来编写这个可执行文件如下:
mongod --dbpath=D:\MongoDB\Server\4.0\data 运行 mongodb.bat 文件,MongoDB 便启动成功!

Linux 环境
-
解压tgz包(我使用的是Centos6.7版本)
-
cd到安装目录,并观察启动命令 >…<

请注意:

mongo命令: 客户端
mongos命令: 路由器
mongod命令: 数据存储
- 配置环境变量
在任意地方编辑环境变量,注意,我这里使用的是centos6.7版本,读者可根据不同的版本选择相应的配置文件:
vi /etc/profile
重新加载配置文件:
source etc/profile
- 测试安装
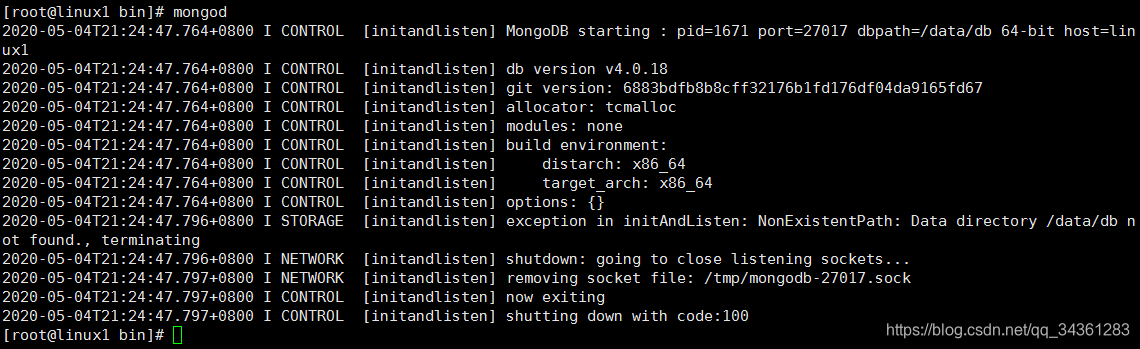
直接启动,提示找不到存放数据的文件夹
我们就在当前mongodb目录下创建data与log文件夹

再次启动:
mongod
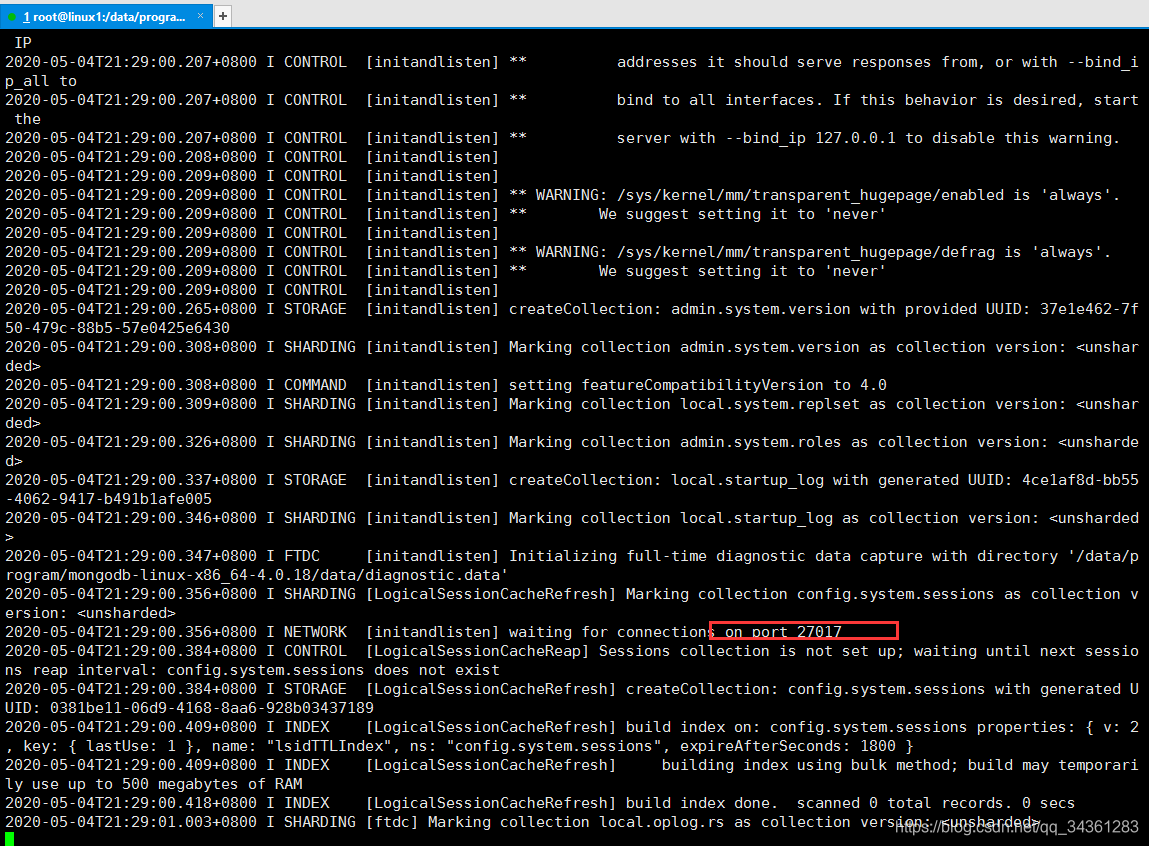
设置数据存储路径:–dbpath=/data/program/mongodb-linux-x86_64-4.0.18/data
设置日志存储路径:–logpath=/data/program/mongodb-linux-x86_64-4.0.18/log
设置后台启动: -fork
设置外联(第三方连接DB): --bind_ip=0.0.0.0
结果成功:
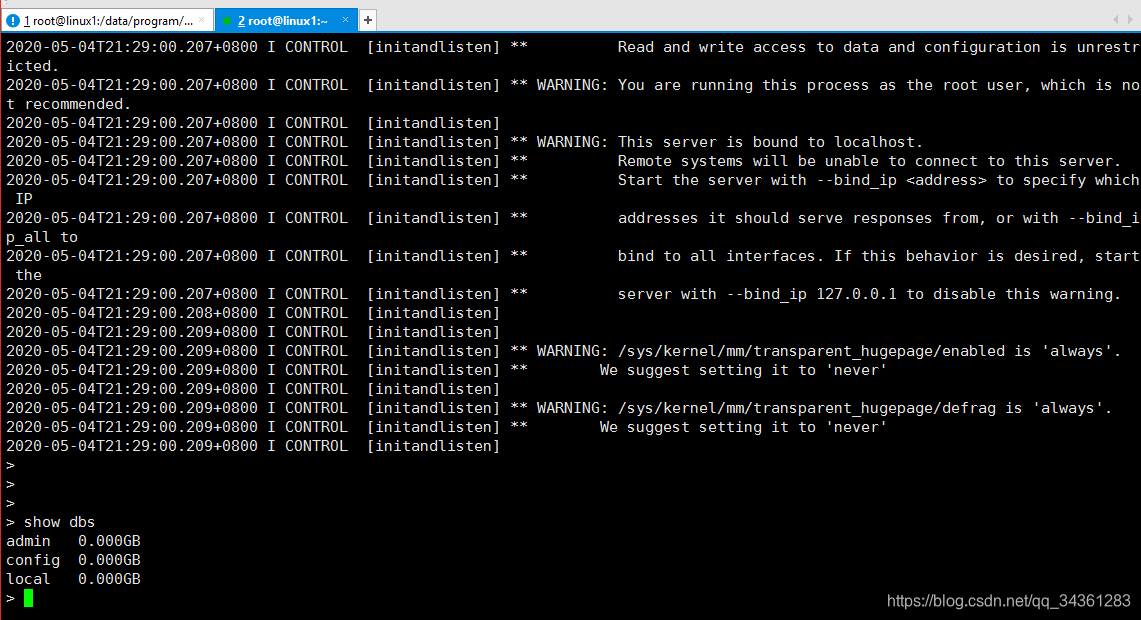
使用mongo进入mongo命令行
这样就没有问题啦·~

安装 RoboMongo 客户端
使用远程连接时,记得关闭防火墙:
然后使用图形化界面连接一下:
MongoDB 基本操作
MongoDB 常用命令
- 创建数据库
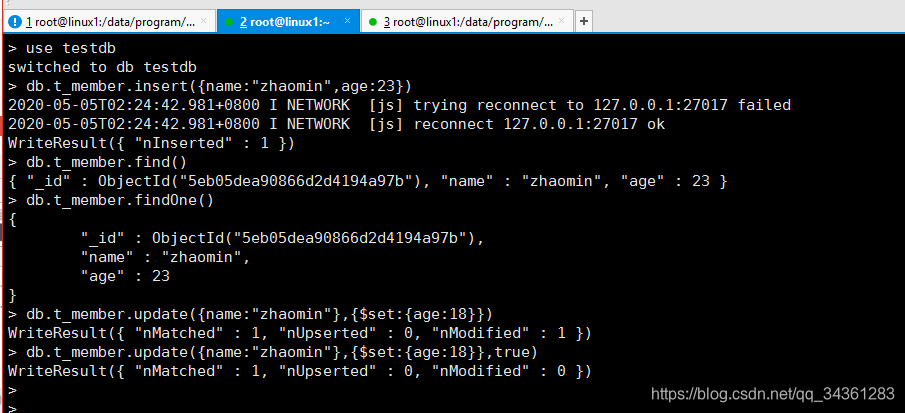
use testdb
命令行效果:
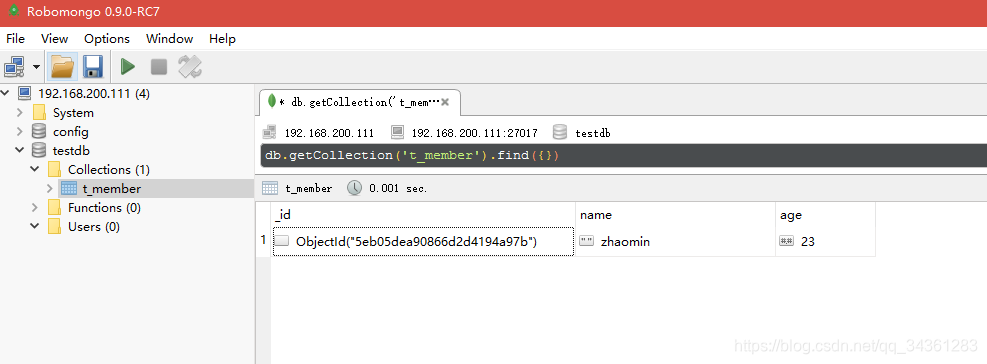
客户端效果:
以下执行经过测试没有问题,读者可以自行测试相关命令~
- 创建集合
db.t_member.insert({name:"zhaomin",age:23})
- 查询
db.t_member.find()
db.t_member.findOne()
- 修改
#不会影响其他属性列 ,主键冲突会报错
db.t_member.update({name:"zhaomin"},{$set:{age:18}})
#第三个参数为 true 则执行 insertOrUpdate 操作,查询出则更新,没查出则插入,或者
db.t_member.update({name:"zhaomin"},{$set:{age:18}},true)
- 删除
#删除满足条件的第一条 只删除数据 不删除索引
db.t_member.remove({age:1})
#删除集合
db.t_member.drop();
