目录导航
前言
本节我们深入了解Java实现多线程的原理。本专题共计5个小节,分别是:
- 并发编程的基础
- 并发编程的实现原理
- 并发编程的原理(上)
- 并发编程的原理(下)
- 并发实战
本节重点:
-
Java 内存模型(Java Memory Model,即JMM)
-
JMM如何解决原子性、可见性、有序性的问题
-
synchronized和volatile
Java 内存模型
内存模型定义了共享内存系统中多线程程序读写操作行为的规范,来屏蔽各种硬件和操作系统的内存访问差异,来实现 Java 程序在各个平台下都能达到一致的内存访问效果。Java 内存模型的主要目标是定义程序中各个变量的访问规则,也就是在虚拟机中将变量存储到内存以及从内存中取出变量(这里的变量,指的是共享变量,也就是实例对象、静态字段、数组对象等存储在堆内存中的变量。而对于局部变量这类的,属于线程私有,不会被共享)这类的底层细节。通过这些规则来规范对内存的读写操作,从而保证指令执行的正确性。
它与处理器有关、与缓存有关、与并发有关、与编译器也有关。他解决了 CPU多级缓存、处理器优化、指令重排等导致的内存访问问题,保证了并发场景下的可见性、原子性和有序性,。内存模型解决并发问题主要采用两种方式:限制处理器优化和使用内存屏障
Java 内存模型定义了线程和内存的交互方式,在 JMM 抽象模型中,分为主内存、工作内存。主内存是所有线程共享的,工作内存是每个线程独有的。线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,不能直接读写主内存中的变量。并且不同的线程之间无法访问对方工作内存中的变量,线程间的变量值的传递都需要通过主内存来完成,他们三者的交互关系如下:
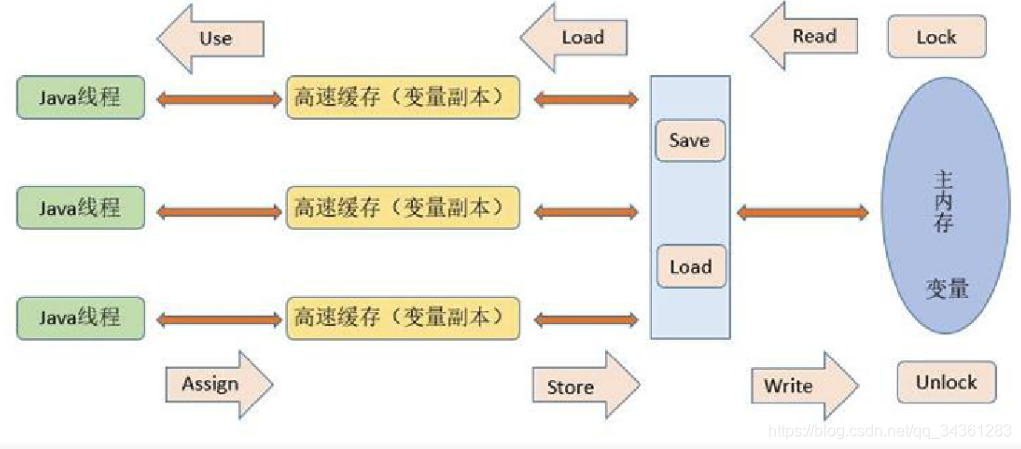
所以,总的来说,JMM 是一种规范,目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。目的是保证并发编程场景中的原子性、可见性和有序性。
这里推荐一篇文章:什么是 Java 内存模型?