#删除数据库
db.dropDatabase();
- 查看集合
show collections
- 查看数据库
show dbs
- 插入数据
db.t_member.insert() #不允许键值重复
db.t_member.save() #若键值重复,可改为插入操作
- 批量更新
db.t_member.update({name:"zhaomin"},{$set:{name:"zhanmin11"}},false,t rue);
批量操作需要和选择器同时使用,第一个 false 表示不执行 insertOrUpdate 操作,第二个 true 表示执行批量
- 更新器使用$set : 指定一个键值对,若存在就进行修改,不存在则添加 $inc :只使用于数字类型,可以为指定键值对的数字类型进行加减操作:
db.t_member.update({name:"zhangsan"},{$inc:{age:2}})
执行结果是名字叫“zhangsan”的年龄加了 2
$unset : 删除指定的键
db.t_member.update({name:"zhangsan"},{$unset:{age:1}})
$push : 数组键操作:1、如果存在指定的数组,则为其添加值;2、如果不存在指定的数组,则创建数组键,并添加值;3、如果指定的键不为数组类型,则报错;
$addToSet : 当指定的数组中有这个值时,不插入,反之插入
#则不会添加到数组里
db.t_member.update({name:"zhangsan"},{$addToSet:{classes:"English"}}) ;
$pop:删除指定数组的值,当 value=1 删除最后一个值,当 value=-1 删除第一个值
#删除了最后一个值
db.t_member.update({name:"zhangsan"},{$pop:{classes:1}})
$pull : 删除指定数组指定的值
#$pullAll 批量删除指定数组
db.persons.update({name:"zhangsan"},{$pull:{classes:"Chinese"}})
#若数组中有多个 Chinese,则全删除
db.t_member.update({name:"zhangsan"},{$pull:{classes:["Chinese"]}})
$ : 修改指定数组时,若数组有多个对象,但只想修改其中一些,则需要定位器:
db.t_member.update({"classes.type":"AA"},{$set:{"classes.$.sex":"male "}})
$addToSet 与 $each 结合完成批量数组更新操作
db.t_member.update({name:"zhangsan"},{$set:{classes:{$each:["chinese" ,"art"]}}})
runCommand 函数和 findAndModify 函数
runCommand({
findAndModify:"persons",
query:{查询器},
sort:{排序},
update:{修改器},
new:true 是否返回修改后的数据
});
runCommand 函数可执行 mongdb 中的特殊函数
findAndModify 就是特殊函数之一,用于返回执行返回 update 或 remove 后的文档
例如:
db.runCommand({
findAndModify:"persons",
query:{name:"zhangsan"},
update:{$set:{name:"lisi"}},
new:true
})
- 高级查询详解
db.t_member.find({},{_id:0,name:1})
第一个空括号表示查询全部数据,第二个括号中值为 0 表示不返回,值为 1 表示返回,默认情况下若不指定主键,主键总是会被返回;
db.persons.find({条件},{指定键});
比较操作符:$lt: < $lte: <= $gt: > $gte: >= $ne: !=
- 查询条件
#查询年龄大于等于 25 小于等于 27 的人
db.t_member.find({age:{$gte:25,$lte:27}},{_id:0,name:1,age:1})
#查询出所有国籍不是韩国的人的数学成绩
db.t_member.find({country:{$ne:"韩国"}},{_id:0,name:1,country:1})
- 包含与不包含(仅针对于数组)
$in 或 $nin
#查询国籍是中国或美国的学生信息
db.t_member.find({country:{$in:["China","USA"]}},{_id:0,name:1:countr y:1})
- $or 查询
#查询语文成绩大于 85 或者英语大于 90 的学生信息
db.t_member.find({$or:[{c:{$gt:85}},{e:{$gt:90}}]},{_id:0,name:1,c:1,e:1})
#把中国国籍的学生上增加新的键 sex
db.t_member.update({country:"China"},{$set:{sex:"m"}},false,true)
#查询出 sex 为 null 的人
db.t_member.find({sex:{$in:[null]}},{_id:0,name:1,sex:1})
- 正则表达式
#查询出名字中存在”li”的学生的信息
db.t_member.find({name:/li/i},{_id:0,name:1})
- $not 的使用
n o t 和 not 和 not和nin 的区别是 n o t 可 以 用 在 任 何 地 方 儿 not 可以用在任何地方儿 not可以用在任何地方儿nin 是用到集合上的
#查询出名字中不存在”li”的学生的信息
db.t_member.find({name:{$not:/li/i}},{_id:0,name:1})
- $all 与 index 的使用