扩展阅读:深入理解 JVM 内存模型(JMM)和垃圾回收器(GC)
JMM如何解决原子性、可见性、有序性的问题
其实线程安全问题可以总结为: 可见性、原子性、有序性这几个问题,我们搞懂了这几个问题并且知道怎么解决,那么多线程安全性问题也就不是问题了
在 Java1.8 源码 HotSpot 里,我们可以看出端倪,类似于解决CPU的高速缓存与主内存之间共享变量原子性、可见性、有序性的问题,在Java的世界,推出JMM(Java Memory Model)模型用以维护多线程安全等问题。
在Java中提供了一系列和并发处理相关的关键字,比如volatile、Synchronized、final、juc等,这些就是Java内存模型封装了底层的实现后提供给开发人员使用的关键字,在开发多线程代码的时候,我们可以直接使用synchronized等关键词来控制并发,使得我们不需要关心底层的编译器优化、缓存一致性的问题了,所以在Java内存模型中,除了定义了一套规范,还提供了开放的指令在底层进行封装后,提供给开发人员使用。
- 原子性保障
在java中提供了两个高级的字节码指令monitorenter和monitorexit,在Java中对应的Synchronized来保证代码块内的操作是原子的。
- 可见性保障
Java中的volatile关键字提供了一个功能,那就是被其修饰的变量在被修改后可以立即同步到主内存,被其修饰的变量在每次是用之前都从主内存刷新。因此,可以使用volatile来保证多线程操作时变量的可见性。
除了volatile,Java中的synchronized和final两个关键字也可以实现可见性。
- 有序性保障
在Java中,可以使用synchronized和volatile来保证多线程之间操作的有序性。实现方式有所区别:
volatile关键字会禁止指令重排。
synchronized关键字保证同一时刻只允许一条线程操作。
volatile如何保证可见性
下载hsdis工具 ,https://sourceforge.net/projects/fcml/files/fcml-1.1.1/hsdis-1.1.1-win32-amd64.zip/download
解压后存放到jre目录的server路径下
然后跑main函数,跑main函数之前,加入如下虚拟机参数:
-server -Xcomp -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly - XX:CompileCommand=compileonly,*App.getInstance(替换成实际运行的代码)
volatile变量修饰的共享变量,在进行写操作的时候会多出一个lock前缀的汇编指令,这个指令在前面我们讲解CPU高速缓存的时候提到过,会触发总线锁或者缓存锁,通过缓存一致性协议来解决可见性问题。
对于声明了volatile的变量进行写操作,JVM就会向处理器发送一条Lock前缀的指令,把这个变量所在的缓存行的数据写回到系统内存,再根据我们前面提到过的MESI的缓存一致性协议,来保证多CPU下的各个高速缓存中的数据的一致性。
volatile防止指令重排序
指令重排的目的是为了最大化的提高CPU利用率以及性能,CPU的乱序执行优化在单核时代并不影响正确性,但是在多核时代的多线程能够在不同的核心上实现真正的并行,一旦线程之间共享数据,就可能会出现一些不可预料的问题。
指令重排序必须要遵循的原则是,不影响代码执行的最终结果,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序,(这里所说的数据依赖性仅仅是针对单个处理器中执行的指令和单个线程中执行的操作.)。