#查询喜欢看 MONGOD 和 JS 的学生
db.t_member.find({books:{$all:["JS","MONGODB"]}},{_id:0,name:1})
#查询第二本书是 JAVA 的学习信息
db.t_member.find({"books.1":"JAVA"},{_id:0,name:1,books:1})
- $size 的使用,不能与比较查询符同时使用
#查询出喜欢的书籍数量是 4 本的学生
db.t_member.find({books:{$size:4}},{_id:0,name:1})
- 查询出喜欢的书籍数量大于 4 本的学生本的学生
1)增加 size 键
db.t_member.update({},{$set:{size:4}},false,true)
2)添加书籍,同时更新 size
db.t_member.update({name:"jim"},{$push:{books:"ORACL"},$inc:{size:1} })
3)查询大于 3 本的
db.t_member.find({size:{$gt:4}},{_id:0,name:1,size:1})
- $slice 操作符返回文档中指定数组的内部值
#查询出 Jim 书架中第 2~4 本书
db.t_member.find({name:"jim"},{_id:0,name:1,books:{$slice:[1,3]}})
#查询出最后一本书
db.t_member.find({name:"jim"},{_id:0,name:1,books:{$slice:-1}})
- 文档查询
查询出在 K 上过学且成绩为 A 的学生
1)绝对查询,顺序和键个数要完全符合
db.t_member.find({school:{school:"K","score":"A"}},{_id:0,name:1})
2)对象方式,但是会出错,多个条件可能会去多个对象查询
db.t_member.find({"school.school":"K","school.score":"A"},{_id:0,nam e:1})
正确做法单条条件组查询$elemMatch
db.t_member.find({school:{$elemMatch:{school:"K",score:"A"}},{_id:0,name:1})
db.t_member.find({age:{$gt:22},books:"C++",school:"K"},{_id:0,name:1,
age:1,books:1,school:1})
- 分页与排序
1)limit 返回指定条数 查询出 persons 文档中前 5 条数据:
db.t_member.find({},{_id:0,name:1}).limit(5)
2)指定数据跨度 查询出 persons 文档中第 3 条数据后的 5 条数据
db.t_member.find({},{_id:0,name:1}).limit(5).skip(3)