这个语义,实际上就是as-if-serial语义,不管怎么重排序,单线程程序的执行结果不会改变,编译器、处理器都必须遵守as-if-serial语义。
多核心多线程下的指令重排影响
public class ThreadTest {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
a = 1;
x = b;
});
Thread t2 = new Thread(() -> {
b = 1;
y = a;
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("x=" + x + "->y=" + y);
}
}
如果不考虑编译器重排序和缓存可见性问题,上面这段代码可能会出现的结果是 x=0,y=1; x=1,y=0; x=1,y=1这三种结果,因为可能是先后执行t1/t2,也可能是反过来,还可能是t1/t2交替执行,但是这段代码的执行结果也有可能是x=0,y=0。这就是在乱序执行的情况下会导致的一种结果,因为线程t1内部的两行代码之间不存在数据依赖,因此可以把x=b乱序到a=1之前;同时线程t2中的y=a也可以早于t1中的a=1执行,那么他们的执行顺序可能是
t1: x=b
t2:b=1
t2:y=a
t1:a=1
所以从上面的例子来看,重排序会导致可见性问题。但是重排序带来的问题的严重性远远大于可见性,因为并不是所有指令都是简单的读或写,比如DCL的部分初始化问题。所以单纯的解决可见性问题还不够,还需要解决处理器重排序问题。
内存屏障
内存屏障需要解决我们前面提到的两个问题,一个是编译器的优化乱序和CPU的执行乱序,我们可以分别使用优化屏障和内存屏障这两个机制来解决。
从CPU层面来了解一下什么是内存屏障
CPU的乱序执行,本质还是,由于在多CPU的机器上,每个CPU都存在cache,当一个特定数据第一次被特定一个CPU获取时,由于在该CPU缓存中不存在,就会从内存中去获取,被加载到CPU高速缓存中后就能从缓存中快速访问。当某个CPU进行写操作时,它必须确保其他的CPU已经将这个数据从他们的缓存中移除,这样才能让其他CPU安全的修改数据。显然,存在多个cache时,我们必须通过一个cache一致性协议来避免数据不一致的问题,而这个通讯的过程就可能导致乱序访问的问题,也就是运行时的内存乱序访问。
现在的CPU架构都提供了内存屏障功能,在x86的cpu中,实现了相应的内存屏障写屏障(store barrier)、读屏障(load barrier)和全屏障(Full Barrier),主要的作用是
-
防止指令之间的重排序
-
保证数据的可见性
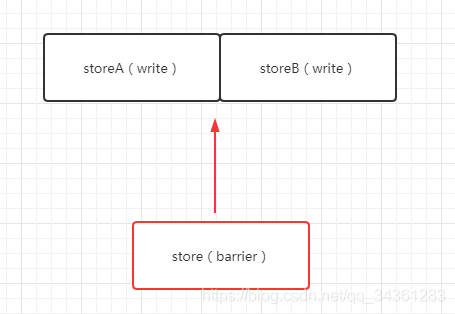
- store barrier
store barrier称为写屏障,相当于storestore barrier, 强制所有在storestore内存屏障之前的所有执行,都要在该内存屏障之前执行,并发送缓存失效的信号。所有在storestore barrier指令之后的store指令,都必须在 storestore barrier屏障之前的指令执行完后再被执行。也就是进制了写屏障前后的指令进行重排序,是的所有 store barrier之前发生的内存更新都是可见的(这里的可见指的是修改值可见以及操作结果可见)
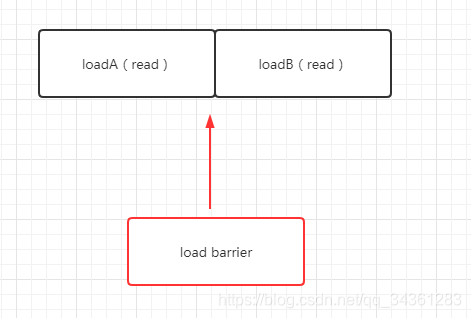
- load barrier
load barrier称为读屏障,相当于loadload barrier,强制所有在load barrier读屏障之后的load指令,都在load barrier屏障之后执行。也就是进制对load barrier读屏障前后的load指令进行重排序, 配合store barrier,使得所有store barrier之前发生的内存更新,对load barrier之后的load操作是可见的
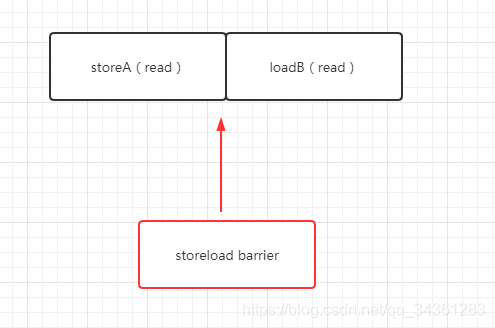
- Full barrier
full barrier成为全屏障,相当于storeload,是一个全能型的屏障,因为它同时具备前面两种屏障的效果。强制了所有在storeload barrier之前的store/load指令,都在该屏障之前被执行,所有在该屏障之后的的store/load指令,都在该屏障之后被执行。禁止对storeload屏障前后的指令进行重排序。
总结:内存屏障只是解决顺序一致性问题,不解决缓存一致性问题,缓存一致性是由cpu的缓存锁以及MESI协议来完成的。而缓存一致性协议只关心缓存一致性,不关心顺序一致性。所以这是两个问题
编译器层面如何解决指令重排序问题
在编译器层面,通过volatile关键字,取消编译器层面的缓存和重排序。保证编译程序时在优化屏障之前的指令不会在优化屏障之后执行。这就保证了编译时期的优化不会影响到实际代码逻辑顺序。
如果硬件架构本身已经保证了内存可见性,那么volatile就是一个空标记,不会插入相关语义的内存屏障。如果硬件架构本身不进行处理器重排序,有更强的重排序语义,那么volatile就是一个空标记,不会插入相关语义的内存屏障。
在JMM中把内存屏障指令分为4类,通过在不同的语义下使用不同的内存屏障来进制特定类型的处理器重排序,从而来保证内存的可见性
LoadLoad Barriers, load1 ; LoadLoad; load2 , 确保load1数据的装载优先于load2及所有后续装载指令的装载
StoreStore Barriers,store1; storestore;store2 , 确保store1数据对其他处理器可见优先于store2及所有后续存储指令的存储
LoadStore Barries, load1;loadstore;store2, 确保load1数据装载优先于store2以及后续的存储指令刷新到内存
StoreLoad Barries, store1; storeload;load2, 确保store1数据对其他处理器变得可见, 优先于load2及所有后续装载指令的装载;这条内存屏障指令是一个全能型的屏障,在前面讲cpu层面的内存屏障的时候有提到。它同时具有其他3条屏障的效果
volatile为什么不能保证原子性
public class Demo {
volatile int i;
public void incr(){
i++;
}
public static void main(String[] args) {
new Demo().incr();
}
}
运行后然后通过javap -c Demo.class,去查看字节码
对一个原子递增的操作,会分为三个步骤:
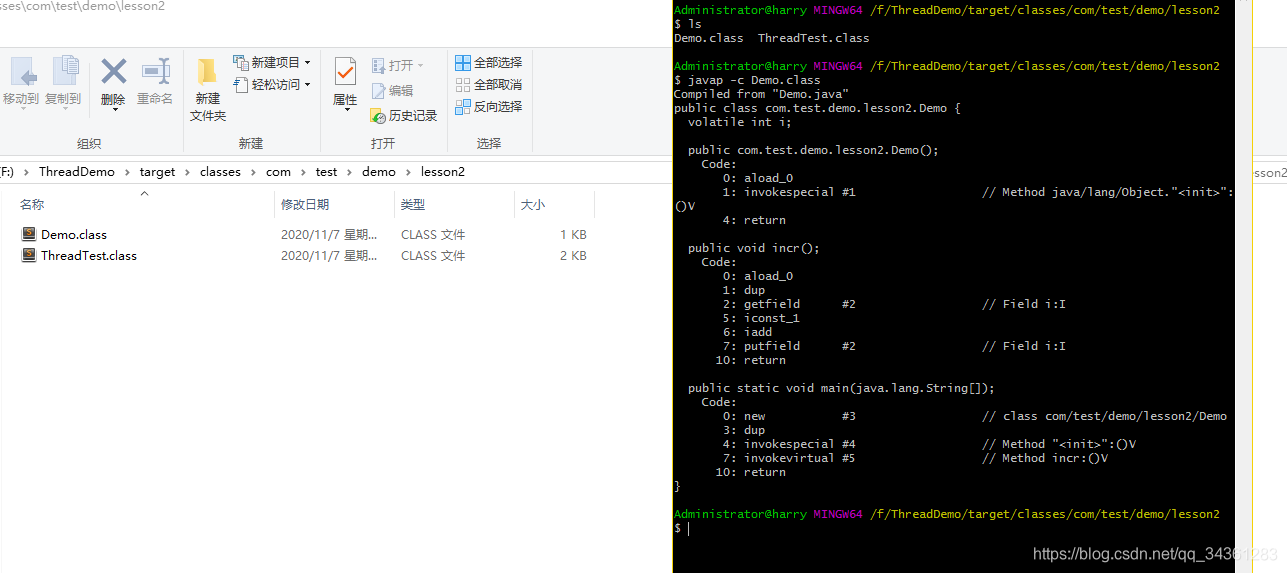
- 读取volatile变量的值到local;
- 增加变量的值;
- 把local的值写回让其他线程可见。
写在最后
本节演示代码地址:
https://github.com/harrypottry/ThreadDemo
更多架构知识,欢迎关注本套系列文章:Java架构师成长之路