3)sort 排序 1 为正序,-1 为倒序
db.t_member.find({},{_id:0,name:1,age:1}).limit(5).skip(3).sort({age:1})
注意:mongodb 的 key 可以存不同类型的数据排序就也有优先级
最小值->null->数字->字符串->对象/文档->数组->二进制->对象 ID->布尔->日期->时间戳->正则->最大值
- 游标
利用游标遍历查询数据
var persons = db.persons.find();
while(persons.hasNext()){
obj = persons.next();
print(obj.name)
}
游标几个销毁条件
1).客户端发来信息叫他销毁
2).游标迭代完毕
3).默认游标超过 10 分钟没用也会别清除
- 查询快照
快照后就会针对不变的集合进行游标运动了,看看使用方法.
#用快照则需要用高级查询
db.persons.find({$query:{name:”Jim”},$snapshot:true})
- 高级查询选项
1)$query
2)$orderby
3)$maxsan:integer 最多扫描的文档数
4)$min:doc 查询开始
5)$max:doc 查询结束
6)$hint:doc 使用哪个索引
7)$explain:boolean 统计
8)$snapshot:boolean 一致快照
- 查询点(70,180)最近的 3 个点
db.map.find({gis:{$near:[70,180]}},{_id:0,gis:1}).limit(3)
- 查询以点(50,50)和点(190,190)为对角线的正方形中的所有的点
db.map.find({gis:{$within:{$box:[[50,50],[190,190]]}}},{_id:0,gis:1})
- 查询出以圆心为(56,80)半径为 50 规则下的圆心面积中的点
db.map.find({gis:{$with:{$center:[[56,80],50]}}},{_id:0,gis:1})
- Count+Distinct+Group
- count 查询结果条数
db.persons.find({country:"USA"}).count()
- Distinct 去重
请查询出 persons 中一共有多少个国家分别是什么
#key 表示去重的键
db.runCommand({distinct:"persons",key:"country"}).values
- group 分组
db.runCommand({ group:{
ns:"集合的名字",
key:"分组键对象",
initial:"初始化累加器",
$reduce:"分解器",
condition:"条件",
finalize:"组完成器"
}})
分组首先会按照 key 进行分组,每组的 每一个文档全要执行$reduce 的方法,他接收 2 个参数一个是组内本条记录,一个是累加器数据.
请查出 persons 中每个国家学生数学成绩最好的学生信息(必须在 90 以上)
db.runCommand({
group:{
ns:"persons",
key:{"country":true},
initial:{m:0},
$reduce:function(doc,prev){
if(doc.m>prev.m){
prev.m = doc.m;
prev.name = doc.m;
prev.country = doc.country;
}
},
condition:{m:{$gt:90}},
finalize:function(prev){
prev.m = prev.name+" comes from "+prev.country+" ,Math score is"+prev.m;
}
}
})
- .函数格式化分组键
如果集合中出现键 Counrty 和 counTry 同时存在
$keyf:function(doc){
if(doc.country){
return {country:doc.country}
}
return {country:doc.counTry}
}
- 常用命令举例
- 查询服务器版本号和主机操作系统
db.runCommand({buildInfo:1})
- 查询执行集合的详细信息,大小,空间,索引等
db.runCommand({collStats:"persons"})
- 查看操作本集合最后一次错误信息
db.runCommand({getLastError:"persons"})
- 固定集合
- 特性
固定集合默认是没有索引的就算是_id 也是没有索引的,由于不需分配新的空间他的插入速度是非常快的
固定集合的顺是确定的导致查询速度是非常快的
最适合就是日志管理
- 创建固定集合
创建一个新的固定集合要求大小是 100 个字节,可以存储文档 10 个
db.createCollection("mycoll",{size:100,capped:true,max:10})
把一个普通集合转换成固定集合
db.runCommand({convertToCapped:"persons",size:1000})
- 对固定集合反向排序,默认情况是插入的顺序排序
db.mycoll.find().sort({$natural:-1})
常见问题总结
Mongo和ES对比
elasticsearch 纯粹的是json(字符串),而mongo结构更加复杂
mongo的优势是哪些?
- BSON
- GirdFS(复杂性的体现)
用户手机注册验证码存取适合用mongo吗?还是redis?
建议用Seesion,用Redis过时时间,不推荐用MongoDB
MongoDB应用场景
-
不规则日志:ELK, Log4J INFO,ERROR,WARN,DEBUG(字符串?)
Pattern,用正则去解析字符串,不止一个正则,
每一种日志格式都要编写一个正则去匹配
既然用正则麻烦,为什么还用ELK存储日志?
因为可能你的系统已经平稳运行N年了(.Net,PHP、Java多语言交错,情况复杂) -
规则日志:MongoDB,结构化的整理,
用户行为日志 operationTime creator type target
Timline,调用链路 invoker Time targetMethod args returnVal throws -
持续增量(id + UpdateTime)
-
文件存储:GirdFS(文件存储系统)
-
不适合Reids:数据需要持久性的而且有一定的依赖性
适合Redis:数据会设置时效
分布式锁
用户登录token
数据库缓存中间件
MongoDB(GridFS)、Hadoop、HBase对于数据存储得使用场景选择吗?
定位:
MongoDB,为一个结构化的缓存,由于设计原理不同,数据量是一定的瓶颈的。
HBase ,基于列簇扩展性,高可用程度会更加灵活,数量级和MongoDB也是有很大差异的。
HBase 通常会跟大数据联系在一起
MongoDB 顶多算是一个日志数据库,文件存储系统
Mongo怎么持久化的?
持久化都是用文件的形式存储,其实任何数据库都是用文件实现持久化的
后记
更多架构知识,欢迎关注本套Java系列文章,地址导航:Java架构师成长之路